SQLite 在这个小工具里扮演什么角色
很多人一听 SQLite,会先想到“数据库”三个字,好像一下就有压力了。但放到断点续跑这个场景里,它更像一本可查询、可更新、不会轻易丢的进度账本。
它解决的是脚本已经处理到一半时,进度该怎么可靠记住的问题。单靠 try-except 只能接错误,不能回答“哪些做完了,哪些还没做”。
它也不是为了把小工具做成大系统。和临时写一个 txt 记录文件相比,SQLite 更适合承载状态、重试次数和结果摘要这些会持续变化的信息。
 一批待处理任务被写进 SQLite 进度账本,脚本重启后继续从未完成项开始。
一批待处理任务被写进 SQLite 进度账本,脚本重启后继续从未完成项开始。在开发批量处理脚本时,最棘手的问题往往不是遇到错误导致中断。
更麻烦的是脚本已经运行了半个小时,处理到第 187 个文件时突然崩溃。如果不做断点记录,重新运行就得把前面 186 个文件全部重跑一遍;若是直接跳过,又很难理清哪些处理过、哪些遗漏了。
这种问题单靠 try-except 异常捕获是无法解决的。
更稳妥的思路是:将任务进度实时记录到本地数据库中。脚本每成功处理完一条记录,就将其状态更新为完成。下次启动时,脚本只需查询出未完成的任务继续处理即可。
SQLite 极其适合承载这类轻量级的本地状态。它是一个纯文件型的数据库,无需搭建数据库服务,而且 Python 标准库已经内置了 sqlite3 模块,我们拿来即用,非常适合作为中小型脚本的断点续跑底座。
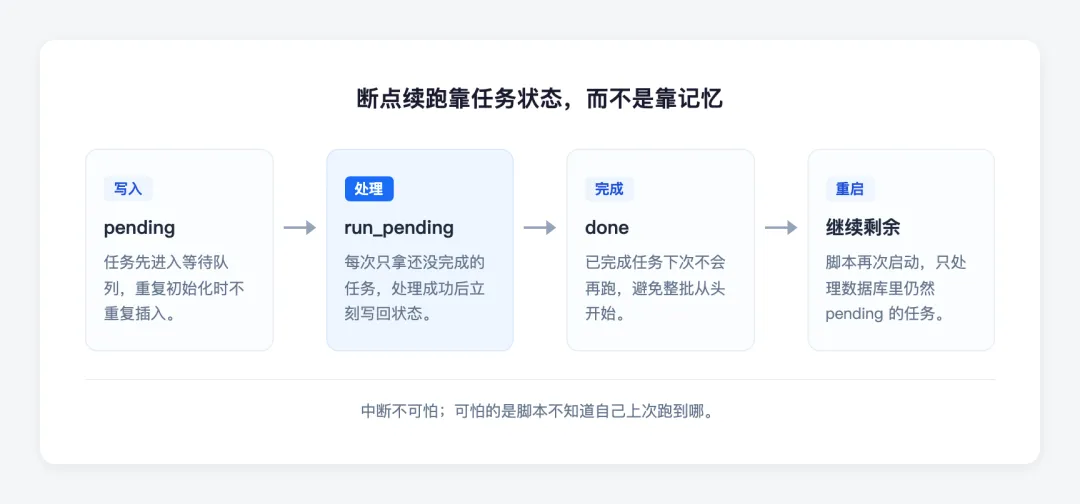
断点续跑的核心:脚本要记住进度
很多脚本最开始是这样写的:
for file in files: process(file)
代码很直观,但它没有记忆。
脚本中断以后,只知道“没跑完”,不知道:
断点续跑要补的就是这层记忆。
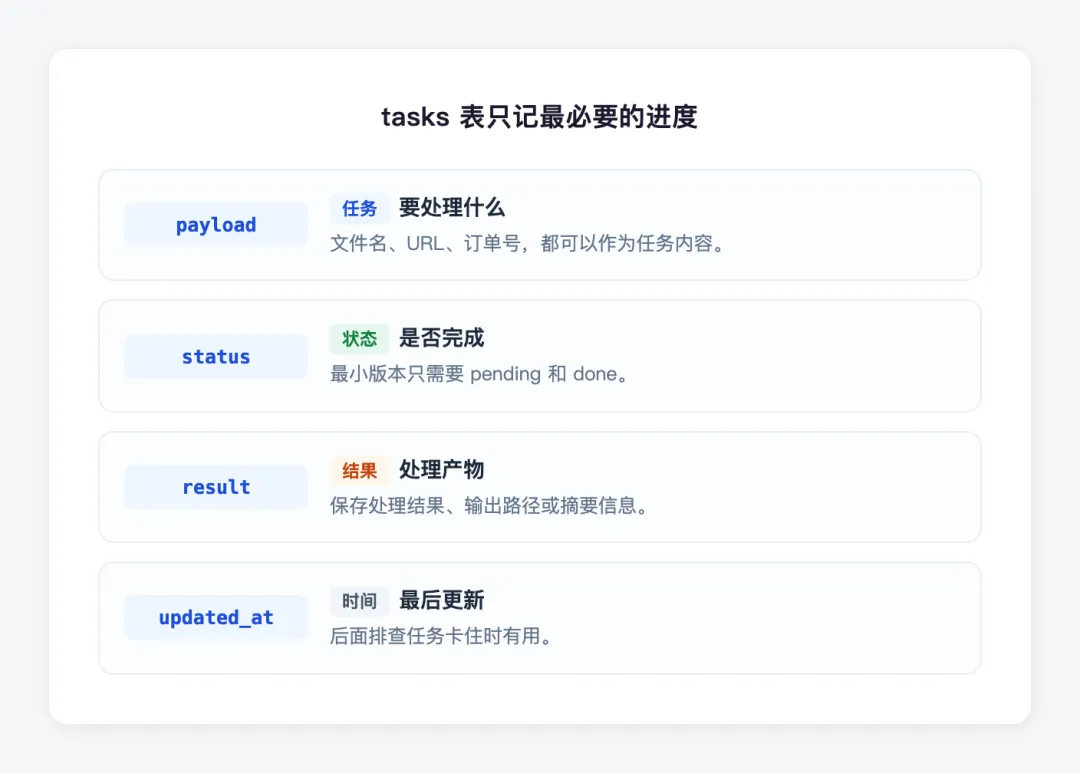
最小版本只需要一张 tasks 表:
| |
|---|
id | |
payload | |
status | |
result | |
updated_at | |
这套简易的表结构足以应付绝大多数日常的数据批处理工作,如批量下载、接口同步、文件格式清洗以及报表汇总等。
 任务从待处理到完成的状态被稳定记录,脚本异常后仍能继续执行。
任务从待处理到完成的状态被稳定记录,脚本异常后仍能继续执行。
数据库设计与任务表创建
接下来,我们编写连接数据库与初始化任务表的函数:
from pathlib import Pathimport loggingimport sqlite3logging.basicConfig(level=logging.INFO, format="%(message)s")logger = logging.getLogger("resume_queue")def connect(db_path: Path) -> sqlite3.Connection: conn = sqlite3.connect(db_path) conn.row_factory = sqlite3.Row return conndef init_db(conn: sqlite3.Connection) -> None: conn.execute( """ CREATE TABLE IF NOT EXISTS tasks ( id INTEGER PRIMARY KEY AUTOINCREMENT, payload TEXT NOT NULL UNIQUE, status TEXT NOT NULL DEFAULT 'pending', result TEXT, updated_at TEXT NOT NULL DEFAULT CURRENT_TIMESTAMP ) """ ) conn.commit()
在这里,我们将 payload 字段设为唯一索引(UNIQUE),目的是防止在初始化阶段导入重复的作业任务。
如果同一个文件名已经记录在任务表中,再次启动脚本时就会自动跳过,从而避免了重复消费相同数据的逻辑漏洞。
任务导入的幂等性设计
批处理脚本在日常运行中可能会被反复启动或重启。
这意味着“将任务灌入队列”的动作必须具备幂等性(即无论执行多少次,状态都应当一致),而不能在第二次运行导入时由于数据冲突导致脚本崩溃。
TASKS = [ "orders-001.xlsx", "orders-002.xlsx", "orders-003.xlsx", "orders-004.xlsx", "orders-005.xlsx",]def seed_tasks(conn: sqlite3.Connection, payloads: list[str]) -> None: conn.executemany( "INSERT OR IGNORE INTO tasks (payload) VALUES (?)", [(payload,) for payload in payloads], ) conn.commit()
这里起到关键作用的是 SQL 中的 INSERT OR IGNORE 语法。
它的执行机制是:如果当前 payload 数据在任务表中尚不存在,则正常写入;如果该 payload 已经存在,则直接忽略。
有了这个机制,脚本每次冷启动时都可以安全地执行 seed_tasks() 来填充任务队列,而无需担心造成数据库任务冗余。
每次只拿 pending 任务
接下来写两个函数:
def get_next_pending(conn: sqlite3.Connection) -> sqlite3.Row | None: return conn.execute( """ SELECT id, payload FROM tasks WHERE status = 'pending' ORDER BY id LIMIT 1 """ ).fetchone()def mark_done(conn: sqlite3.Connection, task_id: int, result: str) -> None: conn.execute( """ UPDATE tasks SET status = 'done', result = ?, updated_at = CURRENT_TIMESTAMP WHERE id = ? """, (result, task_id), ) conn.commit()
这段调度逻辑非常直观:
首先,查询并提取出最早写入的那条 pending 任务;随后,对其执行具体的业务逻辑处理;最后,待业务处理成功后,将该任务的状态更新为 done。
更新为 done 后,该任务便从待处理列表中被剔除,后续的循环和下次冷启动都不会再去读取它。如果脚本在中途被强行终止,尚未完成的任务状态依然为 pending,会在下一次执行中被重新读取并继续处理。
跑任务时,循环到没有 pending 为止
为了演示断点续跑,我们给运行函数加一个 limit 参数。
比如第一轮只跑 2 条,用来模拟脚本跑到一半停掉;第二轮不传 limit,它就会继续处理剩下的任务。
def process_payload(payload: str) -> str: return f"processed:{payload}"def run_pending(conn: sqlite3.Connection, limit: int | None = None) -> int: done_count = 0 while True: if limit is not None and done_count >= limit: break task = get_next_pending(conn) if task is None: break result = process_payload(task["payload"]) mark_done(conn, task["id"], result) done_count += 1 return done_count
真实项目里,process_payload() 可以换成任何耗时任务:
这套断点续跑的状态机和具体业务逻辑是完全解耦的,它只负责追踪和调度任务的执行边界。
命令行交互入口设计
为了让该工具能够在服务器或终端方便地被重复运行,我们为其封装一个友好的命令行入口:
import argparsedef get_summary(conn: sqlite3.Connection) -> dict[str, int]: rows = conn.execute( """ SELECT status, COUNT(*) AS count FROM tasks GROUP BY status """ ).fetchall() return {row["status"]: row["count"] for row in rows}def parse_args() -> argparse.Namespace: parser = argparse.ArgumentParser(description="SQLite 断点续跑任务队列") parser.add_argument("--db", type=Path, default=Path("tasks.db"), help="SQLite 数据库路径") parser.add_argument("--seed", action="store_true", help="写入示例任务") parser.add_argument("--limit", type=int, help="本轮最多处理多少条任务") return parser.parse_args()def main() -> None: args = parse_args() with connect(args.db) as conn: init_db(conn) if args.seed: seed_tasks(conn, TASKS) done_count = run_pending(conn, args.limit) summary = get_summary(conn) logger.info("本轮处理:%s 条", done_count) logger.info("当前状态:%s", summary)
完整结构是这样:

第一次运行,只处理 2 条:
python3 resume_queue.py --db demo.db --seed --limit 2
输出:
本轮处理:2 条当前状态:{'done': 2, 'pending': 3}
第二次运行,不加 --limit:
python3 resume_queue.py --db demo.db
输出:
本轮处理:3 条当前状态:{'done': 5}
这样,一个具备核心断点续跑逻辑的小脚本便构建完成了。
业务操作的幂等性防护
在将这套断点续跑方案落地到真实的复杂业务中时,我们需要考虑一个经典的边界情况:如果业务代码已经执行完毕(比如接口已调用),但在状态还没来得及更新为 done 之前脚本被杀掉了,会发生什么?
下次重启时,由于数据库状态仍为 pending,它会再次被读取并重新处理一遍。
因此,被处理的业务操作应当设计为具有幂等性,或者在最终的数据落盘时加入唯一约束限制。
比如处理文件时,可以把输出文件名固定成:
output/orders-001.result.json
重新处理同一条任务时,直接覆盖同一个结果文件,而不是生成一堆重复文件。
如果写数据库结果,也可以给结果表加唯一键:
UNIQUE(task_id)
断点续跑不负责消灭所有错误,它负责让脚本出错之后还有办法继续,并且尽量不把结果弄乱。
什么时候该加 running 和 failed
最小版本只有 pending 和 done。
如果任务会跑很久,或者需要记录失败原因,可以继续扩展状态:
这时还可以加两个字段:
但是,不要在初期过度设计。
对于大多数个人维护的脚本、中小型文件批处理(任务量在几百到几万条之间),pending 和 done 这套极简的双状态模型就已经足够好用。只有在涉及复杂的并发处理、超时自动回滚或人工三审纠错时,我们才有必要升级为复杂的状态机。
长期运行脚本的健壮性要求
日常随手写完的脚本与能够稳定在生产环境中长期跑的小工具之间,差距往往体现在以下几个细节上:
- • 配置与参数能够通过命令行或配置文件注入,而不是在代码中写死;
- • 具备清晰的日志记录,能一眼看出当前任务推进到何处;
- • 有良好的异常拦截与隔离机制,保证单一任务出错不连累整体跑飞;
- • 支持断点续爬和断点续跑,应对网络瞬断或系统维护;
- • 运行结果在重复执行时能够干净覆盖,而不会造成数据冗余。
这就是引入断点续跑的目标。在任何技术开发里,让工具平稳运行当然重要;如果它因为外部原因中断,还能随时恢复继续执行,才说明这个自动化小系统已经比较成熟。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
