大家好,我是木木。
今天给大家分享一个实用的 Python 库,cachetools。
cachetools
cachetools 是一个专门处理本地缓存的 Python 库。它提供了 LRU、LFU、FIFO、TTL 等多种缓存容器,也提供 cached、cachedmethod 这类装饰器,让函数结果缓存变得很轻量。相比直接用普通 dict,它更适合需要控制容量、过期时间和淘汰策略的场景;相比引入 Redis,它又少了服务依赖,特别适合进程内热点数据、配置结果、轻量 API 响应和计算结果复用。
项目地址:https://github.com/tkem/cachetools
官方文档:https://cachetools.readthedocs.io/
三大特点
策略丰富
内置 LRU、LFU、FIFO、RR、TTL 等策略,能按访问模式选择缓存。
装饰便捷
用 cached 给函数加缓存,改动小,适合包住纯计算和轻量查询。
进程内轻量
没有外部服务依赖,适合单进程或单实例里的热点数据复用。
最佳实践
安装方式:pip install cachetools。
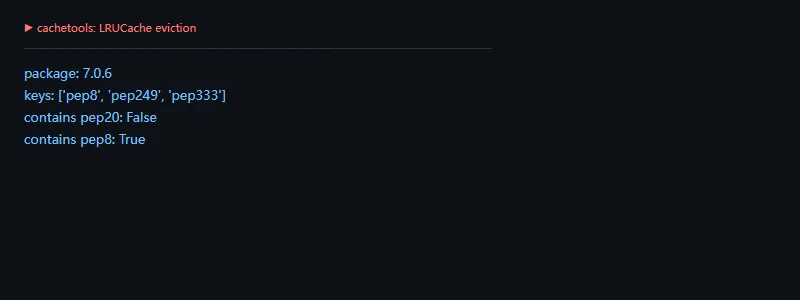
第一段代码解决的问题是:用 LRUCache 控制缓存容量,并验证最近使用的 key 会被保留,较久未使用的 key 会被淘汰。
fromcachetoolsimportLRUCachefromimportlib.metadataimportversioncache=LRUCache(maxsize=3)forkeyin["pep8","pep20","pep249"]:cache[key]=key.upper()_=cache["pep8"]cache["pep333"]="WSGI"print("package:",version("cachetools"))print("keys:",list(cache.keys()))print("contains pep20:","pep20"incache)print("contains pep8:","pep8"incache)
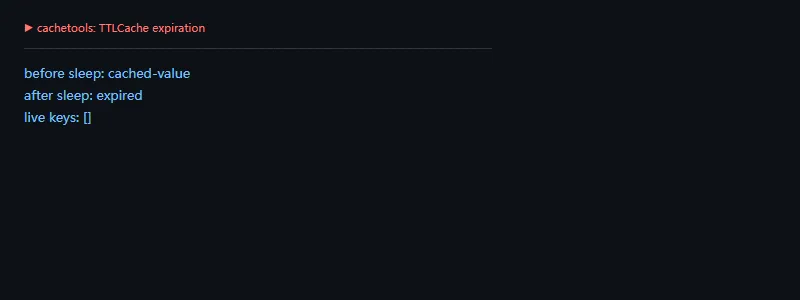
第二段代码解决的问题是:用 TTLCache 给值设置生命周期。它适合缓存短时间有效的 token、配置、接口结果或临时状态。
importtimefromcachetoolsimportTTLCachecache=TTLCache(maxsize=2,ttl=1)cache["token"]="cached-value"print("before sleep:",cache.get("token"))time.sleep(1.2)print("after sleep:",cache.get("token","expired"))print("live keys:",list(cache.keys()))
环境与版本信息
本文示例使用 Python 3.11.0,cachetools 7.0.6。示例全部是进程内缓存,不需要 Redis、Memcached 或数据库服务。
高级功能
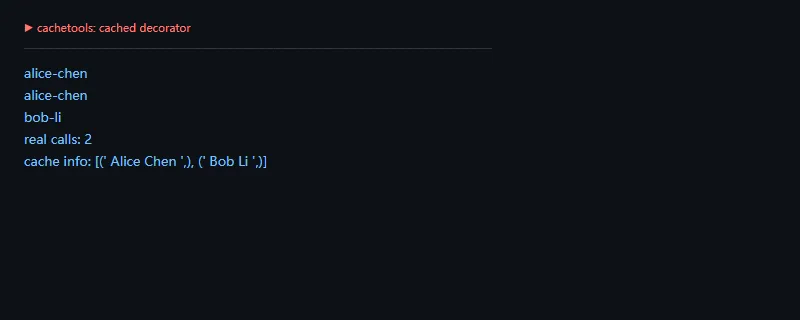
进阶一点看装饰器缓存。cached 很适合包住输入稳定、输出可复用的函数,例如格式归一化、轻量配置查询、规则匹配和较慢的纯计算。要注意的是,缓存 key 默认来自函数参数,如果参数里有不可哈希对象,就要显式设计 key 函数。
fromcachetoolsimportcached,LRUCachecalls={"count":0}@cached(cache=LRUCache(maxsize=4))defnormalize_user(name):calls["count"]+=1returnname.strip().lower().replace("","-")print(normalize_user(" Alice Chen "))print(normalize_user(" Alice Chen "))print(normalize_user(" Bob Li "))print("real calls:",calls["count"])print("cache info:",list(normalize_user.cache.keys()))
适用场景
适合本地热点数据、短生命周期接口结果、重复计算结果、配置读取、函数级 memoization,以及不想为了小缓存额外部署 Redis 的工具型项目。
不适用场景
不适合多进程共享缓存、跨机器一致缓存、需要持久化恢复、需要复杂失效通知、或者缓存命中必须被集中观测和统一治理的生产场景。
上线检查
- 给缓存设置明确的
maxsize 或 ttl,不要让进程内存无限增长。 - 对缓存 key 做测试,避免不同用户或不同权限的数据被错误复用。
- 评估多进程部署下的缓存一致性,必要时改用 Redis 这类共享缓存。
总结
cachetools 的价值在于把缓存策略做得足够简单。小到一个函数,大到一组本地热点数据,只要边界清楚,它能用很少代码换来稳定的性能收益。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
