术语使用申明
文中多处出现 BPF、eBPF 混用表述,统一说明如下:
cBPF 指代经典伯克利包过滤,是早期专为网络数据包过滤设计的实现;eBPF 即扩展伯克利包过滤,是现代 Linux 内核通用可编程执行框架;上下文无歧义时,会简写为 BPF 统称整套技术体系,不再刻意区分 cBPF 与 eBPF;涉及历史演进、功能差异、代码类型时,将严格区分 cBPF、eBPF,避免概念混淆。
引言:为什么同类性能工具多达十余种?
在 Linux 问题排查与性能观测中,同一类场景往往对应多款工具:磁盘 I/O 分析有 iostat、iotop、blktrace、biolatency;网络观测可选择 ss、tcpdump、tcpretrans、sar。很多人疑惑:功能相近的工具为何需要重复存在?
答案并非功能冗余,而是底层数据采集链路与计算位置截然不同。
传统观测工具普遍采用「内核原始数据透出 + 用户态二次计算」模式:iostat 读取 /proc 虚拟文件系统的全局计数器,ss 基于 netlink 套接字拉取内核套接字信息,tcpdump 依靠内核抓包机制获取原始报文。数据原样输出后,过滤、统计、分析全部在用户态完成。
以 eBPF 实现的 biolatency、tcpretrans 等工具则采用全新架构:将自定义逻辑注入内核,在事件产生的瞬间完成过滤、聚合、延迟统计,仅把加工后的轻量化结果导出至用户态。
同一个硬件/内核事件,经由不同链路采集后,数据粒度、时间精度、信息完整性都会产生明显差异。一款工具能做什么、不能做什么,上限由其数据通路决定。
本文将拆解 Linux 性能数据从「内核事件产生 → 内核预处理 → 数据导出 → 用户态消费」的完整分层体系,帮你理解各类工具的底层逻辑,实现精准选型。
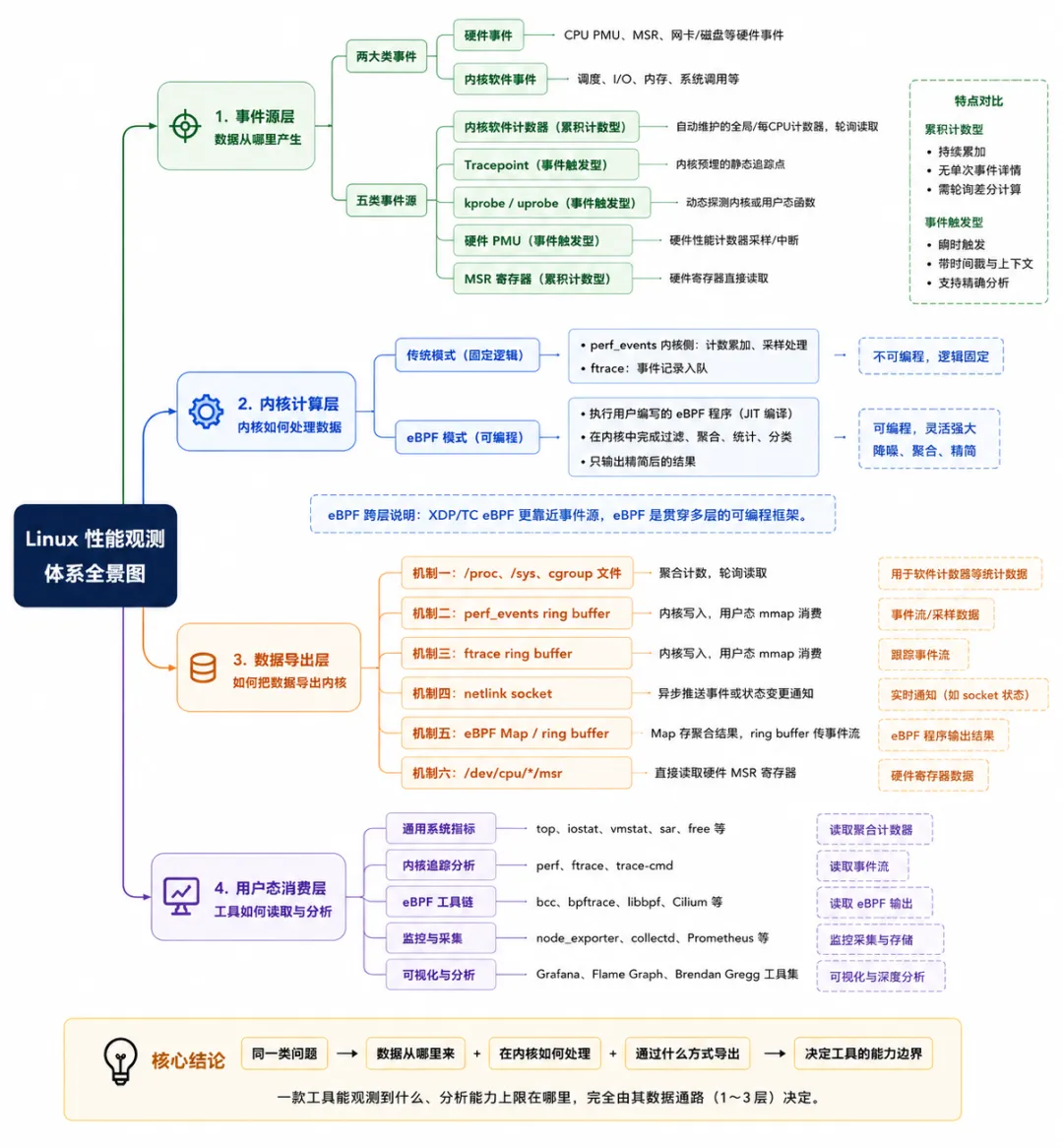
一、Linux 性能观测四层体系
第一层:事件源层
所有性能数据的起点,分两类:
Tracepoint、kprobe 是埋设在内核代码关键路径上的触发接口,是第一层与第二层的边界——事件在第一层发生,注册的处理逻辑在第二层执行。
特点:纳秒级触发,要求回调开销极低。
第二层:内核计算层
事件触发后,注册的处理程序在内核上下文同步执行,是传统工具与 eBPF 工具的核心分水岭:
关于 eBPF 的跨层说明:eBPF 并不只属于本层。XDP 程序挂载在网卡驱动的 NAPI poll 路径,TC eBPF 在协议栈入口,两者的执行时机比多数内核软件事件更早,更靠近第一层。准确地说,eBPF 是一个纵向贯穿多层的可编程框架,第二层是其最主要、最典型的执行场景。
第三层:数据导出层(按数据形态 & 通道大类归类)
第二层处理结果透出到用户态的通道,定义数据格式与访问接口:
| | |
|---|
| /proc、/sys | |
| perf_events ring buffer、ftrace ring buffer | |
| eBPF Map、eBPF ring buffer | Map 存聚合结果,ring buffer 传事件流;计算本身发生在第二层 |
| | |
异步推送:基于事件驱动模型,用户态进程提前向内核订阅指定事件,内核在事件发生后主动将数据推送至用户态,进程无需循环轮询查询。该模式实时性更强、CPU 开销更低,是 netlink 接口最核心的特性,广泛用于网络状态、系统审计、设备热插拔等实时监控场景。
第四层:用户态消费层
读取第三层数据,完成格式化、分析、可视化与告警:
| |
|---|
| top、iostat、vmstat、sar |
| perf、ftrace、trace-cmd |
| bcc、bpftrace、libbpf |
| Prometheus node_exporter、collectd |
| |
工具能力上限由它所消费的数据源决定——无论逻辑多精妙,都无法获得数据源里没有的信息。
二、五类内核事件源
与四层体系的对应关系
本章聚焦第一层(事件源层),说明性能数据从哪里产生、由哪种机制触发。第三章将对应介绍第三层(数据导出层)的六种机制 —— 同一套数据,两章分别从 "产生" 和 "导出" 两个维度切入。
按数据产生的形态,五类事件源可分为两大组别:
下表给出五类事件源在四层体系中的完整定位,也是两章内容的衔接索引:
*------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| 事件源 | 第一层:事件产生 | 第二层:内核计算 | 第三层:导出接口 | 第四层:用户态工具 |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| 内核软件计数器 | 调度/I/O/内存累计计数 | 无 | /proc、/sys、cgroup(机制一) | iostat、vmstat、top |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| Tracepoint | 第一/二层边界触发点 | ftrace/perf/eBPF 回调 | ftrace RB(机制三) | perf、trace-cmd || | | | perf RB(机制二) | bcc、bpftrace || | | | eBPF Map(机制五) | |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| kprobe / uprobe | 第一/二层边界触发点 | 同上 | perf RB(机制二) | perf probe || | | | eBPF Map(机制五) | bcc、bpftrace |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| 硬件 PMU | PMU硬件计数器 | perf_events采样处理 | perf RB(机制二) | perf、bcc profile |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+| MSR(x86) | MSR硬件寄存器 | 无 | /dev/cpu/*/msr(机制六) | turbostat、perf stat |+------------------------+------------------------------------------+--------------------------------+----------------------------------------------+---------------------------+
2.1 累积计数型事件源
事件源一:内核软件计数器
内核在执行关键路径时,自动维护一系列全局和 per-CPU 的累积计数器,无需任何激活操作,始终在运行。这是性能数据中最古老、开销最低的产生方式。
在四层体系中的位置:计数器更新本身属于第一层——调度器在上下文切换时更新 CPU 时间计数,块层在 I/O 完成时更新吞吐量计数,内存子系统在缺页时更新缺页计数。这些计数器通过 /proc、/sys 和 cgroup 统计文件导出到用户态,后者属于第三层,详见第三章机制一。本节只说明内核跟踪了哪些数据,以及这类计数器的能力边界。
内核跟踪的代表性计数器
PSI(压力停顿信息)
Linux 4.20 引入的 PSI(Pressure Stall Information)是一类特殊的软件计数器,通过 /proc/pressure/ 导出,是目前最准确的系统压力指标。与上述利用率计数器不同,PSI 直接测量"有任务在等待资源"的时间比例:
三个维度各提供 10s、60s、300s 三个滑动窗口均值。Facebook 大规模部署的 oomd、systemd 资源控制均以 PSI 为核心信号,是比 %iowait 或 %util 更直接的压力度量。
cgroup 分组计数器(v1 与 v2 有区别)
cgroup 子系统在内核中为每个控制组独立维护一套资源计数,是容器化环境按容器维度观测资源的数据基础。v1 和 v2 的计数器路径和格式不同:
cgroup v1(旧的多层级结构):
- CPU:
/sys/fs/cgroup/cpu/<group>/cpu.stat - 内存:
/sys/fs/cgroup/memory/<group>/memory.stat - 块 I/O:同时提供原生 I/O 统计
blkio.io_service_bytes(实际 I/O 量)和限流统计 blkio.throttle.io_service_bytes(受限流策略影响的 I/O),两者含义不同,没有统一的 io.stat
cgroup v2(统一层级,现代发行版默认):所有控制器集中在 /sys/fs/cgroup/<group>/ 下,重要文件包括 cpu.stat、memory.stat、io.stat(v2 专有,统一了 v1 的多个分散文件)。
主流发行版(Fedora 31+、Ubuntu 21.10+、RHEL 9+)和 Kubernetes 1.25+ 均已默认采用 cgroup v2。cadvisor、docker stats 等工具会自动适配所在系统的 cgroup 版本。
这类事件源的能力边界
内核软件计数器的核心特征是:数据是聚合的(累积计数而非单次事件),是定期轮询的(工具需差分计算速率),是预先定义的(内核开发者决定暴露哪些字段)。无法获取单次事件的时间戳、调用栈和上下文——这是它与后三类插桩型事件源的根本差异,也是为什么同一个问题需要多种工具的核心原因之一。
事件源二:MSR 寄存器(x86/x86-64 专有)
架构限制:本事件源为 x86/x86-64 专有。ARM64 不存在 MSR 机制,RAPL 能耗统计不可用,turbostat 不支持 ARM64。ARM64 的能耗和频率信息需通过 hwmon(/sys/class/hwmon/)、ACPI CPPC 或芯片厂商专有接口获取,无统一标准。
CPU 内部的 Model Specific Registers 存储了 PMU 无法直接暴露的硬件状态:RAPL 能耗计数器(Running Average Power Limit)、当前频率、温度传感器等。这是第一层的硬件数据来源。
在四层体系中的位置:在四层体系中的位置:MSR 寄存器是第一层的硬件状态;/dev/cpu/N/msr 设备文件是第三层的导出接口(详见第三章机制三);读取工具属于第四层。与 PMU 不同,MSR 没有第二层的内核侧预处理,用户态工具直接读取原始寄存器值。MSR 同时出现在本章(第一层:数据来源)和第三章(第三层:访问接口),是因为它的数据产生和接口访问都有独立讨论价值。
实际使用中的常见限制:访问需要 root 权限;主流云虚拟机出于安全隔离通常会屏蔽 MSR 访问(/dev/cpu/*/msr 不可读或返回全零);RAPL 能耗统计在 Intel 平台支持最完整,AMD 从 Zen 架构起提供部分支持,但字段和精度与 Intel 有差异。
典型使用工具:
在分析功耗相关的性能问题(如 CPU 因温度限制而降频、服务器节能策略导致的延迟抖动)时,这个事件源是不可替代的。
2.2 事件触发型事件源
事件源三:Tracepoint(静态内核插桩)
Tracepoint 是内核开发者在代码中主动放置的静态观测点,通过 TRACE_EVENT 宏定义,存在于调度器、内存管理、文件系统、网络协议栈等核心子系统的关键位置。
在四层体系中的位置:Tracepoint 的触发点是第一层与第二层的边界——事件在第一层发生,注册的处理回调(ftrace、perf_events、eBPF 程序)在第二层执行,结果写入 ring buffer 或 eBPF Map 属于第三层。
未激活时,Tracepoint 是一条 nop 指令,开销极低(纳秒级)。激活后通过 jump label 机制替换成 jmp,跳转到追踪回调。
一个容易被忽视的关键设计:Tracepoint 是事件生产者,ftrace ring buffer 和 perf_events 是两条独立的消费渠道,接在同一个事件源上。
perf record -e sched:sched_switch
trace-cmd record -e sched:sched_switch
追踪的是完全相同的内核 Tracepoint,只是数据分别写入 perf ring buffer 和 ftrace ring buffer。工具可以同时注册,同一个 Tracepoint 被触发时,两个 ring buffer 都会收到数据。eBPF 程序也可以 attach 到 Tracepoint 上,三种消费方式可以并存。
所有可用的 Tracepoint 可通过 /sys/kernel/debug/tracing/events/ 目录查看。重要分类如下:
Tracepoint 的核心价值是稳定性:内核开发者承诺一旦加入就不会以不兼容的方式变更(ABI 稳定性),因此基于 Tracepoint 编写的工具可以在不同内核版本之间稳定工作。而基于 kprobe 追踪内核函数的工具在内核版本升级后可能需要修改。
事件源四:kprobe / uprobe(动态插桩)
kprobe 可以在内核任意函数的入口或返回处动态插入观测点,不需要内核预先埋点。
在四层体系中的位置:与 Tracepoint 相同——触发点在第一/二层边界,回调执行在第二层,数据出口在第三层。与 Tracepoint 的区别在于:kprobe 是动态的、覆盖范围更广、但稳定性更低。
在 x86/x86-64 上,其基础机制是将目标函数的第一个字节替换成 int3(软件断点,0xCC);内核会同时备份目标函数前若干字节的原始指令,防止 int3 破坏跨字节的指令边界。触发时调用注册的处理函数。在 ARM64 上则使用 BRK 指令完成相同的拦截。此外,内核还支持 jump optimization:在条件允许时,将 int3 升级为直接的 5 字节 JMP 指令(仅 x86),减少软件中断路径的开销。uprobe 对用户态程序做同样的事情。
kprobe 的覆盖范围是 Tracepoint 无法比拟的——内核里有数万个函数,Tracepoint 只覆盖了其中数百个关键位置。需要追踪 Tracepoint 没有覆盖的内核行为时(比如追踪某个特定的内存分配路径、追踪某个驱动函数),kprobe 是唯一选择。
代价是不稳定性:内核函数是内部实现细节,随时可能在版本之间改名、参数变化、被内联而消失。基于 kprobe 追踪的工具需要随内核版本维护。
kprobe 和 uprobe 事件也可以注册到 perf_events 子系统(通过 perf probe 命令动态添加)或由 eBPF 程序直接 attach,两条消费路径同样并存。
USDT(User Statically Defined Tracing)是在 Linux 上基于 uprobe 实现的用户态静态追踪规范:应用程序开发者在源码中主动埋设静态观测点,通过 semaphore 机制保证未激活时完全零开销,且不受函数内联、版本改名的影响,稳定性远优于普通 uprobe。MySQL、PostgreSQL、Node.js、Python 等应用内置了大量 USDT 探针,是应用层追踪的最优数据源。
事件源五:硬件 PMU 计数器
CPU 内部的 PMU(Performance Monitoring Unit)是性能计数器的硬件实现,直接在硬件层面计数各种微架构事件,不需要任何软件插桩。
在四层体系中的位置:PMU 硬件计数器本身属于第一层(事件源层);perf_events 内核侧的采样与缓冲属于第二/三层;perf 命令行工具属于第四层。
固定计数器(总是可用):总指令数(instructions retired)、总时钟周期数(CPU cycles)、参考时钟周期数(不受频率缩放影响)。从这三个计数器可以计算 IPC(每时钟周期指令数),是判断 CPU 微架构效率的核心指标。
可编程计数器(型号相关):末级缓存缺失(LLC-misses)、分支预测失败(branch-misses)、TLB 缺失(dTLB-load-misses)等。具体支持的事件因 CPU 厂商和型号而异。
PMU 的使用有两种模式:
PMU 数据通过 perf_events 子系统导出给用户态。eBPF 程序也可以 attach 到 PMU 采样事件上(BPF_PROG_TYPE_PERF_EVENT 程序类型),在每次采样时在内核态执行自定义逻辑——这正是 BCC profile 工具实现 On-CPU profiling 的机制基础。
关于 BCC profile 工具的采样机制:profile 默认以 PERF_TYPE_SOFTWARE / PERF_COUNT_SW_CPU_CLOCK(软件时钟事件)触发,并非硬件 PMU 溢出。软件时钟在所有架构上均可用,且不占用有限的 PMU 硬件计数器槽位。perf record -e cycles 才是使用硬件 CPU cycles 计数器的 PMU 采样。两者的采样精度和适用场景有区别,不应混淆。
关于 99Hz 的选择:频率选择 99 而非 100,是为了避免与内核定时器中断产生相位锁定(resonance)。内核定时器频率(CONFIG_HZ)常见值为 100、250、1000,若采样频率与其完全对齐,采样会反复落在相同代码位置(如 do_timer()),导致火焰图严重失真。99 是行业惯例;同理,也有使用 249Hz、499Hz 等与常见 CONFIG_HZ 值互质的频率,出于完全相同的考量。
x86_64 与 ARM64 的差异:PMU 事件名称和编码在两个架构上完全不同。x86_64 使用 Intel/AMD 格式(如 cycles、LLC-load-misses、r4f2e),ARM64 使用 PMUv3 标准格式(如 armv8_pmuv3_0/cpu_cycles/、armv8_pmuv3_0/l2d_cache_refill/)。perf list 的输出在两个平台上差异显著,跨平台编写 perf 脚本时须参照目标平台的事件名。Tracepoint、kprobe 类事件名与架构无关,两平台一致。
三、内核数据导出的六种机制
对应第一层的两类数据形态,六种导出机制可分为两大组别:
机制一:虚拟文件系统(/proc、/sys)
最古老、最通用的导出机制。内核维护内存中的数据结构,/proc 和 /sys 把这些结构以虚拟文件的形式呈现。读取这些文件触发内核的读处理函数,把数据序列化成文本返回给用户态。
优点:接口极其简单,任何语言、任何工具都能访问;不需要特殊权限(大部分文件对所有用户可读);数据始终可用,没有缓冲区满的问题。
缺点:数据是聚合的历史累积,没有单次事件的详细信息;轮询开销不低(文本解析、频繁读文件);内容由内核开发者预先定义,不能自定义要看哪些数据。
适用工具:top、vmstat、iostat、netstat、free、sar、dstat 等所有传统命令行工具,以及大多数监控系统的数据采集 agent(Node Exporter、Prometheus 等)。cgroup 统计(cadvisor、docker stats)和 PSI 监控也走这条路。
机制二:netlink socket
netlink 是内核和用户态之间专为网络子系统设计的通信机制,支持双向通信(用户态可以查询内核,内核也可以主动通知用户态)。
ss 命令:ss使用 netlink 获取 socket 信息,比 netstat 读取 /proc/net/tcp 快得多(避免了文本解析,且 netlink 支持按条件过滤,不需要把所有 socket 信息都传到用户态)。ip 命令、iproute2 工具集通过 netlink 查询和配置路由、地址、接口等。
Taskstats:这是 netlink 在性能领域另一个重要但常被忽视的用途。Taskstats 是内核通过 netlink 导出进程级别任务统计数据的专用协议,提供比/proc/PID/io更完整的进程 I/O 统计——特别是对已退出进程的计,/proc在进程退出后就看不到数据了,而 Taskstats 可以在进程退出时捕获完整统计。iotop主要通过 Taskstats netlink 接口(而非/proc/PID/io)获取进程级 I/O 数据,atop等 accounting 工具也依赖这个接口。
网络事件通知:当网络接口状态变化(link up/down)、路由变化时,内核通过 netlink 主动通知感兴趣的用户态进程(NetworkManager、systemd-networkd 等监听这些通知)。
机制三:MSR 寄存器接口
架构限制:本机制为 x86/x86-64 专有。 ARM64 平台不存在 /dev/cpu/*/msr 接口,RAPL 能耗统计不可用,turbostat 不支持 ARM64。ARM64 的能耗和频率信息需通过 hwmon(/sys/class/hwmon/)、ACPI CPPC、或芯片厂商提供的专有接口获取,无统一标准。
通过 /dev/cpu/N/msr 设备文件直接读写 CPU 的 Model Specific Registers,访问 PMU 无法直接暴露的硬件信息:RAPL 能耗计数器、当前频率、温度等。需要 root 权限,数据格式与 CPU 型号强绑定。
实际使用中的常见限制:主流云虚拟机出于安全隔离通常会屏蔽 MSR 访问(/dev/cpu/*/msr 不可读或返回全零);RAPL 能耗统计在 Intel 平台支持最完整,AMD 从 Zen 架构起提供部分支持,但字段和精度与 Intel 有差异。
turbostat 是这个接口最典型的消费者,能展示每个 CPU 核的实时频率、功耗、温度、C-state 停留时间,是分析 CPU 频率缩放和热量限制(thermal throttling)问题的核心工具。perf stat 的能耗事件(-e power/energy-pkg/)在底层同样依赖 RAPL MSR。
3.2 事件流类通道
机制四:perf_events 子系统
perf_events 是 Linux 2.6.31 引入的统一性能监控接口,通过 perf_event_open() 系统调用访问。它的核心价值在于提供了一个统一的事件订阅框架,把多种异构的事件源(PMU 硬件计数器、Tracepoint、kprobe、uprobe)统一成同一种接口:打开一个 perf_event fd,内核把采样数据写入 mmap 的环形缓冲区,用户态从缓冲区读取。
perf_events 是一个多消费者的框架,以下几类工具都通过它访问事件:
perf 命令行工具:直接使用 perf_event_open(),数据写入 perf.data 文件后离线分析,或实时展示统计数据。
eBPF 程序:BPF_PROG_TYPE_PERF_EVENT 类型的 BPF 程序可以 attach 到任意 perf_event 上,在事件触发时执行自定义的内核态逻辑。BCC profile(On-CPU profiling)就是这样工作的:用 perf_events 设置 99Hz 的软件时钟事件,每次触发 BPF 程序采集调用栈并更新 Map。eBPF 在这个场景里是 perf_events 的消费者,而不是与 perf_events 并列的独立机制。
BPF_MAP_TYPE_PERF_EVENT_ARRAY:这是 eBPF ring buffer 出现(5.8+)之前,BPF 程序把事件数据传给用户态的主要方式——BPF 程序把数据写入 per-CPU 的 perf ring buffer,用户态通过 perf_events 接口读取,顺序不保证,需要为每个 CPU 分别读取。ring buffer 是在此基础上更高效的替代方案(全局共享、保序、支持两阶段提交),但 PERF_EVENT_ARRAY 仍然广泛存在于旧的 BCC 工具里。
x86_64 与 ARM64 的差异:PMU 硬件事件名称和编码在两个架构上完全不同。x86_64 使用 Intel/AMD 的事件名(如 cycles、LLC-load-misses、r4f2e),ARM64 使用 PMUv3 标准事件(如 armv8_pmuv3_0/cpu_cycles/、armv8_pmuv3_0/l2d_cache_refill/)。perf list 的输出在两个平台上差异显著,跨平台编写 perf 脚本时必须参照目标平台的事件名。Tracepoint、kprobe、uprobe 类事件名称与架构无关,在两个平台上保持一致。
机制五:ftrace ring buffer
ftrace 是内核内置的追踪框架,通过 /sys/kernel/debug/tracing/ 目录下的文件接口控制。它维护一个每 CPU 的环形缓冲区,内核的追踪事件直接写入这个缓冲区,用户态通过读取 trace 文件获取数据。
ftrace ring buffer 和 perf_events ring buffer 都可以消费 Tracepoint 事件,两者是同一事件源的两个订阅渠道,可以并存,不冲突。选择哪个渠道取决于使用工具:trace-cmd 用 ftrace 渠道,perf 用 perf_events 渠道,eBPF 程序两个渠道都可以用。
ftrace 的独特功能是 function tracer 和 function_graph tracer:可以追踪内核函数的调用顺序和执行时间,直观地看到内核代码的执行路径(类似程序员熟悉的调用树)。这是 perf 和 BPF 都无法直接提供的能力。
ftrace 的主要用途:
值得注意的是,perf ftrace 子命令可以直接调用 ftrace 的 function tracer 能力,两者的边界在这里有交叉。
x86_64与ARM64 的差异:function tracer 的底层插桩机制在两个架构上实现不同。x86_64 使用 fentry 方案——编译器在每个函数入口插入 5 字节 call __fentry__,未激活时替换为 5 字节 NOP,激活时直接原地 patch 回 call 指令,切换开销极低。ARM64 使用 -fpatchable-function-entry=2 方案——编译器在每个函数入口处插入两条 NOP 指令(函数符号指向第一条 NOP,共 8 字节),激活时将第一条 NOP patch 为 BL 跳转至 ftrace trampoline,第二条 NOP 保留或用于 FTRACE_WITH_REGS、live patch 等扩展功能。由于 ARM64 指令定长(4 字节),patch 操作天然对齐;两个独立指令槽位(共 8 字节)比 x86_64 的单个 5 字节槽位提供了更多扩展空间。
使用 ftrace ring buffer 的工具:trace-cmd(ftrace 的命令行前端)、kernelshark(trace-cmd 的 GUI)。
机制六:eBPF Maps 和 ring buffer
BPF Map 是驻留在内核中的数据结构,BPF 程序通过 helper 函数读写,用户态通过文件描述符和 bpf() 系统调用访问。这是 eBPF 程序向用户态输出数据的核心接口——BPF 程序在内核态完成计算后,把结果写入 Map,用户态定期或按需读取,两侧通过同一块内核内存通信。
聚合结果的导出——Hash / Array Map:适合在内核态累积计算结果再一次性读取的场景。BPF 程序以调用栈、PID、设备号等为 key,在 Map 里做计数或求和;用户态程序定期遍历整张 Map,拿到已经聚合好的统计表,不需要处理原始事件流。biolatency、runqlat 等工具都用这种模式。
事件流的导出——两种 ring buffer:
BPF_MAP_TYPE_PERF_EVENT_ARRAY(旧方式):每个 CPU 独立一块 perf ring buffer,BPF 程序调用bpf_perf_event_output()写入,用户态通过 perf_events 接口按 CPU 分别轮询读取。事件全局顺序无法保证,且内存按 CPU 数量线性增长。
BPF_MAP_TYPE_RINGBUF(5.8+ 新方式):单一全局共享缓冲区,所有 CPU 的 BPF 程序竞争写入同一块内存,事件顺序有保证。写入分两步:reserve预留空间(此时用户态不可见),填充数据后commit提交,失败则discard,避免写入一半的脏数据被用户态读到。支持epoll,用户态可以事件驱动地读取,无需忙轮询。新代码推荐使用。
代表性工具:bpftrace、BCC 工具集(biolatency、tcpretrans、runqlat 等)、Cilium、Falco、Tetragon。
四、数据源之间的依赖与复用
这是理解整个 Linux 可观测性工具体系的核心关键,也是最容易被忽视的底层逻辑。各类数据源与导出机制之间并非独立并列的关系,而是存在明确的分层依赖和多路复用关系。
Tracepoint是核心生产者,ftrace、perf_events 和eBPF是并行消费渠道
Tracepoint 是内核预先埋好的稳定插桩点,采用发布-订阅模式工作。同一个 Tracepoint(如进程调度事件 sched:sched_switch)触发时,所有已注册的消费者都会同时收到事件通知,彼此完全独立、互不干扰。
内核 Tracepoint 触发├─ 已订阅 ftrace → 事件写入 ftrace ring buffer → trace-cmd 读取解析├─ 已订阅 perf_events → 事件写入 perf ring buffer → perf 工具读取解析└─ 已 attach BPF 程序 → 直接执行 BPF 处理逻辑 → 数据写入 BPFMap/RingBuf → bpftrace/BCC 读取
核心特性:同一个 Tracepoint 在内核中只有一个代码插桩点,但可以同时被多个观测者订阅。这意味着可以同时运行 trace-cmd、perf record 和 bpftrace 追踪同一个事件,不会产生额外的插桩开销。
perf_events 是 eBPF 的关键触发与数据传输机制
eBPF 不仅可以直接消费 Tracepoint 和 kprobe/uprobe 事件,还与 perf_events 子系统深度融合,后者是 eBPF 实现采样类观测和高性能数据传输的基础。
使用 99Hz 而非 100Hz,是为了避免与内核定时器频率(CONFIG_HZ 常见值为 100、250、1000)产生相位锁定,防止采样反复落在相同代码位置导致火焰图失真。
kprobe 和 uprobe 的双重消费路径
kprobe(内核动态插桩)和 uprobe(用户态动态插桩)同样支持多路复用,可以被 perf_events 和 eBPF 两种方式独立消费:
关键区别:两者追踪的是同一个内核插桩点,但数据处理能力不同。perf probe 主要用于记录原始事件并提供基础过滤功能;eBPF 支持在内核态进行复杂的过滤、聚合、计算和状态维护,大幅减少需要传输到用户态的数据量。
cBPF:eBPF 的历史前身,至今仍在广泛运行
tcpdump 和 libpcap 使用的 BPF 其实是 cBPF(Classical BPF,经典 BPF)。这项技术最早于 1992 年在 BSD 系统中诞生,Linux 内核在 2.2 版本(1999 年)引入,比 eBPF 早了 15 年,也是 eBPF 名称中「BPF」的来源。
cBPF 专门用于网络数据包过滤,运行在 AF_PACKET socket 的数据包接收路径上。其核心作用是让用户在内核态指定过滤规则(如「只捕获目标端口 80 的 TCP 包」),只有符合规则的数据包才会被复制到用户态,极大降低了数据包捕获的系统开销。
tcpdump 完整工作流程:
用户输入过滤表达式(如 tcp port 80 and host 192.168.1.1) → libpcap 将表达式编译为 cBPF 字节码 → 通过 SO_ATTACH_FILTER socket 选项将字节码加载到内核 → 内核在每个收到的数据包上执行 cBPF 过滤 → 符合条件的数据包通过 AF_PACKET socket 复制到用户态 → tcpdump 解析并展示
现代内核的融合:从 Linux 3.18 开始,内核会自动将 cBPF 程序转换为 eBPF 字节码执行,共享同一套验证器和 JIT 编译引擎。cBPF 和 eBPF 是同一内核 BPF 子系统的两种前端接口。
历史演进:cBPF(1992,BSD 包过滤)→ Linux cBPF(1999,Linux 2.2)→ eBPF(2014,Linux 3.18,通用可编程内核扩展)
核心关系全景总结
# Tracepoint 多路消费(数据从左向右流动)Tracepoint → ftrace ring buffer → trace-cmdTracepoint → perf ring buffer → perf 工具Tracepoint → eBPF 程序 → BPF Map/RingBuf → bpftrace/BCC# 动态插桩多路消费kprobe/uprobe → perf ring buffer → perf 工具kprobe/uprobe → eBPF 程序 → BPF Map/RingBuf → bpftrace/BCC# perf_events 触发与采样PMU 硬件 → perf_events 采样 → perf stat/recordSW_CPU_CLOCK → perf_events 采样 → eBPF 程序(On-CPU 剖析)→ BPF Map# 网络相关 BPFAF_PACKET → cBPF 过滤 → tcpdump/libpcap(符合条件的包)XDP Hook → eBPF 程序 → BPF Map/转发/丢弃(网卡驱动层)TC Hook → eBPF 程序 → BPF Map/流量控制(协议栈流量控制层)
五、工具与数据源的完整映射
/proc 和 /sys 工具族(聚合计数器消费者)
共同特征:周期性读取 /proc 或 /sys 文件,做差分计算速率,展示聚合指标。数据是内核预定义的计数器,无法自定义观测维度。
vmstat:组合读取 /proc/stat(CPU)、/proc/vmstat(内存分页事件)、/proc/diskstats(I/O)、/proc/meminfo(内存用量),每行是多个文件的聚合展示。
iostat:读取 /proc/diskstats,计算每个块设备的 IOPS、带宽、utilization、await、avgqu-sz。只能看块设备层的聚合平均值,无法看单次 I/O 的延迟分布。
sar:定期读取几乎所有 /proc 文件并保存历史,覆盖面最广,适合查询历史趋势。
netstat:解析 /proc/net/tcp、/proc/net/udp 等文本文件。socket 数量多时极慢,推荐以 ss 替代。
ss:通过 netlink socket 直接查询内核 socket 状态,速度远快于 netstat,支持条件过滤,是查询连接状态的推荐工具。
iotop:主要通过 Taskstats netlink 接口获取进程级 I/O 统计,辅以 /proc/PID/io。Taskstats 比 /proc/PID/io 更完整,能追踪已退出进程的数据。
slabtop:读取 /proc/slabinfo,展示内核 slab 缓存使用情况,是发现内核内存异常增长的入口工具。
numastat:读取 /sys/devices/system/node/ 下的统计,展示每个 NUMA 节点的内存分配命中/未命中,是排查跨节点内存访问性能问题的第一步。
perf 工具族(perf_events 消费者)
通过 perf_event_open() 访问 perf_events 子系统,数据经 mmap 环形缓冲区传递,支持高频采样。
perf stat:以计数模式访问 PMU,统计指令数、时钟周期、LLC 缺失等硬件事件,计算 IPC 和缓存命中率。与 vmstat 的本质区别:vmstat 读取 /proc/stat 的软件估算值,perf stat 读取 CPU 硬件计数器的精确值。
perf record:以采样模式访问 PMU 或 Tracepoint,每 N 次事件采样一次调用栈,写入 perf.data。perf record -F 99 -ag 是生成 On-CPU 火焰图的标准命令。
perf annotate:将 perf record 采样数据注释到源码和汇编指令层面,可精确到哪条汇编指令最热,是 BPF 工具无法提供的粒度。
perf probe:在内核或用户态任意位置动态添加 kprobe/uprobe,通过 perf_events 导出,使 perf 能追踪 Tracepoint 未覆盖的内核函数。
perf ftrace:调用 ftrace function tracer 能力,在 perf 接口下追踪内核函数调用树,是 perf 与 ftrace 两个子系统的交叉点。
perf sched:基于 sched:* Tracepoint,分析调度延迟、进程等待时间、CPU 迁移。perf sched latency 汇总各进程的最大/平均调度延迟,是识别调度抖动根因的核心命令。
perf mem:利用硬件采样能力(Intel PEBS、AMD IBS)在硬件层面采样内存访问,精确区分 L1/L2/L3 cache hit 和 DRAM 访问,定位内存访问热点。依赖 CPU 厂商的精确采样特性支持。
perf c2c:检测多核程序中的伪共享(false sharing)和 NUMA 跨节点访问,精确定位频繁被多线程竞争访问的 cache line 及对应代码位置。
perf lock:基于 lock:* Tracepoint 统计内核锁的竞争情况(持锁时间、等待时间、竞争次数),是诊断内核锁竞争瓶颈的专用工具。
perf trace:通过 syscalls: Tracepoint 实现系统调用追踪,开销约比 strace 低一到两个数量级,可在生产环境有限度使用,格式与 strace 相近。
ftrace 工具族(ftrace ring buffer 消费者)
trace-cmd:ftrace 的命令行前端,封装了 /sys/kernel/debug/tracing/ 下的繁琐文件操作,支持录制 Tracepoint 事件和函数追踪数据,配合 kernelshark 可视化分析。
独特场景:function_graph tracer 可追踪某个内核函数的完整调用子树,看到精确的调用顺序和每个子函数的执行时间,这是 perf 和 BPF 工具均无法直接替代的能力。
latency tracer:irqsoff tracer(中断禁用时长)、preemptoff tracer(抢占禁用时长)、wakeup tracer(最高优先级进程唤醒延迟),是低延迟和实时系统问题诊断的专用工具。
BPF 工具族(eBPF 可编程框架消费者)
通过 kprobe、Tracepoint、uprobe、USDT、PMU/软件时钟事件的任意组合采集数据,在内核态预聚合后通过 BPF Map 或 ring buffer 传给用户态。
biolatency:attach 到 block_rq_issue 和 block_rq_complete(Tracepoint),在内核态计算每次 I/O 延迟并更新直方图 Map。与 iostat 的本质区别:iostat 只能看聚合平均值,biolatency 提供完整延迟分布(含 p99 和长尾)。
tcpretrans:attach 到 tcp_retransmit_skb(kprobe),每次 TCP 重传时记录四元组和进程信息。这类信息在 /proc 里完全不可见,是 BPF 独有的能力。
runqlat:attach 到 sched_wakeup 和 sched_switch(Tracepoint),在内核态计算调度延迟并展示直方图。
offcputime:attach 到 sched_switch(Tracepoint),在进程被调度出 CPU 时记录调用栈、调度回时累积 Off-CPU 时间,生成 Off-CPU 火焰图,用于分析锁等待、I/O 等待等非 CPU 阻塞原因。
profile(On-CPU profiling):通过 perf_events 以 99Hz 触发软件时钟采样(BPF_PROG_TYPE_PERF_EVENT),每次触发时在内核态采集调用栈并更新计数 Map,生成 On-CPU 火焰图。数据处理在 BPF 程序内完成,不经过 perf ring buffer。
网络专项工具族
tcpdump / Wireshark:通过 libpcap 和 AF_PACKET socket 捕获原始数据包。libpcap 将过滤表达式编译为 cBPF 字节码,通过 SO_ATTACH_FILTER 加载到内核,在收包路径上过滤,只将符合条件的数据包复制到用户态。适合协议分析,不适合性能指标分析。
tcpretrans 类 eBPF 工具:追踪 TCP 连接状态变化事件(kprobe),不捕获数据包内容,但可关联到具体进程和调用栈。与 tcpdump 的数据源和适用场景完全不同。
XDP:eBPF 在网卡驱动层的 hook,数据包进入内核协议栈前执行 BPF 程序,无需内存复制,可实现极低延迟的包过滤、转发和负载均衡。Cilium、Katran 等高性能网络组件均大量使用。
ss / netstat:查询当前活跃 socket 状态快照,解答"现在系统有哪些连接",与 tcpdump 的实时流量捕获定位不同。
iperf / qperf:主动发起网络压测,直接测量端到端带宽和延迟,属于主动探测而非被动观测,不依赖任何内核导出接口。
能耗与频率工具族
turbostat:通过 /dev/cpu/*/msr 读取 RAPL 能耗计数器,展示每个 CPU 核的实时频率、功耗、温度、C-state 停留时间。分析因温度过高触发降频导致延迟抖动的核心工具,仅支持 x86/x86-64,云虚拟机环境通常无法访问 MSR。
六、数据源的能力边界
不同数据源在几个关键维度上有明确的能力边界,决定了什么工具能回答什么问题。
时间分辨率
/proc 系工具的时间分辨率受限于轮询频率,通常是秒级。一个持续 100ms 的磁盘延迟毛刺,在 iostat 里会被平摊到整个采样周期,看起来只是 await 轻微升高。
Tracepoint 和 kprobe 有纳秒级时间分辨率,每次事件都有精确时间戳,能捕获并记录示例 100ms 的延迟毛刺及其分布。
PMU 和软件时钟采样的分辨率取决于采样频率,99Hz 意味着约 10ms 的采样间隔——足以用于 CPU profiling,但不足以捕获微秒级事件。
PSI 提供 10s、60s、300s 三个滑动窗口的均值,适合趋势判断,不适合瞬时诊断。
单次事件 vs 聚合统计
/proc 和 /sys 只有聚合统计,没有单次事件的记录。能看到"过去 1 秒平均有 100 次 I/O",但看不到"第 37 次 I/O 的延迟是 800ms"。
Tracepoint、kprobe、PMU 采样都能提供单次事件的记录(时间戳、上下文、调用栈)。BPF 工具可以在内核态对单次事件做阈值过滤(只记录延迟超过 10ms 的那次),避免数据量爆炸。
调用栈(代码路径)信息
/proc 系工具完全没有调用栈信息,只有聚合指标。
perf record 和 BPF 工具可以采集调用栈,把延迟或 CPU 时间分配到具体的代码路径,这是生成火焰图的基础。
调用栈采集的可靠性在内核空间和用户空间有所不同:
内核空间:Linux 4.14 引入 ORC(Oops Rewind Capability)unwinder,不依赖帧指针即可可靠展开内核栈,内核空间的调用栈问题已基本解决。
用户空间:GCC 默认以 -fomit-frame-pointer编译,导致大量用户态程序缺少帧指针,调用栈出现 [unknown]帧,火焰图价值大打折扣。这是发行版层面的工程问题——Fedora 38+、Ubuntu 24.04+ 等已在打包时默认恢复帧指针,但存量程序仍受影响,可用 DWARF 展开(perf record --call-graph dwarf)作为替代,代价是更高的采样开销。
进程级别 vs 系统级别
/proc系工具多为系统级别的全局统计,无法区分是哪个进程触发了某次事件。Taskstats netlink 接口和 BPF 工具可以把事件关联到具体进程,且 BPF 工具能在关联进程信息的同时记录调用栈,把"谁"、"做了什么"、"花了多久"整合到同一条记录里。
跨层关联
这是 BPF 相对于其他所有数据源的独特能力。传统工具每个只看一层:iostat 看块设备层,netstat 看网络层,top 看进程层,各层数据无法关联。
BPF 可以同时在多层插桩,用共享 Map(以进程 ID 或请求 ID 为 key)把不同层的事件串联,回答「这个 MySQL 查询的延迟有多少来自磁盘 I/O、多少来自锁等待、多少来自纯 CPU 计算」这类需要跨层视角的问题。
七、strace 的特殊位置
strace 值得单独讨论,因为它的实现机制与上述所有工具都不同,也是最容易被错误使用的工具。
工作机制与开销
strace 使用 ptrace 系统调用追踪目标进程的系统调用。每当目标进程执行系统调用的进入和返回时,内核暂停目标进程并通知 strace,strace 处理完后内核才恢复目标进程。
每个被追踪的系统调用因此产生两次上下文切换(目标进程 → strace → 目标进程),开销与系统调用频率成正比。对于高频系统调用(如 write、read、sendmsg),这个开销可以让服务吞吐量下降 10 倍以上。
strace 不属于 /proc、Tracepoint 或 kprobe 任何一类,而是通过进程暂停-检查-恢复的方式工作,是所有追踪工具里开销最大的一种。
使用原则
生产环境禁止使用 strace。 需要追踪生产环境系统调用时,应使用:
strace 唯一合理的场景:调试环境下,理解某个程序调用了哪些系统调用(如分析二进制程序行为、调试启动失败原因)。
八、Linux 性能可观测性体系全景
【硬件层】
| |
|---|
| PMU 计数器(指令数、时钟周期、缓存缺失等)、RAPL 能耗、MSR 寄存器 |
| |
| |
| |
【内核事件源层】基于五大类拆分
内核计数器(第一层事件源,通过 /proc /sys /cgroup 导出) └─ 调度、I/O、内存、网络子系统自动维护的累积计数 └─ PSI(Linux 4.20,压力停顿信息,最直接的系统压力指标) └─ cgroup v2 提供统一的 io.stat(v1 需区分 blkio.io_service_bytes 和 throttle.*)Tracepoint → 内核关键路径的稳定静态插桩点(ABI 稳定,跨版本可靠) └─ 多消费者:ftrace ring buffer、perf_events、eBPF 可同时订阅同一插桩点kprobe / uprobe → 任意内核/用户态函数的动态插桩点 └─ x86_64:int3(0xCC)+ jump optimization(5 字节 JMP) └─ ARM64:BRK 指令 + 定长 4 字节 patch └─ 消费方式:perf_events 或 eBPF 直接 attachUSDT → 应用程序主动埋设的用户态静态插桩点,基于 uprobe 实现 └─ semaphore 机制保证未激活时零开销,不受函数内联和版本改名影响 └─ MySQL、PostgreSQL、Node.js、Python 等内置大量探针PMU 硬件计数器 → CPU 微架构级别事件(指令数、LLC 缺失、分支预测失败等) └─ 通过 perf_events 子系统消费(计数模式 / 采样模式) └─ eBPF 可 attach 到 PMU 采样事件(BPF_PROG_TYPE_PERF_EVENT)SW_CPU_CLOCK → 内核软件时钟事件(非 PMU 硬件事件) └─ 触发 eBPF 程序进行 On-CPU profiling(profile 工具的默认采样源)XDP(eXpress Data Path)→ eBPF 在网卡驱动层的 hook └─ 数据包进入协议栈前执行,sk_buff 分配前处理,无内存复制开销 └─ 支持极低延迟的包过滤、转发、负载均衡cBPF(AF_PACKET socket 过滤)→ 经典包过滤机制,eBPF 的历史前身 └─ tcpdump/libpcap 将过滤表达式编译为 cBPF 字节码,在收包路径内核侧过滤 └─ 现代内核自动将 cBPF 转换为 eBPF 字节码执行,共享同一套 JIT 引擎
【内核数据导出层】
/proc /sys 虚拟文件系统 └─ 文本轮询,聚合指标(含 PSI、cgroup v1/v2 stat) └─ 接口简单,无需特殊权限,始终可用;无单次事件详情perf_events 子系统 └─ 统一事件订阅框架,PMU / Tracepoint / kprobe / uprobe 均可注册 └─ 数据经 mmap 环形缓冲区传递;BPF_MAP_TYPE_PERF_EVENT_ARRAY 是旧版 BPF 传输方式ftrace ring buffer └─ 内核函数追踪和 Tracepoint 事件记录 └─ 与 perf_events 消费同一 Tracepoint 事件源,两者可同时订阅,互不干扰 └─ function_graph tracer 可展示完整函数调用子树(perf/BPF 无法直接替代)netlink socket └─ 网络子系统查询(ss)、进程任务统计(Taskstats / iotop)、网络事件通知eBPF Maps + ring buffer └─ 可编程数据处理层:在内核态完成过滤、聚合、变换,只将结果传给用户态 └─ BPF_MAP_TYPE_RINGBUF(5.8+):全局共享、保序、支持 reserve+commit 两阶段写入 └─ BTF/CO-RE(5.4-5.5 实用)保证跨内核版本可移植,无需目标机器内核头文件 └─ Verifier 在程序加载时静态分析,保证有界、内存安全、helper 合法MSR 寄存器接口(x86/x86-64 专有) └─ 能耗(RAPL)、频率、温度数据,通过 /dev/cpu/*/msr 访问 └─ 云虚拟机通常屏蔽;ARM64 无此接口
【用户态工具层】
+----------------------+------------------------------------------------------------------+| 工具体系 | 核心工具列表 / 机制说明 |+----------------------+------------------------------------------------------------------+| /proc 系 | top, vmstat, iostat, sar, netstat, free, slabtop, dstat |+----------------------+------------------------------------------------------------------+| cgroup / PSI 系 | cadvisor, docker stats, systemd-oomd |+----------------------+------------------------------------------------------------------+| NUMA 系 | numastat, numactl |+----------------------+------------------------------------------------------------------+| | perf stat, perf record, perf annotate, perf probe, perf ftrace, || perf 系 | perf sched, perf mem, perf c2c, perf lock, perf trace |+----------------------+------------------------------------------------------------------+| ftrace 系 | trace-cmd, kernelshark, irqsoff tracer, wakeup tracer |+----------------------+------------------------------------------------------------------+| | bpftrace || BPF 系 | BCC 工具集:biolatency, tcpretrans, runqlat, offcputime, profile || | 云原生:Cilium, Falco, Tetragon |+----------------------+------------------------------------------------------------------+| 网络专项 | tcpdump(cBPF), Wireshark, ss, iperf, XDP-based 工具 |+----------------------+------------------------------------------------------------------+| 能耗频率(x86 专有) | turbostat |+----------------------+------------------------------------------------------------------+| | strace(ptrace 机制,每次系统调用产生两次上下文切换, || 特殊 | 开销极高,仅用于调试环境) |+----------------------+------------------------------------------------------------------+
横向关系:同一事件在不同工具的多维度呈现
这是理解 Linux 可观测性体系最实用的视角:同一个底层事件,不同工具从不同抽象层次、不同时间粒度、不同数据维度呈现,解决不同阶段的问题。
一次磁盘 I/O 事件
iostat:看到1 秒 / 多秒聚合的平均指标(await、IOPS、utilization),来自 /proc/diskstats 预计算计数器。只能知道 "磁盘整体慢了",无法区分是少量极慢请求还是大量正常请求。
biolatency:看到每次 I/O 的精确延迟值和完整分布直方图(含 p50/p95/p99 长尾延迟),基于 block_rq_issue和 block_rq_complete两个 Tracepoint + eBPF 内核态聚合。能回答 "到底有多慢" 的问题。
blktrace/trace-cmd:看到单次 I/O 在块层全生命周期的所有阶段时间戳(排队、调度、驱动执行、完成),基于 ftrace ring buffer。能深入分析 "I/O 慢在哪个环节"。
perf record -e block:block_rq_complete -g:看到每次 I/O 完成时的完整调用栈(哪个进程、哪个函数发起了这次 I/O),基于Tracepoint + perf_events 事件触发(非采样)。能回答 "谁在发起慢 I/O"。
一次 TCP 重传事件
netstat -s / ss -s:看到系统全局 TCP 重传段计数器(RetransSegs)的增量,来自 /proc/net/snmp。只能知道 "系统有重传发生",无法定位具体连接和进程。
tcpretrans:看到每次重传的四元组、进程 PID、重传次数和时间戳,基于 tcp_retransmit_skb kprobe + eBPF。能精确定位 "哪个进程的哪个连接在重传"。
tcpdump/Wireshark:看到重传数据包的完整二进制内容(序列号、窗口大小、选项等),基于 cBPF + AF_PACKET 原始包捕获。能深入分析 "为什么会重传"(丢包、乱序、超时)。
CPU 利用率 90% 现象
top/vmstat:看到1 秒 / 多秒聚合的 CPU 时间分配比例(用户态、内核态、空闲等),来自 /proc/stat计数器。只能知道 "CPU 忙",无法区分是有效计算还是效率低下。
perf stat:看到PMU 硬件精确计数的 CPU 微架构指标(IPC、缓存命中率、分支预测错误率等)。能判断 "CPU 是真忙还是瞎忙"(例如 IPC<0.5 通常说明 CPU 大部分时间在等待内存)。
perf record -F 99 -g / BPF profile:看到消耗 CPU 时间的代码路径分布(调用栈聚合火焰图)。能精确定位 "哪段代码在消耗 CPU"。turbostat:看到每个 CPU 核的实时运行频率、功耗、温度和 C-state 停留时间,来自 MSR 寄存器。能发现 "CPU 看起来忙但性能上不去" 的隐藏原因(如温度过高触发降频、过度进入深度 C-state)。
九、选择工具的决策框架
开始│├─ 问题1:需要历史趋势还是实时诊断?│ ├─ 历史趋势 → 系统级:sar(持续记录/proc数据)│ │ 业务级:Prometheus + Grafana 监控系统│ └─ 实时诊断 → 进入问题2│├─ 问题2:需要聚合指标还是事件/分布数据?│ ├─ 聚合指标(平均值、总量、比例)→ 进入问题3A│ └─ 事件/分布数据(单次事件、p50/p99长尾、直方图)→ 进入问题3B│├─ 问题3A:聚合指标 → 需要哪个层次的视角?│ ├─ 系统全局资源 → /proc系工具:vmstat、iostat、free、sar、PSI│ ├─ 进程级资源使用 → top、pidstat、iotop、ss│ ├─ cgroup/容器级 → docker stats、cadvisor、cgroup v2 stat文件│ └─ 能耗与频率 → turbostat(CPU频率、功耗、温度)│├─ 问题3B:事件/分布数据 → 需要哪个层次的视角?│ ├─ 系统级延迟分布 → BPF工具:biolatency(IO)、runqlat(调度)、tcpdrop(网络丢包)│ ├─ 进程级行为追踪 → perf trace(系统调用)、bpftrace(自定义追踪)│ ├─ 代码路径级热点 → perf record + 火焰图、BPF profile(On-CPU/Off-CPU)│ ├─ 微架构效率分析 → perf stat(PMU计数:IPC、缓存命中率、分支预测错误率)│ ├─ 专项深度问题│ │ ├─ 缓存伪共享/NUMA → perf c2c、perf mem│ │ ├─ 内核锁竞争 → perf lock、BPF offcputime│ │ ├─ 调度延迟/CPU迁移 → perf sched、BPF runqlat│ │ └─ 网络协议细节 → tcpdump/Wireshark(原始包分析)│ └─ 跨层关联分析(如"哪个SQL触发了哪些磁盘IO")→ 仅BPF工具支持│└─ 问题4:工具是否适合生产环境运行? ├─ ✅ 可长期运行(开销<1%) │ ├─ 所有/proc/sys系工具(top、vmstat、iostat、sar、ss) │ ├─ perf stat(计数模式) │ └─ 低频率BPF聚合工具(如10秒一次的biolatency) ├─ ⚠️ 可短期运行(开销1%-5%,不建议超过30分钟) │ ├─ perf record(99Hz采样) │ ├─ 中等频率BPF追踪工具 │ └─ trace-cmd(轻量事件录制) └─ ❌ 禁止在生产环境运行(开销>20%,会影响业务) ├─ strace/ltrace(ptrace机制) ├─ 高频perf采样(>1000Hz) ├─ 全量tcpdump抓包(千兆以上流量) └─ 无过滤的kprobe追踪(如追踪所有内核函数)
结语
Linux 性能工具看似功能重叠,本质是不同工具对各类数据源的精准适配。本文梳理的核心逻辑可总结为:同一内核事件可被多种渠道消费,而不同数据通道的能力差异,直接决定了工具的观测边界与适用场景。
/proc 系工具用最低的开销提供系统级聚合视图;perf_events 统一了多种事件源的订阅框架,既服务 perf 工具族,也作为 eBPF 的触发机制;ftrace 提供函数级别的执行路径追踪;eBPF 在 Tracepoint、kprobe、perf_events 等多种事件源之上构建了可编程的跨层关联分析能力,BTF/CO-RE 解决了跨内核版本的可移植问题,验证器保证了内核安全;cBPF 在数据包过滤路径上运行了三十年;XDP 把 eBPF 的能力推进到网卡驱动层;MSR 接口直接触达硬件能耗和频率状态。
每种工具都功能局限。理解其间的数据流关系,就理解了每种工具的能力边界,也就知道了面对不同的问题应该选择哪种工具,以及为什么只用一种工具永远不够。
性能分析不是"找到最强的工具用它解决所有问题",而是"理解每种数据源能提供什么信息,按问题的需要组合使用"。这才是 Linux 性能分析工具体系的真正使用方式。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
