Python爬虫入门连载07:爬取数据保存到Excel表格
前面我们学会了:
单页爬取、多页分页爬取、抓标题、抓正文、抓图片。但爬到的数据只打印在控制台,不好保存、不好统计、不好分享。今天教你爬虫终极实用技能:
把爬到的新闻标题、链接、时间自动写入Excel一键生成规整表格,可排序、可筛选、可直接发给办公使用。
一、用到的库
我们用之前办公自动化学过的 openpyxl
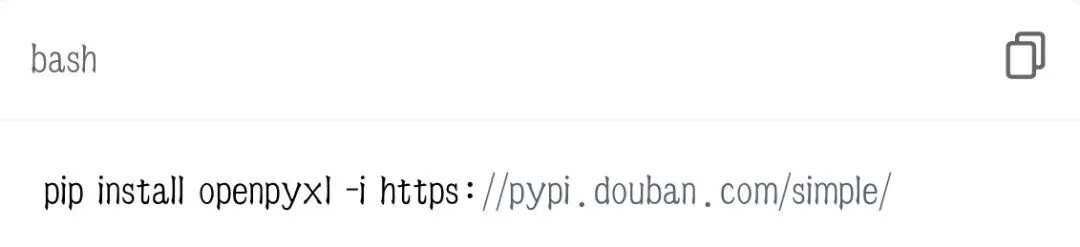
没安装的执行:
二、实现思路
1.requests 请求网页
2.BeautifulSoup 解析提取标题、链接
3.新建Excel、创建表头
4.循环把每条数据逐行写入
5.保存Excel文件四、代码核心讲解
1. 新建Excel并加表头
直接用 append 一行行追加,非常方便。过滤空文字、过滤不是外网链接的地址,保证表格干净。3. 循环写入每一条
每抓到一条标题+链接,就 ws.append() 写入一行。4. 保存文件
运行后自动生成Excel,可直接打开查看。
五、结合分页爬取存入Excel
只要把分页循环套进来就行:
1.循环每一页
2.每页解析数据
3.逐条追加进Excel
4.最后一次性保存
5.逻辑完全通用,不用改太多代码。
六、新手常见坑
❌ 没装 openpyxl 直接运行会报错
❌ Excel打开状态下运行代码,保存失败
❌ 不过滤空数据,表格里一堆空行
❌ 链接是相对路径没判断,存入无效地址
本期小结
1.用 openpyxl 可以把爬虫数据一键存入Excel
2.流程:爬取 → 解析 → 过滤 → 逐行写入 → 保存
3.自动生成规范表格,便于统计、归档、办公使用
4.可结合分页,批量爬多页汇总到一张Excel
小作业
选一个资讯网站,爬取5条新闻标题+链接,保存到自己新建的Excel里。
下期预告
Python爬虫连载08:基础反爬绕过——伪装浏览器、延时访问、简单防盗链处理
解决经常被网站拦截、访问失败的问题,学会基础伪装,爬取更稳定!



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
