前言:
从去年开始,行业里就把 Agent吹得神乎其神,2025年就被称为“Agent之年”,今年更是把Agent AI的位置提得非常高,很多人各种场合言必称Agent。而Agent技术中非常关键的是Agent框架即Agent Framework;从早期的 LangChain、LangGraph等,到如今国人比较熟悉的 Dify、扣子(Coze)等,以及号称下一代Agent Framework的多角色框架CrewAI等。
不少人问我:Agent 框架的底层到底是什么?
其实业内最近热议的“循环工程”(Loop Engineering)已经道出了真相——AI 开发正在从“人天天写提示词”,演进为“人设计确定性的系统循环”让 AI 自己去交互。未来的核心竞争力,就是设计那套让 Agent 自主运转的闭环代码。
今天给大家推荐并翻译这篇非常接地气的文章。作者没有使用任何复杂的框架,纯用 50 行 Python 代码、一个 while 循环和 MCP 协议,就把 AI Agent 框架的本质和循环工程的核心给简单的展示出来了。没有魔法,全是确定性。强烈建议技术同仁们读一读。
原文在https://levelup.gitconnected.com/building-an-ai-agent-from-scratch-no-magic-just-a-deterministic-loop-a916161705fb
以下是我的翻译部分,针对中国读者做了一些定制。
正文如下:
“从零开始构建人工智能代理:没有魔法,只有确定性循环”
我每天都在使用 Claude、Codex、Cursor、Gemini、Copilot 或 Junie,但我仍然无法准确指出“聊天机器人”变成“智能体(Agent)”的确切界限,我也无法解释是什么使它们成为了智能体。所以,为了弄清楚这个问题,我决定不依赖任何现成框架,从头开始自己编写一个最简单的版本。
对我来说,理解新概念的最佳方法就是把它重头构建出来并向别人解释清楚。这篇文章同时做到了这两点。我将实验过程与实用教程结合起来,相信你会觉得它很有用。
我们将从 50 行 Python 代码开始,将其连接到 OpenAI,通过 Ollama 切换到本地模型,构建一个同时使用两者的混合模式,添加工具,实现 MCP(模型上下文协议),最后将其与 Claude CLI 进行比较。到最后,你将清楚地了解其底层工作原理。
没有 LangChain,没有 LangGraph,没有 CrewAI。只有 Python、大语言模型(LLM)和一个 while 循环。
我们正在构建的东西(技术规范)
在建造任何东西之前,你必须先定义它是什么,并详细说明它的功能。
一个人工智能代理是一种具有以下功能的程序:
接受用户分配的高级任务
推断下一步行动
执行操作(调用工具、搜索网络、读取文件等)
观察结果
决定是继续还是返回最终答案
保留对话历史记录,以便每个决定都建立在先前决定的基础上
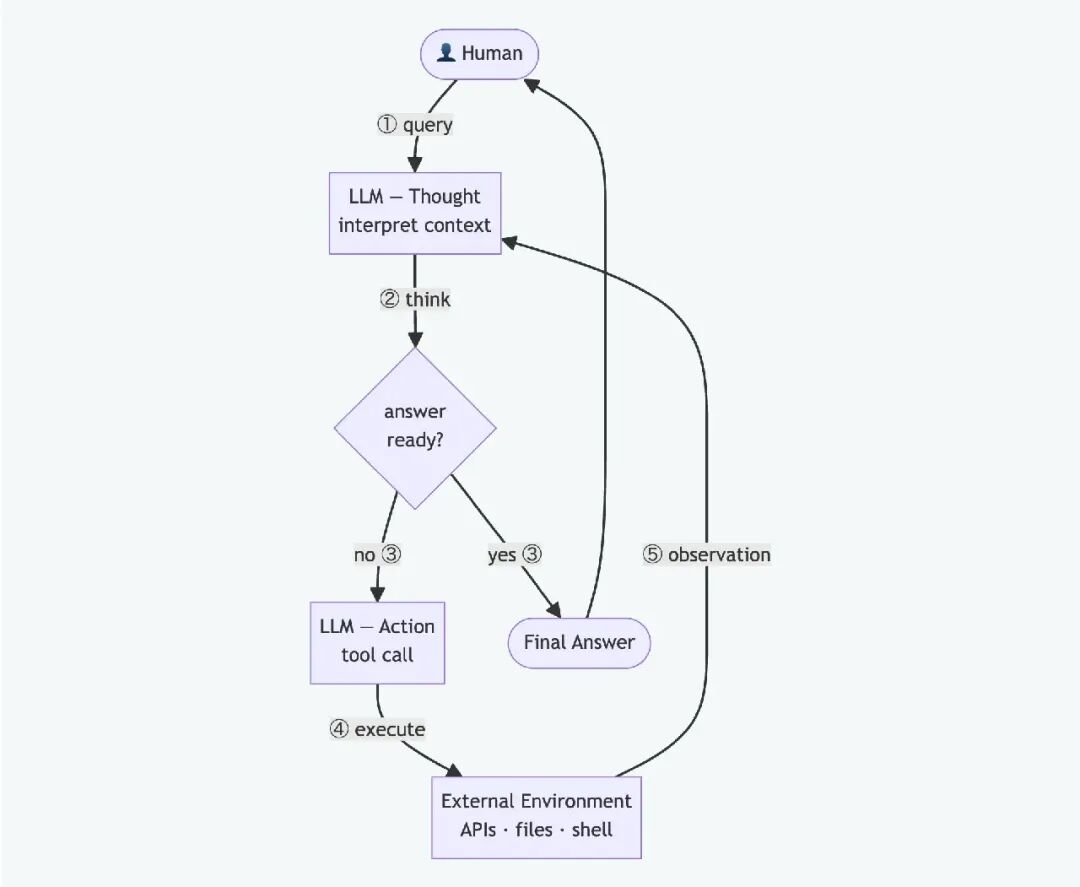
常规的 LLM 调用是一次性操作:发送提示词,接收响应,结束。而Agent则不同,它会循环执行。它接收一个高级任务,推断下一步该做什么,执行一个动作,观察结果,然后持续执行直到任务完成。
构建思考(Reasoning)、行动(Act)、观察(Observe)、决策(Decicion)的重复循环,正是利用大语言模型构建智能体的关键。
如今大多数智能体都遵循一种称为 ReAct(Reason + Act,推理 + 行动)的模式。LLM 不会直接给出最终答案,而是会先产生一个关于该怎么做的想法,然后执行一个行动(工具调用),接着等待并观察结果,最后再决定下一步行动。(注:ReAct是由现任腾讯首席 AI 科学家姚顺雨,在普林斯顿大学求学期间联合谷歌提出来的。)
图 1: ReAct 循环——先推理,然后行动,观察结果,再次推理。该循环重复进行,直到模型获得足够的信息可以直接回答问题。
这个模型没有意识,也没有任何有意义的自我反思能力。它所拥有的只是对话历史——它采取的每一个行动和得到的每一个结果,都老老实实地待在上下文窗口中。ReAct 模式将这些信息转化为类似自我反思和自我纠正的行为。而且它确实有效。
在每个周期中发生的情况如下:
你将当前对话发送到 LLM:包括系统提示词(System Prompts)、用户消息以及任何先前的工具结果。
LLM 返回最终答案或它想要调用的工具列表。
如果是最终答案,流程结束。
如果是工具调用,则执行它们,将结果附加到对话历史中,然后返回步骤 1。
这就是全部架构。
最小实现方案(云端 API 作为大脑)
首先,我们使用云端 API 作为核心。我选择 OpenAI 是因为它拥有最简洁的工具调用接口,但任何兼容 OpenAI 的 API(如 Gemini、Anthropic 等)都适用。
核心代理机制的代码如下:
def run_agent(task: str, client: OpenAI, model: str = "gpt-4o-mini") -> str: messages = [ { "role": "system", "content": ( "你是一个乐于助人的助手。请在需要时使用工具。" "当你得出最终答案时,直接回答,不要调用任何工具。" ), }, {"role": "user", "content": task}, ] while True: response = client.chat.completions.create( model=model, messages=messages, tools=TOOLS, tool_choice="auto", ) message = response.choices[0].message messages.append(message) # 核心决策点:模型是有答案了,还是需要调用工具? if not message.tool_calls: return message.content # 如果执行到这里,说明模型调用了一个或多个工具 for tool_call in message.tool_calls: name = tool_call.function.name args = json.loads(tool_call.function.arguments) print(f" > 正在调用 {name}({args})") fn = TOOL_FUNCTIONS.get(name) result = fn(**args) if fn else f"未知的工具: {name}" messages.append({ "role": "tool", "tool_call_id": tool_call.id, "content": result, }) # 迭代结束 —— 返回 while 循环的开头
关键代码行是 if not message.tool_calls。如果模型返回文本而未请求任何工具,则表示它已拥有回答问题所需的一切信息。此时,Agent退出并返回该文本。如果模型请求工具,Agent则执行这些工具,将结果添加到对话历史记录中,并将所有内容发送回模型以进行下一轮对话。
messages 列表就是Agent的短期记忆。每次工具调用和每次结果都会被添加到其中。当 LLM 认为任务完成时,它已经浏览了所有执行的操作以及从中获取的信息。
系统提示词同样至关重要。它就像方向盘,告诉模型何时使用工具、何时停止,以及最终答案应该是什么样子。在实际生产环境中的Agent中,这个系统提示词通常相当庞大。
定义工具
我们用三个简单的例子来具体说明:当前日期/时间、计算器和天气预报。在实际的代理程序中,你需要将天气预报替换为实际的 API 调用。
import jsonimport osfrom datetime import datetimefrom openai import OpenAIdef get_current_date() -> str: return datetime.now().strftime("%Y-%m-%d %H:%M:%S")def calculate(expression: str) -> str: try: # 注意:实际生产中请勿直接使用 eval,此处仅为演示极简逻辑 result = eval(expression, {"__builtins__": {}}, {}) return str(result) except Exception as e: return f"错误: {e}"def get_weather(city: str) -> str: # 实际开发中此处应替换为真实的天气 API 调用 return f"{city}的天气: 72°F, 多云"TOOL_FUNCTIONS = { "get_current_date": get_current_date, "calculate": calculate, "get_weather": get_weather,}
工具模式(Schema)会告诉 LLM 哪些工具可用。以下 JSON 数据是模型在决定调用哪个工具以及使用哪些参数时所看到的配置:
TOOLS = [ { "type": "function", "function": { "name": "get_current_date", "description": "返回当前的日期和时间", "parameters": {"type": "object", "properties": {}, "required": []}, }, }, { "type": "function", "function": { "name": "calculate", "description": "计算数学表达式并返回结果", "parameters": { "type": "object", "properties": { "expression": { "type": "string", "description": "一个 Python 数学表达式,例如 '2 + 2' 或 '100 * 0.15'", } }, "required": ["expression"], }, }, }, { "type": "function", "function": { "name": "get_weather", "description": "获取指定城市当前的天气", "parameters": { "type": "object", "properties": { "city": {"type": "string", "description": "城市名称"} }, "required": ["city"], }, }, },]
运行它:
if __name__ == "__main__": client = OpenAI(api_key=os.environ["OPENAI_API_KEY"]) task = "今天是几号?另外,847 的 15% 是多少?东京现在天气怎么样?" print(f"任务: {task}\n") answer = run_agent(task, client) print(f"\n答案: {answer}")
输出结果:
任务: 今天是几号?另外,847 的 15% 是多少?东京现在天气怎么样? > 正在调用 get_current_date({}) > 正在调用 calculate({'expression': '847 * 0.15'}) > 正在调用 get_weather({'city': 'Tokyo'})答案: 今天是 2026-04-30 09:14:22。847 的 15% 是 127.05。东京目前天气为 72°F,多云。
在第一轮迭代中,LLM 识别出了所需的全部三个工具,逐一调用它们,获取结果,并汇总出最终答案。整个过程没有使用任何复杂框架,也没有引入额外的编排层。
通过 Ollama 将云端 API 替换为本地大模型
Ollama 提供了一个与 OpenAI 兼容的 API,这意味着只需做一处修改,相同的代理代码即可在本地模型上运行:
ollama_client = OpenAI( base_url="http://localhost:11434/v1", api_key="ollama", # 客户端库必需的参数,但 Ollama 会忽略它)answer = run_agent(task, ollama_client, model="qwen2.5")
就是这样。这段代码本身并不知道它是在与 OpenAI 的云端服务器通信,还是在与运行在你本地机器上的模型通信。
要让 Ollama 运行起来,只需在本地安装后执行:
Bashollama pull qwen2.5ollama serve
之后,Agent将完全离线运行。我常用这种方式来测试新工具,既能避免消耗 API 额度,也能确保涉及的隐私数据不会离开我的本地机器。
并非所有本地模型都支持工具调用
这是实际开发中容易踩到的坑。我起初尝试了 Mistral 7B,它是一款被广泛推荐的优秀本地模型。代理运行没有报错,但输出结果类似这样:
Plaintext答案: 我需要调用 get_current_date() 来获取今天的日期。让我使用计算器工具: calculate(expression="847 * 0.15")...
模型只是输出了描述工具调用的纯文本,并没有发生实际的工具调用。每次返回的 tool_calls 字段都为空,因此程序直接把模型写入的文本内容当成最终答案退出了。
这并非Agent的漏洞。代码完全按照预期运行:检查工具调用,未发现任何调用,然后返回。问题在于 Mistral 7B 不支持 OpenAI 风格的结构化函数调用(Function Calling)。它在训练时学会了用语言描述动作,而不是输出结构化的 JSON。模型只是凭空捏造了它认为我期望的语法。
如果你希望通过 Ollama 获得稳定可靠的函数调用支持,建议选用 Qwen 2.5 或 Llama 3.1 等原生支持该特性的模型。如果你的代理在未调用任何工具的情况下就立即返回,请首先怀疑模型的能力,而不是代码的问题。
构建混合模式(本地编排,云端委托)
你可以进行本地编排,仅在任务实际需要时才为云端调用付费。默认情况下,代理使用本地模型运行,但你可以为其提供一个专用工具,用于将复杂的推理任务委派给云端模型。本地模型负责处理日常循环和简单工具,当遇到需要更深入推理的瓶颈时,它会选择外包。
def ask_cloud_expert(question: str) -> str: """将复杂的哲学或逻辑问题委托给云端高级模型。""" cloud_client = OpenAI(api_key=os.environ["OPENAI_API_KEY"]) response = cloud_client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": question}], ) return response.choices[0].message.content
将此函数添加到 TOOL_FUNCTIONS 中,并将其模式添加到 TOOLS 中。现在运行:
answer = run_agent( task="2+2是多少?另外,请解释一下‘忒修斯之船’这一悖论的哲学含义。", client=ollama_client, model="qwen2.5")
本地模型会自己通过计算器处理“2+2”的运算,同时意识到后面的哲学问题超出了它的能力范围,于是主动调用 ask_cloud_expert() 从 GPT-4 获取合适的答案。你只需要为这一次云端 API 调用付费,而不是为整个循环过程中的几十次调用付费。
添加更多工具
让我们用一些展示现实世界能力的工具来扩展代理:网络搜索、读取文件和写入文件。
from pathlib import Pathdef web_search(query: str) -> str: # 模拟数据 —— 实际开发中可替换为 Brave Search API 或 Tavily 等 return ( f"‘{query}’的搜索结果:\n" f"1. 维基百科: 全面概述\n" f"2. 最新文章: 5分钟深度解析\n" f"3. 官方文档" )def read_file(path: str) -> str: return Path(path).read_text()def write_file(path: str, content: str) -> str: Path(path).write_text(content) return f"已成功将 {len(content)} 个字符写入 '{path}'"TOOL_FUNCTIONS = { "get_current_date": get_current_date, "calculate": calculate, "get_weather": get_weather, "web_search": web_search, "read_file": read_file, "write_file": write_file,}
将它们的模式添加到 TOOLS 中后,Agent现在就具备了搜索网络信息并将结果持久化到本地磁盘的能力。
借助这六种工具,代理人现在可以:
回答需要实时信息的问题(日期/时间)
进行复杂的数学计算
查询各地天气
搜索互联网
读取和写入本地文件
这已经足够用来执行许多实际工作了。但目前还有一个局限:所有工具都是硬编码在脚本里的。我们无法直接与其他代理共享工具,也无法直接使用别人开发好的工具。
MCP 客户端:从外部服务器发现工具
上述硬编码方式导致工具难以跨项目共享或重用。如果我想让另一个代理使用相同的工具,我只能复制粘贴代码;如果我想使用别人的工具,则必须重写。
Anthropic 在 2024 年 11 月推出的 MCP(Model Context Protocol,模型上下文协议)正是为了解决这一痛点。它定义了一种统一的标准,使任何代理都能发现并调用任何服务器上的工具——无论是你自己搭建的服务器,还是面向 GitHub、Slack、Postgres、Google Drive 的第三方服务器。
你的 DIY 代理在接入后就变成了一个 MCP 客户端。你无需在本地硬编码工具定义,只需调用 MCP 服务器,就能直接获取它公开的所有工具:这些工具已经被服务器定义并描述好,可以直接传递给你的 LLM。
代理的核心逻辑没有发生任何改变,改变的只是工具的来源和维护方式。从代理的角度来看,MCP 工具与本地定义的工具并无二致。它们同样呈现在 TOOLS 列表中,以相同的方式被调用,并以相同的方式返回结果。
核心的启示在于:代理并不关心工具是同一个文件中的 Python 函数,还是运行在互联网另一端的远程服务。只要双方都遵循 MCP 协议,它就能完美协作。
MCP 服务器:将你的工具开放给任何代理
硬币的另一面是:如果你想暴露自己的工具,让任何兼容 MCP 的智能体都能使用,你需要构建一个 MCP 服务器。
以下是一个完整的 MCP 服务器示例,它向外提供了两个工具 —— 转换为大写(to_uppercase)和计算单词数(count_words):
# mcp_server.py — 一个极简的 MCP 服务器from mcp.server.fastmcp import FastMCPmcp = FastMCP("mini-tools")@mcp.tool()def to_uppercase(text: str) -> str: """将文本转换为大写。""" return text.upper()@mcp.tool()def count_words(text: str) -> int: """计算字符串中的单词数量。""" return len(text.split())if __name__ == "__main__": mcp.run()
这个例子故意写得很简单,目的是展示其边界:mcp_server.py 是一个独立的进程。当代理调用工具时,子进程启动,进行 JSON-RPC 握手,然后返回结果。哪怕你把这个本地服务替换为运行在互联网另一端的远程服务器,代理侧的代码也完全不需要更改。
现在,任何兼容 MCP 的智能体(如 Claude Desktop、Cursor 或你自己的 DIY 代理)都可以直接调用你写的工具。你发布服务器,他们将配置指向它,一切就能直接运转起来。
这就是整个生态系统实现横向扩展的方式。与其让每个开发者都去重复编写“调用 GitHub API”或“查询 Postgres 数据库”的代码,不如由某个人编写一次 MCP 服务器,然后所有人都能直接复用。
与 Claude CLI 的对比
Claude Code 是一个成熟的生产力工具,而我们今天写的智能体则是一个纯粹的学习工具。这是一次坦诚的对比,我们也需要理解它们之间的本质差距。
Claude Code 能做到许多我们这个简易代理做不到的事:当任务极其庞大时,它会启动具有隔离上下文窗口的子代理;在执行具有破坏性的命令前,它会主动提示用户确认;它能跨会话保持持久记忆;在工具调用失败时,它会调整参数进行重试;在接近上下文窗口限制时,它会自动压缩先前的消息。
我们的简易代理不具备上述任何高级功能。它只有六个工具、一个 messages 列表,而且没有任何安全防护网。如果某个工具抛出异常,整个程序就会直接崩溃。
但我们的代理也有它独特的优势:你可以看懂并掌控其中的每一行代码。一旦出现问题,你准确地知道该去哪里排查。你可以通过 Ollama 让它完全离线运行,或者配置混合模式,只为真正需要的云端调用付费。Claude Code 是按消息计费的,而我们的代理在你不下达调用 GPT-4 的指令前,不会产生任何费用。
如果需要交付一个稳定可靠的商业项目,我会选择 Claude Code 或其他成熟框架。但如果我想彻底搞懂底层原理,或者需要快速为某些想法制作原型,而又不想费尽心思去和复杂的框架抗争,我会直接从这个 while 循环开始。
框架的作用何在?
如果你只是为了弄清楚智能体是什么,你完全不需要 LangGraph。但当自动重试、状态检查点和人工审批门槛变成不可或缺的刚需时,框架的价值就体现出来了。
我们上面写的代码缺乏健壮的错误处理机制。如果工具报错,代理就会直接崩溃。它没有重试逻辑,无法在执行高风险操作前暂停等待人工审核,记忆功能局限于单次对话,也无法生成子代理来处理并行任务。
LangGraph 通过将智能体建模为具有明确节点和边的“状态机”来解决这些问题。你定义每个步骤发生的情况以及触发下一步的条件。虽然前期的配置工作更加繁琐,但你因此获得了检查点机制、结构化的错误处理、人机交互(Human-in-the-loop)步骤,以及对智能体行为及其原因的完全可观测性。
CrewAI 和 AutoGen 则专注于多智能体协作。它们不是让一个智能体拥有多种工具,而是让你定义多个具有特定角色(如研究员、撰稿人、评论家)的智能体,并协调它们之间的沟通流。这对于需要不同步骤提供不同提示词或不同模型的复杂工作流非常有用。
Claude Agents SDK 和 OpenAI Assistants API 则是托管式的运行时。你把状态管理、工具路由和线程处理等底层繁琐工作直接移交给平台。虽然牺牲了一定的控制权,但换来了更快的交付速度。
50 行代码的版本是一张核心草图,而 LangGraph 等框架则是将这张草图转化为一座具有正规承重墙的坚固建筑。
在生产环境中,请信任并使用框架。而为了真正理解其实际运行机制,请自己动手写一次循环。
这次实践带给我的启示
我曾一直渴望彻底理解 AI Agent 的工作原理。现在,我做到了。
亲手构建这个极简模型为我补全了缺失的思维模型。我现在可以准确地看清智能体可能会在哪里陷入死循环,它为什么会选择某个工具而不是另一个,以及为什么盲目添加更多工具反而会让结果变糟。现在当 Claude Code 启动子智能体,或者 Cursor 决定重试一次失败的操作时,我心中对它们的底层动作一清二楚。
在我的许多项目中,我同样需要引入智能体行为。其中一些会选用 LangGraph 或 Claude Agents SDK —— 这些成熟的框架解决了很多我不想重复发明的轮子。但也有一些项目,我会直接从这个 50 行代码的版本开始演进,因为我完全掌握它的每一处细节,并且可以根据需要自由修改,而不需要去费力迎合那些我并不理解的抽象概念。
你现在也看到了相同的本质。这其中并没有什么魔法。模型只是在观察对话历史,判断自己拥有的信息是否足够回答问题,还是需要求助于工具,然后不断重复这个周期,直到任务完成。其他一切高级功能 —— 重试逻辑、人机交互、持久记忆、多智能体编排 —— 都是建立在这个基础循环之上的。
当你未来选择使用框架时,你会清楚地知道它在幕后为你承担了哪些工作;而当你不需要它时,你也不会盲目引入一个你无法调试的沉重依赖。
先试着自己构建一个最简单的版本,然后再做决定。
参考资料
代码与项目
官方文档
OpenAI 函数调用指南:platform.openai.com/docs/guides/function-calling
Ollama API 文档:github.com/ollama/ollama/blob/main/docs/api.md
模型上下文协议(MCP)官网:modelcontextprotocol.io
FastMCP 工具库:github.com/jlowin/fastmcp
主流框架
LangGraph:langchain-ai.github.io/langgraph
CrewAI:crewai.com
AutoGen:microsoft.github.io/autogen
Claude Agents SDK:docs.anthropic.com/en/docs/agents
OpenAI Assistants API:platform.openai.com/docs/assistants
学术论文
结尾:
看完这篇文章,你会发现:Agent 框架在设计上其实很简单。
它的核心就是一个 Loop(循环):处理用户输入,然后跟LLM 交互,LLM进行推理 确定是否调用工具;需要就调用设定的工具,不需要就直接返回。
但“概念简单”和“工程落地”之间,魔鬼出在细节上,无数个细节决定哪个Agent框架好用。想要真正做好这个 Loop,以下几点非常重要:
异常与错误处理:工具执行报错怎么办?LLM 返回的格式乱了怎么自动容错和重试?
上下文与记忆管理:随着对话变长,如何高效裁剪和压缩 Token,防止记忆爆炸或者遗忘?
安全处理与人工介入:涉及修改、删除或付款等高风险操作时,如何安全地暂停循环并等待人工审批?
写一个 50 行的最小实现能让我们看清Agent框架本质,但要把产品推向生产线,解决上面这些细节才是拉开差距的关键。
你现在在用什么框架跑你的业务 Loop?踩过哪些让人头疼的细节坑?欢迎在评论区聊聊。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
