PHP-FPM 核心参数详解与最佳实践:让你的服务器真正跑起来
- 2026-06-27 13:25:17
搞 PHP 开发或运维的,谁还没被 FPM 坑过几次呢。
我当年刚接手一个 WordPress 站点,流量稍微上来一点服务器就 OOM,ssh 都连不上,只能强制重启。那时候真是一脸懵——不就是个博客吗,怎么就把 4GB 内存干爆了?
后来发现,罪魁祸首就是 PHP-FPM 的参数配置。默认配置?不存在的。PHP 官方给的默认值基本等于告诉你"你自己看着办"。
这篇文章把 PHP-FPM 那堆核心参数一个一个掰开讲清楚,最后再给一套根据内存「算」出配置的方法。直接上干货。
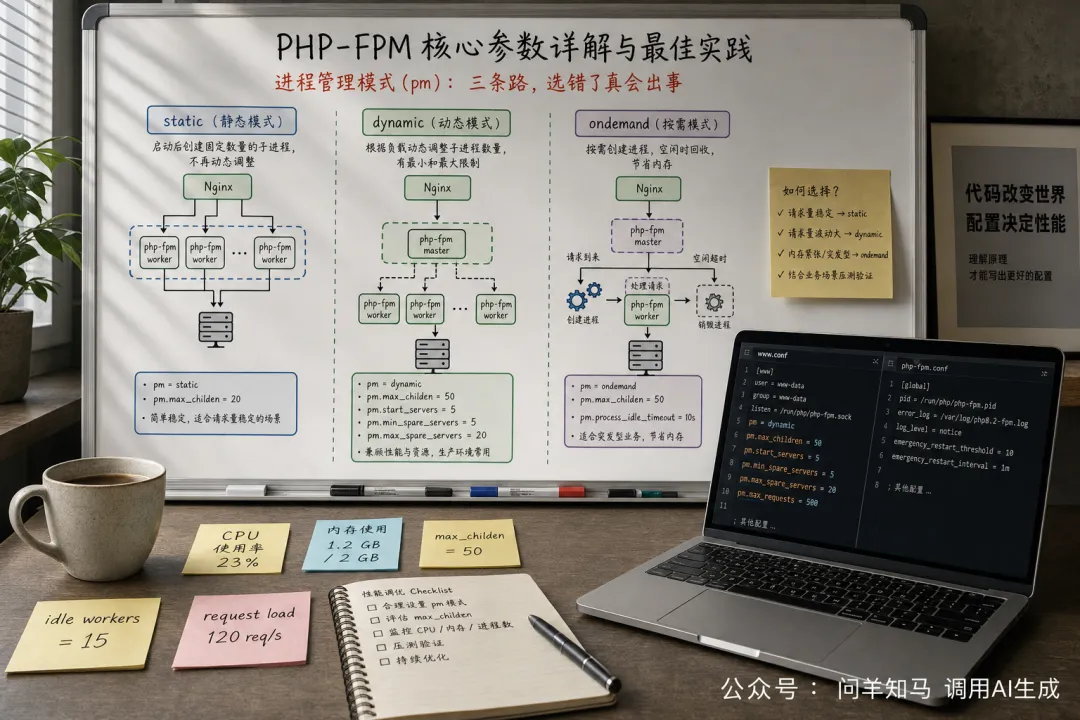
一、进程管理模式(pm):三条路,选错了真会出事
pm 是 FPM 进程管理的开关,决定了进程池怎么创建、怎么回收。三种模式:static、dynamic、ondemand。
static — 简单粗暴,大流量首选
pm = staticpm.max_children = 20启动时就创建固定数量的子进程,数量就是 pm.max_children,既不增加也不减少。没有创建销毁的开销,响应最稳定。
什么时候用? 流量稳定且持续的场合。你有一个 API 服务,每秒请求量在合理范围内波动不大,static 就是最优解。少了进程调度的 overhead,CPU 也能省一点。
踩坑提醒: static 模式没有回收机制。假设你设了 max_children = 50,这 50 个进程就一直活着。如果流量降下来了,它们依然占着内存。小流量场景用 static 纯属浪费资源。
dynamic — 弹性伸缩,中小流量的万金油
pm = dynamicpm.max_children = 50pm.start_servers = 5pm.min_spare_servers = 2pm.max_spare_servers = 10FPM 会根据实际请求量自动调整进程数量。初始启动 pm.start_servers 个,然后根据空闲进程数量在 min 和 max 之间动态调整。
这套参数配合好了,就像汽车自动变速箱——低负载省油(省内存),高负载给足动力(不丢请求)。
什么时候用? 大部分中小站点、流量有时段的场景都适合。白天人多自动扩容,半夜没人自动缩容。
ondemand — 省内存神器,但也最慢
pm = ondemandpm.max_children = 50pm.process_idle_timeout = 10s有请求来了再创建进程,空闲超过 pm.process_idle_timeout 就杀掉。内存最省,但代价是冷启动延迟——第一个请求要等进程创建,耗时在几十到几百毫秒之间。
什么时候用? 低流量站点、开发环境,或者你跑着一堆不常用的 CLI 项目。我见过有人在一台 512MB 的乞丐 VPS 上用 ondemand 跑三四个 PHP 应用,居然也扛住了——只要你不在乎首请求响应慢一点。
一句话总结: 流量大且稳定 → static;流量有波动 → dynamic;流量极低或内存紧张 → ondemand。

二、pm.max_children — 你服务器内存决定了 FPM 最多能创建多少个子进程。
设小了,高峰期请求排队、超时、502。设大了,OOM 挂掉整个服务器。
黄金计算公式
pm.max_children = (总物理内存 - 系统预留内存) / 每个 PHP-FPM 进程平均内存占用看着简单,但"系统预留内存"和"单进程内存"怎么算才是关键。
系统预留内存包括什么?
操作系统本身(大概 200-500MB,看发行版) MySQL/MariaDB、Redis、Nginx 等其他服务 页面缓存(page cache),Linux 默认会拿空闲内存做缓存 swap 打底(不推荐靠 swap 扛 PHP,但总得有)
实战经验:保守预留 512MB,4GB 以下的小机器至少留 20% 的总内存做安全 margin。
怎么算单进程内存?
跑一下命令看看实际每个 FPM 进程吃多少:
ps -ylC php-fpm --sort:rss | awk 'NR>1 {sum+=$8; count++} END {print "Avg RSS:", sum/count/1024, "MB"}'或者更直观的:
ps aux | grep 'php-fpm' | grep -v master | awk '{sum+=$6; count++} END {print "Avg:", sum/count/1024, "MB"}'实战案例 1:1GB 内存服务器跑 WordPress
WordPress 生态里一个 FPM 进程大概吃 35-50MB。
总内存: 1024 MB系统预留: 512 MB(MySQL + Nginx + 系统本身)可用内存: 512 MB单进程: 40 MB(保守估算)pm.max_children = 512 / 40 ≈ 12对,就 12 个进程。WordPress 流量稍微爆发一下,12 个进程可能不够,但设到 20 就会 OOM。你只能优化代码、上缓存来撑。
实战案例 2:4GB 内存服务器跑 Laravel
Laravel 框架本身加载的东西多,每个进程大概 50-70MB。
总内存: 4096 MBMySQL: 512 MB(给 MySQL 分点)Redis: 128 MBNginx: 64 MB系统预留: 512 MB可用: 约 2800 MB单进程: 60 MB(Laravel 保守值)pm.max_children = 2800 / 60 ≈ 46用了 opcache 的话,每个进程的共享内存部分不重复计算,实际还能再多一些。设到 40-45 比较稳妥。
血的教训: 别抱着"先设大一点试试"的心态。设大了不是慢的问题,是整个服务器崩掉,Nginx 也打不开,ssh 都连不上——这就是传说中的"FPM OOM 杀全家"。
三、pm.start_servers / min_spare_servers / max_spare_serve
FPM 启动时创建的子进程数量,官方推荐公式是
min_spare + (max_spare - min_spare) / 2。
比如你的 min_spare=5, max_spare=20,那 start_servers 设 12 或 13 就差不多了。
太大:低峰期浪费内存。太小:刚启动时忽然来一波流量直接打穿。
pm.min_spare_servers
空闲进程的最低数量。低于这个数,FPM 会 fork 新进程。
设得太高——低流量时空闲进程浪费内存。设得太低——请求忽然增多时来不及创建进程,请求排队超时。
pm.max_spare_servers
空闲进程的最高数量。超过这个数,FPM 会杀掉一些空闲进程。
设得太大等于没有上限,设得太小会导致频繁创建销毁。
我的习惯配置(中小流量):
pm = dynamicpm.max_children = 30pm.start_servers = 5pm.min_spare_servers = 3pm.max_spare_servers = 10注意一个陷阱:pm.max_spare_servers 不能大于 pm.max_children,否则 FPM 会报错,但不会挂——它会默默地用 max_children 做上限。
四、pm.max_requests — 默认 0 是颗定时炸弹
默认值是 0,意思是子进程处理完请求后永不退出。
听起来挺美,省得反复创建进程。但你想想:PHP 不像 Go 或 Java,语言本身不擅长长时间运行。即使代码写得再干净,第三方扩展、老旧类库、甚至 PHP 本身都可能积累内存泄漏。
一天两天看不出来,跑上一两个月,你会发现单个 FPM 进程的 RSS 从 40MB 涨到了 80MB、120MB,直到某天撑爆服务器。
pm.max_requests = 500这是比较保守的配置,处理完 500 个请求就让进程退出,FPM master 再重新 fork 一个干净的。
pm.max_requests = 2000如果你对自己的代码有信心,或者跑了 opcache 并且不想频繁刷新,设到 1000-3000 都行。建议不要超过 10000,否则内存泄漏积累的效果会越来越明显。
还有个冷门好处: 配合 opcache,pm.max_requests 可以定时让进程重启,从而加载新的 opcache 缓存的 PHP 文件——这在部署后不重启 FPM 的场景下非常有用。部署新代码后,等待旧请求处理完,新进程自然用上最新字节码。
实测经验:WordPress 加了一堆插件后,每个进程的 RSS 增长非常快。有个客户跑了三个月,max_requests 默认 0,每个进程从 45MB 涨到 160MB。设了 max_requests=1000 后,内存最高就卡在 60MB 左右。
五、pm.process_idle_timeout — 空闲进程的「失业金停发」
仅在 dynamic 和 ondemand 模式下生效。
pm.process_idle_timeout = 10s意思是空闲超过 10 秒的进程会被 FPM 杀掉(前提是空闲进程数超过了 min_spare_servers)。
设大了:空闲进程一直占着内存不释放。设小了:频繁创建销毁,CPU 开销增加。
建议值:
dynamic 模式: 10s-30s。流量波动不大的场景可以设长一点。 ondemand 模式: 5s-10s。既然选了 ondemand 就是为了省内存,空闲了赶紧杀掉。
六、request_terminate_timeout — 你的最后一道保险
request_terminate_timeout = 60s这个参数是 PHP-FPM 层面的硬超时。一旦请求执行时间超过这个值,FPM master 进程会直接 kill 掉对应的 worker 进程。
为什么说它是"最后一道保险"?你在代码里写的 set_time_limit() 不一定靠得住。某些阻塞操作(比如 sleep()、curl 请求远程服务器卡住、文件锁死锁)可能导致 PHP 进程一直挂着。没有这层保护,worker 进程就变成僵尸进程,占着茅坑不拉屎,把 max_children 消耗殆尽。
建议值:
普通 Web 页面:30s-60s API 接口:10s-30s 有长耗时任务的:可以放宽到 120s-300s,但建议用队列异步处理
注意: 这个值要大于 nginx 的 fastcgi_read_timeout。否则 nginx 先报超时断开连接,FPM 还在傻傻地继续运行,做了无用功。
fastcgi_read_timeout60s;# 和 FPM 的 request_terminate_timeout 保持一致或略长一点七、pm.status_path — 不监控就没法调优
pm.status_path = /status打开这个配置后,你可以通过 URL 查看 FPM 进程池的实时状态。
先在 FPM 配置(通常是 /etc/php/8.x/fpm/pool.d/www.conf)中打开:
pm.status_path = /php-fpm-status然后在 Nginx 配置里加上路由:
location /php-fpm-status {fastcgi_pass unix:/var/run/php/php8.3-fpm.sock;include fastcgi_params;fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;# 加个 IP 限制,别让人随便看allow127.0.0.1;deny all;}访问 https://你的域名/php-fpm-status?json 会吐出这样的信息:
{"pool":"www","process manager":"dynamic","start time":1717600000,"start since":3600,"accepted conn":15420,"listen queue":0,"max listen queue":3,"listen queue len":128,"idle processes":8,"active processes":4,"total processes":12,"max active processes":27,"max children reached":0,"slow requests":2}这几个字段是调优的关键:
listen queue | ||
max listen queue | ||
max children reached | ||
idle processes | ||
slow requests | request_slowlog_timeout 定位慢代码 |
我的调优流程:
先用 max children reached是否 > 0 判断 max_children 够不够再用 listen queue判断排队严重程度看 idle processes和active processes的比例调整 min/max spareslow requests结合request_slowlog_timeout = 5s追踪慢代码
配合 curl 加个定时任务,记录到日志里:
*/5 * * * * curl -s http://127.0.0.1/php-fpm-status?json >> /var/log/php-fpm-status.log跑一周再分析,比凭感觉调参靠谱一万倍。
八、完整配置示例
1GB 内存 + WordPress
[www]pm = dynamicpm.max_children = 12pm.start_servers = 4pm.min_spare_servers = 2pm.max_spare_servers = 6pm.max_requests = 1000pm.process_idle_timeout = 10srequest_terminate_timeout = 60spm.status_path = /php-fpm-status算过了:每个进程约 40MB,12 个占 480MB,系统留 500MB,加起来刚好 1GB 出头一点。高峰期如果 OOM,先把 MySQL 的 buffer pool 调小 100MB 试试。
4GB 内存 + Laravel API
[www]pm = staticpm.max_children = 40pm.max_requests = 2000request_terminate_timeout = 30spm.status_path = /php-fpm-statusAPI 服务流量相对稳定,直接 static。40 个进程 × 60MB = 2400MB,加上 MySQL 512MB、系统 500MB,总共约 3.4GB,还有 600MB 的 buffer/cache 余量。
512MB 乞丐 VPS
[www]pm = ondemandpm.max_children = 8pm.process_idle_timeout = 5spm.max_requests = 500request_terminate_timeout = 30s512MB 就别想着 dynamic 了,ondemand 省到极致。max_children 设到 8 是因为每个进程至少 40MB,留 200MB 给系统和 Nginx 都嫌少。
九、常见踩坑汇总
踩坑 1:max_children 设太大导致服务器崩了
症状:流量高峰时服务器 ssh 都连不上,直接死机。 原因:FPM 把所有内存吃光,操作系统 OOM Killer 杀掉关键进程(包括 sshd)。 解药:严格按公式算,留出安全余量。
踩坑 2:max_requests 默认 0,跑半年内存爆炸
症状:服务器用过半年后,FPM 进程 RSS 翻了好几倍,动不动就接近 OOM。 原因:代码或扩展的内存泄漏累计。有的第三方扩展(比如某些混淆加密的 PHP 扩展)每个请求泄漏几百 KB,半年积累下来非常可观。 解药:设置 pm.max_requests,定期让进程退出重建。
踩坑 3:dynamic 模式 start_servers 设太小
症状:FPM 刚重启,来一波请求,全部排队超时。 原因:start_servers 只设了 2,instant requests 来了几十个,FPM 来不及 fork。 解药:稍微设大一点,按 min_spare + (max_spare - min_spare) / 2 算。
踩坑 4:request_terminate_timeout 和 nginx 超时不一致
症状:nginx 日志里有大量 upstream timed out,但 FPM 这边啥事没有。 原因:nginx 超时比 FPM 短,nginx 断开了连接但 FPM 还在跑,浪费资源。 解药:保证 fastcgi_read_timeout >= request_terminate_timeout。
踩坑 5:不监控凭感觉调参
如果连 pm.status_path 都没配,那调优就是在盲调。不知道真实负载,不知道进程池使用率,改了参数也不知道效果——这不是调优,是碰运气。
总结一下
pm | ||
pm.max_children | ||
pm.start_servers | min + (max - min) / 2 | |
pm.max_requests | ||
request_terminate_timeout | ||
pm.status_path |
PHP-FPM 调优不是什么玄学,核心就一件事:管好内存。
知道每个进程吃多少,算出服务器能扛多少,然后用 status_path 验证这个数字靠不靠谱。这套方法用到任何一台服务器上都不会翻车。
你可能要花一个下午来测单进程内存、调整参数、观察 status 输出——但相信我,这个下午绝对比你凌晨三点爬起来处理 OOM 要划算得多。
(完)
封面及配图均为本号使用AI工具生成
故事部分为演绎,仅为串讲需要
Linux inode 详解:磁盘还有空间,却写不了文件是怎么回事
RMUX:Rust 重写的现代终端复用器,tmux 的 AI 时代接班人

问羊知马
我们一起探究这个世界
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux 内核功耗子系统(一):从 PM Core 看功耗框架的分层设计
- 自学Python的顺序不,千万别搞乱了!
- 别再手动抠图了!python的15个抠图大模型
- 清华计算机学姐:期末考Python,吃透这套题,90分没问题!
- 说句不好听的,学python真的不用吃低级的苦……
- Python描述符(上):为什么 property 能拦截属性访问?
- Python人狂喜!高频核心词直接安排
- python笔记基础知识和输出输入.
- Python 的 OOPS,不是把函数塞进 class 就完事了
- Linux 系统下载秒速搞定!国内 8 大最强开源镜像站,装系统必收藏
