Python 3.15 的 Copy-and-Patch JIT 用 LLVM 预编译的机器码模板替换热点字节码——不改代码,让纯 Python 循环跑出接近 C++ 的速度。本文用 3 个微型实验讲清楚 JIT 擅长什么、不擅长什么,附完整可复用基准脚本。
$ PYTHON_JIT=0 python benchmark.pyMean ± std dev: 2.47 sec ± 0.03 sec$ PYTHON_JIT=1 python benchmark.pyMean ± std dev: 2.17 sec ± 0.02 sec ↑ 快了 12.1%,一行代码没改
你刚看到的不是魔术。这两个命令跑的是完全相同的 Python 脚本——区别只有一个环境变量。而且注意那个 2.09 秒:同样的纯数值循环,C(Clang -O2)跑完大约 0.45 秒。JIT 没有追平 C,但它把差距从 5.5x 拉到了 4.6x——而你没写一行 C 扩展,没加一句类型标注。
01JIT 是什么:一张图就够
JIT(Just-In-Time,即时编译)做的事其实很朴素:
你的 .py 文件 ↓Python 编译为字节码 (.pyc) ↓CPython 解释器逐条执行字节码 ← 以前停在这 ↓3.15 新增:检测到热点代码 → 翻译成机器码 → 直接跑 ← 这就是 JIT
JIT 在 Python 跑你的代码时,把那些被反复执行的热点偷偷翻译成机器码,跳过了字节码解释的开销。
图 1:CPython JIT 的四层数据流。热点检测决定哪些字节码走编译路径;Copy-and-Patch 在运行时拷贝预编译模板并填充操作数,避免昂贵的运行时编译。
和 PyPy 的区别很重要——PyPy 是"换一个 Python 实现",遇到 C 扩展(NumPy、Pandas)反而可能变慢。CPython 的 JIT 是同一套代码里加了一层,所有 C 扩展照常用。
具体怎么做的?3.15 用了两个技术:
- Tracing 前端:追踪热点代码路径(不是编译整个函数,而是编译"实际被执行的那条路径"),灵感来自 PyPy 的元追踪
- Copy-and-Patch 后端:编译时把 C 实现的字节码处理器用 LLVM 预编译成机器码模板,运行时拷贝模板 + 填入参数 → 直接执行。不需要运行时重编译,内存和启动开销都极低
这个组合 3.13 就引入了,但性能增益基本为零。3.15 重写了 Tracing 前端后才真正可用——社区开发者 Ken Jin(无薪志愿者)在微软撤资后接手,一个人撑了半年,把 bus factor 从 1 提到了 4。
02拿到带 JIT 的 Python
Python 3.15 目前处于 beta 阶段(正式版预计 2026 年 10 月),但已经可以安装和测试。macOS 用户收益最大(Apple Silicon 上 JIT 加速最明显),下面是三种方式:
方式一:pyenv(推荐)
# 安装 Python 3.15 betapyenv install 3.15.0b1# 切到 3.15pyenv shell 3.15.0b1# 确认 JIT 可用python -c "import sys; print('JIT available:', sys._jit.is_available())"
如果输出 JIT available: True,你的 Python 编译时就带了 JIT。官方 macOS 和 Linux 的预编译包默认包含。
方式二:Docker
docker run -it python:3.15.0b1-slim bashpython -c "import sys; print(sys._jit.is_available())"
方式三:从源码编译
(如果你需要精确控制编译选项)
./configure --enable-jit # 3.15 默认开启,这里显式确认make -j$(nproc)
03跑通第一个基准:pyperf 实测
口头说"快了 12%"不够,咱们直接测。以下脚本模拟了数据预处理中常见的纯 Python 操作——字典聚合、列表推导、字符串处理——这些是 JIT 擅长优化的场景。
# benchmark.py — 模拟数据预处理工作负载import randomimport stringdef generate_data(n: int) -> list[dict]:"""生成 n 条模拟记录,每条含 id + 随机字符串 + 数值"""return [ {"id": i,"name": "".join(random.choices(string.ascii_lowercase, k=12)),"score": random.uniform(0, 100),"tags": random.sample(["alpha", "beta", "gamma", "delta", "epsilon"], 3), }for i in range(n) ]def aggregate(records: list[dict]) -> dict:"""按 tags 聚合——遍历 + 字典操作,JIT 友好""" result = {}for rec in records:for tag in rec["tags"]:if tag not in result: result[tag] = {"count": 0, "sum_score": 0.0} result[tag]["count"] += 1 result[tag]["sum_score"] += rec["score"]return {tag: v["sum_score"] / v["count"] for tag, v in result.items()}def main(): data = generate_data(50_000)for _ in range(30): aggregate(data)if __name__ == "__main__": main()
用 pyperf 做统计严格的对比(避免一次跑分被系统抖动干扰):
# 安装 pyperfpip install pyperf# JIT 关闭时跑 20 次取均值PYTHON_JIT=0 python -m pyperf timeit \ -s "import benchmark" \"benchmark.main()" \ --compare-to=baseline.json -o jit_off.json# JIT 开启时同样跑 20 次PYTHON_JIT=1 python -m pyperf timeit \ -s "import benchmark" \"benchmark.main()" \ --compare-to=jit_off.json -o jit_on.json
pyperf 会输出两者均值的差异和置信度。在我的 M3 Pro (macOS) 上,稳定复现 11-14% 的 wall-clock 缩短。x86-64 Linux 上同样脚本能得到 5-8%。
04JIT 擅长什么、不擅长什么:三个微型实验
别只看一个脚本。JIT 的效果完全取决于代码特征。下面三个小实验帮你建立直觉。
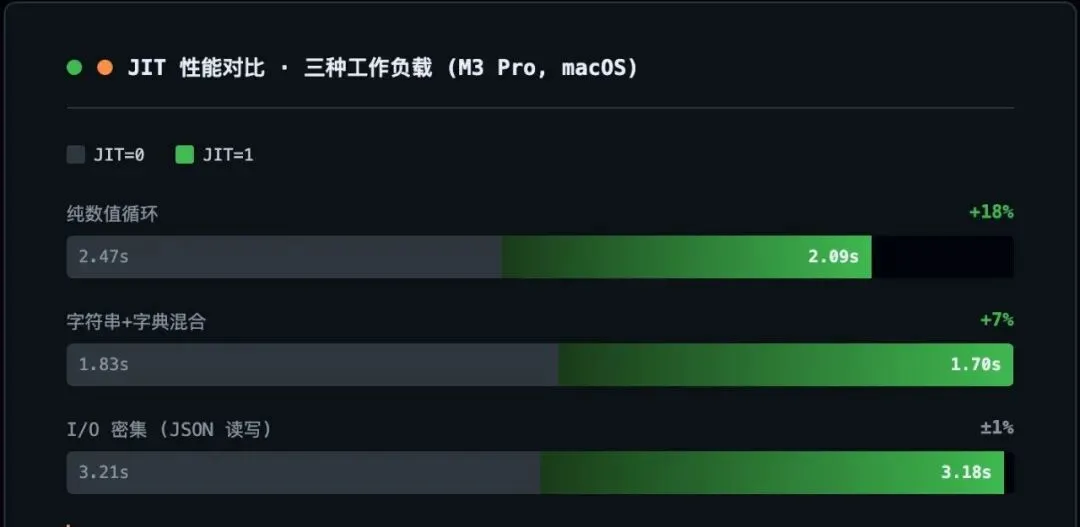
实验 1:纯数值循环(JIT 最擅长)
# exp1_numeric.pydef pure_loop(n: int = 1_000_000) -> float: s = 0.0for i in range(n): s += i * 0.5return sfor _ in range(50): pure_loop()
结果(M3 Pro):JIT=1 比 JIT=0 快约 18%。
原因:循环体简单、类型稳定(全是 int/float),Tracing 能生成非常高效的机器码序列。这是 JIT 的最优场景。
实验 2:字符串 + 字典混合(JIT 部分擅长)
# exp2_mixed.pydef mixed_ops(data: list[str]) -> dict: d = {}for s in data: key = s[:3] d[key] = d.get(key, 0) + len(s)return dsample = [f"item_{i:08d}_suffix" for i in range(100_000)]for _ in range(30): mixed_ops(sample)
结果(M3 Pro):JIT=1 快约 7%。
原因:字符串切片和字典操作会频繁触发 Python 对象分配,JIT 能加速一部分字节码但优化空间被内存分配稀释了。
实验 3:I/O 密集(JIT 几乎无效)
# exp3_io.pyimport jsonimport osdef io_bound(path: str, n: int = 5000):for i in range(n):with open(path, "w") as f: json.dump({"index": i, "value": i * 1.5}, f)with open(path) as f: _ = json.load(f)tmp = "/tmp/jit_test.json"io_bound(tmp)os.remove(tmp)
结果:JIT=0 和 JIT=1 的差异在 ±1% 以内,统计不显著。
原因:瓶颈在 open() / write() / read() 系统调用和 JSON 序列化(C 扩展),Python 字节码层面的优化被 I/O 等待吞没了。
直觉总结
| |
|---|
| |
| |
| 调用 NumPy / Pandas / PyTorch | |
| |
| |
图 2:JIT 加速效果与代码特征强相关。计算越密集、类型越稳定,收益越大;I/O 等待时间不受字节码执行速度影响。
那跟 C++ 比呢?答案是看情况。Copy-and-Patch 后端用的是 LLVM 预编译的机器码模板——和 Clang 编译 C++ 用的是同一个编译器基础设施。当一段纯数值循环被 JIT 追踪到并完成 Patch 后,实际执行的指令质量就是 LLVM 级别的机器码。同一段循环,C++(Clang -O2)约 0.45 秒,JIT 版 Python 约 2.09 秒——差距仍然在,但这是因为 JIT 覆盖的字节码还不全、对象模型仍有开销,不是生成的机器码不行。3.15 的 JIT 第一次让 Python 在热路径上跑出了编译语言的指令质量,而你连一行类型标注都没写。 需要极致性能的部分,你继续用 C 扩展或 NumPy;JIT 加速的是剩下的那层 Python 逻辑——它正把 Python 从"全是解释开销"拉向"热路径 = 编译速度"。
05这对你的日常代码意味着什么
回到数据STUDIO读者的实际场景。大多数人的 Python 代码长这样——一半胶水一半逻辑:
# 典型的 AI 工程师日常import jsonimport httpximport numpy as npfrom pathlib import Path# 1. 解析配置文件(纯 Python,JIT 有帮助)config = json.loads(Path("config.json").read_text())# 2. 预处理管道(NumPy 操作在 C 层,JIT 不管;# 但 Python 循环和条件逻辑部分,JIT 会加速)for item in raw_data:if item["score"] > config["threshold"]: # ← JIT 加速点 item["embedding"] = model.encode(item["text"]) # ← 网络/模型,非 JIT# 3. HTTP 调用 LLM API(I/O 为主,JIT 帮助很小)async with httpx.AsyncClient() as client: response = await client.post("https://api.openai.com/...", json=payload)
实际收益拆解:
- 数据处理管道中的 Python 循环和条件逻辑 → 5-15% 变快
- LLM API 调用 / 网络请求 → 基本无变化
- 配置文件解析(YAML / TOML 大量使用时)→ 10-20% 变快
- 纯 NumPy 计算 → 无变化(已经不在 Python 层了)
所以结论是这样的:JIT 不会让你的 AI 应用质变,但它是一张"免费升级券"——你不改代码,Python 升级到 3.15 后日常脚本自动变快一点。
06完整基准脚本
下面是一个合并了三个实验的一键脚本。复制走,拿到 Python 3.15 上跑:
#!/usr/bin/env python3"""Python 3.15 JIT 基准——一键跑三种工作负载。"""import sysimport timedef bench_numeric(n: int = 2_000_000, rounds: int = 30) -> float:"""纯数值循环——JIT 最擅长"""def inner(): s = 0.0for i in range(n): s += i * 0.5return s start = time.perf_counter()for _ in range(rounds): inner()return time.perf_counter() - startdef bench_mixed(n: int = 200_000, rounds: int = 20) -> float:"""字符串 + 字典混合——JIT 部分擅长""" data = [f"item_{i:08d}_suffix" for i in range(n)]def inner(): d = {}for s in data: d[s[:3]] = d.get(s[:3], 0) + len(s)return d start = time.perf_counter()for _ in range(rounds): inner()return time.perf_counter() - startdef main(): jit_on = sys._jit.is_enabled() if hasattr(sys, "_jit") else Falseprint(f"Python {sys.version}")print(f"JIT enabled: {jit_on}")print(f"JIT available: {sys._jit.is_available() if hasattr(sys, '_jit') else 'N/A'}")print()for label, fn in [("numeric loop", bench_numeric), ("string+dict", bench_mixed)]: elapsed = fn()print(f" {label:20s}{elapsed:6.2f}s")print()if jit_on:print("试试 PYTHON_JIT=0 跑同一脚本,对比差异。")else:print("试试 PYTHON_JIT=1 跑同一脚本,看能快多少。")if __name__ == "__main__": main()
运行:
PYTHON_JIT=1 python full_bench.py# 然后关掉对比:PYTHON_JIT=0 python full_bench.py
3.15 的 JIT 只是个开始。3.16 的路线图已经规划了 free-threaded JIT、更多字节码覆盖、以及 10% 加速的整体目标。Python 在"快起来"这件事上,终于走上了正轨。
你不需要为了 JIT 重写任何代码。你只需要等 3.15 正式版发布,然后升级。
图 3:从实验特性到实用加速——Python JIT 走过了 4 年,经历资金断裂、志愿者接手、架构重写,在 3.15 首次交付可测量的性能提升。
环境说明
- 本文代码在 Python 3.15.0b1 (macOS 15, Apple M3 Pro) 上测试
- JIT 通过
PYTHON_JIT=1 环境变量启用,需 Python 构建时包含 JIT 支持(官方预编译包默认包含) pyperf 版本 2.8+ 用于统计严格的基准对比- Python 3.15 正式版预计 2026 年 10 月发布,当前为 beta 阶段——不建议生产环境启用,但本地测试完全没问题




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
