用Python做科研级画图——一张“评估图套件”模板
- 2026-06-28 02:43:05
大家好,我是你们的小帅学长。
如果你一路看到这里,应该已经发现,前面我们已经讲了很多评估图(真值 vs 预测、误差分布、分组误差、多模型对比),每一张图都很重要,也都各自回答了一个问题。但真正到了写论文、做汇报、准备答辩的时候,新的问题就出现了:我到底该放哪几张?怎么组织才像一套完整的评估逻辑?难道每次都从头拼?
很多人到这一步就开始“临时凑图”:这一张讲拟合,那一张讲误差,再加一张模型对比,最后图是有了,但逻辑不成体系,读者看完仍然不知道你到底想证明什么。
所以这一篇,我们不再讲某一张单图,而是来做一件更实用、也更“论文级”的事:把评估图做成一套可复用的模板。也就是:一张“评估图套件”模板:可一键出 4 张图。
这 4 张图组合起来,基本可以覆盖绝大多数回归、反演、预测任务的论文评估需求。
01.为什么需要“评估图套件”?
因为模型评估不是一个问题,而是一组问题。你至少要回答这四类核心问题:
1)模型整体贴不贴?
也就是:预测值和真值的一致性如何。
用真值 vs 预测图
2)误差偏不偏、散不散?
也就是:误差分布长什么样,有没有系统偏差。
用误差分布图
3)误差“坏”在什么地方?
也就是:某些区间、某些类别是不是明显更差。
用分组误差图
4)多个模型到底谁更强?
也就是:不只比较一个模型,要横向比较多个模型的精度和稳定性。
用多模型对比图
这4个问题加起来,才构成一个完整的评估体系。
所以真正成熟的模型评估,不是“画一张很漂亮的图”,而是用一套图,把模型的优点、缺点、边界讲清楚。
02.这套“4图模板”分别负责什么?
为了以后写论文时不再乱,可以把这套模板固定成下面的结构:
图 1:True vs Predicted
关键词:一致性
核心作用:看模型整体贴不贴、是否围绕 1:1 线
图 2:Error Distribution
关键词:偏差结构
核心作用:看误差是否围绕 0、是否偏态、是否存在系统偏差
图 3:Grouped Error
关键词:局部问题
核心作用:看误差是不是在某些区间/类别明显变坏
图 4:Multi-model Comparison
关键词:横向比较
核心作用:当有多个模型时,看谁更强、谁更稳、谁更均衡
03.为什么这套模板特别适合论文?
因为论文评估最怕两件事:
1)信息不完整
只放一张 True vs Predicted 图,看起来很好,但误差分布呢?是否有系统偏差?某些区间会不会很差?
2)信息太零散
你可能放了很多图,但没有组织逻辑,读者/审稿人看得累。
而“4图套件”的好处是:每一张图各司其职,合在一起又形成完整证据链。
它特别适合:论文结果部分
模型评估章节
答辩 PPT
04.最稳的组织顺序
1)先放 True vs Predicted
因为这张图最直观,读者一眼就能建立“整体印象”。
2)再放 Error Distribution
整体贴得不错没错,但误差到底偏不偏、散不散?
3)再放 Grouped Error
整体表现不错,不代表局部都好,问题可能藏在高值区、某类样本里。
4)最后放 Multi-model Comparison
如果你有多个模型,这一张就是总结图:到底哪个模型最好,为什么最好。
这个顺序非常符合阅读逻辑:先整体,后误差;先直观,后拆解;最后总结。
一张图看不完模型的全部,真正专业的评估不是“选一张最漂亮的图”,而是让每张图回答一个清晰的问题,然后把这些答案拼成一套完整证据链。
05.论文级“一键出 4 图”模板代码
下面这段代码会直接帮你生成一套评估图件:
图 1:真值 vs 预测
图 2:误差分布(直方 + KDE + Bias 线)
图 3:分组误差(按真值区间)
图 4:多模型对比(箱线 / 条形 / 点图三联图)
import osimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib import font_manager as fmfrom matplotlib.ticker import MaxNLocator, FormatStrFormatterfrom sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error# =========================================================# 0) 字体设置:英文 Times New Roman + 中文 SimSun# =========================================================win_fonts = r"C:\Windows\Fonts"for p in [os.path.join(win_fonts, "times.ttf"),os.path.join(win_fonts, "timesbd.ttf"),os.path.join(win_fonts, "timesi.ttf"),os.path.join(win_fonts, "simsun.ttc"),]:if os.path.exists(p):try:fm.fontManager.addfont(p)except Exception:passmpl.rcParams["font.family"] = ["Times New Roman", "SimSun"]mpl.rcParams["axes.unicode_minus"] = Falsempl.rcParams["text.usetex"] = FalseOUT_DIR = r"D:\py_figs"os.makedirs(OUT_DIR, exist_ok=True)# =========================================================# 1) 构造示例数据# =========================================================np.random.seed(42)y_true = np.random.uniform(280, 320, 600)preds = {"Model A / 模型A": y_true + np.random.normal(0, 1.8, 600),"Model B / 模型B": y_true + np.random.normal(0, 2.4, 600),"Model C / 模型C": y_true + np.random.normal(0, 1.5, 600) + 0.35,"Model D / 模型D": y_true + np.random.normal(0, 2.0, 600) - 0.25,}# 默认选一个主模型演示单模型评估图main_model_name = "Model C / 模型C"y_pred = preds[main_model_name]errors = y_pred - y_true# =========================================================# 2) 图1:True vs Predicted# =========================================================r2 = r2_score(y_true, y_pred)rmse = np.sqrt(mean_squared_error(y_true, y_pred))mae = mean_absolute_error(y_true, y_pred)bias = np.mean(errors)xy_min = min(y_true.min(), y_pred.min()) - 1.5xy_max = max(y_true.max(), y_pred.max()) + 1.5fig, ax = plt.subplots(figsize=(5.8, 5.2))ax.scatter(y_true, y_pred, s=18, alpha=0.40, color="#4C78A8")ax.plot([xy_min, xy_max], [xy_min, xy_max], linestyle="--", linewidth=1.6, color="red")ax.set_xlim(xy_min, xy_max)ax.set_ylim(xy_min, xy_max)ax.set_xlabel("True Value (K) / 真值", fontsize=12)ax.set_ylabel("Predicted Value (K) / 预测值", fontsize=12)ax.set_title("True vs Predicted / 真值与预测值", fontsize=14)ax.xaxis.set_major_locator(MaxNLocator(nbins=6))ax.yaxis.set_major_locator(MaxNLocator(nbins=6))metrics_text = (f"R² = {r2:.4f}\n"f"RMSE = {rmse:.3f}\n"f"MAE = {mae:.3f}\n"f"Bias = {bias:.3f}")ax.text(0.05, 0.95,metrics_text,transform=ax.transAxes,va="top",ha="left",fontsize=11,bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor="black", alpha=0.9))for spine in ax.spines.values():spine.set_linewidth(1.2)fig.savefig(os.path.join(OUT_DIR, "suite_01_true_vs_predicted.jpg"),dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)# =========================================================# 3) 图2:Error Distribution# =========================================================bias = np.mean(errors)sd = np.std(errors, ddof=1)fig, ax = plt.subplots(figsize=(6.2, 4.8))sns.histplot(errors, bins="fd", stat="density", alpha=0.35, ax=ax)sns.kdeplot(errors, linewidth=2.0, ax=ax)ax.axvline(0, color="black", linestyle="--", linewidth=1.4)ax.axvline(bias, color="red", linestyle="--", linewidth=1.6)ax.set_title("Error Distribution / 误差分布", fontsize=14)ax.set_xlabel("Error = Predicted - True (K) / 误差", fontsize=12)ax.set_ylabel("Density / 密度", fontsize=12)ax.xaxis.set_major_locator(MaxNLocator(nbins=6))ax.yaxis.set_major_locator(MaxNLocator(nbins=6))metrics_text = (f"Bias = {bias:.3f}\n"f"SD = {sd:.3f}\n"f"RMSE = {rmse:.3f}")ax.text(0.97, 0.95,metrics_text,transform=ax.transAxes,va="top",ha="right",fontsize=11,bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor="black", alpha=0.9))for spine in ax.spines.values():spine.set_linewidth(1.2)fig.savefig(os.path.join(OUT_DIR, "suite_02_error_distribution.jpg"),dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)# =========================================================# 4) 图3:Grouped Error(按真值区间)# =========================================================bins = [280, 290, 300, 310, 320]labels = ["280–290", "290–300", "300–310", "310–320"]df = pd.DataFrame({"True": y_true,"Pred": y_pred,"Error": errors})df["True_bin"] = pd.cut(df["True"], bins=bins, labels=labels, include_lowest=True)grouped_errors = [df.loc[df["True_bin"] == lab, "Error"].values for lab in labels]fig, ax = plt.subplots(figsize=(7.0, 4.6))ax.boxplot(grouped_errors,patch_artist=True,widths=0.6,showfliers=True,medianprops=dict(color="black", linewidth=1.5),whiskerprops=dict(color="black", linewidth=1.2),capprops=dict(color="black", linewidth=1.2),boxprops=dict(facecolor="white", edgecolor="black", linewidth=1.2),flierprops=dict(marker='o', markerfacecolor='white', markeredgecolor='black',markersize=4, linestyle='none'))ax.axhline(0, color="red", linestyle="--", linewidth=1.3)ax.set_xticks(range(1, len(labels) + 1))ax.set_xticklabels(labels, fontsize=11)ax.set_title("Grouped Error by True Bins / 按真值区间分组的误差", fontsize=14)ax.set_xlabel("True Value Bin (K) / 真值区间", fontsize=12)ax.set_ylabel("Error (K) / 误差", fontsize=12)for spine in ax.spines.values():spine.set_linewidth(1.2)fig.savefig(os.path.join(OUT_DIR, "suite_03_grouped_error.jpg"),dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)# =========================================================# 5) 图4:Multi-model Comparison(三联图)# =========================================================model_names = list(preds.keys())errors_all = []rmse_list = []r2_list = []for name in model_names:err = preds[name] - y_trueerrors_all.append(err)rmse_list.append(np.sqrt(mean_squared_error(y_true, preds[name])))r2_list.append(r2_score(y_true, preds[name]))fig, axes = plt.subplots(1, 3, figsize=(14, 4.8))# ---- (1) 箱线图:误差分布 ----axes[0].boxplot(errors_all,patch_artist=True,widths=0.55,medianprops=dict(color="black", linewidth=1.5),whiskerprops=dict(color="black", linewidth=1.2),capprops=dict(color="black", linewidth=1.2),boxprops=dict(facecolor="white", edgecolor="black", linewidth=1.2),flierprops=dict(marker='o', markerfacecolor='white', markeredgecolor='black',markersize=4, linestyle='none'))axes[0].axhline(0, color="red", linestyle="--", linewidth=1.2)axes[0].set_xticks(range(1, len(model_names) + 1))axes[0].set_xticklabels(["A", "B", "C", "D"])axes[0].set_title("Error Distribution / 误差分布", fontsize=13)axes[0].set_ylabel("Error (K) / 误差", fontsize=11)# ---- (2) 条形图:RMSE ----order_rmse = np.argsort(rmse_list)vals_rmse = [rmse_list[i] for i in order_rmse]y_rmse = np.arange(len(vals_rmse))axes[1].barh(y_rmse, vals_rmse)axes[1].set_yticks(y_rmse)axes[1].set_yticklabels(["A", "B", "C", "D"])axes[1].invert_yaxis()axes[1].set_title("RMSE Ranking / RMSE 排序", fontsize=13)axes[1].set_xlabel("RMSE (K)", fontsize=11)for yi, v in zip(y_rmse, vals_rmse):axes[1].text(v + 0.03, yi, f"{v:.2f}", va="center", fontsize=10)# ---- (3) 点图:R² ----order_r2 = np.argsort(r2_list)[::-1]vals_r2 = [r2_list[i] for i in order_r2]y_r2 = np.arange(len(vals_r2))axes[2].scatter(vals_r2, y_r2, s=70)for yi, v in zip(y_r2, vals_r2):axes[2].plot([0, v], [yi, yi], linewidth=1.0)axes[2].text(v + 0.002, yi, f"{v:.3f}", va="center", fontsize=10)axes[2].set_yticks(y_r2)axes[2].set_yticklabels(["A", "B", "C", "D"])axes[2].invert_yaxis()axes[2].set_xlim(left=0)axes[2].set_title("R² Ranking / 排序", fontsize=13)axes[2].set_xlabel("R²", fontsize=11)for ax in axes:for spine in ax.spines.values():spine.set_linewidth(1.2)fig.suptitle("Multi-model Comparison / 多模型对比", fontsize=15, y=1.02)fig.savefig(os.path.join(OUT_DIR, "suite_04_multi_model_comparison.jpg"),dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)print("Saved 4 figures to:", OUT_DIR)
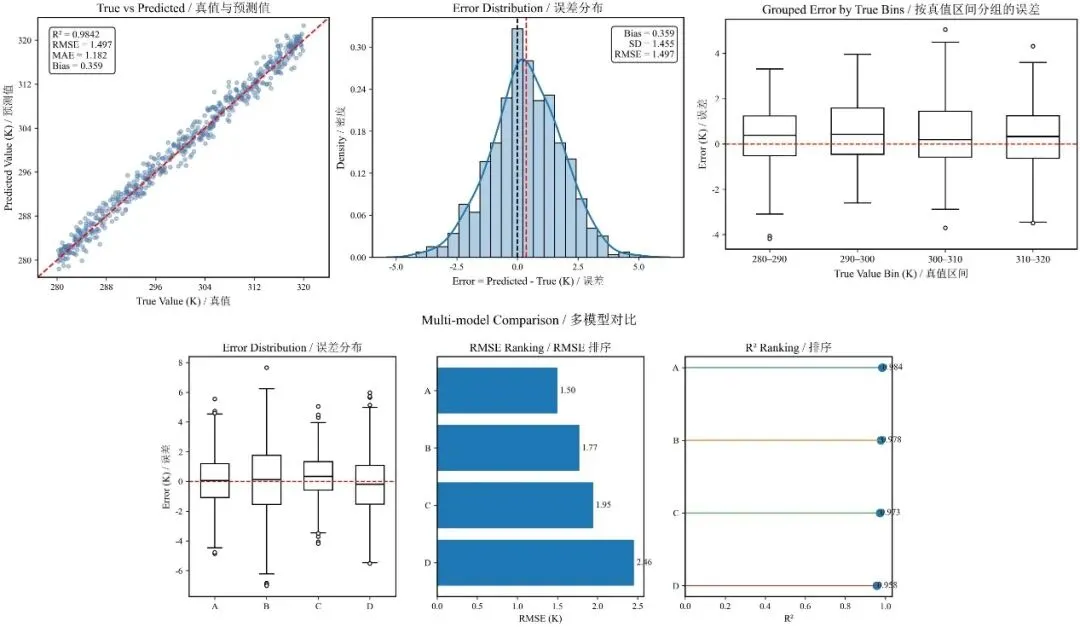
这套模板的价值,不在于“自动生成 4 张图”本身,而在于它帮你固定了一套评估逻辑:先用真值 vs 预测图看整体一致性,再用误差分布看系统偏差与形状,再用分组误差看局部问题,最后用多模型对比图做总结。
一张评估图能回答一个问题,但一套评估图才能证明一个模型——当真值 vs 预测、误差分布、分组误差、多模型对比被固定成模板之后,你的模型评估就不再是临时拼图,而是一套可以持续复用的证据系统。
下一篇我们会进入另一个非常实用、但经常让人纠结的技术点:《子图布局(tight / constrained 怎么选)》。当你开始把多张图组合成一整版论文图时,布局就不再只是“摆放”,而是决定一张图到底显不显专业的关键。
——期待你的关注——
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2026 Python量化交易入门到实战全套课程(AI+量化/零基础/源码课件/AQF认证)合集
- GESP第12次认证真题解析|Python三级真题回顾
- 不用装Python、不用配环境:浏览器里训练CNN,10分钟部署到ESP32-S3
- python学习
- 嵌入式 Linux 安全基石:威胁模型、密码学与硬件启动防护全解
- 手搓微型 Linux 发行版:从零开始打造你的专属系统
- 用 Python 自动生成 PPT,我踩过的坑
- Linux 运维高薪敲门砖|红帽认证全解析
- Python工单驱动网络诊断:接到报障先跑一遍自动检查
- 生产环境 Linux 大文件批量复制:四大实用工具详解
