不用装Python、不用配环境:浏览器里训练CNN,10分钟部署到ESP32-S3
如果你曾经尝试在本地搭建一个 TinyML 开发环境,你一定经历过这样的痛苦:
- •
pip install tensorflow 之后发现 CUDA 版本不匹配 - • 模型训练好了,却不知道怎么转成
.tflite - • 好不容易生成了
.tflite,ESP32 上的推理代码又让你头大 - • 最后发现模型太大,SRAM 装不下,一切重来
2026 年 4 月,GitHub 上出现了一个叫 webmcu-vision-web 的项目,它用一种极为激进的方式解决了上述所有问题:
整个 TinyML 流水线,全部在浏览器里跑。
不用装 Python、不用配环境、不用写一行 C++。只要你有块 $15 的 ESP32-S3 Sense,打开浏览器,10 分钟后你就能拥有一个在设备上实时运行的 CNN 视觉模型。
这就是我们今天要深度拆解的项目。
项目速览
| 项目 |
webmcu-vision-web |
| GitHub |
webmcu-ai/webmcu-vision-web |
| License |
MIT |
| 硬件 |
Seeed Studio XIAO ESP32-S3 Sense |
| 成本 |
约 ¥100 |
| 核心亮点 |
零安装、浏览器训练、10 分钟闭环 |
项目来自 webmcu-ai 组织,是"webmcu-ai 系列"的第二篇论文的配套实现。它不仅仅是一个 demo,而是一个可复用的 Living Template——你可以通过 LLM 辅助,快速适配到新的硬件平台和任务。
为什么这个项目值得关注
1. 真正的"零安装"
整个应用是一个单文件 HTML(约 500KB),里面内嵌了:
- • TensorFlow.js(训练引擎)
- • Serial API(浏览器直接读写串口)
- • Web Serial 固件烧录逻辑
- • 数据可视化、模型训练 UI、推理结果展示
你不需要 Node.js、不需要 Conda、不需要任何 IDE。把 HTML 文件拖到浏览器里,或者双击打开,就能开始工作。
2. 训练速度碾压本地方案
作者在论文中做了对比测试:
| 方案 |
训练时间 |
| 设备端训练(ESP32-S3) |
~9 分钟 |
| 浏览器训练(TensorFlow.js) |
~1 分钟 |
浏览器用上了你电脑的 GPU/CPU,训练速度是设备端的 9 倍。这意味着你的迭代周期从"喝杯咖啡"变成了"眨个眼"。
3. 数据完全本地,隐私零风险
所有图像数据、模型权重、训练过程都不会离开你的电脑。这在工业质检、医疗影像、安防监控等敏感场景中是一个巨大的优势。
4. 实时激活热图回传
推理时,ESP32-S3 不仅返回分类结果,还会把每一层的 Conv2D 激活热图通过串口实时回传到浏览器,以可视化的方式展示模型"在看哪里"。这对调试模型和教学演示非常有价值。
十分钟上手实操

TinyML四步上手流程图
硬件准备
你只需要一块 Seeed XIAO ESP32-S3 Sense(带摄像头和 SD 卡槽的版本):
- • 主控:ESP32-S3(双核 240MHz,512KB SRAM,8MB PSRAM)
- • 摄像头:OV2640 200万像素
- • 接口:USB-C(用于供电和串口通信)
- • 价格:约 ¥100 左右
如果你手上只有普通的 ESP32-CAM,也可以尝试适配,但需要修改引脚定义。
步骤一:烧录固件(浏览器直接刷)
- 1. 用 USB-C 线把 XIAO 连到电脑
- 2. 打开
webmcu-vision-web.html - 3. 点击 "Connect & Flash Firmware"
- 4. 浏览器会弹出串口选择窗口,选择你的 XIAO 设备
- 5. 等待约 10 秒,固件自动烧录完成
整个过程不需要 esptool.py,不需要按 Boot 键,不需要手动进下载模式——项目的 Serial API 封装已经帮你处理好了 ESP32-S3 的自动复位和 Boot 控制。
步骤二:采集训练数据
固件烧好后,页面会显示实时摄像头画面。按以下流程操作:
- 1. 在"Class Name"输入框里填第一个类别,比如
"screwdriver" - 2. 把螺丝刀放在摄像头前,点击 "Capture" 拍照
- 3. 每个类别拍 20-30 张(不同角度、不同光照)
- 4. 切换到下一个类别,比如
"pliers" - 5. 重复直到收集完所有类别
步骤三:浏览器训练
点击 "Train Model",TensorFlow.js 开始在浏览器后台训练一个轻量 CNN:
Conv2D(16, 3x3) → MaxPool → Conv2D(32, 3x3) → MaxPool → Flatten → Dense(64) → Output
训练参数默认:
- • Epochs: 50
- • Batch size: 16
- • Learning rate: 0.001
- • 数据增强:随机旋转、缩放、水平翻转
约 1 分钟后,训练完成,页面显示准确率曲线和混淆矩阵。
步骤四:导出权重并部署
点击 "Export & Deploy":
- 1. 权重被量化为 INT8,打包成二进制格式
- 2. 通过串口传输到 ESP32-S3 的 PSRAM
- 3. 设备自动重启,加载新模型
- 4. 页面上出现实时推理窗口 + 激活热图
至此,一个端到端的 TinyML 视觉应用就已经跑起来了。
技术架构拆解
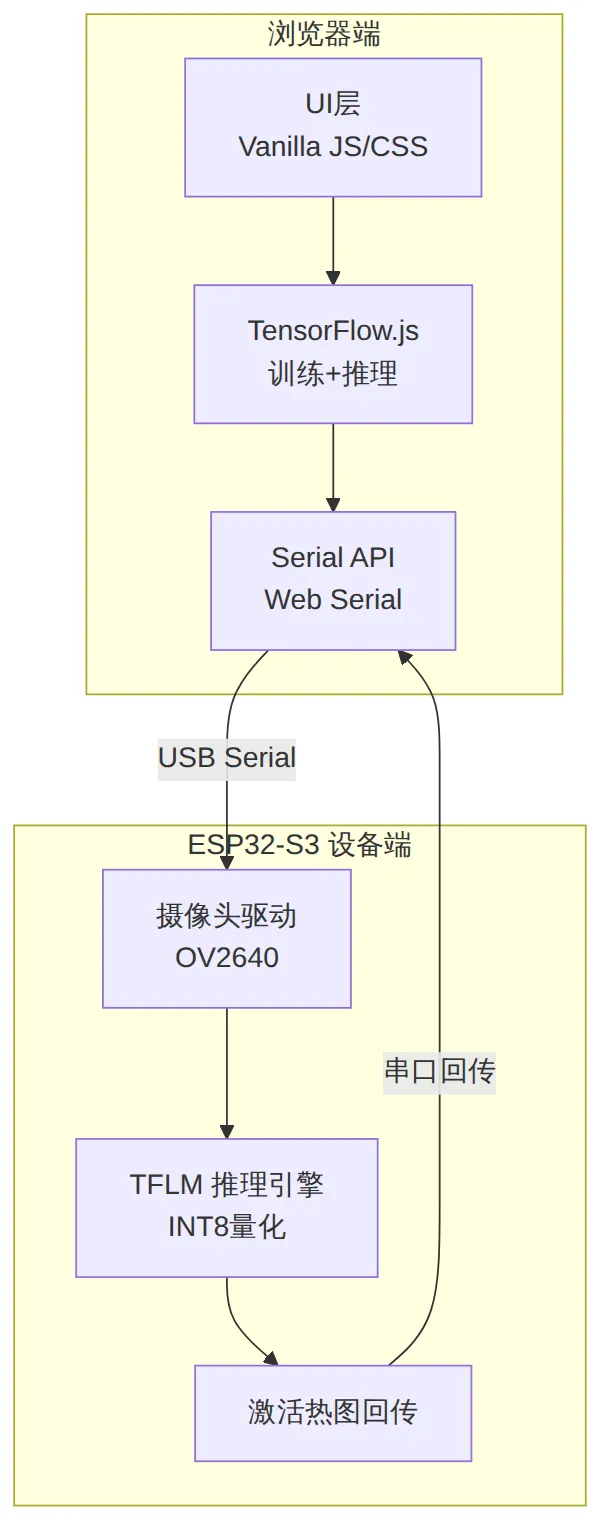
webmcu-vision-web 系统架构图
浏览器端:单文件 HTML 的工程学
┌─────────────────────────────────────────────┐
│ webmcu-vision-web.html │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ UI 层 │ │ TensorFlow.js │ │ Serial API │ │
│ │ (Vanilla │ │ (训练+推理) │ │ (Web Serial)│ │
│ │ JS/CSS) │ │ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ↕ USB Serial │
└─────────────────────────────────────────────┘
作者把所有的 JS 依赖都内联了,没有外部 CDN 请求。这意味着你甚至可以在离线环境中使用它——只要把 HTML 文件拷贝到内网电脑即可。
设备端:ESP32-S3 固件结构
// 固件核心逻辑伪代码
void loop() {
camera_fb_t* fb = esp_camera_fb_get();
int8_t* input = quantize_image(fb->buf);
// INT8 推理
int8_t* output = tflite_interpreter->Invoke(input);
// 回传分类结果 + 激活热图
Serial.write(output, OUTPUT_SIZE);
Serial.write(conv2_activation_map, MAP_SIZE);
esp_camera_fb_return(fb);
}
固件基于 TensorFlow Lite for Microcontrollers (TFLM),模型存储在 PSRAM 中,推理在 SRAM 中执行。关键的内存优化点:
- • 模型权重 INT8 量化:相比 FP32,模型体积缩小 4 倍
- • ** arena 大小仅 96KB**:适合 ESP32-S3 的 512KB SRAM
- • DMA 双缓冲:摄像头数据读取和推理并行
激活热图回传原理
传统 CNN 可解释性工具(如 Grad-CAM)需要反向传播计算梯度,这对 MCU 来说太重了。webmcu 采用了更轻量的方案:
- 1. 取最后一层 Conv2D 的输出(HxWxC 的特征图)
- 2. 对每个空间位置,取所有通道的最大值
- 3. 归一化到 0-255
- 4. 通过串口以 JPEG 压缩格式回传
这种方式不需要额外计算开销,而且热图的"粗糙度"反而更适合 MCU 级别的调试——它告诉你模型在图像的哪个区域聚焦,而不是精确的像素级归因。
适用场景与扩展方向
立即可用的场景
| 场景 |
说明 |
| 工业质检 |
缺陷分类(划痕、污渍、错位) |
| 智能家居 |
手势识别、物品检测 |
| 教育演示 |
TinyML 教学,学生零门槛上手 |
| 原型验证 |
快速验证一个视觉 AI idea |
扩展方向
项目文档明确说明这是一个 Living Template,你可以通过以下方式扩展:
- 1. 换硬件:把 XIAO 换成 ESP32-CAM、Maix Bit 或 Arduino Nicla Vision,修改引脚定义和摄像头驱动即可
- 2. 换模型架构:在浏览器端把 CNN 换成 MobileNetV2 或自定义结构,TFLM 转换器会自动适配
- 3. 加传感器:固件预留了 I2C/SPI 接口,可以融合加速度计、麦克风等多模态数据
- 4. 上云:训练完成后,可以把模型权重上传到云端进行 OTA 分发
与其他方案的对比
| 特性 |
webmcu-vision-web |
Edge Impulse |
TensorFlow Lite Micro |
| 安装要求 |
零安装(单HTML) |
注册账号+CLI |
Python + 交叉编译链 |
| 训练位置 |
浏览器本地 |
云端/本地 |
预训练模型 |
| 隐私性 |
完全本地 |
数据上传云端 |
本地 |
| 成本 |
免费 |
免费/付费 |
免费 |
| 定制程度 |
高(开源可改) |
中(黑盒部分) |
高 |
| 上手速度 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
⭐⭐ |
webmcu 的核心优势在于"快速验证"——当你想在一个下午验证一个视觉 AI 的 idea 时,它是目前最快的路径。
写在最后
TinyML 领域一直有这样一个悖论:最该用 AI 的人(嵌入式工程师),往往最难用上 AI。
webmcu-vision-web 用浏览器这个每个人都有的平台,把 TinyML 的门槛降到了地板以下。你不需要懂神经网络、不需要会 Python、不需要配交叉编译环境。你只需要:一块 $15 的开发板、一个浏览器、10 分钟时间。
这个项目本身开源在 MIT 协议下,你可以自由地修改、分发、商用。如果你手头正好有一块 ESP32-S3,不妨现在就下载 HTML 文件试一试——毕竟,没有什么比亲自跑通一次更能说明问题了。
参考链接
- • webmcu-vision-web GitHub 仓库[1]
- • 项目论文:A Browser-Based Companion to On-Device CNN Training[2]
- • Seeed XIAO ESP32-S3 Sense 购买页面[3]
- • TensorFlow.js 官方文档[4]
- • TensorFlow Lite for Microcontrollers[5]

