一、单选题(每题2分,共30分)
|
题号
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
答案
|
C
|
A
|
D
|
C
|
A
|
C
|
D
|
C
|
B
|
A
|
B
|
A
|
D
|
B
|
A
|
1、2024年10⽉8⽇
,诺贝尔物理学奖“意外地”颁给了两位计算机科学家约翰·霍普菲尔德(John
J. Hopfield)和杰
弗⾥·⾟顿(Geoffrey
E. Hinton)
。这两位科学家的主要研究⽅向是( )。
A.天体物理
B.流体⼒学
C.⼈⼯智能
D.量⼦理论
答案:C
解析:在2024年,瑞典皇家科学院宣布将诺贝尔物理学奖授予两位科学家——约翰·霍普菲尔德(John
J. Hopfield)和杰弗里·辛顿(Geoffrey
E.
Hinton),以表彰他们在人工神经网络和机器学习领域的开创性工作。两位科学家不仅为今天的机器学习技术奠定了坚实的基础,还引领了机器学习的发展,推动了其在当今科技中的广泛应用。
2、计算机系统中存储的基本单位⽤B来表⽰
,⽐如某个照⽚⼤⼩为3MB,其中B代表的是(
)。
A.
Byte
B.
Block
C.
Bulk
D.
Bit
答案:A
解析:计算机系统中存储的基本单位是比特(bit)和字节(byte),8比特为1个字节。比特用小写字母b表示,字节用大写字母B表示。
3、执⾏下⾯Python代码后
,输出的结果是? (
)

A. [('item3',
1), ('item1', 2), ('item2', 3)]
B. [('item1',
2), ('item2', 3), ('item3', 1)]
C. [('item2',
3), ('item3', 1), ('item1', 2)]
D.
[('item2', 3), ('item1', 2), ('item3', 1)]
答案:D
解析:sorted函数使用lambda表达式作为比较函数对items中的元组进行排序。排序的规则由lambda函数定义,即key=lambda
x: (-x[1], x[0])。这里的x是列表中的每个元组,x[1]是元组中的第二个元素(整数),x[0]是元组中的第一个元素(字符串)。-x[1]表示按照第二个元素的降序排序,如果第二个元素相同,则按照第一个元素的升序排序。因此,排序后的列表应该是[('item2',
3), ('item1', 2), ('item3', 1)]。
4、以下Python代码实现的排序算法的时间复杂度是? (
)

A.
O(n)
B.
O(2n)
C.
O(n2)
D.
O(n3)
答案:C
解析:这段Python代码实现的是插入排序算法。插入排序的基本思想是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。这段代码有两层循环,在最坏情况下,内层循环中的代码会执行1
+ 2 + 3 + ... + (n - 1)次。这是一个等差数列求和,其和为(n
- 1) * n / 2,这是一个关于n的二次函数。所以,这段代码的时间复杂度是O(n^2)
n的平方。
5、执⾏下⾯Python代码后
,输出的结果是? (
)
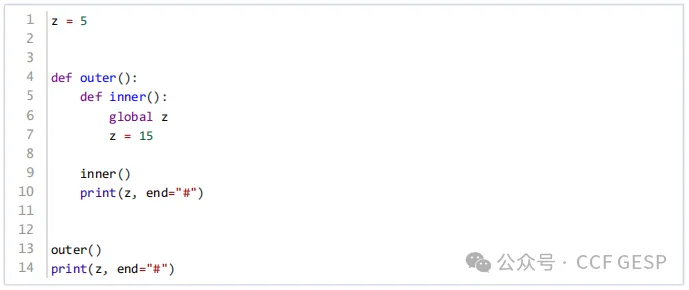
A. 15#15#
B. 15#5#
C. 5#15#
D. 5#5#
答案:A
解析:让我们逐步分析代码的执行过程:
1.z 被初始化为5。
2.调用 outer() 函数。
3.在 outer() 函数内部,调用 inner() 函数。
4.inner() 函数中,global
z 声明了 z 为全局变量,这意味着 inner() 函数内部对 z 的修改会影响到全局变量 z。
5.z 在 inner() 函数中被赋值为15。
6.inner() 函数执行 print(z,
end="#"),此时 z 的值为15,所以输出"15#"。
7.outer() 函数调用结束后,再次执行 print(z,
end="#"),此时全局变量 z 的值已经被 inner() 函数修改为15,所以再次输出"15#"。
因此,最终的输出结果是"15#15#"。
6、执⾏下⾯Python代码后
,输出的结果是? (
)
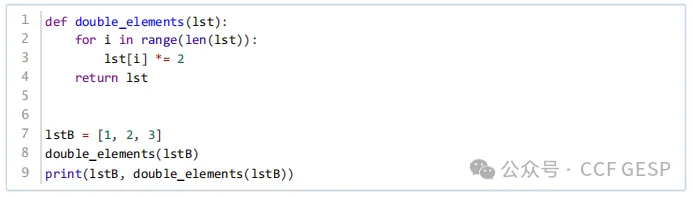
A. [1,
2, 3] [2, 4, 6]
B. [2,
4, 6] [4, 8, 12]
C. [4,
8, 12] [4, 8, 12]
D.
[1, 2, 3] [4, 8, 12]
答案:C
解析:这段Python代码定义了一个函数double_elements,它接受一个列表lst作为参数,并将列表中的每个元素乘以2。这个函数直接修改传入的列表,并且返回这个被修改后的列表。
让我们逐步分析代码的执行过程:
1.定义列表 lstB
= [1, 2, 3]。
2.调用 double_elements(lstB),这将修改 lstB 中的元素,使得每个元素都乘以2,因此 lstB 变为 [2,
4, 6]。
3.函数 double_elements 返回修改后的列表 [2,
4, 6],但由于这个返回值没有被存储或打印,它不会影响后续的输出。
4.执行 print(lstB,
double_elements(lstB))。首先调用 double_elements(lstB),这将再次修改 lstB 中的元素,使得每个元素都乘以2,因此 lstB 变为 [4,
8, 12]。然后再执行print语句,会把lstB和这次调用double_elements的返回值打印出来。
因此,最终的输出结果是[4,
8, 12] [4, 8, 12]。
7、执⾏下⾯Python代码后
,会发⽣什么? (
)

A.代码正常执⾏
,输出3
B.抛出TypeError异常
C.抛出ValueError异常
D.抛出IndexError异常
答案:D
解析:IndexError异常是在尝试访问序列(如列表、元组、字符串等)中不存在的索引时抛出的。在这个例子中,因为my_list只有三个元素,所以有效的索引只有0、1和2。尝试访问索引3会导致IndexError。
8、执⾏下⾯Python代码后
,输出的结果是? (
)
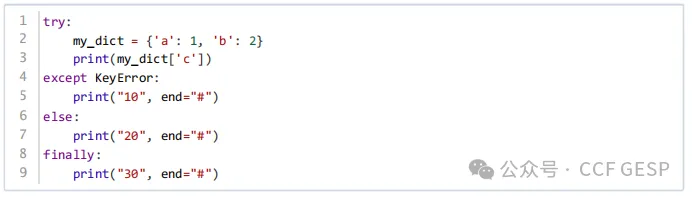
A.
10#
B.
20#
C.
10#30#
D.
20#30#
答案:C
解析:这段Python代码使用了异常处理结构try...except...else...finally。让我们逐步分析代码的执行过程:
try块中,尝试打印字典my_dict中键'c'对应的值。但是,'c'并不是my_dict的一个键,所以这将引发一个KeyError。
except
KeyError: 由于捕获到KeyError,这个块将被执行,打印"10"并在后面加上"#"。
else:由于已经引发了KeyError,所以这个块将被跳过。
finally:块无论是否发生异常都会执行,打印"30"并在后面加上"#"。
因此,最终的输出结果是"10#30#"。
9、执⾏下⾯Python代码后
,输出的结果可能是? (
)

A.
{'a': [1, 2, 3], 'b': (4, 5, 6, 7)}
B.
{'a': [10, 2, 3], 'b': (4, 5, 6, 7)}
C.
{'a': [10, 2, 3], 'b': (4, 5, 6)}
D.
{'a': [10, 2, 3], 'b': (4, 5, 6, 7, 7)}
答案:B
解析:这段Python代码首先创建了一个字典my_dic,其中包含两个键:'a'对应一个列表[1,
2, 3],'b'对应一个元组(4,
5, 6)。
接下来,代码执行了以下操作:
my_dic['a'][0]
= 10:这行代码将列表中的第一个元素(索引为0)的值从1改为10。因此,列表变为[10,
2, 3]。
my_dic['b']
+= (7,):这行代码尝试将元组(7,)追加到键'b'对应的元组(4,
5, 6) 后面。但是,元组是不可变的,这意味着不能直接修改元组的内容或长度。这行代码实际上会创建一个新的元组(4,
5, 6, 7) 并将其赋值给my_dic['b']。
print(my_dic):打印修改后的字典。
根据上述分析,字典my_dic的最终内容将是{'a':
[10, 2, 3], 'b': (4, 5, 6, 7)}。
10、执⾏下⾯Python代码后
,输出的结果是? (
)

A.1,2
B.
2, 1
C.抛出异常
D.
None
答案:A
解析:这段Python代码定义了一个函数func,它接受两个参数:a和b。在函数定义中,*用于指示其后面的b是一个关键字参数,这意味着在调用函数时,必须使用关键字b来指定这个参数的值。
函数体中使用"{},{}".format(a,
b) 来格式化字符串并打印a和b的值。
在第5行,函数func被调用,参数a被赋予值1,参数b被赋予值2。
因此,函数将输出1,2。
11、执⾏下⾯Python代码后
,输出的结果是? (
)
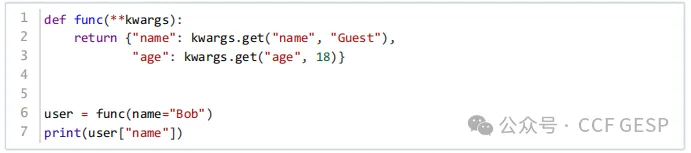
A. Guest
B. Bob
C.
18
D.
None
答案:B
解析:这段Python代码定义了一个函数func,它接受任意数量的关键字参数(kwargs),并返回一个字典。这个字典包含两个键:"name"和"age"。对于"name",它使用kwargs.get("name",
"Guest") 来获取值,如果"name"没有在kwargs中被指定,则默认值为"Guest"。对于"age",它使用kwargs.get("age",
18) 来获取值,如果没有指定"age",则默认值为18。
在第6行,函数func被调用,并且传递了name="Bob"作为参数。这意味着"name"的值被设置为"Bob"。
在第7行,打印出返回的字典中"name"键对应的值。
因此,输出的结果是"Bob"。
12、在⼀个棋盘上
,有⼀堆麦⼦ 。根据棋盘的规则 ,第1格放1粒麦⼦
,第2格放2粒麦⼦
,第3格放4粒麦⼦,
以此类推 ,每增加⼀格 ,麦⼦的数量翻倍 。下列程序⽤来计算在第 n(n
< 64) 格有多少粒麦⼦
,其中横线处填写的代码为? (
)

A.
lst[i - 1] * 2
B.
lst[i - 2] * 2
C.
lst[i - 1] + lst[i - 2]
D.
lst[-1] * 2
答案:A
解析:这个问题描述的是麦子的数量在棋盘上按照翻倍的规则增长,这是一个典型的等比数列问题,其中每一项都是前一项的两倍,也就是说,第n格的麦子数量应该是第n-1格麦子数量的两倍。
代码中的lst数组已经初始化为64个0,并且lst[1]被设置为1,这符合题目中第1格放1粒麦子的规则。在while循环中,我们需要从第2格开始计算,直到第n格。
正确答案是A.
lst[i-1] * 2。
13、⼩杨相信数字“1”、“3”、“5”能给他带来好运
,不喜欢数字“7”。他设计了⼀个计算数字幸运值的程序
。对于 数字中的所有字符 ,字符“ 1”幸运值为5,字符“3”幸运值为6,字符“5”幸运值为7,字符“7”的幸运值为-3,其他字符的幸运值为0,数字的幸运值即为其所有字符的幸运值之和
。请在下⾯程序空⽩处填上正确内容以实现计算某数字幸运值的功能。

A. ① ch
in dic.values() ② ans += dic[ch]
B. ① ch
in dic.items() ② ans += dic[ch]
C.
① ch in dic.keys() ② ans = dic[ch]
D.
① ch in dic ② ans += dic[ch]
答案:D
解析:这个问题要求我们填写代码,以实现一个功能:计算一个数字中每个字符的幸运值之和。幸运值是根据字符来定义的,其中“1”、“3”、“5”和“7”有特定的幸运值,其他字符的幸运值为0。
我们需要在代码的空白处填写逻辑,以检查当前字符ch是否有幸运值,如果有,则将其幸运值加到ans上。
选项分析:
A. ch
in dic.values() 检查 ch 是否是字典 dic 中的值之一,这是不正确的,因为我们应该检查的是键(字符)而不是值。
B. ch
in dic.items() 这个选项不正确,因为 dic.items() 返回的是字典项(键值对)的列表,而不是字典的键的列表。
C. ch
in dic.keys() 这个选项部分正确,它检查 ch 是否是字典的键之一,但是 ans
= dic[ch] 应该是 ans
+= dic[ch],因为我们需要累加幸运值。所以此选项不正确。
D. ch
in dic 这个选项正确,它检查 ch 是否是字典的键之一,ans
+= dic[ch] 正确地累加了幸运值。
因此,正确答案是D。
14、打开一个由小写英文和数字组成的文本文件notes.txt,将该文件中的每一个字母加密后写入到一个新文件encnypted_notes.txt,加密的方法是:a变成b,b变成c,……,z变成a,其它字符不变化。请在下面程序空白处填上正确内容以实现程序功能。

A.
① (ord(line[i]) + 1) % 26 ② ' '.join(list)
B.
① ord('a ') + (ord(line[i]) + 1 - ord('a ')) % 26 ② '
'.join(list)
C.
① (ord(line[i]) + 1) % 26 ② str(list)
D.
① ord('a ') + (ord(line[i]) + 1 - ord('a ')) % 26 ② str(list)
答案:B
解析:这道题考查的是ASCII码相关的知识点。在ASCII表中,小写字母'a'到'z'的值从97到122,是连续的26个数。按照题目的要求,对于字母'a'到'y'都是比较简单的,只要将其对应的ASCII值加1即可,但是对于'z'我们需要将它的ASCII值由122变为97。
选项分析:
A. ①(ord(line[i])
+ 1) % 26 这段代码会对一个小写字母进行计算并得到一个0到25的数值,而在ASCII表中0到25对应的并不是小写字母'a'到'z',所以这个选项不正确。②''.join(list) 正确地将列表中的字符连接成一个字符串。
B. ①ord('a')
+ (ord(line[i]) + 1 - ord('a')) % 26 对一个小写字母的ASCII值先减去'a'的ASCII值,将问题转化成只是在'a'到'z'这26个字母里的循环偏移(加1和取模操作)。最后再加上'a'的ASCII值就可以得到正确的加密后的字符。②''.join(list) 同样正确。
C. ①(ord(line[i])
+ 1) % 26 这个选项与A相同,不正确。 ②str(list)并不是把列表中的字符串连接起来,仅仅是把列表转化成字符串,如list=[1,2,3],str(list)为"[1,2,3]"
D. ①ord('a')
+ (ord(line[i]) + 1 - ord('a')) %
26 这个选项与B相同,是正确的。但是 ②str(list) 同样存在C选项中提到的问题。
因此,正确答案是B。
15、假设你管理⼀个实验室
,需要记录物品的领⽤情况 。每次领⽤时
,你会记录下领⽤的⽇期、物品名称以及 领⽤⼈的姓名
。这个信息将被保存在⼀个名为lab_issuance.txt的⽂本⽂件中。其要求如下:①在⽂件末尾追加新的物
品领⽤记录 ;②可以查看当前所有的物品领⽤记录
。请在下⾯程序空⽩处填上正确内容以实现程序功能。
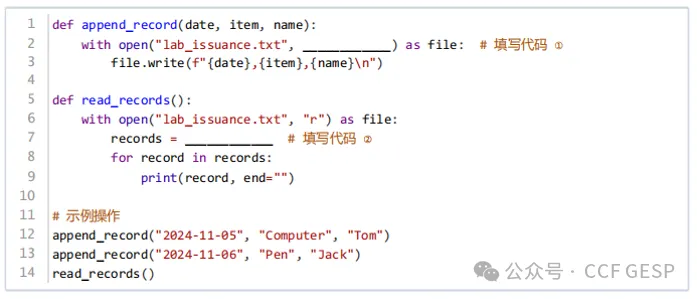
A. ①”a”
②file.readlines()
B. ①”a”
②file.readline()
C. ①”w”
②file.readlines()
D. ①”w”
②file.readline()
答案:A
解析:这个问题要求我们填写两个函数append_record和read_records中的空白部分,以实现在文件末尾追加记录和读取所有记录的功能。
对于append_record函数,我们需要在文件末尾追加新的记录,因此应该使用追加模式"a"打开文件。这样,每次写入操作都会在文件的末尾添加内容。如果使用"w"模式,对于已经存在的文件就会覆盖已有的内容。
对于read_records函数,我们需要读取文件中的所有记录。使用file.readlines()可以读取文件中的所有行,并将其作为一个列表返回,其中每一行都是列表中的一个元素。而使用file.readline()只能读取文件中的一行内容。
根据这些分析,正确的选项是:A.
① "a" ② file.readlines()
二、判断题(每题2分,共20分)
|
题号
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
|
答案
|
√
|
×
|
√
|
×
|
√
|
√
|
×
|
√
|
×
|
√
|
1、在Windows的资源管理器中为已有⽂件A建⽴副本的操作是Ctrl+C ,然后Ctrl+V。
答案:对
解析:题目表述正确。
2、执⾏下⾯Python代码后
,输出的结果是14。

答案:错
解析:这段Python代码使用了位运算符&(按位与)和左移运算符<<。
a
= 5 和 b
= 3,将5和3分别赋值给变量a和b。
result
= (a & b) << 1,这里首先执行 a
& b,即5和3的按位与操作。5的二进制表示是 101,3的二进制表示是 011。按位与操作的结果是 001,即十进制的1。
然后,将这个结果左移1位,即 001 变为 010,这是十进制的2。
因此,打印出的结果应该是2。题目描表述不正确。
3、执行下面Python代码,调用函数get_max可以得到一个None类型的数据。

答案:对
解析:在代码的最后一行print(type(get_max())),调用了get_max()函数而没有传入任何参数。由于没有参数传入,args将是一个空元组,因此函数将返回None。type(get_max())将返回NoneType,因为get_max()函数调用的结果是None。所以,输出的结果是NoneType。题目表述正确。
4、执⾏下⾯Python代码后
,输出的结果为[1,
3, 5, 7]。

答案:错
解析:lambda
x: x % 2 == 0 是一个匿名函数,它检查列表中的每个元素x是否能够被2整除(即x是否是偶数)。如果x
% 2 == 0 为True,则x是偶数,这个元素将被包含在filter函数的结果中。
然而,题目中给出的输出结果为[1,
3, 5, 7],这实际上是奇数列表,与代码中的筛选条件(筛选偶数)不符。根据代码逻辑,正确的输出应该是所有偶数的列表[2,
4, 6, 8]。
因此,题目表述不正确。
5、下面这段程序的时间复杂度为常数阶O(1)。

答案:对
解析:这段Python代码定义了一个函数fun,它接受一个参数n,但并没有在函数体中使用这个参数。函数体中只有一个操作,即打印字符串"Hello,
World!"。在这种情况下,无论输入规模如何,fun函数都只执行一个固定的操作,即打印一个字符串。这个操作的时间不依赖于输入规模,因此,这个函数的时间复杂度是常数阶O(1)。
因此,题目表述正确。
6、如果在函数内部对一个变量进行赋值操作,那么该变量默认为局部变量。
答案:对
解析:在Python中,如果在函数内部对一个变量进行赋值操作,那么这个变量默认是局部变量,其作用域仅限于函数内部。这意味着在函数外部无法访问这个变量。局部变量是在函数调用时创建的,并且在函数执行完毕后被销毁。如果需要在函数内部修改全局变量,必须使用global关键字来明确指出。
因此,题目表述正确。
7、在Pyton中,已执行1ist_of_tuples
=[(1,2),(3,4)],如果执行 1ist_of_tuples[@][1]=
5将不会报错。
答案:错
解析:在Python中,元组(tuple)是不可变的序列类型,这意味着一旦创建了元组,就不能修改其内容。尝试修改元组中的元素将导致TypeError。
题目中的代码list_of_tuples
= [(1, 2), (3, 4)] 创建了一个包含两个元组的列表。然后,尝试执行list_of_tuples[0][1]
= 5 来修改第一个元组的第二个元素。这将引发错误,因为元组是不可变的。
因此,题目表述不正确。
8、在Python中,[(i,i**2)for
i in range(5)]+[7,]是合法的表达式。()
答案:对
解析:题目中的表达式[(i,
i ** 2) for i in range(5)] 使用列表推导式创建了一个新列表,其中包含元组(i,
i ** 2),i从0到4。然后,使用+运算符将这个列表与另一个只包含单个元素7的列表拼接起来。
9、根据下面Pyton兩数定义,调用func()函数时如果参数分别为str和tuple类型,会报错。

答案:错
解析:函数func(a,
b) 定义为接受两个参数a和b,并返回a
+ str(b)。这里的str(b)会将b参数转换为字符串,无论b的原始类型是什么。因此,只要a是字符串类型,b可以是任何类型,str(b)都会成功地将其转换为字符串,然后与a连接。所以,调用func()不会报错。
因此,题目表述不正确。
10、在Python中,使用 with
open(file,’w')as
f:语句打开文件后,即使发生异常,文件资源通常也会被正确关闭。
答案:对
解析:在Python中,with语句用于包裹执行文件操作的代码块。这种结构的好处是,无论在代码块中是否发生异常,文件都会被正确关闭。这是通过上下文管理协议实现的,文件对象需要实现__enter__和__exit__两个方法。在with语句块的开始,__enter__方法被调用,返回的对象被赋值给as后面的变量(在这个例子中是f)。在with语句块的末尾,无论是否发生异常,__exit__方法都会被调用,这通常用于清理资源,如关闭文件。这是with语句的一个关键特性,它简化了资源管理,使得代码更加清晰和安全。
因此,题目表述正确。
三、编程题(每题25分,共50分)
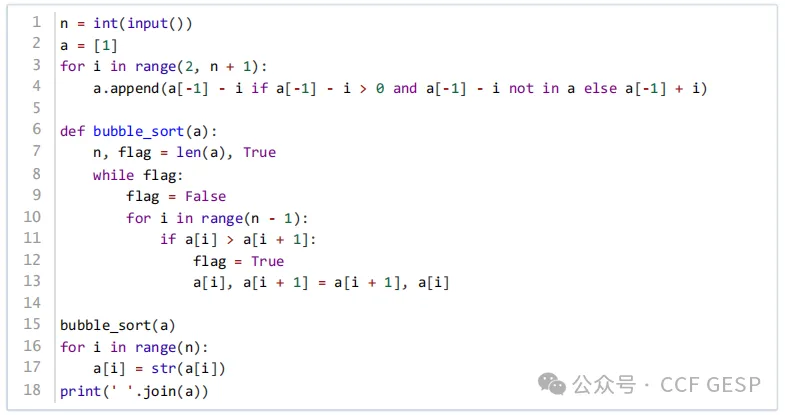
1、Recamán
题目描述
小杨最近发现了有趣的Recamán数列,这个数列是这样生成的:
·数列的第一项a1是1;
·如果ak-1-k是正整数并且没有在数列中出现过,那么数列的第k项ak为ak-1-k,否则为ak-1+k。
小杨想知道Recamán数列的前n项从小到大排序后的结果。手动计算非常困难,小杨希望你能帮他解决这个问题。
输入格式
第一行,一个正整数n。
输出格式
一行,n个空格分隔的整数,表示Recamán数列的前n项从小到大排序后的结果
输出样例1

输入样例1

输出样例2

输入样例2

样例解释
对于样例1,n
=5:
·a1=1;
·a1-2=
-1,不是正整数,因此a2=a1+2=3;
·a2-3=
0,不是正整数,因此a3=a2+3=6;
·a3-4=
2,是正整数,且没有在数列中出现过,因此a4=2;
·a4-5=
-3,不是正整数,因此a5=a4+5=7;
a1,a2,a3,a4,a5从小到大排序后的结果为1
2 3 6 7。
数据范围
对于所有数据点,保证1≤n ≤3000。
【解题思路】
为了生成Recaman数列的前n项并输出排序后的结果,我们可以按照以下步骤进行:
1.初始化:
·初始化一个数组 recaman 来存储数列的每一项,并设置 recaman[0]
= 1,因为数列的第一项是1。
·使用一个集合 seen 来记录已经出现过的数值。
2.生成Recaman数列:
·对于每一个 k从1到 n−1,根据规则计算 ak:
·每次计算完 ak后,更新 seen 集合,并将 ak添加到 recaman 数组中。
3.排序:
·使用冒泡排序算法对 recaman 数组进行排序。
4.输出结果:
·将排序后的数组输出为一行,每个元素之间用空格分隔。
参考程序
2、字符排序
题目描述
小杨有n个仅包含小写字母的字符串s1,s2,……,sn,小杨想将这些字符串按一定顺序排列后拼接到一起构成字符串t。小杨希望最后构成的字符串t满足:
·假设ti为字符串t的第i个字符,对于所有的j<i均有t<ti。两个字符的大小关系与其在字母表中的顺序一致,例如e<
g<p< s。
小杨想知道是否存在满足条件的字符串排列顺序。
输入格式
第一行包含一个正整数T,代表测试数据组数。
对于每组测试数据,第一行包含一个正整数n,含义如题面所示。
之后n行,每行包含一个字符串si。
输出格式
对于每组测试数据,如果存在满足条件的排列顺序,输出1,否则输出0。
样例
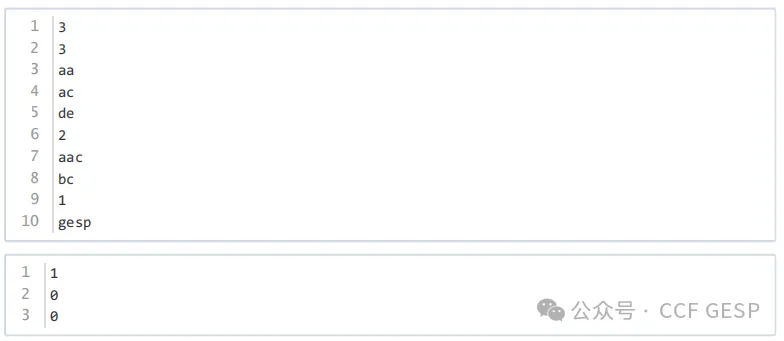
样例解释
对于第一组测试数据,一种可行的排列顺序为aa+ac+de,构成的字符串t为aaacde,满足条件。
对于全部数据,保证有1≤t,n≤100,每个字符串的长度不超过10。
【解题思路】
排序:首先,对字符串进行排序。
检查:接着,拼接排好序的字符串。
输出:如果在整个检查过程中没有发现任何违反规则的字符串对,那么我们认为存在满足条件的排列顺序,输出1;否则,输出0。
参考程序
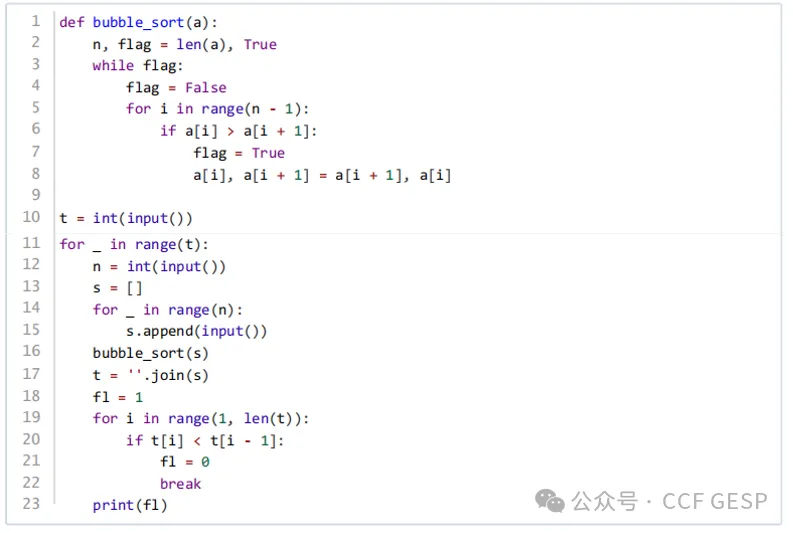
技术支持:GESP技术委员会委员
陈珊
策划:GESP技术委员会副主席
刘晓庆















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
