Python三级
2025年09月
一、单选题(每题2分,共30分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
答案 | D | C | D | A | A | D | C | D | B | C | B | B | A | D | C |
第1 题 人工智能现在非常火,小杨就想多了解一下,其中就经常听人提到“大模型”。那么请问这里说的“大模型”最贴切是指( )。
A.大电脑模型
B.大规模智能
C.智能的单位
D.大语言模型
【参考答案】D
【答案解析】大模型指的是大语言模型,是一种参数规模庞大,是一种能理解和生成人类语言的人工智能系统,核心能力是基于大量数据学习规律,从而完成对话、创作、分析等复杂任务
第2 题 在TCP协议中,完成连接建立需要通过( )握手。
A. 一次
B. 二次
C. 三次
D. 四次
【参考答案】C
【答案解析】TCP协议是互联网中最核心的协议之一,作用是在两台设备之间建立可靠的、有序的字节流传输,通信前必须通过 “三次握手” 建立连接,通过 “请求 -应答 -再确认” 建立双向通信基础
第3 题 二进制数 1101 0111 转换为十六进制是?()
A. 7C
B. C7
C. 7D
D. D7
【参考答案】D
【答案解析】二进制转换为十六进制可以采用“四合一”方式,四位二进制转换为一位十六进制,即1101为13,对应十六进制为D,0111为7,7在十六进制下也是7,转换结果为D7
第4 题 将十进制2025转化成二进制,可以使用下列哪个表达式?()
A. bin(2025)
B. oct(2025)
C. hex(2025)
D. int(2025, 2)
【参考答案】A
【答案解析】A选项的bin为转换二进制的函数,B选项的oct为转换8进制的函数,C选项中的hex为转换十六进制的函数,D选项的int(str,base)函数用于将字符串转换为整数,第二个参数base用于说明字符串的进制。直接使用整数2025作为第一个参数会引发错误。
第5 题 若 a = 4,b = 5,则(a | b) & 3的值为?( )
A. 1
B. 5
C. 0
D. 3
【参考答案】A
【答案解析】做位运算需要将数字转为二进制,4的二进制100,5的二进制101,做“或”运算结果为101,再与3的二进制011做“与”运算,结果为001,对应十进制1
第6 题 执行下面Python代码后,输出的结果是?()

A. None
B. 1
C. 2
D. 3
【参考答案】D
【答案解析】列表的pop()方法:该方法用于移除并返回列表中指定索引位置的元素,索引为负数时表示从列表末尾开始计数(-1为最后一个元素,-2为倒数第二个元素等),在代码中,列表lst = [1, 2, 3, 4],调用lst.pop(-2)表示移除并返回列表中倒数第二个元素。列表中元素的索引(从前往后)依次为:1对应 0,2对应 1,3对应 2,4对应3;从后往前数,倒数第二个元素是3(对应索引2),lst.pop(-2)会返回3,输出结果为3,正确答案是选项D
第7 题 已知列表lst = list(range(1, 10, 2)),下列语句输出结果为False的是?( )
A. print(lst[2] == lst[-3])
B. print(lst[: 2] == lst[: -3])
C. print(lst[: 1] == lst[0])
D. print(lst[3] == lst[-2])
【参考答案】C
【答案解析】首先,计算列表lst = list(range(1, 10, 2)),其结果为[1, 3, 5, 7, 9]。选项A:lst[2]是列表中索引为2 的元素,即5;lst[-3]是从后往前数第3 个元素,同样是5。两者相等,输出True。选项B:lst[:2]表示取索引0 到1 的元素,结果为[1, 3];lst[:-3]表示取到从后往前数第3 个元素之前的元素,即索引0 到1 的元素,结果也为[1, 3]。两者相等,输出True。选项C:lst[:1]表示取索引0 的元素组成的子列表,结果为[1];lst[0]是索引为0 的元素,即1。列表[1]与整数1 不相等,输出False。选项D:lst[3]是索引为3 的元素,即7;lst[-2]是从后往前数第2 个元素,即7。两者相等,输出True,输出结果为False的是选项C
第8 题 字典是键值对的容器,下列有关字典描述正确的是?()
A.字典一旦创建不可以被修改。
B.可以通过字典的键找到对应的值,也可以通过值来找到对应的键。
C.字典里面的键可以包含列表、字符串等数据类型。
D.字典里面的键可以是tuple(元组)类型。
【参考答案】D
【答案解析】选项A:字典是可变容器,创建后可以通过添加、修改、删除键值对进行修改,因此该描述错误。选项B:字典可以通过键直接找到对应的值,但由于不同的键可能对应相同的值,没有直接通过值找到对应键的内置方法,需自行遍历查找,因此该描述错误。选项C:字典的键必须是不可变数据类型(如字符串、数字、元组等),而列表是可变类型,不能作为键,因此该描述错误。选项D:元组是不可变数据类型,若元组中不包含可变元素,则可以作为字典的键,因此该描述正确,正确答案是选项D
第9 题 关于字典的.setdefault()方法,以下说法正确的是?( )
A.如果键不存在,setdefault()方法会返回 None并且不会修改原字典。
B.如果键不存在,setdefault()方法会将键和默认值添加到字典中,并返回默认值。
C.如果键存在,setdefault()方法会更新该键的值为指定的默认值。
D.如果键存在,setdefault()方法会返回默认值而不是键原有的值。
【参考答案】B
【答案解析】字典的.setdefault()方法的功能:该方法用于获取指定键的值,若键不存在,则会将该键和指定的默认值添加到字典中,并返回默认值;若键已存在,则返回该键对应的原有值,且不会修改原字典中的值。选项A:若键不存在,setdefault()会添加键和默认值并返回默认值,而非返回None且不修改字典,该说法错误。选项B:若键不存在,setdefault()会将键和默认值添加到字典中,并返回默认值,符合方法特性,该说法正确。选项C:若键存在,setdefault()不会更新键的值,而是返回原有值,该说法错误。选项D:若键存在,setdefault()返回的是键原有的值,而非默认值,该说法错误,正确答案是选项B
第10 题 执行下面Python代码后,输出的结果是?()

A. 0
B. 1
C. 3
D. ValueError
【参考答案】C
【答案解析】元组的index()方法:该方法用于查找指定元素在元组中首次出现的索引,语法为tuple.index(value, start, end),其中start和end为可选参数,限定查找的起始和结束索引(左闭右开)。在代码中,元组t = ('a', 'b', 'c', 'a'),调用t.index('a', 1)表示从索引1 开始查找元素'a'。元组中元素的索引依次为:'a'对应0,'b'对应1,'c'对应2,'a'对应3。从索引1 开始查找,首次出现的'a'在索引3 的位置,输出结果为3,正确答案是选项C
第11 题 已知元组 t = (1, 2, 3, 4, 5),下列哪个语句能够得到一个包含t中偶数的元组?()
A. result = [x for x in t if x % 2 == 0]
B. result = tuple(x for x in t if x % 2 == 0)
C. result = (x for x in t if x % 2 == 0)
D. result = {x for x in t if x % 2 == 0}
【参考答案】B
【答案解析】元组t = (1, 2, 3, 4, 5),目标是得到包含其中偶数(2、4)的元组。选项A:[x for x in t if x % 2 == 0]是列表推导式,结果为列表[2, 4],不是元组,不符合要求。选项B:tuple(x for x in t if x % 2 == 0)中,x for x in t if x % 2 == 0是生成器表达式,用tuple()函数将其转换为元组,结果为(2, 4),符合要求。选项C:(x for x in t if x % 2 == 0)是生成器表达式,返回的是生成器对象,不是元组,不符合要求。选项D:{x for x in t if x % 2 == 0}是集合推导式,结果为集合{2, 4},不是元组,不符合要求,正确答案是选项B
第12 题 关于集合中的remove()和discard()方法的区别,以下说法正确的是?
A.在移除的元素不存在时都会抛出KeyError。
B.在移除的元素不存在时remove()会抛出 KeyError,而discard() 不会。
C. discard() 会随机删除一个元素,remove()删除指定元素。
D.两者都只能通过索引删除元素。
【参考答案】B
【答案解析】集合中remove()和discard()方法的区别:两者和discard()方法都用于删除集合中的指定元素。当要移除的元素不存在时,remove()方法会抛出KeyError异常;而discard()方法不会抛出异常。选项A:错误,discard()在元素不存在时不会抛出KeyError。选项B:正确,符合两者在元素不存在时的行为差异。选项C:错误,两者都删除指定元素,discard()不会随机删除。选项D:错误,集合无索引,且两者都通过指定元素删除,正确答案是选项B
第13 题 如何判断集合s1 是否是 s2的真子集?( )
A. s1 < s2
B. s1 <= s2
C. s1.issubset(s2)
D. s1 in s2
【参考答案】A
【答案解析】依照题目描述,选项A:在 Python中,s1 < s2用于判断s1是否是s2的真子集(即s1包含于s2且s1不等于s2),符合真子集的定义,该选项正确。选项B:s1 <= s2判断的是s1是否是s2的子集(包括s1与s2相等的情况),并非专门判断真子集,该选项错误。选项C:s1.issubset(s2)的功能与<=相同,判断s1是否是s2的子集(包含相等情况),不专门用于真子集判断,该选项错误。选项D:s1 in s2用于判断s1是否是s2中的元素,而不是判断子集关系,该选项错误,正确答案是选项A
第14 题 在处理用户输入的标签字符串时,需要移除每个标签两端的空格并将所有标签转换为小写。已知输入为" Python, DATA Science , AI ",以下哪个代码能正确输出列表['python', 'data science', 'ai']?( )
A. 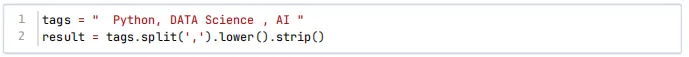
B.

C. D.
D. 【参考答案】D
【参考答案】D
【答案解析】输入字符串为" Python, DATA Science , AI ",目标是得到列表['python', 'data science', 'ai'],需要完成的操作是:按逗号分割标签,移除每个标签两端的空格,再将每个标签转为小写。选项A:tags.split(',')得到列表[' Python', ' DATA Science ', ' AI '],但列表没有lower()和strip()方法,会报错,无法得到目标结果。选项B:先strip()移除字符串两端空格得到"Python, DATA Science , AI",再lower()转为小写得到"python, data science , ai",最后split(',')得到['python', ' data science ', ' ai'],每个元素两端仍有空格,不符合要求。选项C:replace(' ', '')会移除所有空格,得到"Python,DATAScience,AI",转为小写后分割得到['python', 'datascience', 'ai'],原标签中的空格(如DATA Science中的空格)被误删,不符合要求。选项D:先split(',')得到[' Python', ' DATA Science ', ' AI '],再通过列表推导式对每个元素执行strip()(移除两端空格)和lower()(转为小写),最终得到['python', 'data science', 'ai'],符合目标结果,正确答案是选项D
第15 题 下面程序是用枚举法查找最大值的索引,横线处应该填写的是?()

A. arr[maxIndex] > arr[i]
B. arr[i - 1] > arr[maxIndex]
C. arr[i] > arr[maxIndex]
D. arr[i + 1] > arr[maxIndex]
【参考答案】C
【答案解析】题面程序通过枚举法查找列表中最大值的索引。初始时将maxIndex设为0(即假设第一个元素为最大值),然后从索引1开始遍历列表,若当前元素大于maxIndex对应的元素,则更新maxIndex为当前索引,最终maxIndex即为最大值的索引。横线处需要填写的条件是判断当前元素是否大于maxIndex对应的元素。在循环中,i是当前遍历的索引,arr[i]是当前元素,arr[maxIndex]是目前已知的最大值元素。因此,当arr[i] > arr[maxIndex]时,说明当前元素更大,需要更新maxIndex为i。选项C:arr[i] > arr[maxIndex]表示当前元素大于已知最大值,需要更新maxIndex,符合逻辑,正确答案是选项C
二、判断题(每题2分,共20分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
答案 | × | √ | √ | √ | × | √ | × | × | × | √ |
第1 题 在集成开发环境里调试程序时,要注意不能修改源程序,因为如果修改,就要终止调试、关闭该文件并重新打开,才能再次开始调试。( )
【参考答案】错误
【参考解析】该说法错误。在集成开发环境(IDE)中调试程序时,通常支持在调试过程中修改源程序。多数IDE(如PyCharm、VS Code 等)具备实时编辑功能,修改后无需终止调试、关闭再重新打开文件,只需保存修改并根据IDE 设置,即可继续调试,以提高调试效率
第2 题 在Python语言中,表达式0xFE == 254 的值为True。
【参考答案】正确
【参考解析】该说法正确。在Python 中,0xFE是十六进制表示的整数,其中F对应十进制的15,E对应十进制的14。十六进制转换为十进制的计算方式为:15×16¹ + 14×16⁰ = 240 + 14 = 254。因此,0xFE与十进制的254 相等,表达式0xFE == 254的值为True
第3 题 执行下面Python代码后,输出两个True。
 【参考答案】正确
【参考答案】正确
【参考解析】该说法正确。在代码中,t1 = (1, 2, 3)创建了一个元组,t2 = t1表示将t2指向t1所引用的同一个元组对象(即t1和t2引用内存中的同一个对象)。t1 == t2用于判断两个元组的内容是否相等,由于它们引用同一个元组,内容必然相同,因此结果为True。t1 is t2用于判断两个变量是否引用同一个对象,此处t1和t2指向同一个元组对象,因此结果也为True
第4 题 执行下列两段Python代码,输出的结果相同。
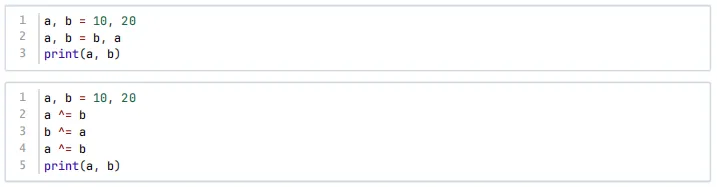 【参考答案】正确
【参考答案】正确
【参考解析】该说法正确。第一段代码使用Python 的变量交换特性,a, b = b, a直接将a和b的值交换,执行后a为20,b为10,输出20 10。第二段代码使用异或运算实现变量交换:初始a=10(二进制1010),b=20(二进制10100)。第一步a ^= b:a变为10 ^ 20 = 30(二进制11110)。第二步b ^= a:b变为20 ^ 30 = 10(二进制1010)。第三步a ^= b:a变为30 ^ 10 = 20(二进制10100)。最终a为20,b为10,输出20 10。两段代码输出结果相同
第5 题 下列程序用于输出1至20中,2和3的共同倍数。
 【参考答案】错误
【参考答案】错误
【参考解析】程序中if语句使用的and逻辑,是将不是2的倍数同时不是3的倍数标记为0,应该将and逻辑改为or逻辑,这样就是不能被2或者不能被3整除都会被标记剔除,最后统计剩下的都是能被2和3同时整除的数字
第6 题 执行下列Python代码,输出的结果是12。
 【参考答案】正确
【参考答案】正确
【参考解析】列表lst通过列表推导式生成,元素为1 到20(即[1, 2, 3, ..., 20])变量cnt初始值为0。循环从20 开始,递减到2,共执行19 次(i=20,19,…,2)循环中判断lst[i-1] + lst[i-2]的和对3 取余是否不为0(即(和% 3) != 0),若满足则cnt加1经计算,满足条件的情况共12 次:
[19 18] [18 17] [16 15] [15 14] [13 12] [12 11] [10 9] [9 8] [7 6] [6 5] [4 3] [3 2]
第7 题 在对用户输入的标签进行次数统计时,可以使用如下的方法,把标签字符串"python,java,python,c++,java"转换成为字典{'python': 2, 'java': 2, 'c++': 1}。
 【参考答案】错误
【参考答案】错误
【参考解析】这种方法不正确,无法得到预期的统计结果,程序中直接对字符串tags进行遍历(for tag in tags),这会逐字符处理字符串,而非按逗号分割后的标签处理。例如,字符串"python,java,..."会被拆分为'p'、'y'、't'、'h'、...、','、'j'、'a'等单个字符,因此,最终的result字典会统计每个字符出现的次数,而非每个标签的出现次数,与预期的{'python': 2, 'java': 2, 'c++': 1}完全不符,正确的做法是先按逗号分割字符串得到标签列表,例如tags.split(','),再遍历列表统计每个标签的次数。
第8 题 在分析两个商品的购买用户群体时,可以使用如下方法,找出同时购买商品A和商品B的用户。
 【参考答案】错误
【参考答案】错误
【参考解析】这种方法不正确,buyers_a ^ buyers_b 无法找出同时购买商品A 和B 的用户,找出同时购买两款商品的用户,需要用集合的交集运算,而^ 是集合的对称差集运算,返回只属于其中一个集合、不属于另一个集合的元素,功能完全相反。& 是集合交集:返回同时属于两个集合的元素,才是 “同时购买 A 和B 的用户”
第9 题 可以使用如下方法检查输入的网址(如:https://gesp.ccf.org.cn/)是否使用了安全的HTTPS协议,不会产生误判。
 【参考答案】错误
【参考答案】错误
【参考解析】这种描述不正确,该方法可能产生误判。仅通过判断字符串中是否包含 “https” 无法准确验证是否使用HTTPS 协议。如某些网址 “http://example.com?https=1”中虽包含 “https”,但实际使用的是http 协议,会被误判为https。正确的https 协议网址格式应以 “https://” 开头,而不是含有https即可
第10 题 可以使用枚举算法来找出小于100的所有质数。
【参考答案】正确
【参考解析】使用枚举法对1-100范围内每个数据进行判断,可以正确找出所有质数,描述正确
三、编程题(每题25分,共50分)
3.1编程题1
试题名称:数组清零
时间限制:1.0 s
内存限制:512.0 MB
3.1.1 题目描述
小A有一个由n个非负整数构成的数组a=[a1,a2,...an]。他会对数组a重复进行以下操作,直到数组a只包含0。在一次操作中,小A 会依次完成以下三个步骤:
1.在数组a中找到最大的整数,记其下标为k。如果有多个最大值,那么选择其中下标最大的。
2.从数组a所有不为零的整数中找到最小的整数aj。
3.将第一步找出的ak减去aj。
例如,数组a=[2,3,4]需要7次操作变成[0,0,0]:
[2,3,4]→[2,3,2]→[2,1,2]→[2,1,1]→[1,1,1]→[1,1,0]→[1,0,0]→[0,0,0]
小A想知道,对于给定的数组a,需要多少次操作才能使得a中的整数全部变成0。可以证明,a中整数必然可以在有限次操作后全部变成0。你能帮他计算出答案吗?
3.1.2 输入格式
第一行,一个正整数n,表示数组a的长度。
第二行,n个非负整数a1,a2,...an,表示数组a中的整数。
3.1.3 输出格式
一行,一个正整数,表示a中整数全部变成0所需要的操作次数。
3.1.4 样例
3.1.4.1 输入样例1
3.1.4.2 输出样例1
 3.1.4.3 输入样例2
3.1.4.3 输入样例2
3.1.4.4 输出样例2
3.1.5 数据范围
对于所有测试点,保证1≤n ≤100,0≤ai≤100。
3.1.6 参考程序
【解析】首先接收输入的数据个数和列表元素,初始化cnt为0,通过循环持续处理列表,直到数组中的最大元素为0时停止:每次循环开始,操作次数加1。找出当前列表中的最大元素,以及该最大元素的下标(若存在多个相同的最大元素,默认取第一个出现的下标),接下来找出列表中所有大于0的元素中的最小值,将找到的最大元素所在位置的值减去这个最小值。重复上述过程,直到列表中所有元素都变为0,最后输出总的操作次数
3.2 编程题 2
试题名称:日历制作
时间限制:1.0 s
内存限制:512.0 MB
3.2.1 题目描述
小A 想制作2025年每个月的日历。他希望你能编写一个程序,按照格式输出给定月份的日历。
具体来说,第一行需要输出MON TUE WED THU FRI SAT SUN,分别表示星期一到星期日。接下来若干行中依次输出这个月所包含的日期,日期的个位需要和对应星期几的缩写最后一个字母对齐。例如,2025年9月1日是星期一,在输出九月的日历时,1号的个位1就需要与星期一MON的最后一个字母N对齐。九月的日历输出效果如下:

你能帮助小A 完成日历的制作吗?
3.2.2 输入格式
一行,一个正整数m,表示需要按照格式输出2025 年m月的日历。
3.2.3 输出格式
输出包含若干行,表示2025 年m月的日历。
3.2.4 样例
3.2.4.1 输入样例1
3.2.4.2 输出样例1
3.2.4.3 输入样例2
3.2.4.4 输出样例2
3.2.5 数据范围
对于所有测试点,保证1≤ m≤ 12。
3.2.6 参考程序
【解析】题目要求根据输入的月份,打印出该月份的日历,以星期为单位进行排版。定义列表,用于存储每个月的天数,索引1到12 分别对应1 到12 月,2月默认28天,未考虑闰年情况,,先接收输入的目标月份,然后打印出星期表头(MON到SUN),需要计算出目标月份第一天是星期几,这里以1 月1日为星期三作为基准:从1月开始,累加目标月份之前所有月份的天数,再对7取余,得到目标月份1号是星期几,结果为0时对应星期日,1对应星期一,以此类推。排版打印时,先根据目标月1号的星期数,在月初前添加相应数量的空白(每个空白占3个字符)。然后遍历该月所有天数,每个日期占3个字符(要求是右对齐),按每周7天的格式分组:当一组天数满7个时,将这组日期拼接成字符串并打印,再开始新的一组;遍历结束后,若仍有剩余未打印的日期,将其拼接成字符串并打印
















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
