Linux 7.2 的合并窗口于 2026 年 6 月打开,调度器、存储和 Rust 基础库三个方向同时收到精准修补。Cache Aware Scheduling(CAS)经过超过一年的社区审查,以 CONFIG_SCHED_CACHE 选项正式合入主线,调度器首次真正理解现代多 LLC CPU 的缓存分区布局。同期,字节跳动工程师 Fengnan Chang 的两行代码让 EXT4 和 XFS 在高 IOPS 场景 IOPS 提升约 5%;Rust zerocopy 库(约 39,000 行)开始系统性消除内核 Rust 代码中的 unsafe 块;/proc/filesystems 的读取速度在结构重构后最高提升 444%。这几项改进的共同线索:内核旧抽象对新硬件的积压欠债,在高并发场景被逐一暴露,而偿还代价往往出乎意料地低。
字节跳动发现的隐性代价:memset 和内存写带宽
iomap_iter() 是 Linux VFS 层中 EXT4 和 XFS 共用的文件映射迭代框架。每次迭代结束时,旧代码对 iomap 结构体执行 memset 清零——这是防御性编程,防止下一次迭代读到残余数据。问题在于:调用者在迭代完成后直接丢弃该结构体,这次内存写完全无用。字节跳动工程师 Fengnan Chang 在测试 4K 随机读场景(NVMe 轮询模式,通过 io_uring 提交)时测量到,这个冗余的 memset 在高频 I/O 路径上消耗了可观的内存写带宽。他在提交说明中写道:
"Skip the memset of the iomap in iomap_iter() once the iteration is done. In high-IOPS scenarios (4k randread NVMe polling via io_uring) the pointless memset wasted memory write bandwidth; this improves IOPS by about 5% on ext4 and xfs."
两行代码位移,EXT4 和 XFS 在对应场景下 IOPS 提升约 5%。字节跳动作为中国最大的自研存储基础设施运营者之一,长期向上游贡献内核补丁,这次优化是近期最直接的性能收益案例。同一个 VFS pull request 还包含为 XFS 添加 FS-VERITY 支持的基础设施——以 post-EOF Merkle tree 方式存储文件完整性校验数据,补上 XFS 相对 ext4 的一项缺口。
调度器的拓扑盲区:从 2017 年的公开规格到 2026 年的内核支持
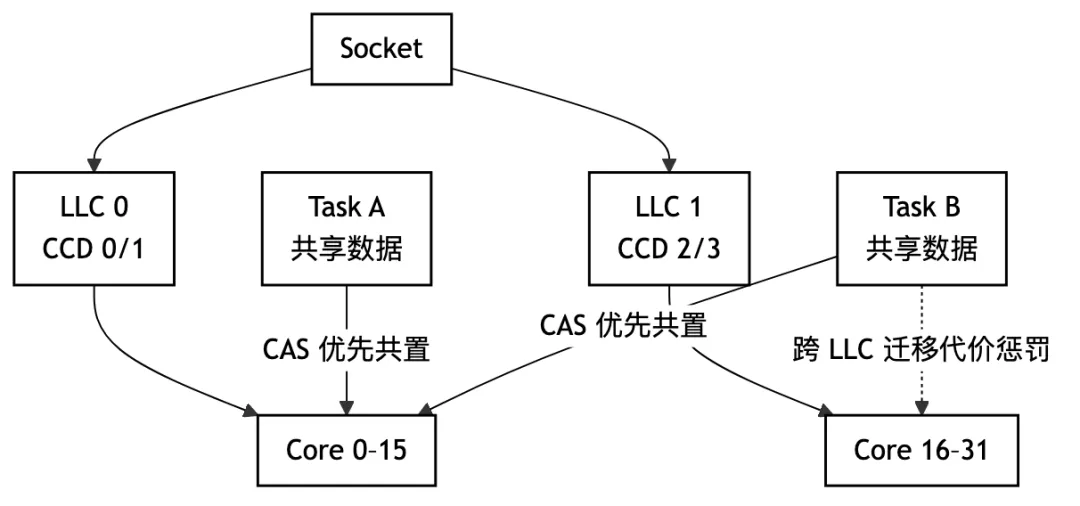
早期 Linux 调度器隐含了一个前提:同一个 CPU socket 上的所有核共享最后一级缓存(LLC)。这个前提在单芯片、小核数时代基本成立。AMD EPYC 从 2017 年 Naples 世代起就采用多 die 多 LLC 分区设计——每个 Zeppelin die 包含两个 CCX(Core Complex),每个 CCX 各有独立 L3;2019 年 Rome 世代进一步演化为 IOD + 多个 CCD(Core Complex Die)的分离架构,每个 CCD 含独立 L3;Intel Xeon 6 同样采用多 LLC 分区设计。调度器因此会把两个共享热数据的任务分配到属于不同 LLC 的核上,每次跨分区的数据访问都需要绕过本地 LLC,产生额外延迟,并可能引发 cache bouncing(同一缓存行在多个 LLC 间来回失效同步)。
多 LLC 布局是这些处理器的公开规格,内核社区早有讨论。但调度器改动需要同时满足三个约束:不破坏负载均衡、对 LLC 亲和敏感度不同的工作负载保持可配置、感知 LLC 拓扑的调度路径本身不能引入额外开销。这三个约束的交叉让补丁经历了超过一年的审查和迭代,主导工作由 Intel 工程师推进。
CAS 的机制:共置策略与调度域权重
Cache Aware Scheduling 通过 CONFIG_SCHED_CACHE Kconfig 选项启用。核心逻辑是:当调度器识别出存在数据共享关系的任务组时,在负载均衡时优先将它们维持在同一 LLC 域内。在调度域层次结构中,LLC 边界被赋予更高的迁移代价权重,使得跨 LLC 的任务迁移更为保守。
SD_ASYM_CPUCAPACITY 的 SMT 感知改进让大小核混合场景(如 Intel P/E-core 架构)的调度决策更准确;cfs_rq 和 sched_entity 的内存布局调整减少了调度器自身热路径上的缓存 miss——调度器在感知外部任务缓存拓扑的同时,自身内存访问模式也在同方向优化。
在 AMD EPYC Turin、Intel Xeon 6 和 AMD Zen 5 HEDT 平台上的测试中,PostgreSQL 查询吞吐、Valkey 请求延迟和网络包处理速率均有可测量的提升,具体幅度因工作负载和 CPU 型号而异。AMD EPYC 在国内企业私有云和公有云服务器中大量部署,各大云厂商和金融行业的数据库集群直接受益于 CAS 的主线合入。
zerocopy:39,000 行代码移交的是 unsafe 的归属权
39,000 行的数字容易产生误解——这不是新的功能实现,而是一个库的引入,它改变的是 unsafe 代码在内核中的归属结构。
Rust 中的 unsafe 有明确语义:编译器放弃对该代码块的内存安全验证。内核 Rust 代码无法完全回避 unsafe:与 C 代码互操作、处理原始指针、做跨类型的字节级转换,这些场景编译器独立无法验证。历史上每个调用点各自维护 unsafe impl,散点分布难以审计。
zerocopy 提供可派生的 trait(FromBytes、IntoBytes、Unaligned 等)和编译期宏(transmute!),让字节级内存操作通过类型系统得到验证。设计上,库作者一次性证明某个类型的字节布局安全,所有调用者复用这个证明——unsafe 的责任从每个调用点收归到 trait 实现处,而不是分散在代码库各处。
Miguel Ojeda 在提交说明中引用了 zerocopy 的自述:"Fast, safe, compile error. Pick two. Zerocopy makes zero-cost memory manipulation effortless. We write unsafe so you don't have to." 他验证了在 Nova GPU 驱动的一个 unsafe impl 替换案例中,zerocopy 版本在开启 debug-assertions 后没有剩余的 panic 路径,而旧代码保留若干 ub_checks。zerocopy 是 Rust crate 生态下载量最高的库之一,Rust 编译器本身也依赖它,合并到内核时仅需 +2/-3 行适配。同期,Rust Binder 代码接入 AutoFDO(自动反馈导向优化)后测得约 13% 的性能提升。
/proc/filesystems 的链表遗产:444% 来自哪里
/proc/filesystems 列出内核当前支持的文件系统列表,内容通常不超过数十行文本。旧实现是手写链表,每次读取时逐条指针追踪、逐行 printf 输出。读取本身开销不大,但它的调用频率远超直觉:libselinux 在内部查询这个文件以确认文件系统类型支持情况,而 libselinux 被链接到大量系统工具——包括 sed。
Christian Brauner 的改动将文件系统列表改为 RCU(Read-Copy-Update)管理,在注册/注销文件系统时预生成完整字符串并缓存,后续每次读取直接返回缓存内容,绕过 open/close 的引用计数维护。并发读者不再互相阻塞,可伸缩性同步提升。
"The file was a mess with a hand-rolled linked list in desperate need of a cleanup... the string emitted when reading /proc/filesystems is pre-generated and cached instead of pointer-chasing and printfing entry by entry on every read."
改动后读取性能最多提升 444%。一个 proc 文件的重构能产生数倍加速,原因在于原有的线性遍历加 printf 在高频访问下代价被线性放大,而缓存字符串的读取代价几乎是常数。
这几项改进共享一个触发模式:硬件拓扑变化(多 LLC 分区)或访问模式变化(高 IOPS NVMe、高并发 proc 读取)让原有代码路径的性能假设失效,一旦失效变得可量化,修复的代码量通常很小。运营 AMD EPYC 服务器的数据库和缓存集群、EXT4/XFS NVMe 存储密集型场景、SELinux 高并发环境,这三类部署对 7.2 的几个方向都有具体的性能预期可对照。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
