为什么我选择 Python + PostgreSQL,而不是 Java + Oracle?
今年决定自己动手做一套 ERP 的时候,第一个要回答的问题不是"做什么功能",而是"用什么技术栈"。
这个问题我翻来覆去想了两周。因为这个选择一旦做了,后面三年的开发方向、部署成本、AI 集成的难易程度,全都被锁死了。
最后我选了 Python + PostgreSQL。
有朋友不理解:"ERP 不都应该是 Java 吗?Python 扛得住企业级?"
我说:"你应该问我:为什么没有选 Java + Oracle。"
20 年前的老答案,回答不了今天的新问题
国内主流 ERP 厂商,十家有八家用 Java + Oracle。这是历史惯性。
20 年前我刚入行的时候,企业级软件只有这条路。Java 是唯一能写"正经企业应用"的语言,Oracle 是唯一让 CIO 睡得着觉的数据库。在那个年代,选别的意味着"不专业"。
但那是 20 年前。
今天的环境完全变了:容器化部署、AI 大模型、向量检索、小团队+AI 的开发模式——这些东西都不是 Java + Oracle 时代的设计前提。Java 的 Spring Boot 在努力追赶云原生,但它的基因是 2000 年代的。Oracle 的自治数据库很酷,但它的授权模式是 1990 年代定下来的。
继续用旧时代的答案回答新时代的问题,这不是保守,这是跑错了方向。
技术选型没有"最好",只有"最匹配"
我经常看到技术选型争论陷入无意义的对抗。Java 性能好 vs Python 写得快,Oracle 稳定 vs PostgreSQL 免费。
这种讨论忽略了一个根本问题:你的团队规模、开发节奏、产品形态,决定了什么技术栈是"对的"。
来说说我的约束条件:
- 团队只有 3-5 人,没有专职 DBA,没有运维团队,没有测试团队。
- 小团队的高效迭代模式下,写代码。每行代码的产出效率都至关重要。
- 要同时支持 SaaS 多租户和客户私有化部署。不能假设客户"养得起 DBA"。
- AI 是核心竞争力——不是加一个聊天机器人,而是嵌入每一个业务操作环节。
在这个约束下,答案就清晰了:
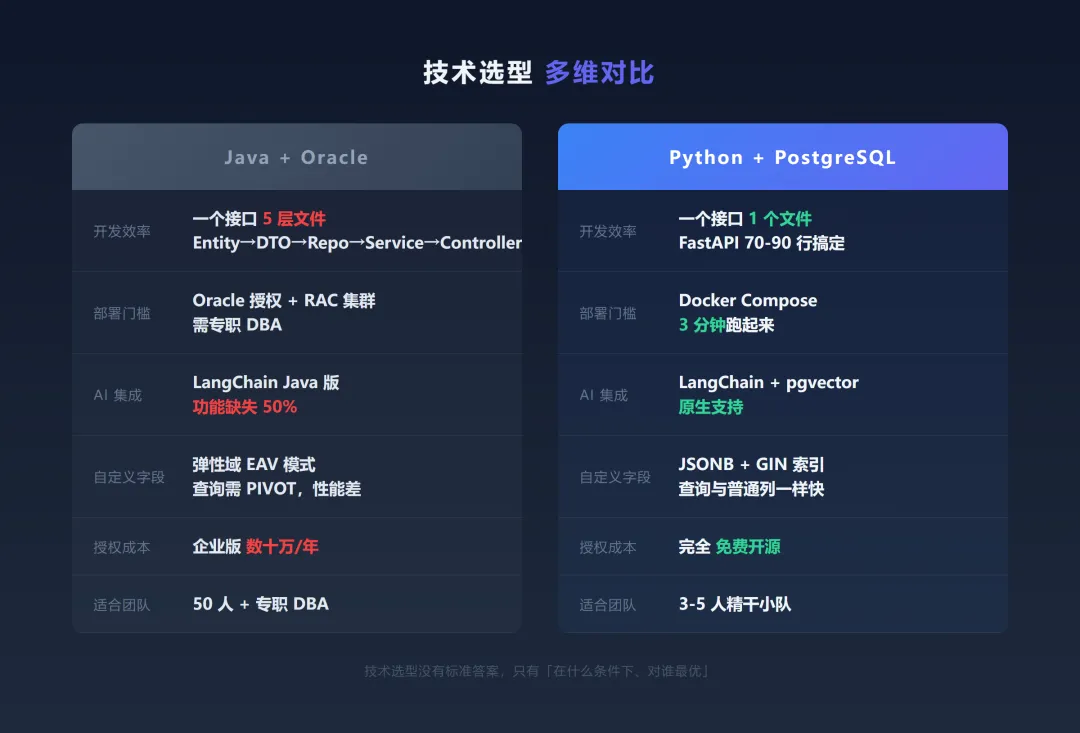
Java 写一个带校验的创建接口,Entity → DTO → Repository → Service → Controller,五层文件,每层至少 30 行。Python FastAPI 一个文件,70 行搞定。对小团队开发资源有限的团队来说,文件数量本身就是认知负担。
Oracle 企业版部署动不动上百万,还要养专职 DBA。PostgreSQL 一个 Docker 镜像,在客户服务器上三分钟跑起来。私有化部署的门槛从"需要 IT 部门"降到"会用命令行就行"。
技术选型的本质不是选最好的技术,是选最匹配你的约束条件的技术。
Python 的真正优势:AI 时代的胶水语言
很多人对 Python 的刻板印象还停留在"脚本语言""性能不行""不适合企业级"。
但 FastAPI 的异步性能已经不输 Spring Boot,Pydantic 的类型系统给了编译期的安全感,SQLAlchemy 2.0 解决了 ORM 的并发问题。我现在的 ERP 后端核心流程,一个中等复杂的接口 FastAPI 版约 70-90 行,同样的逻辑 Spring Boot 保守 300 行起。
但真正让我无法拒绝 Python 的,是 AI 集成的便利性。
我的系统里,AI 不是外挂功能。它嵌入在每一个操作环节里:创建采购订单时自动对比供应商历史报价,发票 OCR 录入时自动匹配 PO 行,月末结账时自动定位差异源头。
这些能力依赖的底层组件——向量检索(pgvector)、大模型编排(LangChain)、文本嵌入(sentence-transformers)——Python 是它们的第一语言。用 Java 不是不能做,但胶水代码的量足够让一个小团队崩溃。
Python 是 AI 时代的"胶水语言"。而"胶水"恰好是小团队最需要的东西。
PostgreSQL:一把被低估的瑞士军刀
ERP 数据库有四个硬要求:事务一致性、多租户隔离、灵活自定义字段、AI 集成。
Oracle 在前两点上是王者——40 年的积累,RAC 高可用、Flashback 闪回、AWR 性能诊断,每一样都是艺术品。
但在后两点,局势就变了。
自定义字段这个需求,制造业要"批次号",零售业要"门店编码",每个客户的字段都不一样。传统 Oracle ERP 的弹性域方案,查询一个供应商的所有自定义字段要 PIVOT 一次,性能灾难。PostgreSQL 的 JSONB 直接存 JSON,支持 GIN 索引,查自定义字段跟查普通列一样快。
AI 集成方面,pgvector 扩展让 PostgreSQL 原生支持向量检索。业务数据和 AI 向量在同一个数据库里,不用额外搭一个 Pinecone。对小团队来说,少一个组件就是少一个深夜报警电话。
多租户隔离,PostgreSQL 的 Schema 隔离方案,十几行代码搞定。Docker 镜像只有 200MB,客户现场五分钟部署完毕。
还有一个无法回避的因素:Oracle 企业版一年的授权费,够一个 3 人小团队发两个月工资。PostgreSQL 完全免费。省下来的每一分钱,都是多活一个月的生存空间。
Docker Compose 就够了
大厂的方案动不动就是 K8s 集群 + 负载均衡 + 多机房容灾。对 50 人的运维团队是标配,对 3 人小团队是自杀。
我选的是 Docker Compose 单机部署。一套文件,三个容器——PostgreSQL + FastAPI + Nginx——总内存不超过 2GB。客户想私有化部署?发一个 zip 过去,解压,一行命令跑起来。
如果客户量上来需要扩展,我的模块化分包设计可以随时拆——把采购模块拉出来变独立容器,加个 API Gateway 就行。但这种复杂度,只在需要的时候才加。
过早优化是万恶之源。过早分布式也是。
不是 Java + Oracle "不好"
我必须做一个澄清。
我见过无数用 Java + Oracle 跑得比高铁还稳的 ERP 系统。它们的成功不是因为技术栈"先进",是因为团队大、有专职 DBA、有 20 年代码积累。
Java + Oracle 是"兵团作战"的最优解——当你有 50 人的团队,你需要强制性的架构约束来防止代码腐化。当你有专职 DBA,Oracle 的 AWR 报告能让慢查询优化到毫秒级。
但我的情况是什么?我主导架构设计,AI 辅助编码,3-5 人小团队。我没有兵团,我只有特种兵。
特种兵不能背重型装备翻山。他需要轻便、灵活、能快速适应地形的工具。Python + PostgreSQL 就是我的轻型装备。
三个用血换来的教训
技术选型做完三个月后,我才真正理解了三件事:
第一,ORM 是个深坑。 SQLAlchemy async 的关联查询非常脆弱,不小心就把对象传到 greenlet 外面直接崩溃,报错像天书。现在的铁律:ORM 只管单表 CRUD 和事务边界,所有 JOIN 用手写 SQL。这条规则避免了我 80% 的调试时间。
第二,JSONB 不是银弹。 我一开始把所有自定义字段都塞进 JSONB,觉得太灵活了。三个月后发现高频查询的字段即使有 GIN 索引,性能也远不如正规列。现在策略:热数据建列,冷数据放 JSONB。
第三,AI 的真正成本不在模型调用。 很多人以为"集成 AI"就是调一下 API。真正的困难是:怎么把 ERP 的业务上下文——当前用户、当前单据、关联数据——结构化地喂给 AI?这个上下文工程的代码量,是调用 API 的 10 倍。好消息是 Python 在这块有天然的便利。
不要抄我的答案
如果有 CIO 问我"该选什么技术栈",我会说:"先给我看看你的团队。"
如果你有 20 人 Java 团队,Oracle 授权费不是问题——继续用 Java + Oracle。稳定、可靠、人才好招。
但如果你是小团队、要快速验证产品、要把 AI 作为核心竞争力——至少认真看一下 Python + PostgreSQL 这条路。不是我说的对,是你的约束条件可能跟我一样。
技术选型没有标准答案,只有"在什么条件下、对谁最优"。
我的条件是这样,所以我选了这个。你的条件是什么?
20 年企业数字化从业者。头 10 年扎根 ERP 实施一线,之后走出去看了不同的世界——先后在项目协作平台、云计算与视觉 AI 服务商、全球 BPM 软件厂商担任售前专家。近 4 年回归 ERP 赛道,用 AI 原生的思路从零打造新一代 ERP。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
