6种智能体意图识别方案深度解析,附Python实战代码
- 2026-06-28 06:57:45

向AI转型的程序员都关注公众号 机器学习AI算法工程
你的智能体是不是经常"答非所问"?
用户说"我想退货",它给你讲了一堆产品功能;用户问"今天天气怎么样",它开始推荐相关商品。
问题不在模型不够强,而在于你的系统根本没搞懂用户想要什么。
意图识别(Intent Recognition)是智能体调度系统的"第一道关卡"——用户输入一句话,系统必须先判断"他想干嘛",然后才能把任务路由到正确的处理模块。
做对了,用户觉得"这AI真聪明";做错了,用户直接关掉页面。
这篇文章会把当前业界主流的 6种意图识别方案讲清楚,重点拆解 LLM零样本分类和 RAG增强意图识别两种最新方案,附完整Python代码,看完就能用。
· · ·
一、意图识别在智能体调度中的位置
一个完整的智能体调度系统长这样:
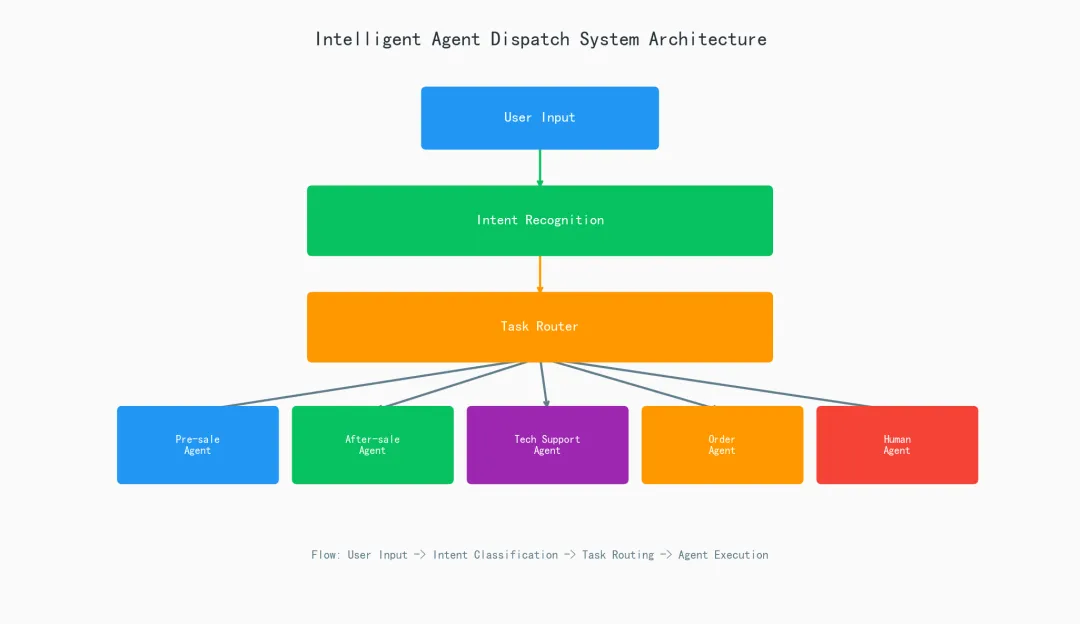
意图识别的核心任务就是:把非结构化的用户输入,映射到预定义的意图类别上。
比如:
看起来简单?但实际项目中,用户表达千变万化:"退退退"、"不想要了能退不"、"买多了想退一个"——都是退货意图,但措辞完全不同。
这就是为什么需要不同的方案来应对。
· · ·
二、6种方案全景
前三种是经典方案,后三种是当前主流。我们重点拆解 方案4和方案5。
· · ·
三、方案四:LLM零样本/少样本分类(无训练数据,快速验证)
核心思想
不训练任何模型,直接利用GPT-4o、Claude、DeepSeek等大模型的语义理解能力,通过精心设计的Prompt来完成意图分类。
一句话理解:把大模型当"分类器"用——你告诉它有哪些类别,给几个示例,它就能准确分类新输入。
方案架构
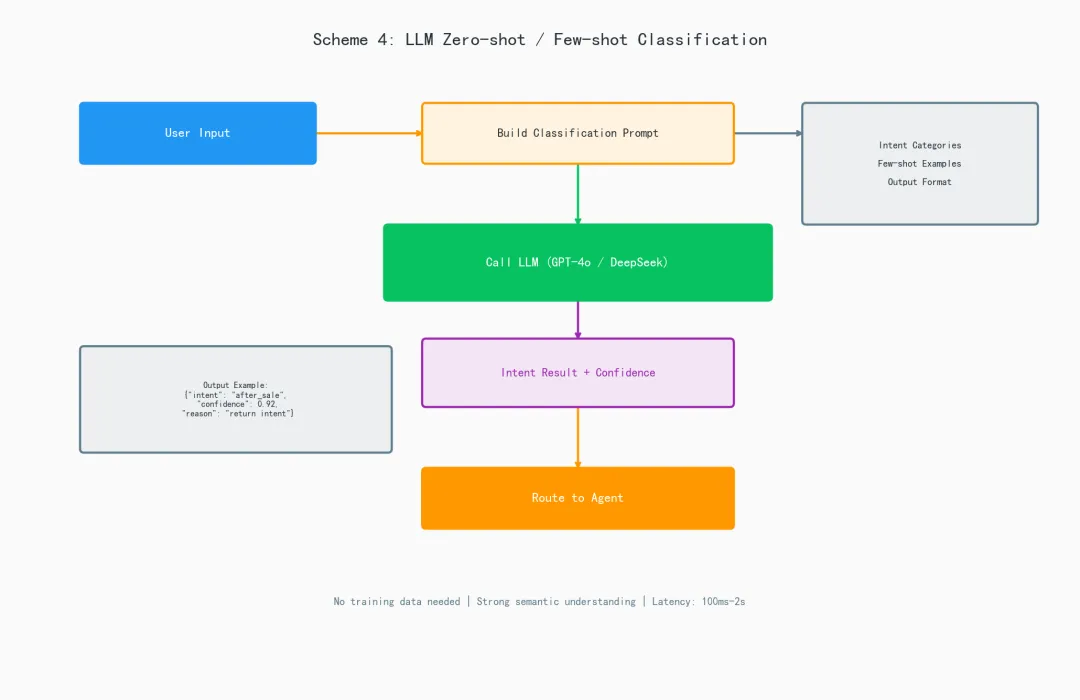
实战代码1:基础零样本分类
import openaiimport jsonclient = openai.OpenAI(api_key="your-api-key")# 定义意图类别INTENTS = { "pre_sale": "售前咨询:产品功能、价格、库存、购买方式", "after_sale": "售后问题:退换货、维修、投诉、退款", "tech_support": "技术支持:使用问题、故障排查、安装指导", "order_query": "订单查询:物流、订单状态、发货时间", "chitchat": "闲聊:打招呼、开玩笑、非业务话题", "other": "其他:无法归类的输入"}def classify_intent(user_input: str) -> dict: """零样本意图分类""" intent_desc = "\n".join( [f"- {k}: {v}" for k, v in INTENTS.items()] ) system_prompt = f"""你是一个精准的意图分类器。请将用户输入分类为以下意图之一:{intent_desc}输出要求(JSON格式):{{ "intent": "意图类别key", "confidence": 0.0-1.0之间的置信度, "reason": "分类理由(一句话)"}}注意:1. 只输出JSON,不要其他内容2. 如果不确定,confidence设为0.5以下3. 优先选择最匹配的类别,实在无法归类才选other""" response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_input} ], temperature=0.1, response_format={"type": "json_object"} ) return json.loads(response.choices[0].message.content)# 测试test_cases = [ "这件衣服能退吗?已经穿过一次了", "你们最新的手机多少钱", "我电脑开不了机怎么办", "我的快递到哪了,三天了还没到", "你好呀,今天天气不错",]for text in test_cases: result = classify_intent(text) print(f"输入: {text}") print(f"意图: {result['intent']} | 置信度: {result['confidence']}") print(f"理由: {result['reason']}") print("---")实战代码2:少样本分类(Few-shot,更高精度)
def classify_intent_fewshot(user_input: str) -> dict: """少样本意图分类 - 通过示例提升精度""" system_prompt = """你是一个精准的意图分类器。根据以下示例学习分类规则:## 示例用户输入:"我想买一件红色的连衣裙"分类:pre_sale(售前咨询)理由:用户表达购买意向,询问商品信息用户输入:"质量有问题想退货"分类:after_sale(售后问题)理由:用户反映质量问题,明确表示要退货用户输入:"app一直闪退打不开"分类:tech_support(技术支持)理由:用户描述应用故障,需要技术帮助用户输入:"我的包裹到北京了吗"分类:order_query(订单查询)理由:用户询问物流状态用户输入:"哈哈你真逗"分类:chitchat(闲聊)理由:用户在闲聊,无业务意图---## 输出要求(JSON格式){ "intent": "意图类别key", "confidence": 0.0-1.0, "reason": "分类理由"}""" response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_input} ], temperature=0.1, response_format={"type": "json_object"} ) return json.loads(response.choices[0].message.content)# 测试模糊意图print(classify_intent_fewshot("买多了想退一个"))# 预期: after_sale(虽然有"买"字,但核心是退)方案四的优缺点
优势
零训练成本,有API Key就能用;语义理解能力强,处理歧义和长尾表达好;支持复杂意图(多意图混合、隐含意图)
劣势
推理延迟100ms-2s;每次调用都有成本;输出不完全可控;依赖外部API稳定性
· · ·
四、方案五:RAG增强的意图识别(当前最佳实践)
核心思想
纯LLM分类有个问题:它没见过你的业务场景。你说"退退退"是退货意图,但LLM可能理解为"重复强调"。
RAG增强的思路是:先从示例库中检索最相似的历史case,把它们作为Few-shot示例喂给LLM。
一句话理解:不是让LLM"凭空分类",而是让它"参考相似案例再分类"——就像新员工遇到不确定的问题,先翻翻老case再回答。
方案架构
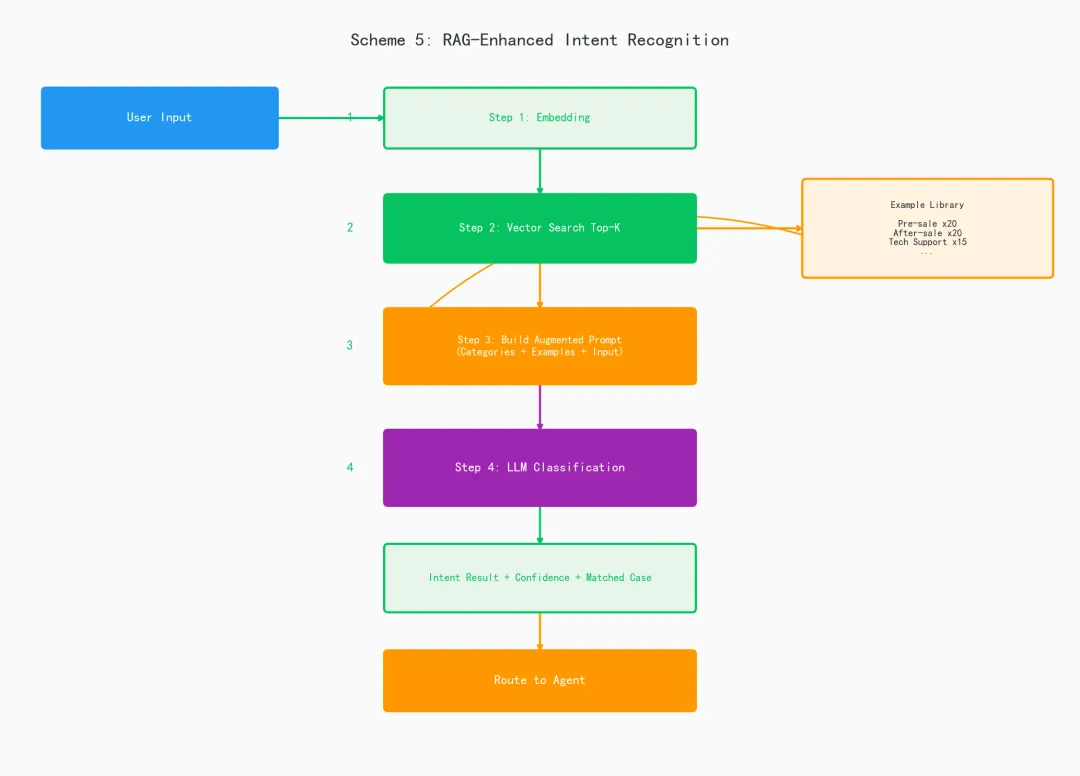
实战代码3:完整RAG增强意图识别系统
import openaiimport jsonimport numpy as npfrom typing import List, Dictclient = openai.OpenAI(api_key="your-api-key")# ==================== 第一部分:示例库管理 ====================# 意图分类示例库(实际项目中可存入数据库)INTENT_EXAMPLES = [ # 售前咨询示例 {"text": "这款手机有什么颜色", "intent": "pre_sale", "label": "售前咨询"}, {"text": "能便宜点吗", "intent": "pre_sale", "label": "售前咨询"}, {"text": "有没有货", "intent": "pre_sale", "label": "售前咨询"}, {"text": "支持分期吗", "intent": "pre_sale", "label": "售前咨询"}, {"text": "这个和那个比哪个好", "intent": "pre_sale", "label": "售前咨询"}, # 售后问题示例 {"text": "买多了想退一个", "intent": "after_sale", "label": "售后问题"}, {"text": "收到的商品有划痕", "intent": "after_sale", "label": "售后问题"}, {"text": "颜色和图片不一样能退吗", "intent": "after_sale", "label": "售后问题"}, {"text": "退款什么时候到账", "intent": "after_sale", "label": "售后问题"}, {"text": "穿了一次就破了", "intent": "after_sale", "label": "售后问题"}, {"text": "质量太差了要投诉", "intent": "after_sale", "label": "售后问题"}, # 技术支持示例 {"text": "app闪退怎么办", "intent": "tech_support", "label": "技术支持"}, {"text": "连不上WiFi", "intent": "tech_support", "label": "技术支持"}, {"text": "安装不了", "intent": "tech_support", "label": "技术支持"}, {"text": "账号登不上去了", "intent": "tech_support", "label": "技术支持"}, # 订单查询示例 {"text": "我的快递到哪了", "intent": "order_query", "label": "订单查询"}, {"text": "什么时候发货", "intent": "order_query", "label": "订单查询"}, {"text": "能改一下收货地址吗", "intent": "order_query", "label": "订单查询"}, # 闲聊示例 {"text": "你是机器人吗", "intent": "chitchat", "label": "闲聊"}, {"text": "今天心情不好", "intent": "chitchat", "label": "闲聊"}, {"text": "给我讲个笑话", "intent": "chitchat", "label": "闲聊"},]class IntentRAGClassifier: """RAG增强的意图分类器""" def __init__(self, examples: List[Dict], top_k: int = 3): self.examples = examples self.top_k = top_k self.embeddings = None self._build_index() def _get_embedding(self, text: str) -> List[float]: """获取文本的embedding向量""" response = client.embeddings.create( model="text-embedding-3-small", input=text ) return response.data[0].embedding def _build_index(self): """构建向量索引""" print("正在构建示例库向量索引...") self.embeddings = [] for example in self.examples: emb = self._get_embedding(example["text"]) self.embeddings.append(emb) self.embeddings = np.array(self.embeddings) print(f"索引构建完成,共 {len(self.examples)} 条示例") def _retrieve(self, query: str) -> List[Dict]: """检索最相似的Top-K示例""" query_emb = np.array(self._get_embedding(query)) # 计算余弦相似度 similarities = np.dot(self.embeddings, query_emb) / ( np.linalg.norm(self.embeddings, axis=1) * np.linalg.norm(query_emb) ) # 取Top-K top_indices = np.argsort(similarities)[-self.top_k:][::-1] results = [] for idx in top_indices: results.append({ **self.examples[idx], "similarity": float(similarities[idx]) }) return results def classify(self, user_input: str) -> dict: """RAG增强的意图分类""" # Step 1: 检索相似示例 retrieved = self._retrieve(user_input) # Step 2: 构造增强Prompt examples_text = "\n".join([ f'用户说:"{ex["text"]}" → 意图:{ex["label"]}({ex["intent"]})' for ex in retrieved ]) system_prompt = f"""你是一个精准的意图分类器。根据以下历史案例学习分类规则:## 参考案例(与当前输入最相似){examples_text}## 意图类别- pre_sale: 售前咨询- after_sale: 售后问题(退换货、质量投诉、退款)- tech_support: 技术支持(使用问题、故障排查)- order_query: 订单查询(物流、发货、地址修改)- chitchat: 闲聊- other: 其他## 输出要求(JSON格式){{ "intent": "意图类别key", "confidence": 0.0-1.0, "reason": "分类理由", "matched_example": "匹配到的参考案例原文"}}""" # Step 3: LLM分类 response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": f"用户输入:{user_input}"} ], temperature=0.1, response_format={"type": "json_object"} ) result = json.loads(response.choices[0].message.content) result["retrieved_examples"] = retrieved return result# ==================== 使用示例 ====================# 初始化分类器classifier = IntentRAGClassifier(INTENT_EXAMPLES, top_k=3)# 测试test_inputs = [ "颜色和图片差太多了想退", # 模糊表达 → 售后 "有没有红色的", # 简短表达 → 售前 "app一直转圈加载不出来", # 技术问题 → 技术支持 "那个东西发货了吗", # 口语化 → 订单查询 "你能不能陪我聊聊天", # 闲聊 → 闲聊]for text in test_inputs: result = classifier.classify(text) print(f"\n输入: {text}") print(f"意图: {result['intent']} | 置信度: {result['confidence']}") print(f"理由: {result['reason']}") print(f"匹配案例: {result['matched_example']}") print(f"检索相似度: {[round(ex['similarity'], 3) for ex in result['retrieved_examples']]}")实战代码4:带置信度阈值的生产级路由
class IntentRouter: """生产级意图路由器 - 带置信度阈值和兜底策略""" # 意图 → Agent的映射 INTENT_AGENT_MAP = { "pre_sale": "pre_sale_agent", "after_sale": "after_sale_agent", "tech_support": "tech_agent", "order_query": "order_agent", "chitchat": "chitchat_agent", } def __init__(self, classifier: IntentRAGClassifier, threshold: float = 0.6): self.classifier = classifier self.threshold = threshold # 置信度阈值 def route(self, user_input: str) -> dict: """路由用户请求到对应Agent""" result = self.classifier.classify(user_input) intent = result["intent"] confidence = result["confidence"] # 置信度低于阈值,走兜底策略 if confidence < self.threshold: return { "agent": "human_agent", # 转人工 "intent": intent, "confidence": confidence, "reason": f"置信度 {confidence} 低于阈值 {self.threshold},转人工处理", "original_result": result } # 正常路由 agent = self.INTENT_AGENT_MAP.get(intent, "default_agent") return { "agent": agent, "intent": intent, "confidence": confidence, "reason": result["reason"], "original_result": result }# 使用示例router = IntentRouter(classifier, threshold=0.6)test_input = "这个东西好像有点问题但我也说不清楚"route_result = router.route(test_input)print(f"路由结果: {route_result['agent']}")print(f"意图: {route_result['intent']} | 置信度: {route_result['confidence']}")print(f"原因: {route_result['reason']}")实战代码5:多层级调度系统
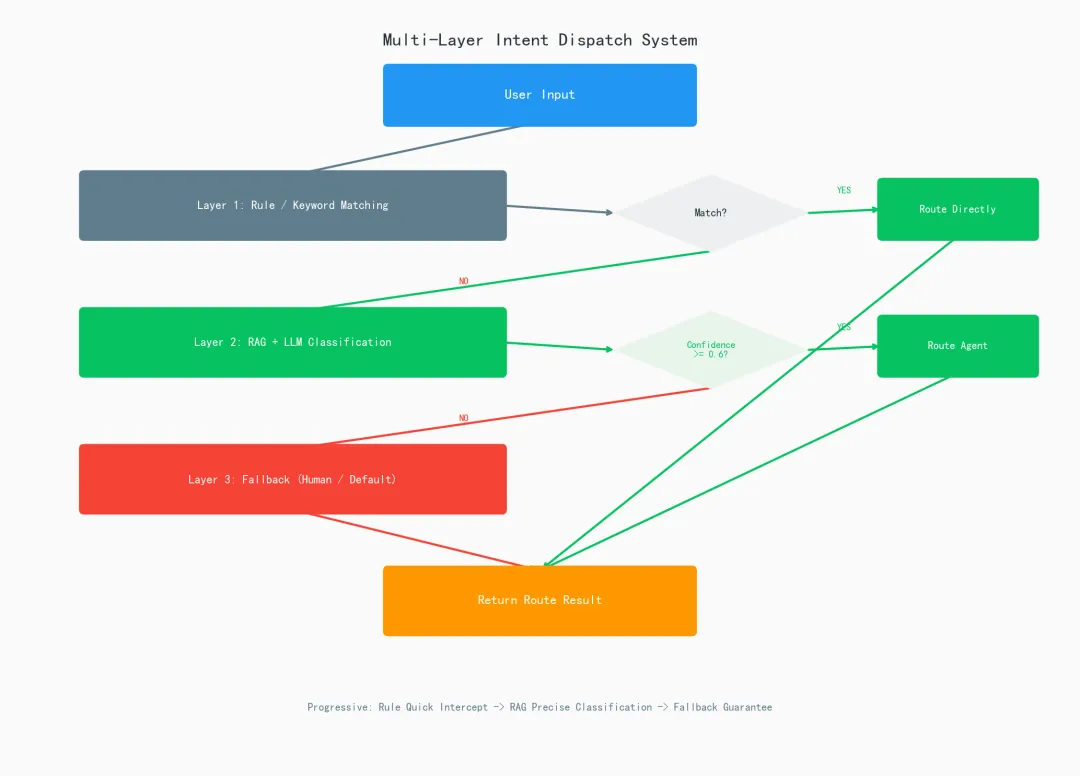
class MultiLayerIntentDispatcher: """多层级意图调度系统 Layer 1: 规则匹配(快速拦截明确意图) Layer 2: RAG增强LLM(处理复杂/模糊意图) Layer 3: 兜底路由(转人工或默认回复) """ def __init__(self, rag_classifier: IntentRAGClassifier): self.rag = rag_classifier self.router = IntentRouter(rag_classifier, threshold=0.6) # Layer 1: 规则库 self.rules = [ {"pattern": r"退[款货]|不想要|退货", "intent": "after_sale", "agent": "after_sale_agent"}, {"pattern": r"多少[钱元]|价格|便宜|打折", "intent": "pre_sale", "agent": "pre_sale_agent"}, {"pattern": r"快递|物流|到哪|发货", "intent": "order_query", "agent": "order_agent"}, ] def dispatch(self, user_input: str) -> dict: """三层调度""" import re # Layer 1: 规则快速匹配 for rule in self.rules: if re.search(rule["pattern"], user_input): return { "layer": "rule", "agent": rule["agent"], "intent": rule["intent"], "confidence": 1.0, "reason": f"规则命中: {rule['pattern']}" } # Layer 2: RAG增强LLM分类 route = self.router.route(user_input) if route["agent"] != "human_agent": return { "layer": "rag_llm", "agent": route["agent"], "intent": route["intent"], "confidence": route["confidence"], "reason": route["reason"] } # Layer 3: 兜底 - 转人工 return { "layer": "fallback", "agent": "human_agent", "intent": route["intent"], "confidence": route["confidence"], "reason": "所有自动分类失败,转人工处理" }# 初始化多层调度器dispatcher = MultiLayerIntentDispatcher(classifier)# 测试test_cases = [ "我要退款", # Layer 1: 规则命中 "你们家的东西颜色和图片差太多了想退一个", # Layer 2: RAG+LLM "今天心情好想买点东西但不知道买啥", # Layer 2: 复杂意图 "asdfghjkl", # Layer 3: 兜底]for text in test_cases: result = dispatcher.dispatch(text) print(f"\n输入: {text}") print(f"层级: {result['layer']} | Agent: {result['agent']}") print(f"意图: {result['intent']} | 置信度: {result['confidence']}") print(f"原因: {result['reason']}")· · ·
五、方案五的优化技巧
技巧1:示例库的质量决定分类精度
黄金法则:每类意图至少准备10-20个示例,覆盖不同的表达方式(口语化、书面化、简短、详细、模糊、明确)。
# 示例库扩充策略示例类型 = { "标准表达": "我要退货", "口语化": "买多了想退一个", "模糊表达": "这个东西好像有问题", "情绪化": "质量太差了!要投诉!", "简短": "退退退", "详细描述": "我上周买的衣服,收到后发现颜色和图片差很多,而且有一处线头,我想退货退款"}技巧2:动态调整Top-K
# 根据用户输入复杂度动态调整检索数量def dynamic_top_k(user_input: str) -> int: """输入越长/越复杂,检索更多示例""" length = len(user_input) if length < 10: return 2 # 简短输入,少检索 elif length < 30: return 3 # 中等长度 else: return 5 # 复杂输入,多检索技巧3:添加相似度阈值过滤
# 检索结果相似度太低时,不使用检索示例def classify_with_threshold(classifier, user_input, sim_threshold=0.5): retrieved = classifier._retrieve(user_input) # 过滤低相似度结果 high_sim = [ex for ex in retrieved if ex["similarity"] >= sim_threshold] if len(high_sim) == 0: # 无高质量匹配,退化为纯LLM分类 return classify_intent(user_input) else: # 使用高质量匹配做Few-shot return classifier.classify(user_input)技巧4:异步批量处理提高吞吐
import asyncioimport aiohttpasync def batch_classify(user_inputs: List[str]) -> List[dict]: """批量异步分类,提高吞吐量""" tasks = [classifier.classify_async(text) for text in user_inputs] results = await asyncio.gather(*tasks) return results# 并发处理100条请求results = asyncio.run(batch_classify(hundred_inputs))· · ·
六、各方案对比与选型建议
选型建议:
• 从方案4开始:零成本快速验证意图分类效果
• 收集100+真实case后:升级到方案5,用RAG增强精度
• 高并发场景:规则层(方案1)+ RAG层(方案5)组合使用
· · ·
七、生产环境部署建议
# 项目结构建议intent_dispatch/├── config/│ ├── intents.json # 意图类别定义│ └── config.yaml # 阈值、模型配置├── examples/│ └── intent_examples.json # RAG示例库├── core/│ ├── classifier.py # 意图分类器│ ├── router.py # 路由逻辑│ └── dispatcher.py # 多层调度器├── api/│ └── main.py # FastAPI接口└── tests/ └── test_accuracy.py # 分类精度测试# FastAPI部署示例from fastapi import FastAPIfrom pydantic import BaseModelapp = FastAPI()dispatcher = MultiLayerIntentDispatcher(classifier)class UserRequest(BaseModel): text: str session_id: str = None@app.post("/classify")async def classify(req: UserRequest): result = dispatcher.dispatch(req.text) return { "intent": result["intent"], "agent": result["agent"], "confidence": result["confidence"] }机器学习算法AI大数据技术
搜索公众号添加:datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
【模型高效部署】tensorrtx 深度解读,yolov11高性能推理实战案例
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:datayx

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux系统目录结构解析
- 【招聘】Senior Linux developer 无日语要求 日本名古屋【赴日驻日IT工作岗位】
- 6.18 在 macOS/Linux系统运行 Windows 程序的另一个选择 :CrossOver
- 《Python 从入门到精通》087|sys 模块:理解 Python 运行环境的重要入口
- Linux 运维必学(五)|磁盘与文件系统管理全解(附实操命令)
- 忘记Linux密码?别慌!3分钟教你通过GRUB重置root密码
- Python开发从零开始-37.3-日期与时间
- 如何理解Linux中的软链接和硬链接
- 【Linux社区短距简报】linux-bluetooth周动态(20260611~0617)
- 它真的把Python爬虫讲得好清晰啊!
