由于真实金融面板数据涉及复杂的清洗过程,为了聚焦方法本身,我们首先构建一个模拟金融面板数据集,包含500家上市公司10年(2016-2025)的年度数据,该数据具备:2)处置变量treat(是否执行某项内部治理改革,后文在IV/DID/RD中分别按不同规则生成)4)协变量size(市值对数)、lev(杠杆率)、industry(行业分类)import numpy as npimport pandas as pdimport statsmodels.api as smimport statsmodels.formula.api as smffrom linearmodels.iv import IV2SLSfrom scipy.stats import normimport matplotlib.pyplot as pltimport seaborn as snssns.set_style('whitegrid')# 固定种子,结果可复现np.random.seed(123)# =========== 生成面板数据参数 =============N = 500 # 公司数T = 10 # 年数years = list(range(2016, 2026)) # 2016-2025# 公司特征(稳定)industries = ['Health', 'Finance', 'Tech', 'Energy', 'Retail']industry = np.random.choice(industries, N)size = np.random.lognormal(mean=22.5, sigma=1.5, size=N) # 市值对数lev = np.clip(np.random.beta(2, 5, size=N), 0.05, 0.95) # 杠杆率# =========== 构建面板数据 =============data_list = []for i in range(N): for t_idx, year in enumerate(years): # 基础ROA由公司固定成分+时间趋势+随机误差组成 base_roa = 0.05 + 0.02 * size[i]/size.mean() \ - 0.10 * lev[i]\ + 0.01 * np.random.randn() # 加入时间趋势 time_effect = 0.002 * (year - years[0]) # 模拟处理变量(根据后续方法将有不同定义,此处先生成占位符) treat_placeholder = 0 # 后续覆盖 # 工具变量 iv_val = 0 # 后续覆盖 data_list.append({ 'firm_id': i, 'year': year, 'industry': industry[i], 'size': size[i], 'lev': lev[i], 'base_roa': base_roa + time_effect, 'treat': treat_placeholder, 'iv': iv_val, })df_draw = pd.DataFrame(data_list)# 处理效应应预先定义,后面根据需要覆盖df_draw['ROA'] = df_draw['base_roa'] + 0.05 * df_draw['treat']
我们研究公司治理改革(treat)对ROA的因果效应。该改革要求对2016年前注册的公司要求必须执行。因此,可以使用“公司是否在2016年前注册”作为工具变量。内生性来源:是否自愿执行改革与公司绩效可能受遗漏的“管理层能力”的影响,导致OLS有偏。工具变量应满足:2)外生性:注册时间不会通过其他路径影响之后的ROA(与控制变量一起)# 为每个公司生成注册年份(2016年之前或之后)np.random.seed(123)df = df_draw.copy()# 工具变量:公司注册年<2016(1=老公司,可能被强制要求改革)registered_before_2016 = np.random.binomial(1, 0.7, size=N) # 70%上市公司在2016年之前注册iv = registered_before_2016# 处理变量:老公司执行改革概率高(0.8),新公司低(0.2)p_treat = np.where(registered_before_2016 == 1, 0.8, 0.2)treat = np.random.binomial(1, p_treat)# 将iv和treat扩展到面板(每个公司-年相同)df['iv'] = np.tile(iv, T)df['treat'] = np.tile(treat, T)# 生成ROA:处理效应为真 +0.05df['ROA'] = df['base_roa'] + 0.05 * df['treat']\ + 0.02 * np.random.randn(N*T)
此处工具变量在“公司”层面恒定,面板中年份变化不会影响。实际应用时工具应在个体-时点变动。我们需要先手动检查第一阶段的F统计量(Stock-Yogo弱工具检验)# 第一阶段: treat ~ iv + 控制变量first_stage = smf.ols( 'treat ~ iv + size + lev + C(industry) + C(year)', data=df).fit()print("=== 第一阶段回归结果 ===")print(first_stage.summary().tables[1]) # 系数表# F统计量(排除iv的检查)f_test = first_stage.f_test('iv = 0')print(f"第一阶段F统计量: {f_test.fvalue:.3f}, p值: {f_test.pvalue:.5f}")
=== 第一阶段回归结果 ============================================================================================= coef std err t P>|t| [0.025 0.975]------------------------------------------------------------------------------------------Intercept 0.2985 0.026 11.691 0.000 0.248 0.348C(industry)[T.Finance] 0.0045 0.017 0.263 0.793 -0.029 0.038C(industry)[T.Health] -0.0064 0.017 -0.366 0.715 -0.041 0.028C(industry)[T.Retail] -0.0256 0.018 -1.454 0.146 -0.060 0.009C(industry)[T.Tech] 0.0169 0.018 0.953 0.341 -0.018 0.052C(year)[T.2017] 0.0050 0.025 0.202 0.840 -0.044 0.054C(year)[T.2018] -0.0016 0.025 -0.066 0.947 -0.050 0.047C(year)[T.2019] -0.1266 0.025 -5.071 0.000 -0.176 -0.078C(year)[T.2020] -0.0100 0.025 -0.400 0.689 -0.059 0.039C(year)[T.2021] 0.0100 0.025 0.402 0.688 -0.039 0.059C(year)[T.2022] -0.0016 0.025 -0.066 0.947 -0.050 0.047C(year)[T.2023] -0.2016 0.025 -8.091 0.000 -0.250 -0.153C(year)[T.2024] -0.1100 0.025 -4.411 0.000 -0.159 -0.061C(year)[T.2025] -0.1083 0.025 -4.352 0.000 -0.157 -0.060iv 0.5836 0.012 46.828 0.000 0.559 0.608size -4.802e-14 1.71e-13 -0.281 0.779 -3.83e-13 2.87e-13lev -0.0472 0.035 -1.360 0.174 -0.115 0.021==========================================================================================第一阶段F统计量: 2192.905, p值: 0.00000
一般要求F>10,p<0.05以拒绝弱工具变量,上述结果明显满足。# 面板数据设定(需要entity-time索引)df = df.set_index(['firm_id', 'year'])# 定义内生变量、工具变量和外生变量formula = 'ROA ~ 1 + size + lev + C(industry) + C(year) + [treat ~ iv]'iv_model = IV2SLS.from_formula(formula, data=df)iv_result = iv_model.fit(cov_type='robust', debiased=True) # 稳健标准误print("=== IV 第二阶段回归结果 ===")print(iv_result.summary)
=== IV 第二阶段回归结果 === IV-2SLS Estimation Summary ==============================================================================Dep. Variable: ROA R-squared: 0.8098Estimator: IV-2SLS Adj. R-squared: 0.8096No. Observations: 5000 F-statistic: 2602.1Date: Tue, Jun 16 2026 P-value (F-stat) 0.0000Time: 15:10:05 Distribution: F(7,4992)Cov. Estimator: robust Parameter Estimates ========================================================================================== Parameter Std. Err. T-stat P-value Lower CI Upper CI------------------------------------------------------------------------------------------Intercept 0.0558 0.0012 44.863 0.0000 0.0534 0.0583size 1.144e-12 9.945e-15 115.02 0.0000 1.124e-12 1.163e-12lev -0.0996 0.0020 -49.816 0.0000 -0.1035 -0.0957C(industry)[T.Finance] 0.0007 0.0010 0.7242 0.4690 -0.0012 0.0027C(industry)[T.Health] 0.0016 0.0010 1.6118 0.1071 -0.0004 0.0036C(industry)[T.Retail] 0.0011 0.0010 1.0329 0.3017 -0.0009 0.0031C(industry)[T.Tech] 0.0021 0.0010 2.1079 0.0351 0.0001 0.0041treat 0.0533 0.0012 43.328 0.0000 0.0509 0.0557==========================================================================================Endogenous: treatInstruments: ivRobust Covariance (Heteroskedastic)Debiased: True
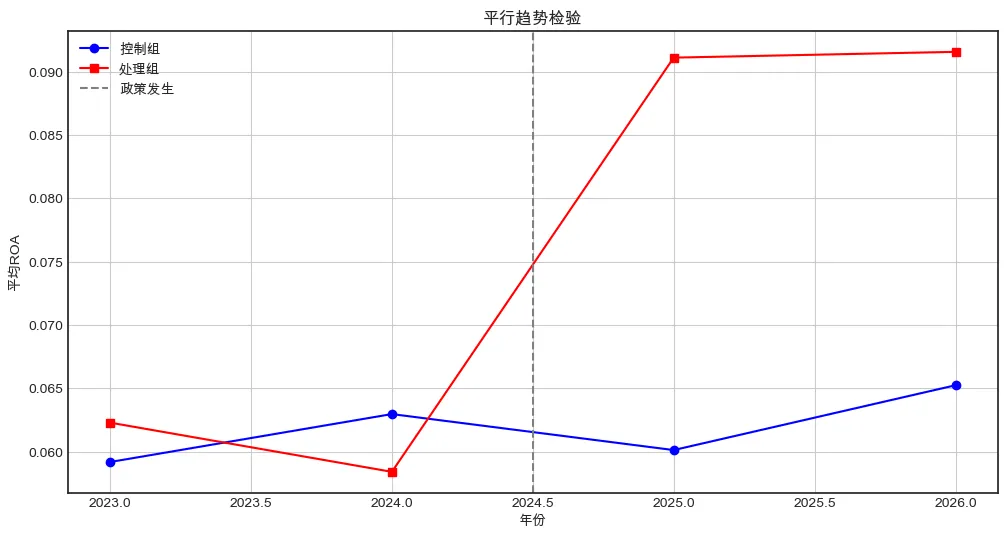
treat的系数即为局部平均处理效应,估计值接近真实值0.05。假设在2025年开始,某项金融监管政策实施,该政策仅对金融行业产生影响,其他行业作为控制组。使用2023-2026年年度数据,观察政策前后ROA的变化。共同趋势假设:如果没有政策,金融行业与其他行业的ROA变化趋势相同。np.random.seed(123)# 重新构建简洁的 DID 面板N_did = 200 # 公司数量(金融100,其他100)T_did = 4 # 年份数量(2023-2026)years_did = [2023, 2024, 2025, 2026]# 行业分组:前100家为金融,后100家为其他treat_group = np.array([1]*100 + [0]*100)firm_id = np.arange(N_did)# 生成面板did_data = []for i in firm_id: for t in years_did: # 基础ROA(公司固定效应+随机噪声) firm_effect = np.random.normal(0, 0.02) # 时间效应(共同) time_effect = 0.001 * (t - years_did[0]) # 处理效应(只有处理组在2025及以后) effect = 0.03 if (treat_group[i]==1 and t>=2025) else 0 roa = 0.06 + firm_effect + time_effect + effect + 0.01*np.random.randn() did_data.append({ 'firm_id': i, 'year': t, 'treat': treat_group[i], 'post': 1 if t>=2025 else 0, 'roa': roa })df_did = pd.DataFrame(did_data)
DID的关键前提是政策前干预组与控制组的趋势平行,绘制平均ROA的时间序列。# 计算各年各组的平均ROAmean_roa = df_did.groupby(['year', 'treat'])['roa'].mean().unstack()mean_roa.columns = ['控制组', '处理组']# 设置绘图样式plt.style.use('seaborn-v0_8-white')# 设置中文字体和负号显示plt.rcParams["font.sans-serif"] = ["PingFang SC", "Arial Unicode MS", "Heiti TC"]plt.rcParams["axes.unicode_minus"] = False# 绘图plt.figure(figsize=(12, 6))plt.plot(mean_roa.index, mean_roa['控制组'], 'b-o', label='控制组')plt.plot(mean_roa.index, mean_roa['处理组'], 'r-s', label='处理组')plt.axvline(x=2024.5, color='gray', linestyle='--', label='政策发生')plt.xlabel('年份')plt.ylabel('平均ROA')plt.title('平行趋势检验')plt.legend()plt.grid(True)plt.show()
若政策发生前两组趋势平行,则图形中两条线斜率相近。# 交互项 = treat * postdid_ols = smf.ols('roa ~ treat * post', data=df_did).fit( cov_type='cluster', cov_kwds={'groups': df_did['firm_id']} )print(did_ols.summary().tables[1])
============================================================================== coef std err z P>|z| [0.025 0.975]------------------------------------------------------------------------------Intercept 0.0611 0.002 39.813 0.000 0.058 0.064treat -0.0007 0.002 -0.317 0.751 -0.005 0.004post 0.0016 0.002 0.728 0.466 -0.003 0.006treat:post 0.0294 0.003 9.296 0.000 0.023 0.036==============================================================================
# 使用固定效应模型:roa ~ treat | firm_id + year# 注意:由于treat不随时间变化,公司固定效应会吸收它;post会被固定效应吸收。因此,只保留交互效应did_fe = smf.ols('roa ~ treat:post + C(firm_id) + C(year)', data=df_did).fit()
from linearmodels.panel import PanelOLSdf_did = df_did.set_index(['firm_id', 'year'])mod = PanelOLS.from_formula( 'roa ~ treat:post + EntityEffects + TimeEffects', data=df_did)fe_result = mod.fit(cov_type='robust')print(fe_result)
PanelOLS Estimation Summary ================================================================================Dep. Variable: roa R-squared: 0.1305Estimator: PanelOLS R-squared (Between): 0.2045No. Observations: 800 R-squared (Within): 0.2489Date: Wed, Jun 17 2026 R-squared (Overall): 0.2085Time: 14:14:18 Log-likelihood 2037.2Cov. Estimator: Robust F-statistic: 89.421Entities: 200 P-value 0.0000Avg Obs: 4.0000 Distribution: F(1,596)Min Obs: 4.0000 Max Obs: 4.0000 F-statistic (robust): 89.421 P-value 0.0000Time periods: 4 Distribution: F(1,596)Avg Obs: 200.00 Min Obs: 200.00 Max Obs: 200.00 Parameter Estimates ============================================================================== Parameter Std. Err. T-stat P-value Lower CI Upper CI------------------------------------------------------------------------------treat:post 0.0294 0.0031 9.4563 0.0000 0.0233 0.0355==============================================================================F-test for Poolability: 1.0683P-value: 0.2759Distribution: F(202,596)Included effects: Entity, Time
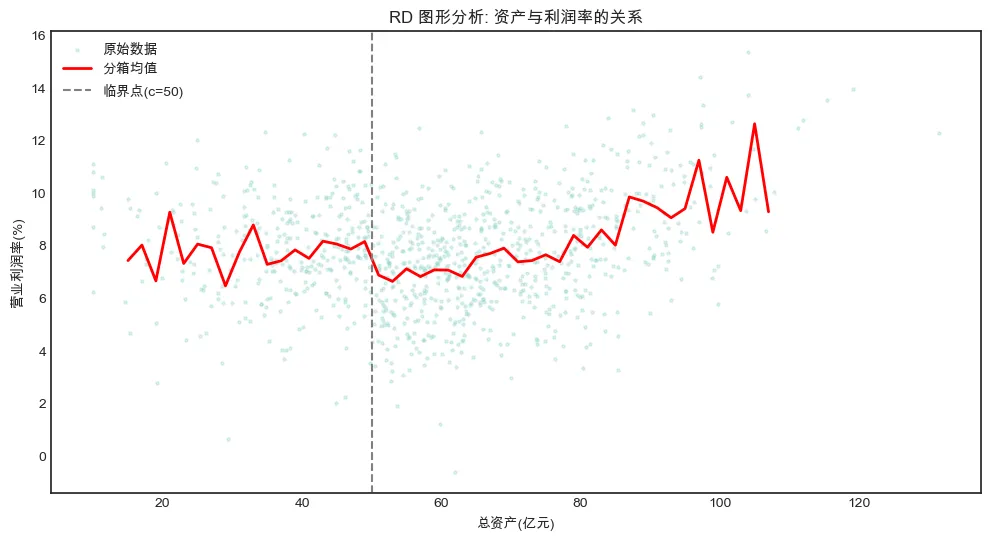
1. treat:post的系数即为DID估计量,应接近0.03。2. 交互项系数的显著性检验即为对政策效果的检验。假设某项“中小企业扶持政策”,针对总资产50亿元的公司可享受优惠。我们想知道该政策是否提升了公司的营业利润率。这里赋予一个模糊点设计:政策使低于50亿的公司利润率更高,但并非所有低于阈值的都享受(可能受申请等影响),在阈值处有一个“跳跃”。结果变量:profit_margin(营业利润率,%)为了演示我们使用精确断点(Sharp RD),即 treat = I(asset < 50)。np.random.seed(123)n_rd = 1000# 参考变量:总资产(近似正态,均值为60,标准差20,但产生一些样本50附近)asset = np.random.normal(60, 20, n_rd)asset = np.clip(asset, 10, 150) # 截断c = 50treat = (asset < c).astype(float)# 潜在结果函数(包含连续性假设)# 基线:利润与资产有线性关系(对数形式),加上误差def baseline_profit(asset): return 5 + 0.03 * asset + 0.001 * (asset - c)**2# 处理效应:阈值处跳跃+1.5个百分点的利润率margin_0 = baseline_profit(asset) + np.random.randn(n_rd) * 2margin_1 = margin_0 + 1.5 # 1.5个百分点的处理效应# 观测结果margin = np.where(treat == 1, margin_1, margin_0)df_rd = pd.DataFrame({'asset': asset, 'treat': treat, 'margin': margin})
# 绘制原始数据(少量样本点)及分箱均值plt.figure(figsize=(12, 6))plt.scatter(df_rd['asset'], df_rd['margin'], alpha=0.3, s=5, label='原始数据')# 分箱均值bins = np.arange(10, 150, 2)bin_means = df_rd.groupby(pd.cut(df_rd['asset'], bins), observed=False)['margin'].mean() # type: ignorebin_centers = (bins[:-1] + bins[1:]) / 2plt.plot(bin_centers, bin_means, 'r-', linewidth=2, label='分箱均值')plt.axvline(x=c, color='gray', linestyle='--', label='临界点(c=50)')plt.xlabel('总资产(亿元)')plt.ylabel('营业利润率(%)')plt.title('RD 图形分析: 资产与利润率的关系')plt.legend()plt.show()
在断点附近使用局部多项式。以临界点为中心,选择带宽h(这里演示手动选择h=15)。h = 15df_rd_local = df_rd[(df_rd['asset'] >= c - h) & (df_rd['asset'] <= c + h)].copy()df_rd_local['x'] = df_rd_local['asset'] - c # 中心化# 二次多项式交互回归df_rd_local['treat'] = (df_rd_local['asset'] >= c).astype(float) # 重新构造数据(避免混乱,直接使用新定义)treat_rd = (df_rd['asset'] >= c).astype(float)margin_rd = marginrd_data = pd.DataFrame({'asset': asset, 'x': asset - c, 'treat': treat_rd, 'margin': margin_rd})# 在带宽h=20内局部回归h = 20rd_sub = rd_data[(rd_data['x'] >= -h) & (rd_data['x'] <= h)].copy()rd_sub['x2'] = rd_sub['x']**2# 模型: margin ~ treat + x + treat:x (交互允许斜率不同)model_rd = smf.ols('margin ~ treat * (x + x2)', data=rd_sub).fit()print(model_rd.summary().tables[1])
============================================================================== coef std err t P>|t| [0.025 0.975]------------------------------------------------------------------------------Intercept 8.2978 0.327 25.347 0.000 7.655 8.941treat -1.3849 0.441 -3.140 0.002 -2.251 -0.519x 0.1181 0.085 1.388 0.166 -0.049 0.285x2 0.0057 0.004 1.285 0.199 -0.003 0.014treat:x -0.1630 0.110 -1.488 0.137 -0.378 0.052treat:x2 -0.0006 0.006 -0.115 0.908 -0.012 0.010==============================================================================
treat系数即为精确断点RD估计量在-1.5左右。from sklearn.linear_model import LinearRegressionh_manual = 10 # 选带宽left = rd_data[(rd_data['x'] > -h_manual) & (rd_data['x'] < 0)]right = rd_data[(rd_data['x'] >= 0) & (rd_data['x'] < h_manual)]# 左侧加权回归(矩形核 = 简单 OLS)left_reg = LinearRegression().fit(left[['x']], left['margin'])# 右侧加权回归right_reg = LinearRegression().fit(right[['x']], right['margin'])# 预测在 x=0 处的值left_pred = left_reg.intercept_ + left_reg.coef_[0]*0right_pred = right_reg.intercept_ + right_reg.coef_[0]*0rd_estimate = right_pred - left_predprint(f"LLR 估计 (h={h_manual}) : {rd_estimate:.4f} (理论: -1.5)")
LLR 估计 (h=10) : -1.4183 (理论: -1.5)
1. 参数和非参数估计量都应捕捉到断点处的跳跃(约-1.5,因为我们设定treat=1对应asset≥c且无正向效应,跳跃方向为负;若重新设计treat=1对应asset<c且正向效应,则符号为正)。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
