【Python语音识别系列】语音识别评价:词错率(WER)与字错率(CER)的计算(案例+源码)
- 2026-06-30 09:54:36
这是我的第470篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序开发|数据采集|数据分析|数据可视化|特征工程|机器学习|时序数据|深度学习|人工智能等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)

一、引言
词错率(Word Error Rate, WER)是一项用于评价ASR性能的重要指标,用来评价预测文本与标准文本之间错误率,因此词错率最大的特点是越小越好。像英语、阿拉伯语语音转文本或语音识别任务中研究者常用WER衡量ASR效果好坏。
因为英文语句中句子的最小单位是单词,而中文语句中的最小单位是汉字,因此在中文语音转文本任务或中文语音识别任务中使用字错率(Character Error Rate, CER)来衡量中文ASR效果好坏。
两者计算方式相同,为行文统一,下文统一使用WER表示该性能。
它们的计算公式是:
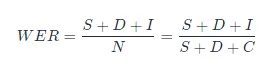
假设有一个参考例句Ref和一段ASR系统转写语音后生成的预测文本Hyp。带入上面公式,S表示将Hyp转化为Ref时发生的替换数量,D表示将Hyp转化为Ref时发生的删除数量,I代表将Hypo转化为Ref时发生的插入数量,N代表Ref句子中总的字数或者英文单词数。C代表Hyp句子中识别正确的字数。即原参考句子总字数N = S+ D + C。
再说一句,根据维基百科里面的说法,N就是原样例文本总的字数。
二、实现过程
函数:
def levenshtein_distance(hypothesis: list, reference: list):"""编辑距离计算两个序列的levenshtein distance,可用于计算 WER/CER词错率(Word Error Rate, WER)是一项用于评价ASR性能的重要指标,用来评价预测文本与标准文本之间错误率,因此词错率最大的特点是越小越好。像英语、阿拉伯语语音转文本或语音识别任务中研究者常用WER衡量ASR效果好坏。因为英文语句中句子的最小单位是单词,而中文语句中的最小单位是汉字,因此在中文语音转文本任务或中文语音识别任务中使用字错率(Character Error Rate, CER)来衡量中文ASR效果好坏。两者计算方式相同,为行文统一,下文统一使用WER表示该性能。WER = (S+D+I)/N = (S+D+I)/(S+D+C)参考资料:https://www.cuelogic.com/blog/the-levenshtein-algorithmhttps://martin-thoma.com/word-error-rate-calculation/N: number 真实序列的字数C: correct 预测序列识别正确的字数W: wrong 预测序列识别错误的字数I: insert 相较于真实序列,预测序列错误插入的数量D: delete 相较于真实序列,预测序列错误删除的数量S: substitution 相较于真实序列,预测序列错误替换的数量:param hypothesis: 预测序列:param reference: 真实序列:return: 1: 错误操作,所需要的 S,D,I 操作的次数;2: ref 与 hyp 的所有对齐下标3: 返回N、C、W、S、D、I 各自的数量"""len_hyp = len(hypothesis)len_ref = len(reference)cost_matrix = np.zeros((len_hyp + 1, len_ref + 1), dtype=np.int16)# 记录所有的操作,0-equal;1-insertion;2-deletion;3-substitutionops_matrix = np.zeros((len_hyp + 1, len_ref + 1), dtype=np.int8)for i in range(len_hyp + 1):cost_matrix[i][0] = ifor j in range(len_ref + 1):cost_matrix[0][j] = j# 生成 cost 矩阵和 operation矩阵,i:外层hyp,j:内层reffor i in range(1, len_hyp + 1):for j in range(1, len_ref + 1):if hypothesis[i-1] == reference[j-1]:cost_matrix[i][j] = cost_matrix[i-1][j-1]else:substitution = cost_matrix[i-1][j-1] + 1insertion = cost_matrix[i-1][j] + 1deletion = cost_matrix[i][j-1] + 1# compare_val = [insertion, deletion, substitution] # 优先级compare_val = [substitution, insertion, deletion] # 优先级min_val = min(compare_val)operation_idx = compare_val.index(min_val) + 1cost_matrix[i][j] = min_valops_matrix[i][j] = operation_idxmatch_idx = [] # 保存 hyp与ref 中所有对齐的元素下标i = len_hypj = len_refnb_map = {"N": len_ref, "C": 0, "W": 0, "I": 0, "D": 0, "S": 0}while i >= 0 or j >= 0:i_idx = max(0, i)j_idx = max(0, j)if ops_matrix[i_idx][j_idx] == 0: # correctif i-1 >= 0 and j-1 >= 0:match_idx.append((j-1, i-1))nb_map['C'] += 1# 出边界后,这里仍然使用,应为第一行与第一列必然是全零的i -= 1j -= 1# elif ops_matrix[i_idx][j_idx] == 1: # insertelif ops_matrix[i_idx][j_idx] == 2: # inserti -= 1nb_map['I'] += 1# elif ops_matrix[i_idx][j_idx] == 2: # deleteelif ops_matrix[i_idx][j_idx] == 3: # deletej -= 1nb_map['D'] += 1# elif ops_matrix[i_idx][j_idx] == 3: # substituteelif ops_matrix[i_idx][j_idx] == 1: # substitutei -= 1j -= 1nb_map['S'] += 1# 出边界处理if i < 0 and j >= 0:nb_map['D'] += 1elif j < 0 and i >= 0:nb_map['I'] += 1match_idx.reverse()wrong_cnt = cost_matrix[len_hyp][len_ref]nb_map["W"] = wrong_cnttry:wer = (nb_map["S"] + nb_map["D"] + nb_map["I"])/(nb_map["S"] + nb_map["D"] + nb_map["C"])except:wer = float('inf')# print("ref: %s" % " ".join(reference))# print("hyp: %s" % " ".join(hypothesis))# print(nb_map)# print("match_idx: %s" % str(match_idx))return wrong_cnt, match_idx, nb_map, wer
举例1:Ref: 你吃了吗 Hyp: 你吃了么
标准文本为“你吃了吗”,转写结果为“你吃了么”,上例发生了一次错误替换,Hyp将“吗”替换成了么,即S=1,D=0, I =0, 参考文本字数N=4, 因此本次转写结果WER= 1/4 = 25%.
代码:
wrong_cnt, match_idx, nb_map, wer = levenshtein_distance(list("你吃了么"), list("你吃了吗"))print(wrong_cnt, match_idx, nb_map, wer)
结果:

举例2:Ref: 今天天气很好 Hyp: 今天天气很好啊
举例2中,Hyp文本相比标准文本错误插入了一个“啊”,即S=0,D=0,I =1,N=6,因此字错率WER= 1/6 = 16.7%。
代码:
wrong_cnt, match_idx, nb_map, wer = levenshtein_distance(list("今天天气很好啊"), list("今天天气很好"))print(wrong_cnt, match_idx, nb_map, wer)
结果:

三、小结
句错率,SER,SER表述为句子中如果有一个词识别错误,那么这个句子被认为识别错误,句子识别错误的的个数,除以总的句子个数即为SER。
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微信直接交流。


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 放弃低效手动操作吧!Python 脚本自动化 + PINN 物理仿真才是未来CAE工程师的进阶硬实力!
- Linux一口气删掉近4000行代码!活了40年的苹果协议,最终竟被AI“送走”了……
- Python源码一键打包exe神器,可视化界面不用巧命令行,轻松实现py文件转exe
- 【入门到精通】Python编程进阶,一篇文章全吃透!
- AI Agent——Python学习路线
- 【好书推荐】PYTHON编程-从数据分析到数据科学 朝乐门(第二版)(扫描版·复制版)
- 90%财务人都不知道:用AI写Python,根本不用自己敲代码
- Python + Pycharm超详细下载安装教程,小白必备!
- python开发中需要掌握哪些识别和解决内存泄漏的技巧?
- 一图看懂Linux目录结构
