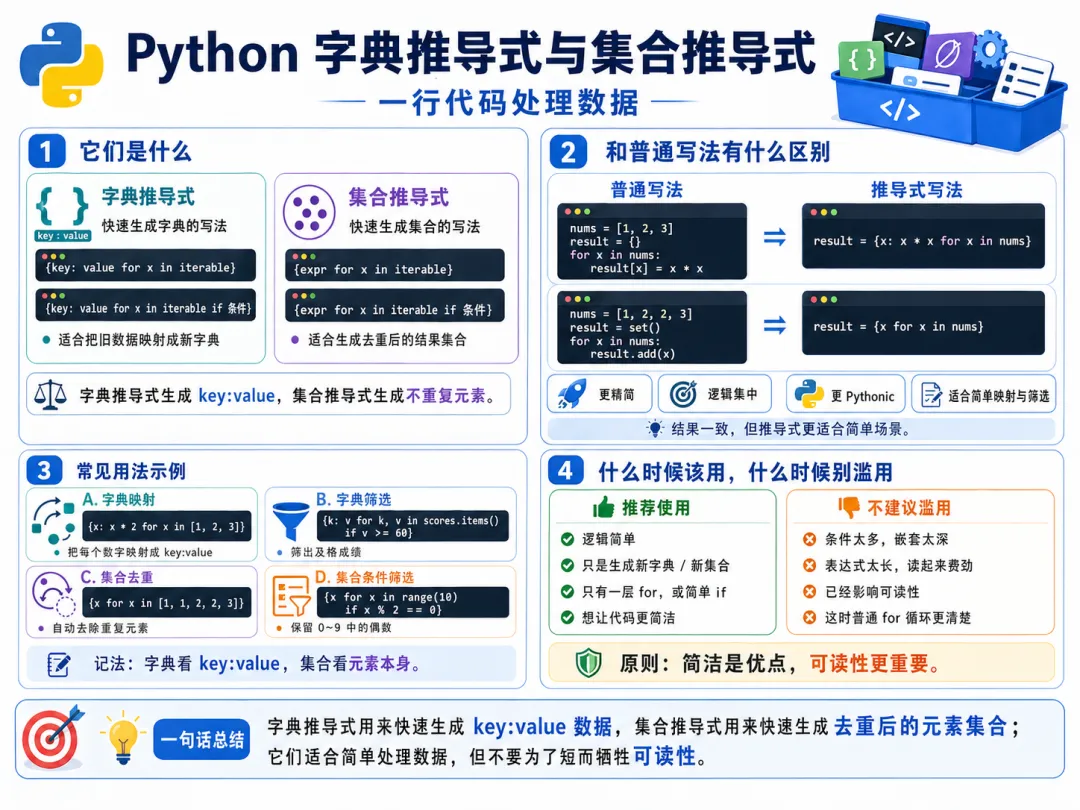
上一章我们已经正式进入了推导式的世界,先认识了列表推导式。你应该已经感觉到了:
推导式并不是什么神秘高级魔法。 它本质上只是把一些非常高频的“循环加收集”逻辑,用更紧凑的方式表达出来。
而且我们已经知道,列表推导式特别适合:
遍历一组旧数据 做处理 筛选条件 生成一个新列表
那接下来,Python 很自然地会往前再走一步:
既然列表可以这么生成, 那字典行不行? 集合行不行?
答案当然是行。
于是就有了这一章的两个主角:
字典推导式 集合推导式
你会发现,它们和列表推导式其实是一家人。只是目标容器从列表,换成了字典和集合。
一、先别急着看语法,先回忆你以前是怎么构造字典的
比如现在你有一个列表:
words = ['apple', 'banana', 'cat']
你想把它变成这样一个字典:
{'apple': 5,'banana': 6,'cat': 3}
也就是:
单词作为键 单词长度作为值
如果按你以前最熟悉的方式写,通常会这样:
words = ['apple', 'banana', 'cat']result = {}for word in words: result[word] = len(word)print(result)
输出结果:
{'apple': 5, 'banana': 6, 'cat': 3}
这段代码当然没有任何问题。 但你会发现,这种模式和列表推导式之前的写法是不是非常像?
准备一个空容器 遍历旧数据 生成新内容 塞进结果容器
既然列表可以压缩成推导式,那字典当然也可以。
二、什么是字典推导式
先给最直接的定义:
字典推导式,就是用一行更紧凑的写法,直接生成一个新字典。
刚才那段代码,用字典推导式写出来就是:
words = ['apple', 'banana', 'cat']result = {word: len(word) for word in words}print(result)
输出结果还是:
{'apple': 5, 'banana': 6, 'cat': 3}
你会发现,逻辑完全没变。 只是原来分散在好几行里的构造过程,被集中到了一个表达式里。
所以你可以先把字典推导式理解成:
把“循环里不断给字典赋键值对”的固定模式,压缩成一行。
三、字典推导式的基础模板长什么样
你现在先记住这个骨架:
{键表达式: 值表达式 for 变量 in 可迭代对象}
例如:
{x: x * x for x in [1, 2, 3, 4]}
这句话的意思是:
遍历 [1, 2, 3, 4]每次取出一个 x把 x 作为键 把 x * x 作为值 最终生成一个字典
输出结果:
{1: 1, 2: 4, 3: 9, 4: 16}
这就是字典推导式最典型的入门例子之一。
四、字典推导式到底该怎么读
看这句:
{x: x * x for x in [1, 2, 3, 4]}
你可以分三部分读。
第一部分:
x: x * x
表示新字典里每一项的键和值怎么构造。
第二部分:
for x in [1, 2, 3, 4]
表示数据从哪里来。
整句话翻译成人话就是:
从 [1, 2, 3, 4] 中一个一个取出 x把每个 x 作为键 把它的平方作为值 放进新字典
只要你学会这样拆,它就一点都不难。
五、字典推导式特别适合哪些场景
你现在可以先把它和下面这些需求绑定起来:
把一个列表转换成字典 做键值映射 根据旧数据快速生成查找表 做批量转换 做简单的数据索引
比如:
单词映射长度 学生映射成绩 文件名映射大小 数字映射平方 键和值做转换
这些几乎都特别适合字典推导式。
六、再看几个特别典型的例子
例子 1,数字映射平方:
nums = [1, 2, 3, 4, 5]result = {n: n * n for n in nums}print(result)
输出:
{1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
例子 2,学生映射成绩:
students = ['张三', '李四', '王五']scores = [95, 88, 91]result = {students[i]: scores[i] for i in range(len(students))}print(result)
输出:
{'张三': 95, '李四': 88, '王五': 91}
例子 3,把字符串映射成长度:
words = ['python', 'book', 'banana']result = {word: len(word) for word in words}print(result)
输出:
{'python': 6, 'book': 4, 'banana': 6}
这些例子有一个共同点:
原始数据先被遍历,然后被组织成键值结构。
这正是字典推导式的天然主场。
七、字典推导式也可以加条件筛选
和列表推导式一样,字典推导式也可以带 if 条件。
比如你只想保留长度大于 4 的单词:
words = ['cat', 'python', 'book', 'banana']result = {word: len(word) for word in words if len(word) > 4}print(result)
输出:
{'python': 6, 'banana': 6}
模板这时候就升级成:
{键表达式: 值表达式 for 变量 in 可迭代对象 if 条件}
这说明字典推导式不仅能构造,还能边筛选边构造。
在数据处理中,这一点会非常常用。
八、一个特别实用的场景:交换字典的键和值
假设你有一个字典:
info = {'a': 1, 'b': 2, 'c': 3}
你想把它变成:
{1: 'a', 2: 'b', 3: 'c'}
普通写法当然可以循环写。 但字典推导式会特别自然:
info = {'a': 1, 'b': 2, 'c': 3}result = {value: key for key, value in info.items()}print(result)
输出:
{1: 'a', 2: 'b', 3: 'c'}
这段代码非常值得你记住。 因为“交换键值”是字典推导式里特别典型、特别有代表性的一个应用。
同时你也会看到,推导式不只是操作列表,也很适合处理字典自身。
九、现在转到集合推导式
前面我们已经见过列表推导式和字典推导式。 集合推导式其实也是同一套思路。
先给最直接的定义:
集合推导式,就是用一行更紧凑的写法,直接生成一个新集合。
比如现在你有一个列表:
nums = [1, 2, 2, 3, 3, 3, 4]
你想生成一个去重后的平方结果集合。
普通写法可能是:
nums = [1, 2, 2, 3, 3, 3, 4]result = set()for n in nums: result.add(n * n)print(result)
输出结果:
{1, 4, 9, 16}
集合推导式写法就是:
nums = [1, 2, 2, 3, 3, 3, 4]result = {n * n for n in nums}print(result)
输出还是:
{1, 4, 9, 16}
你看,是不是一下就和列表推导式接上了。
十、集合推导式的模板长什么样
最基础模板是:
{表达式 for 变量 in 可迭代对象}
注意,这里看起来和字典推导式很像,但少了冒号。
这一点特别关键:
有冒号的是字典推导式。没有冒号的是集合推导式。
比如:
{x * 2for x in [1, 2, 3, 4]}
表示生成一个集合。
而:
{x: x * 2for x in [1, 2, 3, 4]}
表示生成一个字典。
你一定要把这点分清。
十一、集合推导式最适合什么场景
你现在可以先记住下面几类:
批量处理后自动去重 从一组数据中提取唯一值 边筛选边去重 生成不重复结果集合
比如:
获取所有单词长度 提取所有首字母 提取所有不同城市 生成一组唯一标签
这些都很适合集合推导式。
十二、再看几个集合推导式例子
例子 1,提取所有单词长度:
words = ['apple', 'banana', 'cat', 'dog', 'book']result = {len(word) for word in words}print(result)
输出:
{3, 4, 5, 6}
因为长度重复的不会重复保存,这正是集合的特点。
例子 2,提取所有首字母:
words = ['apple', 'banana', 'book', 'cat', 'car']result = {word[0] for word in words}print(result)
输出:
{'a', 'b', 'c'}
例子 3,只保留偶数平方:
nums = [1, 2, 2, 3, 4, 4, 5, 6]result = {n * n for n in nums if n % 2 == 0}print(result)
输出:
{4, 16, 36}
这些例子会帮助你快速建立一个感觉:
集合推导式特别适合“处理后还想自动去重”的情况。
十三、为什么集合推导式很适合数据清洗
因为很多数据清洗场景,本来就特别关心:
唯一值 不重复结果 去重后的标签 分类后的键集合
比如你从一堆用户数据里,想提取所有出现过的城市名:
cities = ['北京', '上海', '北京', '深圳', '上海', '广州']result = {city for city in cities}print(result)
输出:
{'北京', '上海', '深圳', '广州'}
这就特别自然。
如果你前面学过集合的价值,就会很容易理解:
集合推导式的重点不只是“推导”,还包括“去重”。
十四、列表、字典、集合推导式,现在可以放在一起看了
到了这里,你应该开始能感受到它们其实是一套东西。
列表推导式:
[表达式 for 变量 in 可迭代对象]
字典推导式:
{键表达式: 值表达式 for 变量 in 可迭代对象}
集合推导式:
{表达式 for 变量 in 可迭代对象}
你会发现,核心结构都一样:
先写结果长什么样 再写循环来源 有需要的话再加条件
这说明推导式本质上不是三套完全不同的知识,而是一种统一思想在不同容器上的展开。
十五、现在最容易混的点是什么
最大坑通常有两个。
第一个坑,字典推导式和集合推导式看起来都用花括号,容易混。 判断办法很简单:
有冒号,是字典 没冒号,是集合
第二个坑,推导式写太复杂。 一旦你往里面塞太多判断和多层嵌套,代码很快就会从“简洁”变成“难读”。
所以还是那句话:
推导式的前提是更清楚,不是更花哨。
十六、什么时候特别适合字典推导式
你可以先记住这些高频场景:
要快速生成映射关系 要做键值对转换 要把旧数据整理成查找表 要从对象或列表中提取键值结果 要做简单筛选后生成新字典
比如:
姓名映射成绩 单词映射长度 编号映射对象 旧字典键值交换 筛选后生成配置项
这些都非常适合它。
十七、什么时候特别适合集合推导式
也很简单:
你既想批量处理 又想结果自动去重
比如:
提取所有不同长度 提取所有不同首字母 提取所有唯一标签 筛选后保留唯一结果
如果最终结果天然应该是“不重复的一组值”,那集合推导式就很顺手。
十八、做一个小综合案例:整理成绩数据
假设你有一组学生成绩记录:
students = {'张三': 95,'李四': 58,'王五': 88,'赵六': 58,'小明': 95}
现在你想做三件事。
第一,筛出及格学生,生成新字典:
passed = {name: score for name, score in students.items() if score >= 60}print(passed)
输出:
{'张三': 95, '王五': 88, '小明': 95}
第二,提取所有不同成绩:
score_set = {score for score in students.values()}print(score_set)
输出:
{88, 58, 95}
第三,交换键值做个简单映射:
simple_map = {score: name for name, score in students.items()}print(simple_map)
输出可能是:
{95: '小明', 58: '赵六', 88: '王五'}
注意最后这一条很有意思。 因为字典的键不能重复,重复分数会互相覆盖,所以这里只保留最后一次出现的那个名字。
这个例子也提醒你:
推导式只是表达方式,不会改变字典和集合本身的规则。
十九、本章小练习
你可以做三个特别适合巩固的练习。
练习 1 给下面列表生成“数字:平方”的字典:
nums = [1, 2, 3, 4, 5]
练习 2 从下面单词列表中,生成“只保留长度大于 4 的单词及其长度”的字典:
words = ['cat', 'python', 'book', 'banana', 'go']
练习 3 从下面列表中提取所有不重复的偶数平方,生成集合:
nums = [1, 2, 2, 3, 4, 4, 5, 6]
参考答案:
nums = [1, 2, 3, 4, 5]result1 = {n: n * n for n in nums}print(result1)words = ['cat', 'python', 'book', 'banana', 'go']result2 = {word: len(word) for word in words if len(word) > 4}print(result2)nums = [1, 2, 2, 3, 4, 4, 5, 6]result3 = {n * n for n in nums if n % 2 == 0}print(result3)
你把这三个练习亲手写一遍,列表推导式、字典推导式、集合推导式这三兄弟的关系就会非常清楚。
二十、本章总结
这一章最重要的,是把推导式的统一思路继续扩展开。
字典推导式适合快速生成键值映射,基础模板是:
{键表达式: 值表达式 for 变量 in 可迭代对象}
集合推导式适合批量处理后自动去重,基础模板是:
{表达式 for 变量 in 可迭代对象}
两者都可以加 if 条件做筛选。 字典推导式特别适合做映射、索引、键值交换。 集合推导式特别适合做唯一值提取和去重后的结果生成。 学习它们的关键,不是死背花括号,而是理解:推导式本质上是一种“边遍历边生成容器”的统一思想。
下一章我们继续往前走,进入另一个非常高频、但也很容易被误用的高级语法:093|lambda 表达式:匿名函数该在什么时候用。