红黑树:CFS 的高效引擎
Linux 调度子系统技术文档系列 · 第 5 篇
由于缺乏高效的增删改查机制,传统就绪队列在应对大规模进程时产生的 O(n) 耗时,是导致调度器启动延迟的核心瓶颈。Linux 选择了红黑树——一种自平衡二叉搜索树,让查找、插入、删除的时间复杂度全部锁定在 O(log n)。无论就绪进程是 10 个还是 1200 个,调度器的核心操作耗时始终稳定在一个可预期的范围内。
红黑树的"自平衡"并非追求完美平衡。它通过五条颜色规则约束树的形态:根节点为黑色、红色节点不能有红色子节点、每条路径上的黑色节点数量相同。这些规则保证树高不超过 2log(n+1)。代价是插入和删除后需要执行旋转和重新着色操作,但这些调整最多只需两次旋转,不会引发连锁反应。对于调度器这种高频操作场景,局部调整远比全局重平衡高效。
CFS 红黑树的核心组件有哪些?
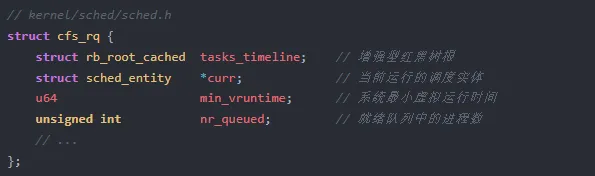
CFS 将就绪进程组织在 cfs_rq(CFS 就绪队列)中。这个结构体的 tasks_timeline 字段是红黑树的根,类型为 rb_root_cached——Linux 内核提供的一种增强型红黑树,自带最左节点缓存。
每个进程对应的 sched_entity 中嵌入了 rb_node 节点。进程从等待态进入就绪态时,内核通过 run_node 将 sched_entity 挂入红黑树。内核用 container_of(通过 rb_entry 宏封装)从 rb_node 反查 sched_entity,实现零额外内存开销的双向关联。
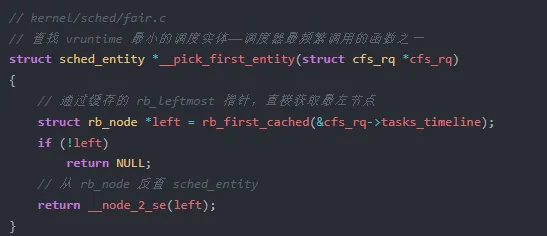
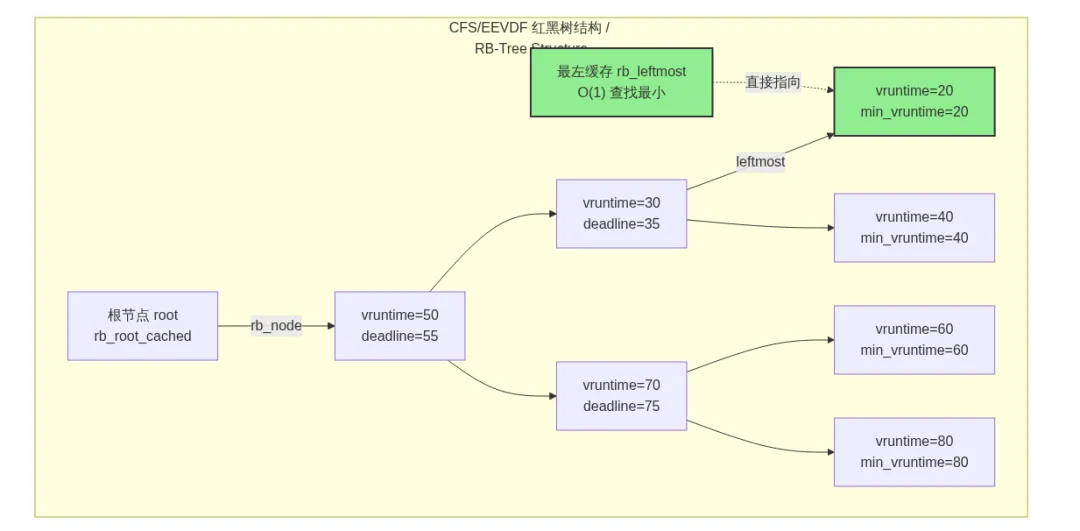
红黑树的排序键是 vruntime。vruntime 越小的进程,在树中越靠左。理论上,查找最小 vruntime 进程需要从根节点一路向左走 O(log n) 步。但内核在这里做了一个关键的工程优化——rb_root_cached 缓存了最左节点的指针,让调度器最频繁执行的操作降到了 O(1)。
在 EEVDF(Earliest Eligible Virtual Deadline First)算法下,红黑树的功能进一步扩展。树不仅按 deadline 排序,还通过 min_vruntime 增强字段维护子树最小值,实现 O(log n) 的资格剪枝。调度器可以在遍历时快速跳过不满足资格的子树,而不需要遍历所有节点。
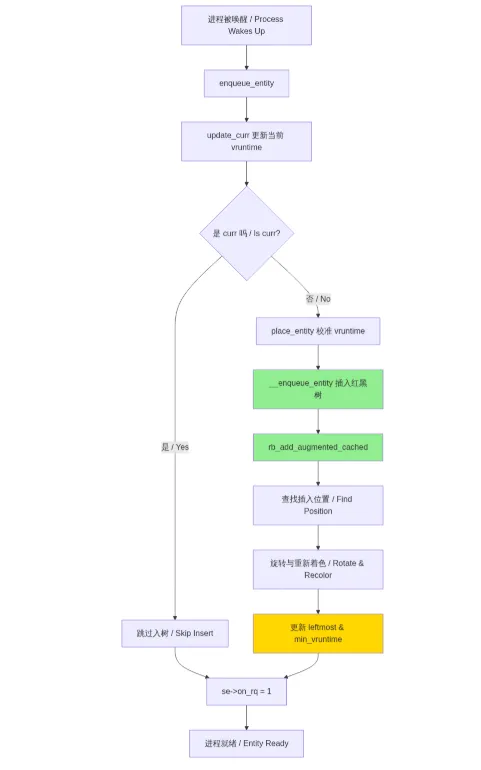
进程入树:从等待到就绪的完整路径
进程从阻塞态被唤醒时,内核执行 enqueue_entity。这个函数要完成三件事:更新负载统计、校准时间基准、插入红黑树。插入红黑树只发生在进程不是当前运行进程的情况下——如果是当前进程重新入队,它不需要进树,因为它已经在运行了。
place_entity 负责给新入队的进程分配一个合理的初始 vruntime。对于刚 fork 的子进程,内核会给它一个略高于 min_vruntime 的值,让它有公平竞争的机会。对于从睡眠中唤醒的进程,place_entity 会考虑它等待了多久,适当补偿它的 vruntime。
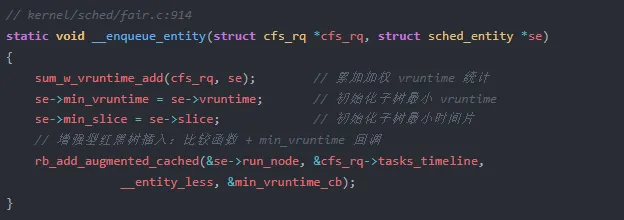
真正执行树插入的是 __enqueue_entity。内核使用 rb_add_augmented_cached 这个增强版红黑树 API,它同时处理树节点插入、平衡调整、最左节点缓存更新,以及 min_vruntime 增强字段的维护。比较函数 __entity_less 决定节点在树中的位置,回调 min_vruntime_cb 负责在树结构调整后更新 min_vruntime。
rb_add_augmented_cached 内部执行了完整的红黑树插入流程:先按比较函数找到插入位置,挂入节点,执行旋转和重新着色平衡树结构,最后更新最左节点缓存和 min_vruntime。整个过程 O(log n),最多两次旋转。
出队路径同样简洁。__dequeue_entity 调用 rb_erase_augmented_cached 删除节点,平衡树结构,更新缓存和增强字段,最后减去负载统计。__pick_eevdf 从根节点出发,利用 min_vruntime 做资格剪枝,在 O(log n) 时间内找到最早可达截止期的 eligible 进程。
为什么 CFS 选择红黑树?
这个问题的答案需要从调度场景的特殊约束说起。调度器每毫秒执行一次,每次执行都要做一次查找、可能的删除和可能的插入。这意味着红黑树的操作频率是每秒数千次。在这种频率下,数据结构的选择直接决定了系统的吞吐量和延迟。
让我们逐一排除其他选项。数组的缓存局部性最好,查找最小值却需要 O(n) 的线性扫描。1200 个进程时就是 1200 次比较,加上分支预测失败的代价,调度延迟急剧上升。链表的插入是 O(1),但查找最小值同样是 O(n)。堆结构查找最小值是 O(1),删除最小值是 O(log n),但删除任意元素需要先找到它,最坏是 O(n)——而调度场景中经常需要删除特定进程(比如进程主动退出或被信号杀死)。
红黑树的选择体现了内核开发者的工程权衡。O(log n) 比 O(1) 差吗?在调度场景下,答案是否定的。1200 个进程的 log(1200) 约等于 11,意味着红黑树查找最多 11 次比较。而缓存优化把最常见的查找最小值操作提升到了 O(1)。换句话说,红黑树在 O(log n) 的框架内,通过 rb_leftmost 缓存把最高频操作优化到了 O(1),同时保持了插入、删除、任意查找全部 O(log n) 的一致性。
这种一致性是红黑树不可替代的核心优势。调度器不能容忍"大部分时候快,偶尔很慢"的行为——一次 O(n) 的抖动就意味着数百毫秒的调度延迟,在实时场景下这是不可接受的。红黑树保证了无论就绪队列多大,每次操作的耗时都在一个可预期的范围内。
从用户空间的角度看,这个选择直接影响了大规模容器部署的体验。在一台运行 1200 个容器的宿主机上,每个容器的启动时间、网络请求响应时间都间接依赖调度器的查找效率。红黑树让调度延迟从 O(n) 的线性增长变成了 O(log n) 的对数增长,1200 个进程相比 10 个进程,理论延迟只增加了 log(1200)/log(10) ≈ 3.1 倍,而不是 120 倍。
总结
红黑树在 CFS 中扮演的角色远不止一个"排序容器"。它是调度器公平性和响应速度的基础设施:通过 vruntime 排序保证进程按虚拟时间公平竞争,通过 rb_leftmost 缓存实现 O(1) 的最小值查找,通过增强型 min_vruntime 字段支持 EEVDF 的资格剪枝,通过 O(log n) 的一致性操作保证大规模场景下的可预期延迟。
Linux 内核在这里做了一个经典的工程决策:不追求理论最优,而追求综合最优。堆在查找最小值上更快,但不支持高效的任意删除;B 树在缓存局部性上更好,但实现复杂度更高。红黑树在所有维度上都达到"足够好",同时保证了最坏情况下的可预期性。对于操作系统内核,可预期性就是可靠性。
互动问题: 如果你的服务器从 50 个进程扩展到 5000 个容器,红黑树的 O(log n) 能让调度延迟保持在什么范围?EEVDF 引入的 min_vruntime 增强字段相比传统 CFS 的简单左最节点查找,在高并发场景下能减少多少无效遍历?欢迎在评论区分享你的测算结果。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处