 假设你要回测一个策略,需要下载 50 只股票的价格数据。但传统方式通常是一只股票一只股票地下载。这个顺序下载过程可能会非常慢,尤其是每次接口调用都需要等待外部服务或本地客户端响应时。那有没有办法同时下载多只股票的数据?这就要请出我们今天的主角“多线程了”!
假设你要回测一个策略,需要下载 50 只股票的价格数据。但传统方式通常是一只股票一只股票地下载。这个顺序下载过程可能会非常慢,尤其是每次接口调用都需要等待外部服务或本地客户端响应时。那有没有办法同时下载多只股票的数据?这就要请出我们今天的主角“多线程了”!
什么是多线程?
多线程是一种编程技术,它允许程序并发执行多个线程。
那什么是线程?线程是操作系统可以独立管理的最小执行单元。你可以把线程理解成运行在主程序内部的一个小程序。
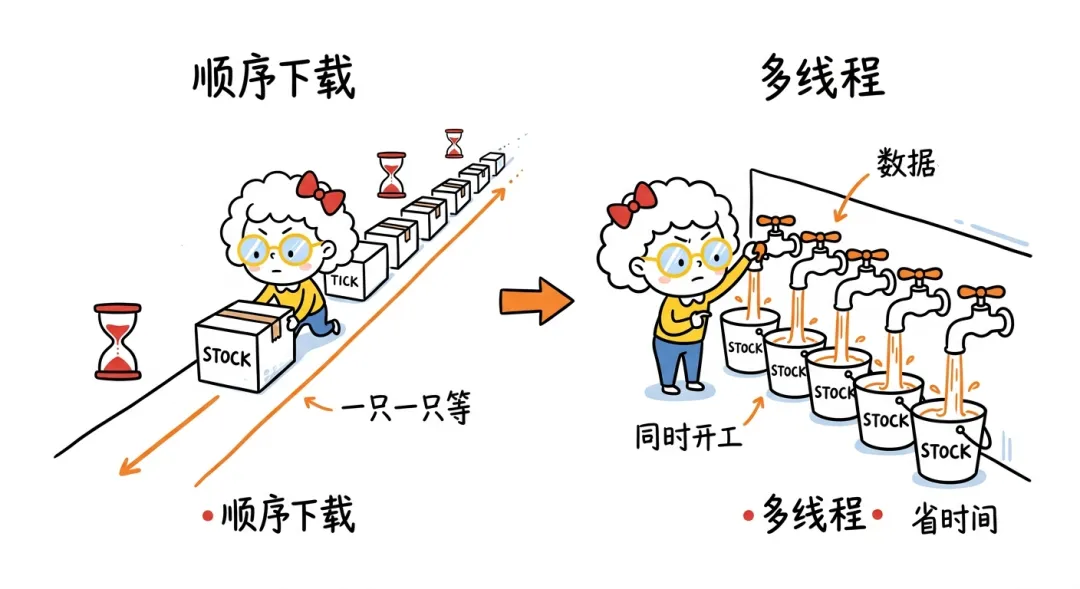
当你写一个 Python 程序下载股票行情时,程序会从一个主线程开始执行,并按照代码顺序一步一步运行。如果你写脚本下载多只股票的价格数据,主线程会先发送第一个请求,等待响应,处理数据,然后再进入下一只股票,如此重复。
由于每次下载都需要等待服务端、客户端或本地缓存返回结果,程序在这段时间里其实是空闲的。这就是多线程可以发挥作用的地方。
 Gemini_Generated_Image_3m9fpi3m9fpi3m9f
Gemini_Generated_Image_3m9fpi3m9fpi3m9f使用多线程后,程序不再只依赖主线程,而是创建多个线程同时工作。每个线程可以处理一只不同的股票,让多个下载任务并行发生。一个线程下载第一只股票的数据,另一个线程下载第二只股票的数据,第三个线程处理第三只股票的数据。
如果某个线程正在等待响应,其他线程仍然可以继续工作,从而减少空闲时间,让程序运行得更快。虽然看起来所有线程都在同时运行,但操作系统实际上是在快速切换它们,制造出并行执行的效果。
在多核电脑上,部分线程可以真正并行运行,进一步提升效率。因为所有线程共享同一块内存空间,所以在处理共享数据时,需要注意避免冲突和意外行为。
现在你已经理解了多线程如何帮助加快股票数据下载,接下来我们用一个简单例子看看如何在 Python 中实现它。
如何在 Python 中实现多线程?
 默认文件1782098934316
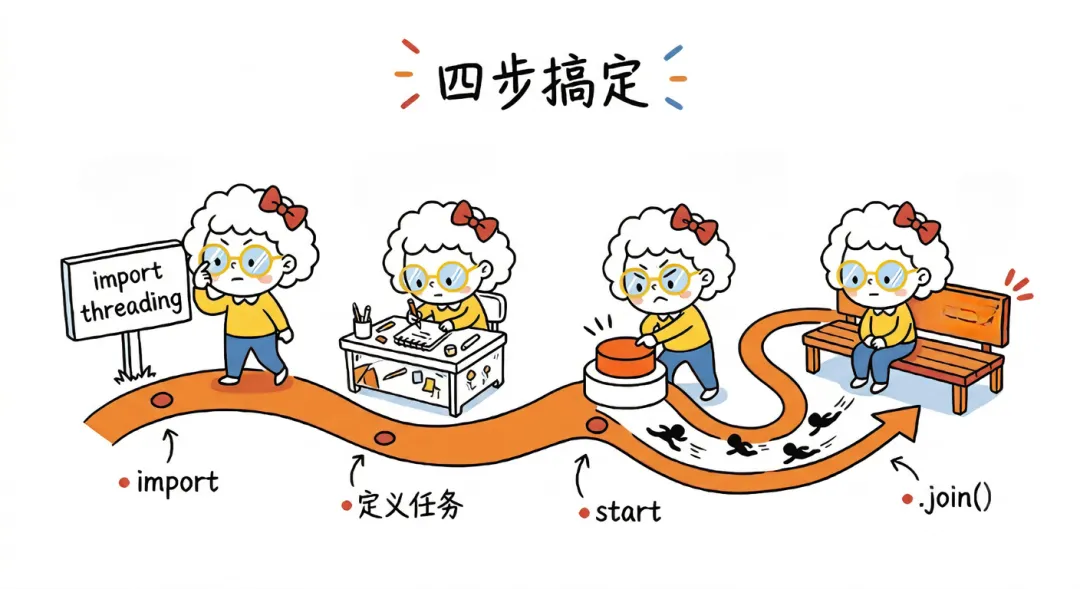
默认文件1782098934316Step 1:导入 threading 模块
第一步是导入 threading 模块。它允许我们让多个函数并发运行。
import threading
Step 2:定义任务
我们需要先定义一个函数,说明每个线程要执行什么工作。
在这个例子中,这个函数会模拟下载股票数据:先打印下载提示,等待两秒,然后提示下载完成。
import time
defdownload_stock(ticker):
print(f"正在下载 {ticker}...")
time.sleep(2) # 模拟 2 秒下载时间
print(f"{ticker} 下载完成!")
Step 3:创建并启动线程
不再按顺序执行函数,而是为不同任务创建不同线程。线程可以让这些任务同时开始。
# 为两只股票创建两个线程
thread1 = threading.Thread(target=download_stock, args=("股票1",))
thread2 = threading.Thread(target=download_stock, args=("股票2",))
# 启动线程
thread1.start()
thread2.start()
Step 4:等待线程完成
为了确保所有线程执行完毕后程序再继续向下运行,需要使用 .join() 方法。这样可以防止任务还没完成,程序就提前退出。
thread1.join()
thread2.join()
print("所有下载任务完成!")
现在你已经理解了多线程的基本实现方式。接下来,我们进入一个更实际的例子:下载 5 只股票的数据。
实战例子:多股票行情数据下载
接下来举个例子,使用 miniQMT 的 xtdata 获取行情。
需要注意的是,miniQMT 获取历史行情通常分两步:
第一步,使用 download_history_data 下载历史数据到本地缓存;
第二步,使用 get_market_data_ex 从本地缓存读取行情数据。
import time
import threading
from xtquant import xtdata
tickers = ["股票1", "股票2", "股票3", "股票4", "股票5"]
deffetch_data(ticker):
xtdata.download_history_data(
stock_code=ticker,
period="1d",
start_time="20240101",
end_time="",
incrementally=True,
)
data = xtdata.get_market_data_ex(
field_list=["open", "high", "low", "close", "volume"],
stock_list=[ticker],
period="1d",
start_time="20240101",
end_time="",
count=-1,
dividend_type="front_ratio",
fill_data=True,
)
df = data[ticker]
df.to_csv(f"{ticker}.csv", index=False)
print(f"{ticker}: {len(data.get(ticker, []))} 行数据")
# 不使用多线程
start = time.time()
for ticker in tickers:
fetch_data(ticker)
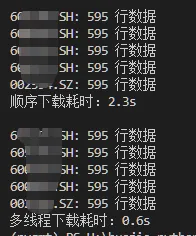
print(f"顺序下载耗时:{time.time() - start:.1f}s\n")
# 使用多线程
start = time.time()
threads = []
for ticker in tickers:
thread = threading.Thread(target=fetch_data, args=(ticker,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print(f"多线程下载耗时:{time.time() - start:.1f}s")
输出结果:(具体耗时会因设备、miniQMT 客户端状态、网络情况、本地缓存情况而不同,但多线程执行通常会更快。)
 20260622110833
20260622110833“注:miniQMT行情下载以后会缓存到本地,股票首次下载和第二次下载用时不同,第一次会慢第二次会快很多,所以在测试的时候要注意两次测试的股票要选择不同的。
可以看到,多线程比顺序下载快得多。
重要提醒:虽然多线程可以显著加快数据下载,但使用 miniQMT 时也要注意线程数量。miniQMT 的行情下载依赖本地客户端、行情服务和本地缓存。如果线程开得过多,可能不会更快,反而可能导致客户端响应变慢、请求失败或数据不稳定。实际使用时,可以先从较小的线程数量开始测试,并确认 miniQMT 客户端已经正常启动。
什么时候适合使用多线程,什么时候不适合?
在这篇文章中,我们介绍了多线程的实现方式,并用一个下载多只股票行情数据的实际例子展示了它的优势。
理解多线程适合什么场景、不适合什么场景非常重要。
Python 多线程最适合输入输出密集型任务,也就是程序大部分时间都在等待外部数据,而不是持续进行计算的任务。输入输出密集型任务包括:从网络下载数据、读取和写入文件、与数据库通信、等待本地客户端返回结果等。
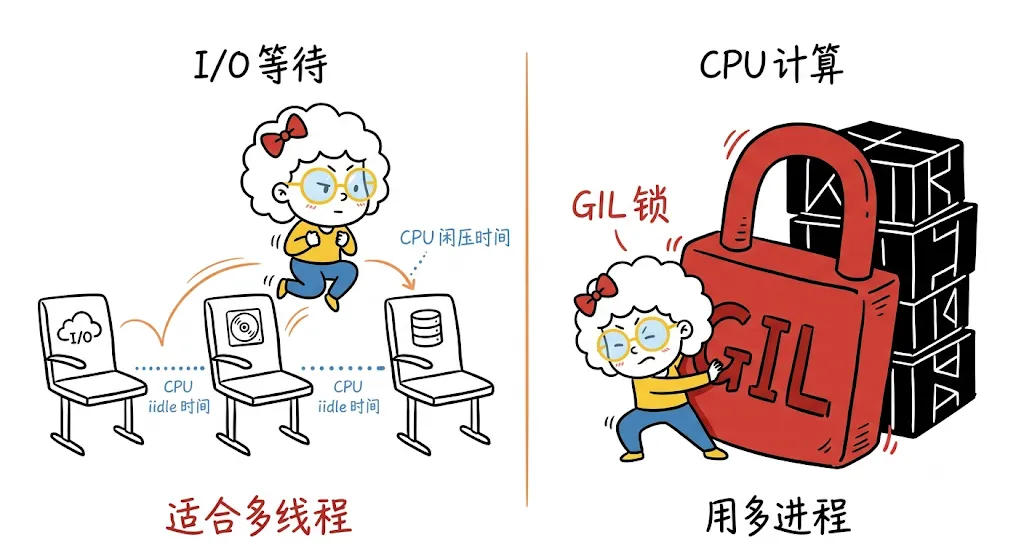 20260622113130
20260622113130在这些场景中,CPU 经常处于空闲状态,等待外部响应。多线程可以让 Python 在一个线程等待时切换到另一个线程继续执行,从而减少整体等待时间。
但是,多线程不适合 CPU 密集型任务,例如大量数学计算、机器学习模型训练、大规模数据处理等。这类任务需要持续占用计算资源,系统没有太多空闲时间在线程之间切换。
Python 的全局解释器锁,也就是 GIL,会限制同一进程中多个线程同时执行 Python 代码。即使创建了多个线程,在任意时刻通常也只有一个线程在执行 Python 代码,因此对于 CPU 密集型任务,性能提升并不明显。
对于 CPU 密集型任务,多进程通常是更好的选择。线程共享同一个进程,而多进程会创建多个独立进程,每个进程都有自己的内存空间和执行环境。这样任务就可以在多个 CPU 核心上并行运行,从而绕开 GIL 带来的限制。
总的来说,多线程并不是复杂的黑科技,它更像是一个把等待时间利用起来的小工具。
在批量获取行情数据这类任务里,程序真正慢的地方往往不是计算,而是一次次等待数据返回。把这些等待任务拆给多个线程处理,就能让数据准备过程更高效。
如果你使用 miniQMT 做量化研究,可以先从少量线程开始测试,确认客户端稳定、数据能正常下载和读取,再逐步扩大股票池。速度很重要,但稳定的数据更重要。
把行情数据准备得更顺,后面的回测、分析和策略迭代,才会真正省时间。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
