折腾 fnOS/NAS 本地 AI 的小伙伴应该都发现了:应用商店里的 Ollama 套件自带 OpenWebUI,虽开箱即用,但如果只是用来跑模型、对接 API,Web 前端完全属于多余组件,还会额外占用存储与算力。今天教大家两种只安装 Ollama 主程序的部署方法,不附带任何网页端,轻量化纯净部署,适合只需要底层推理服务、习惯 SSH 命令行操作的玩家。如果你的网络允许的情况下,可以使用下面的一键脚本安装Ollama,方便快捷:curl -fsSL https://ollama.com/install.sh | sh
大多数情况下我们的网络无法直接访问官方脚本(通过Github部署),就需要用到这个方法了,使用Ollama离线包安装:# 使用迅雷可以加速下载 https://ollama.com/download/ollama-linux-amd64.tar.zst
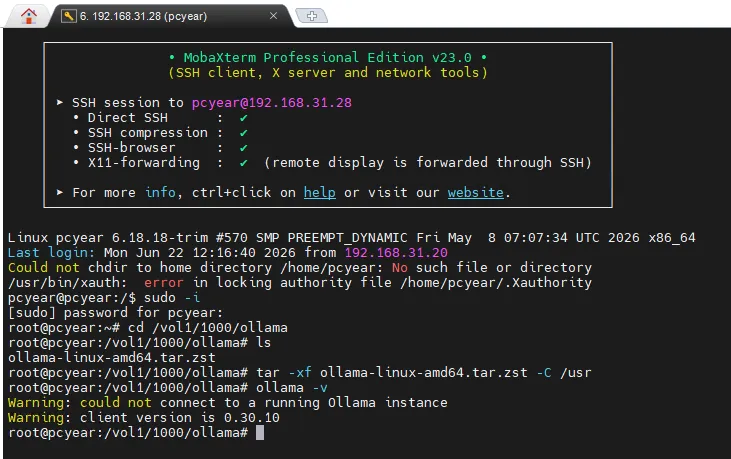
2. 在飞牛的存储空间创建“ollama”文件夹,用来存放离线包。如果你使用的不是飞牛NAS系统,方法也是通用的,在你的系统新建一个可以存放离线包的目录即可。3. 将下载好的 “ollama-linux-amd64.tar.zst” 文件上传至 “ollama” 文件夹中。4. 然后使用SSH工具登录到飞牛SSH控制台,依次执行以下命令:# 先提权sudo -i# 然后将目录切换到存放ollama文件包的位置 cd /vol1/1000/ollama# 将ollama文件包解压到系统全局目录tar -xf ollama-linux-amd64.tar.zst -C /usr# 然后验证一下是否安装成功ollama -v
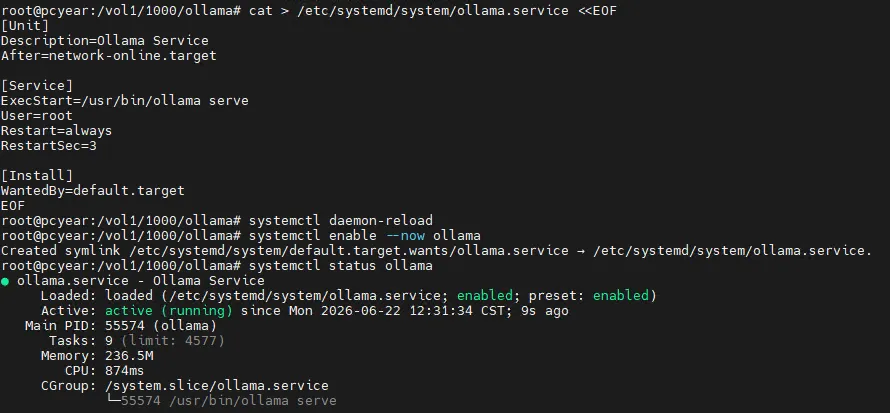
看到 “client version is 0.30.10” 版本号,表示已经安装完成了!5. 手动创建 systemd 服务文件,实现开机自启# 复制下面所有内容,直接在命令行执行即可创建 “ollama.service” 文件 cat > /etc/systemd/system/ollama.service <<EOF[Unit]Description=Ollama ServiceAfter=network-online.target[Service]ExecStart=/usr/bin/ollama serveUser=rootRestart=alwaysRestartSec=3Environment="OLLAMA_HOST=0.0.0.0:11434"[Install]WantedBy=default.targetEOF
7. 设置开机自启 && 立即启动 && 查看运行状态systemctl enable --now ollama# 然后查看下Ollama的运行状态systemctl status ollama
出现 active (running) 则表示 Ollama 启动成功了。
8. 接下来,需要拉取一下模型,我们以 “qwen:7b” 为例:
# 拉取 qwen:7b 模型 ollama pull qwen:7b# 查看已安装模型列表ollama list
当界面显示如下图状态,表示“qwen:7b”模型已经安装成功了!
qwen:7b 最低运行要求:纯 CPU 推理至少需要 8GB 空闲内存,推荐 12GB 以上,如果可用内存低于 6G,加载 7B 模型会被系统 kill 掉。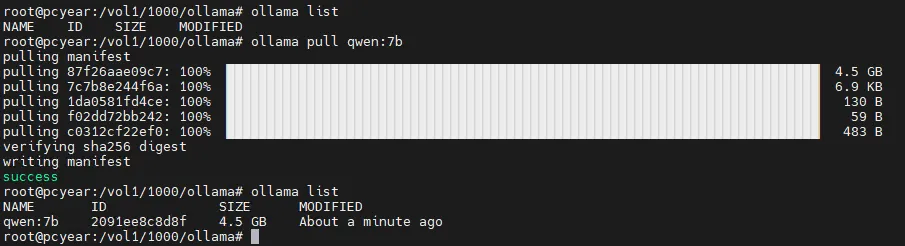
给大家整理了一些 Ollama 的常用命令
1. 拉取模型
ollama pull qwen:7b# 指定镜像源加速下载(国内必用)OLLAMA_HOST=https://ollama.XXX.org ollama pull qwen:7b
2. 查看本地已经下载的模型
3. 运行对话模型
ollama run qwen:7b# 单次提问直接输出,不进入交互式终端ollama run qwen:7b "你是谁?你在飞牛中可以干什么?"
4. 删除本地模型
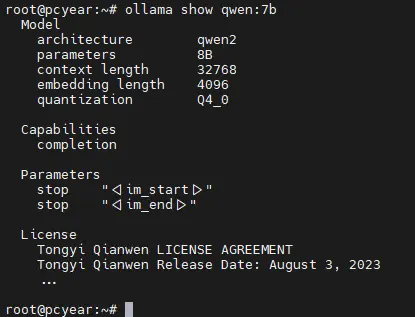
5. 查看模型详情(参数、文件大小、参数规模等)
ollama show qwen:7b# 只查看模型Modelfile配置ollama show qwen:7b --modelfile# 只查看模型参数信息ollama show qwen:7b --parameters
以上就是部署纯净 Ollama 核心程序的所有步骤了,感谢大家观看!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
