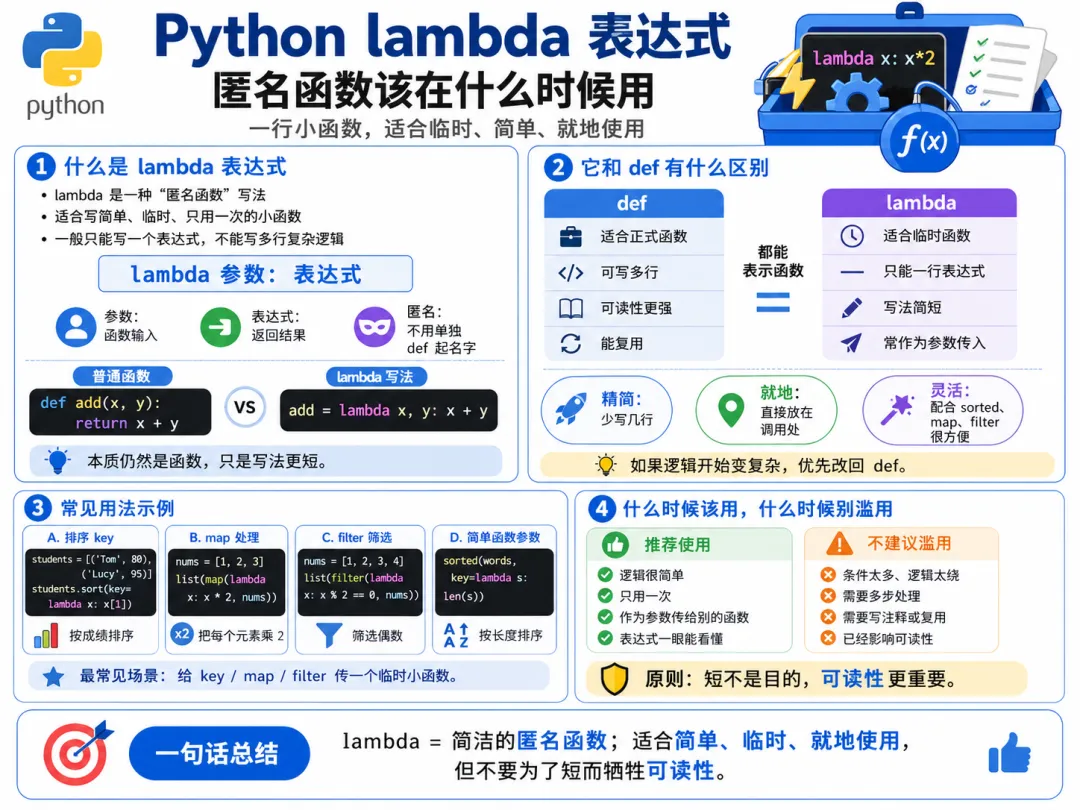
前面我们已经学过函数,也知道函数的核心价值,不只是把代码包起来,更重要的是把一段逻辑变成一个可以重复使用的能力。到了这一章,Python 会给你一个看起来有点特别、但其实并不复杂的写法:
lambda
很多人第一次看到它时,会觉得有点怪。
为什么这里突然不用 def 了 为什么函数可以一行写完 为什么它好像没有名字 这东西到底是不是高级写法 是不是以后函数都要改成这样写
这些疑问都特别正常。
先提前告诉你一个特别重要的结论:
lambda 不是用来替代普通函数的。它更像是一种适合小场景、短逻辑、临时使用的匿名函数写法。
这一章,我们就把这件事彻底讲清。你会发现,lambda 真正难的不是语法,而是很多人一开始不知道它到底该在什么时候用。
一、先别急着看 lambda,先看你已经会的写法
比如你想写一个函数,把传进来的数字翻倍。
最正常的写法当然是:
defdouble(x):return x * 2print(double(5))
输出结果:
10
这就是一个非常标准、非常清楚的函数。
它有名字 它能被重复调用 它适合后面反复使用
那为什么还要有 lambda?
因为有时候,你并不是想认真定义一个将来会频繁使用的函数。 你只是临时需要一个特别短的小函数逻辑,用一次就够了。
这时候,如果还专门写一个 def,有时会显得有点重。
于是,lambda 就出场了。
二、什么是 lambda 表达式
先给最直白的定义:
lambda 表达式,就是一种用来快速写匿名函数的方式。
关键词有两个:
快速 匿名
什么叫快速?
就是它能把一个很短的函数逻辑,直接写成一行。
什么叫匿名?
就是它通常没有像 double 这种正式函数名。
比如刚才那个翻倍函数,用 lambda 可以写成:
double = lambda x: x * 2print(double(5))
输出结果:
10
你会发现,结果完全一样。
但这里的函数不是通过 def 定义出来的,而是通过 lambda 表达式生成后,再赋值给变量 double。
所以你现在可以先把它理解成:
lambda 是一种更紧凑的函数表达方式。
三、lambda 最基础的结构长什么样
你先记住这个骨架:
lambda 参数: 返回值表达式
比如:
lambda x: x * 2
这句话的意思就是:
接收一个参数 x返回 x * 2 的结果
你可以把它对应回普通函数:
defdouble(x):return x * 2
你会发现,lambda 本质上并没有创造什么新能力。 它只是把原本函数里的这两部分:
参数 返回值
压缩成了一行。
所以你可以把 lambda 先粗略理解成:
省略了 def 和 return 的简写函数。
不过这里要注意,虽然这么理解很方便,但它并不意味着以后所有函数都该这么写。后面我们会专门讲它的边界。
四、先看几个最基础的 lambda 例子
例子 1,加 1:
add_one = lambda x: x + 1print(add_one(10))
输出:
11
例子 2,两个数相加:
add = lambda a, b: a + bprint(add(3, 5))
输出:
8
例子 3,取平方:
square = lambda x: x * xprint(square(6))
输出:
36
看到这里,你应该已经能感觉到:
lambda 并不神秘。 它和普通函数本质上做的是同一件事。 只是写法更紧凑。
五、lambda 和 def 到底是什么关系
这是本章最关键的问题之一。
很多新手一看到 lambda,会以为这是另一种完全不同的函数体系。其实不是。
更准确地说:
lambda 也是函数。它生成出来的结果,本质上还是一个函数对象。
比如:
f = lambda x: x * 2print(type(f))
你会发现,它本质上依然是函数。
所以你不要把它理解成什么特别独立、特别神秘的东西。 它只是函数的一种写法而已。
这个认知非常重要。因为只有这样,你后面才不会把它当成“高级语法怪物”。
六、那为什么不一直用 lambda
这就是很多人最容易走偏的地方。
前面你看到:
double = lambda x: x * 2
感觉好像挺短。 那是不是以后所有函数都可以写成 lambda?
不是。
原因很简单:
lambda 适合短逻辑,不适合复杂逻辑。
比如下面这种简单函数,用 lambda 还说得过去:
lambda x: x * 2
但如果一个函数里需要:
多步计算 多行逻辑 条件判断 循环 打印 异常处理
那你硬写成 lambda,不仅不优雅,反而会很难读。
所以从设计角度来说:
def 是常规主力lambda 是临时补充
这个定位一定要先立住。
七、lambda 和普通函数最大的外观区别是什么
你可以先直接记住几个最明显的外观差别。
第一,lambda 通常写成一行。 第二,它没有函数名这个部分。 第三,它不写 return,但表达式结果会自动作为返回值。 第四,它只能写一个表达式,不能写复杂语句块。
比如:
lambda x: x + 1
这就是一个完整的 lambda。
而你不能这样在 lambda 里面写:
lambda x: y = x + 1return y
这就不行。
这说明什么?
说明 lambda 本身就是一种为“简单逻辑”而生的函数表达形式。
八、为什么说它是匿名函数
因为它原本没有正式函数名。
比如你写:
lambda x: x * 2
这里并没有像:
defdouble(x):
那样给它命名。
当然,你后面可以把它赋值给变量:
f = lambda x: x * 2
但这和 def double() 那种明确命名的感觉还是不太一样。
所以“匿名函数”这个词,重点不在于它永远不能有变量引用,而在于:
它最初就是一种不强调正式命名的小函数写法。
这个味道你要抓住。
九、真正高频的场景,不是单独定义 lambda,而是作为参数传进去
这一点特别重要。
如果你只是写:
f = lambda x: x * 2
那很多时候还不如直接写成:
deff(x):return x * 2
更清楚。
所以 lambda 真正高频的使用场景,通常不是单独摆在那,而是:
把它作为一个临时函数,传给别的函数使用。
这句话先记住。 因为从这一刻开始,你就会明白 lambda 的真正价值不在“短”,而在“临时传入”。
最典型的场景,就是排序。
十、lambda 最经典的使用场景:排序 key
先看一个很有代表性的例子。
假设有一组元组数据:
students = [ ('张三', 95), ('李四', 88), ('王五', 91)]
现在你想按成绩排序。
如果你直接写:
students.sort()print(students)
默认会先按元组的第一个元素排,也就是先按名字排。 但你真正想按成绩排,这时候就要告诉 Python:
排序时,请拿每个元素里的第二项当依据。
这时常见写法就是:
students = [ ('张三', 95), ('李四', 88), ('王五', 91)]students.sort(key=lambda x: x[1])print(students)
输出:
[('李四', 88), ('王五', 91), ('张三', 95)]
这里的:
lambda x: x[1]
意思就是:
给我一个元素 x我返回它的第 2 项 排序时就按这个值来比
这就是 lambda 最经典、最常见、最实用的场景之一。
十一、为什么这里用 lambda 特别合适
因为你只是临时告诉排序函数一件事:
排序依据是什么
你根本不需要专门为了这一个小逻辑,去写一个正式函数名。
当然,你也可以写成:
defget_score(item):return item[1]students.sort(key=get_score)
这当然没问题。
但这里的 get_score() 逻辑非常短,而且只是在这次排序时临时用一下。 那用 lambda 就会显得更自然:
students.sort(key=lambda x: x[1])
所以你现在应该开始真正理解 lambda 的定位了:
不是替代正式函数,而是作为小型、临时、只用一次的函数逻辑。
十二、再看几个排序场景,你会更有感觉
例子 1,按字符串长度排序:
words = ['python', 'go', 'banana', 'cat']words.sort(key=lambda x: len(x))print(words)
输出:
['go', 'cat', 'python', 'banana']
例子 2,按字典里的年龄排序:
users = [ {'name': '张三', 'age': 18}, {'name': '李四', 'age': 22}, {'name': '王五', 'age': 20}]users.sort(key=lambda x: x['age'])print(users)
输出会按年龄从小到大排列。
例子 3,按元组里的第二个值倒序排序:
students = [ ('张三', 95), ('李四', 88), ('王五', 91)]students.sort(key=lambda x: x[1], reverse=True)print(students)
输出:
[('张三', 95), ('王五', 91), ('李四', 88)]
这些例子会帮助你建立一个非常强的条件反射:
一看到排序规则很简单,而且只是临时用一下,lambda 往往就特别顺手。
十三、map 和 filter 里也经常会见到 lambda
下一章我们会正式讲 map、filter、reduce,但这里你可以先提前感受一下。
比如:
nums = [1, 2, 3, 4]result = list(map(lambda x: x * 2, nums))print(result)
输出:
[2, 4, 6, 8]
再比如:
nums = [1, 2, 3, 4, 5, 6]result = list(filter(lambda x: x % 2 == 0, nums))print(result)
输出:
[2, 4, 6]
你现在先不用深究 map 和 filter 本身。 这里只是先让你感受到:
lambda 经常和“需要一个短函数作为参数”的场景绑定出现。
排序是这样。map 是这样。filter 也是这样。
这就是它为什么存在感很强的原因。
十四、lambda 能不能写条件表达式
可以,但要注意别写得太难读。
比如:
check = lambda x: '及格'if x >= 60else'不及格'print(check(75))print(check(40))
输出:
及格不及格
这说明 lambda 里虽然不能写完整的 if 语句块,但可以写条件表达式。
不过这里一定要提醒你:
能写不等于该写。
如果逻辑只是这种一眼就能看懂的小判断,那还行。 但如果条件一多,分支一复杂,就不要为了硬用 lambda 而降低可读性。
十五、什么时候适合用 lambda
你现在可以先记住下面这些典型场景:
排序时临时指定 key 传给 map()、filter() 这种函数 只需要一个一次性的小函数 逻辑非常短,一眼能看懂 不值得专门写一个正式 def
这些就是 lambda 最舒服的舞台。
你会发现,这些场景有一个共同点:
这个函数不是项目主角,它只是当前某个操作里临时需要的一小段逻辑。
这就是 lambda 的定位。
十六、什么时候不适合硬用 lambda
这也必须说清楚。
下面这些情况,通常更适合老老实实写 def:
函数逻辑超过一行还想拆步骤 需要写注释说明 后面会多次复用 逻辑本身不够直观 包含复杂分支 你想给这个功能一个明确名字
比如你要写一个真正有业务含义的函数:
计算折后价 验证用户名 生成订单编号 检查权限 处理异常输入
这些函数通常都有明确语义,也很可能被重复调用。 那就别硬写成 lambda 了,直接 def 更清楚。
所以你可以直接记住一条非常稳的经验:
能让代码更清楚时再用 lambda。否则就用 def。
十七、一个特别常见的误区:以为 lambda 更高级
不是。
很多新手刚接触 lambda,会有一种错觉:
用了 lambda,好像代码就更高级了
其实这恰恰是最容易误入的方向。
真正成熟的代码,不看你用了多少花哨语法,而看:
可读性 清晰度 是否适合当前场景
如果一个地方写成 lambda 之后更难懂,那它就不是更高级,而是更糟糕。
所以请你一定要建立一个非常健康的理解:
lambda 只是工具,不是身份象征。
这句话非常重要。
十八、一个特别实用的判断方法
以后你遇到某个场景时,可以先问自己两个问题:
第一,这个函数逻辑是不是非常短? 第二,这个函数是不是只临时用一次?
如果两个答案都是“是”,那很可能适合 lambda。
如果任何一个答案变成“不是”,那你就应该认真考虑直接写 def。
比如排序 key:
逻辑短 通常临时用一次 很适合 lambda
比如用户校验函数:
逻辑可能不短 可能会复用 更适合 def
你只要把这套判断思路立住,lambda 基本就不会乱用。
十九、和前面的列表推导式有什么关系
这两章放在一起,其实很自然。
列表推导式是在说:
有些高频的列表生成逻辑,可以用更紧凑的方式写
lambda 则是在说:
有些高频的小函数逻辑,也可以用更紧凑的方式写
所以它们有一个共同点:
都是 Python 为高频小模式提供的紧凑表达方式。
但共同点之外,也要看到区别:
列表推导式是生成容器 lambda 是生成函数
把这点分清,你就不会混。
二十、做一个更贴近实际的小案例
假设你有一批商品信息,想按价格排序。
products = [ {'name': '键盘', 'price': 199}, {'name': '鼠标', 'price': 99}, {'name': '显示器', 'price': 1299}]products.sort(key=lambda x: x['price'])print(products)
输出结果会按价格升序排列。
这段代码特别像真实业务代码。 而且你会发现,lambda 在这里的存在感非常自然:
只是临时告诉排序函数,拿商品价格作为排序依据。
这就是它最舒服的用法。
二十一、本章小练习
你可以做三个特别适合巩固的练习。
练习 1 写一个 lambda,把传入的数字乘以 3。
练习 2 给下面的列表按字符串长度排序:
words = ['python', 'go', 'banana', 'cat']
练习 3 给下面的学生数据按成绩从高到低排序:
students = [ ('张三', 95), ('李四', 88), ('王五', 91)]
参考答案:
triple = lambda x: x * 3print(triple(4))words = ['python', 'go', 'banana', 'cat']words.sort(key=lambda x: len(x))print(words)students = [ ('张三', 95), ('李四', 88), ('王五', 91)]students.sort(key=lambda x: x[1], reverse=True)print(students)
只要你把这三个练习亲手写一遍,这一章的主干就会非常清楚。
二十二、本章总结
这一章最重要的,不是把 lambda 神秘化,而是给它一个准确的位置。
lambda 表达式本质上是一种快速生成匿名函数的方式。 它的基础结构是:
lambda 参数: 表达式
它适合短逻辑、临时使用、一次性的小函数场景。 最常见的使用位置,是排序的 key 参数,以及后面会讲到的 map()、filter() 这类函数。 它不是为了替代普通函数,更不是越用越高级。 真正成熟的判断标准只有一个:写出来的代码是不是更清楚。
下一章我们继续往前走,进入 lambda 最常见的搭档:094|map、filter、reduce:函数式编程入门。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
