服务器变慢了,你的第一反应是看 CPU、内存、磁盘 IO——top、htop、iotop 都能帮你。但如果你想知道哪个 HTTP 接口在被狂刷,工具链突然就断了。
现有的方案绕不开加东西。要么挂 Sidecar 采集指标,要么在代码里加埋点,要么配 Prometheus + Grafana。临时排查时,这些前置工作比问题本身还费时间。
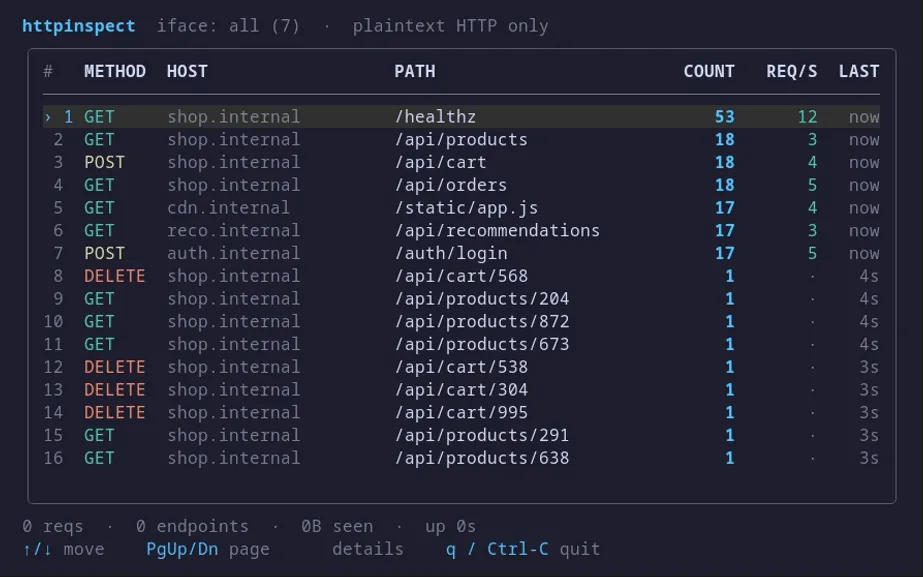
yeet-src/httpinspect 不绕弯:不需要代理,不需要改代码。把 eBPF 程序挂到内核 TC 层,直接读网卡上的 HTTP 明文请求,在终端画一个实时排行——哪个 METHOD + Host + Path 组合请求量最高、速率多少、上次访问是几秒前,和 top 一样实时刷新。
一行命令,零侵入
启动就是 yeet run .。eBPF 自动枚举所有 up 网卡接口,包括 loopback。本地服务之间的 HTTP 调用也在监视范围。
终端表格每行一个端点,按请求总数降序。方向键移动光标,回车进详情页,能看到 p50/p95/max 延迟、状态码分布、请求速率和延迟的微型趋势图。
延迟计算有意思。它不是应用层打点,而是把同一个 TCP 流上的请求段和响应段配对,取内核时间戳差值作为线上延迟——包含网络 RTT,但避免了时钟漂移和埋点开销。
eBPF 在底层抓包,不拦截
两层架构。内核层两个 TC 挂载点,ingress 抓入站 TCP 段,egress 抓出站段。BPF 在 kernel 里做极轻量检查——看 payload 前几个字节是不是 HTTP 方法名。匹配时才通过 ring buffer 推到用户空间。
ACK、非 HTTP 流量、TLS 握手在 BPF 层就被丢弃了。不拦截、不持有、不修改任何包。
用户空间是 yeet 运行时上的 JS TUI,订阅 ring buffer 事件,解析请求行和 Host 头,配对响应获取状态码和延迟,然后渲染。
明文 HTTP 才可见。HTTPS 在这一层是密文,读不到请求行。这不是 bug,是 TC 层的物理边界。
适合什么场景
线上服务突然变慢时想知道哪个接口在扛压——上去就跑,零配置。
审计一台机器上跑了哪些明文 HTTP 流量、去往哪些 Host。本地多个微服务互调但不知道调了什么,开 lo 接口看一眼。
怀疑某个客户端在重试风暴,盯着一个路径的 REQ/S 看它有没有飙升。
项目基于 yeet 框架,用 JS 写 eBPF 程序,2026 年 6 月 17 日创建,一周近 200 Star。需要 Linux 6.6+ 内核和 BTF 支持。只有明文 HTTP 可见。
如果你有 Linux 服务器偶尔需要看一眼 HTTP 流量,五秒就跑起来。它不替代 Prometheus,但在你不知道该看什么的时候,先告诉你流量往哪去了。
项目地址:https://github.com/yeet-src/httpinspect
官网地址:https://yeet.cx
参考链接:
[1] https://yeet.cx/docs
[2] https://github.com/yeet-src/httpinspect#readme
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
