组调度:容器时代的公平保障
Linux 调度子系统技术文档系列 · 第 12 篇
一、从一个不公平的场景说起
假设一台 32 核的 Kubernetes 节点上跑了两个 Pod:
- Pod A 是一个高并发的 Web 服务,里面启动了 100 个 worker 线程;
- Pod B 是一个后台定时任务,只有 2 个线程。
两个 Pod 都设置了相同的 cpu=16 limit,理应各占 50% 的 CPU。然而打开 top 一看——Pod A 吃掉了 80% 的 CPU,Pod B 只拿到了不到 20%。
问题出在哪里?
Linux CFS 调度器默认的公平单位是线程。CFS 红黑树里排队的每一个实体(sched_entity)权重相同,pick_next_entity 就选 vruntime 最小的那个。100 个线程 vs 2 个线程,Pod A 在红黑树里天然占据 100 个席位,每次调度都有更高的概率被选中。线程级公平,不等于组级公平。
这就像一个班级按"人头"分蛋糕:人多的组拿到的总量自然多。而容器场景需要的是"按组"分——不管组里有多少线程,组与组之间按权重分配。
这就是组调度(Group Scheduling)要解决的核心问题。它让 CFS 不再只看单个线程,而是沿着 cgroup 层级树做逐级公平。
二、组调度核心数据结构是什么?
启用 CONFIG_FAIR_GROUP_SCHED 后,内核引入了一组嵌套结构。我们逐一拆解。
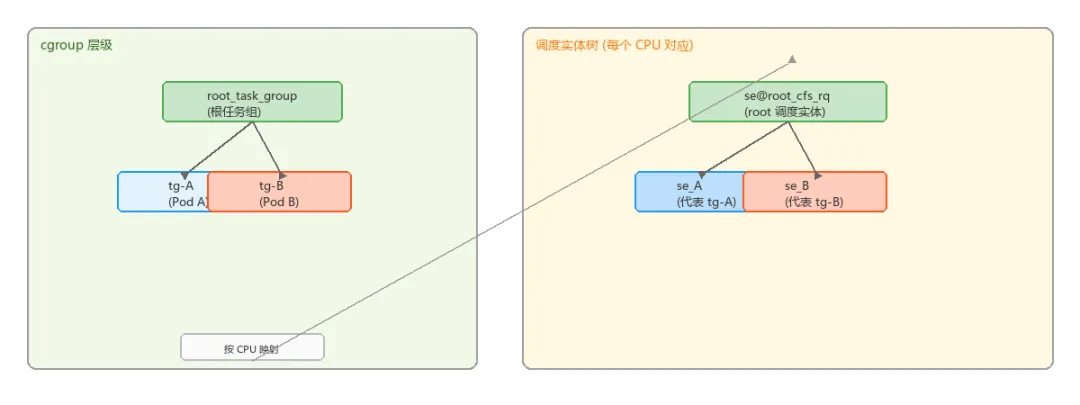
2.1 task_group:cgroup 在调度子系统的化身
关键设计点:
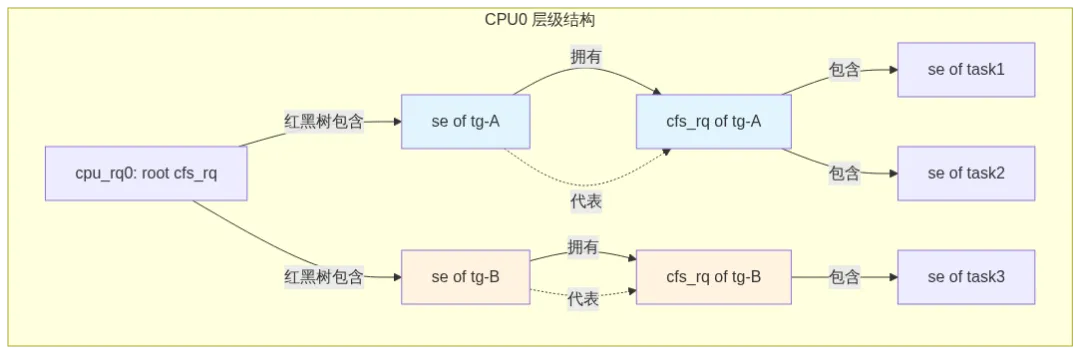
se[] 和 cfs_rq[] 都是每 CPU 的指针数组。组 A 在 CPU 0 上有一个 sched_entity 代表它参与父级竞争,同时有一个 cfs_rq 来容纳自己的子实体。parent / siblings / children 构成一棵树,根是 root_task_group。每个 cgroup 创建一个 task_group 节点。shares 对应 cgroup v2 cpu.weight,默认 1024,范围 [1, 10000]。
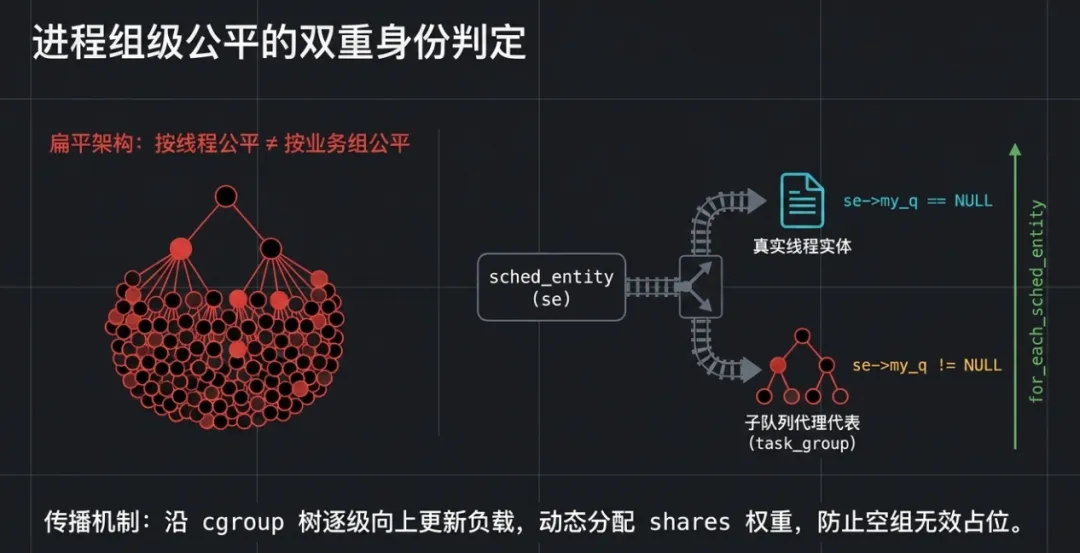
2.2 sched_entity 的双重角色
struct sched_entity 是 CFS 的原子调度单位。在组调度中,它同时扮演两种角色:
这里的判别逻辑是 se->my_q:
my_q | | |
|---|
| | 代表一个真实的 task_struct,只参与一次调度 |
| | "拥有" 一个子 cfs_rq,是父组队列中的代理 |
为什么这样设计?
如果为组调度单独引入一种新结构,调度器的主循环 pick_next_entity 就要写两套逻辑。内核的做法是让 sched_entity 自身"升级"——当 my_q 指向子队列时,它就自动变成组代表。调度器主路径完全不用感知差异。这就是 Linux 内核的经典设计哲学:用同一套机制,通过指针关系区分角色。
2.3 cfs_rq 的层级嵌套
每个 task_group 在每个 CPU 上都有一个 cfs_rq。叶子 cfs_rq(tg 是最底层 cgroup)里面放的是普通任务的 sched_entity;非叶子 cfs_rq 里面放的是子组的 sched_entity 代表。
2.4 层级关系全景图
三、进程入队的层级传播路径
当一个任务被唤醒并加入运行队列时,组调度做了什么?让我们沿着代码路径追踪。
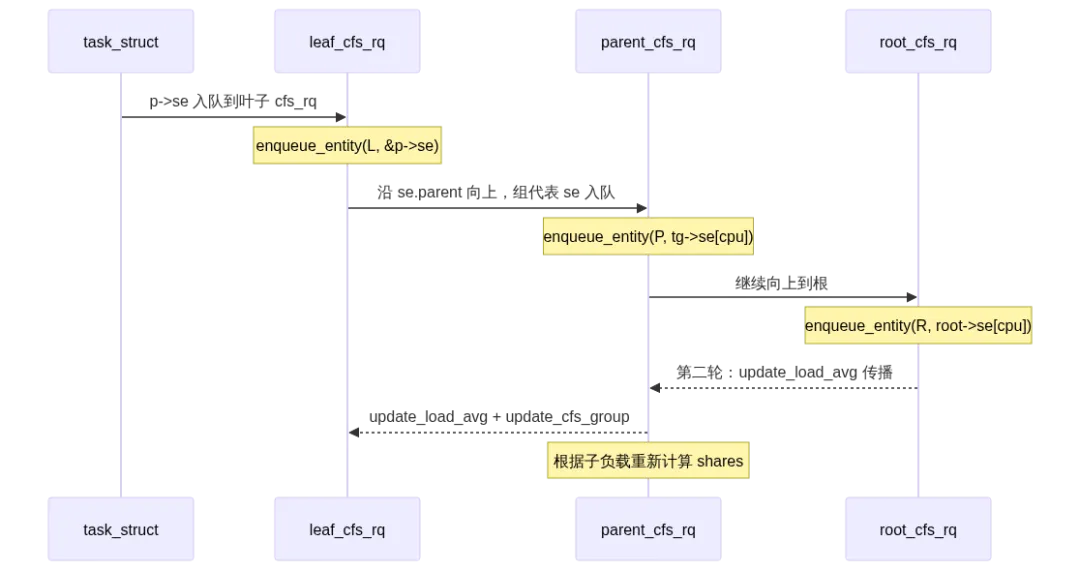
3.1 enqueue_task_fair:沿树向上传播
宏 for_each_sched_entity 在组调度开启时的定义:
这个 for 循环的迭代路径是:
task->se→se.parent(tg-A的组代表) →se.parent(root的组代表) →NULL
每迭代一次,就把当前层级的 sched_entity 加入其父级 cfs_rq 的红黑树。如果父组已经在队列中(se->on_rq 为真),就可以提前退出——这是常见的快速路径优化。
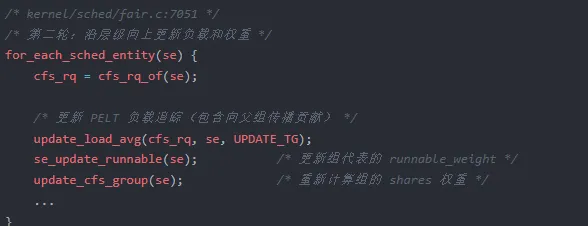
3.2 第二轮:负载更新与权重重新计算
这里做了三件关键事:
update_load_avg:PELT(Per-Entity Load Tracking)算法更新当前 se 的负载平均值,并通过 UPDATE_TG 标记把负载贡献传播到父组。se_update_runnable:更新组代表的 runnable_weight,使其等于子 cfs_rq 中 h_nr_runnable 的值。update_cfs_group
3.3 update_cfs_group:动态权重再分配
calc_group_shares 的逻辑核心是:一个组的实际权重不能超过它子队列中所有任务权重的总和。如果一个 Pod 配了 cpu.weight=2048,但里面只跑了 1 个 nice 0 的任务(weight=1024),那么这个组的实际权重就是 1024 而不是 2048。
为什么这么做?防止"空组"占用过多份额。如果一个 cgroup 创建后没有任务,它的 shares 再大也不应该影响调度决策。
3.4 完整执行时序
四、为什么需要层级公平?
4.1 扁平公平的局限
在扁平模式下,所有线程在同一个红黑树中竞争。假设系统中有两个容器:
红黑树里有 102 个实体。每次 pick_next_entity 选 vruntime 最小的那个——100 个来自 A,2 个来自 B。虽然每个线程获得的 CPU 时间相等,但从组的维度看:
容器A获得:100/102≈98%CPU
容器B获得:2/102≈2%CPU
这显然不是多租户想要的结果。
4.2 层级公平的递归分配
组调度引入了层级公平的概念。调度器在根 cfs_rq 上比较的是组的代表实体,而不是单个线程:
- 根 cfs_rq 中,
se_A(代表容器 A)和 se_B(代表容器 B)按 shares 权重竞争; se_A 被选中后,调度器进入容器 A 的 cfs_rq,从它的 100 个线程中选一个;se_B 被选中后,调度器进入容器 B 的 cfs_rq,从它的 2 个线程中选一个。
如果 shares 相同(默认 1024),两个容器各得 50% CPU——与各自内部有多少线程无关。
这就像先按组分蛋糕,再由组内自行分配。
五、用户空间的映射关系
组调度在内核中的 task_group、shares、cfs_rq 层级,直接对应容器生态中的用户空间接口。
5.1 cgroup v2 接口
| | |
|---|
cpu.weight | task_group->shares | |
cpu.max | cfs_bandwidth | |
cpu.idle | task_group->idle | |
写入 cpu.weight 512,内核最终调用 sched_group_set_shares() 更新 task_group->shares,进而在下一次 update_cfs_group 时重新计算组实体的调度权重。
5.2 Kubernetes CPU 限制
Kubernetes 的 resources.limits.cpu 最终翻译为 cgroup v1 的 cpu.cfs_quota_us 和 cpu.cfs_period_us,对应内核的 cfs_bandwidth 结构:
limits → CFS 带宽限制:在 period 窗口内最多使用 quota 微秒的 CPU。组内所有任务共享这个配额,用完后整个组被 throttle。requests
5.3 多租户隔离
在公有云场景中,组调度是 CPU 隔离的基础:
- 每个租户的 VM 或容器对应一个独立的 cgroup,有自己的
task_group; - 租户 A 的线程数暴增不会影响租户 B 的 CPU 配额,因为调度器在根层级比较的是组代表,而不是线程;
- 如果租户 A 超出
cpu.max 限制,整个组被节流(throttle),不会"泄漏"到租户 B 的时间片。
六、架构要点总结
| |
|---|
| 公平单位的转变 | 从"每个线程公平"升级为"每个组公平,组内再公平" |
| 双重身份 | sched_entity 通过 my_q 区分普通任务和组代表,一套机制两种角色 |
| 层级传播 | for_each_sched_entity |
| 动态权重 | update_cfs_group 根据子队列实际负载调整组 shares,防止空组占份额 |
| 叶子链表 | leaf_cfs_rq_list 将所有叶子 cfs_rq 串成链表,供负载均衡遍历 |
| 带宽限制 | cfs_bandwidth 独立于 shares,提供硬性上限(Kubernetes limits) |
七、思考
组调度解决了一个关键问题:进程级公平不等于组级公平。但它也引入了新的复杂性——层级传播意味着每次任务入队、出队、唤醒都要遍历整棵树,cgroup 层级越深开销越大。
这里留两个问题供大家思考:
如果一个 cgroup 层级有 5 层深,任务唤醒时需要遍历 5 级 for_each_sched_entity 循环。这种开销在实际生产中可以接受吗?内核做了哪些优化?
当组内只有一个线程时,update_cfs_group 会把组 shares 限制为该线程的权重(1024)。但如果管理员设置了 cpu.weight=2048,这个配置是否"浪费"了?在什么场景下这种设计会带来意想不到的效果?
欢迎在评论区讨论你的答案,或者分享你在 Kubernetes 节点上遇到的 CPU 分配"诡异"现象。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
