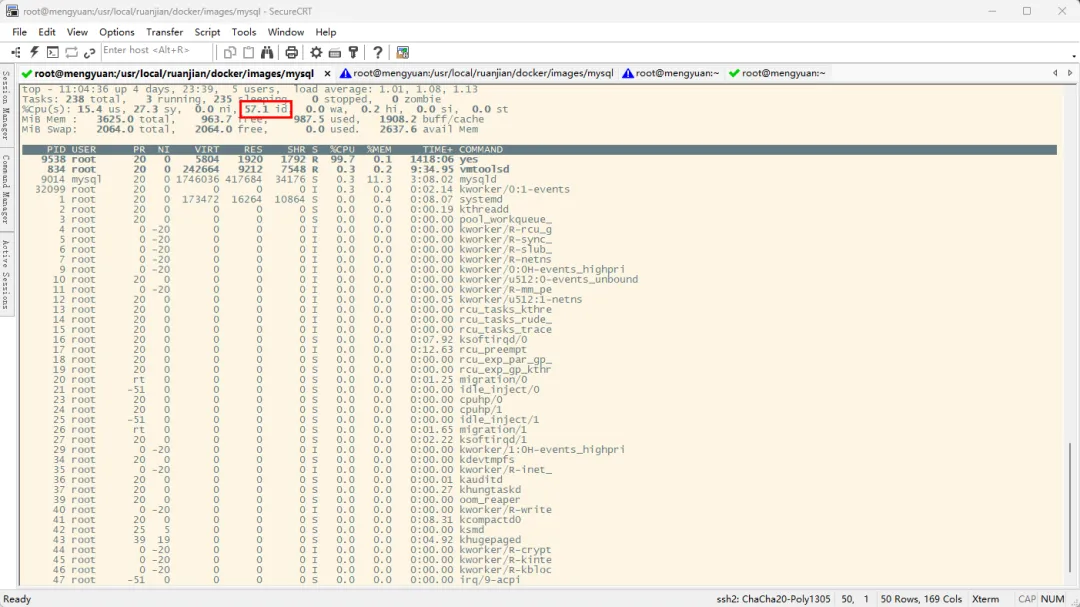
在使用 Linux 作为应用服务器时,遇到以下场景时,查看系统的 CPU 资源是否耗尽是一个必要的运营排查操作:应用响应变慢、实时监控告警、识别恶意进程等那么如何查询呢?我总结了以下三种方式,这三种方式所使用到的命令均是系统自带,无需联网安装工具,对于网络安全严格的环境的很实用小提示:前两种方式我仅讲解如何使用命令,第三种方式是根据前两种方式的底层原理、自己编写脚本文件来计算。各种方式的优缺点与应用场景要注意
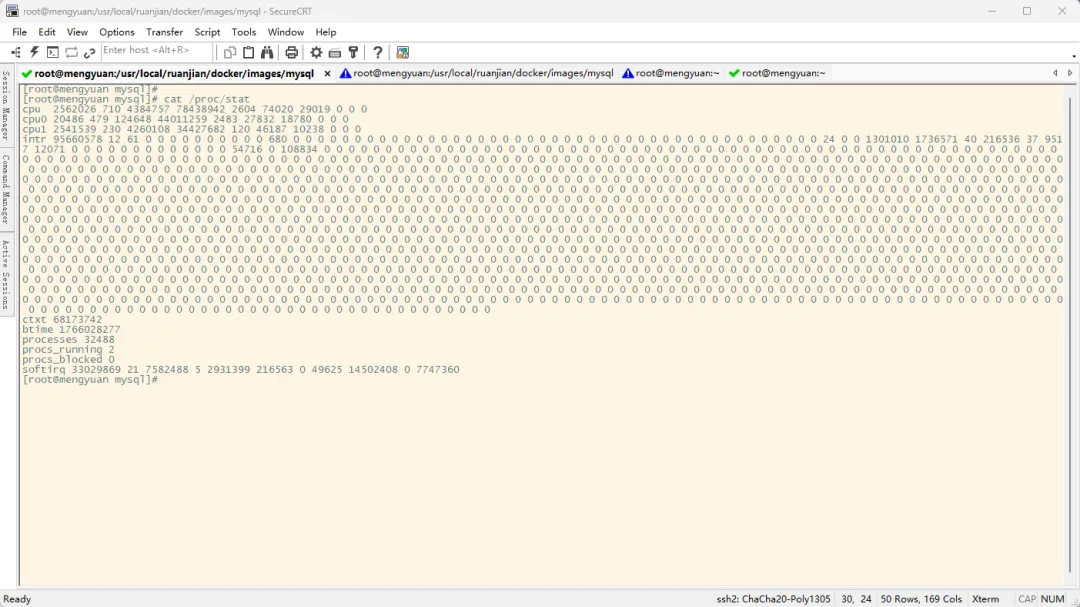
使用 top 命令查看系统的 CPU 资源、内存资源、负载状态、进程 CPU 使用率、进程内存使用率等,这种方式想必大家都烂熟于心了在默认情况下,top 命令的执行结果每 3 秒更新一次,以 CPU 使用率为例,也就是计算出 3 秒时间段的 CPU 平均使用率。那么如何缩短为计算 1 秒的时间段的 CPU 平均使用率呢?top 命令的执行结果中的 CPU 使用率是否准确呢?## 夹杂的信息很多,有系统总CPU信息、系统总内存信息、各个进程信息## 默认情况下每3秒钟刷新一次## 仅展示CPU空闲百分比使用率,如图中是红框中的数据,需要使用100减去这个值才能得到CPU已使用率top
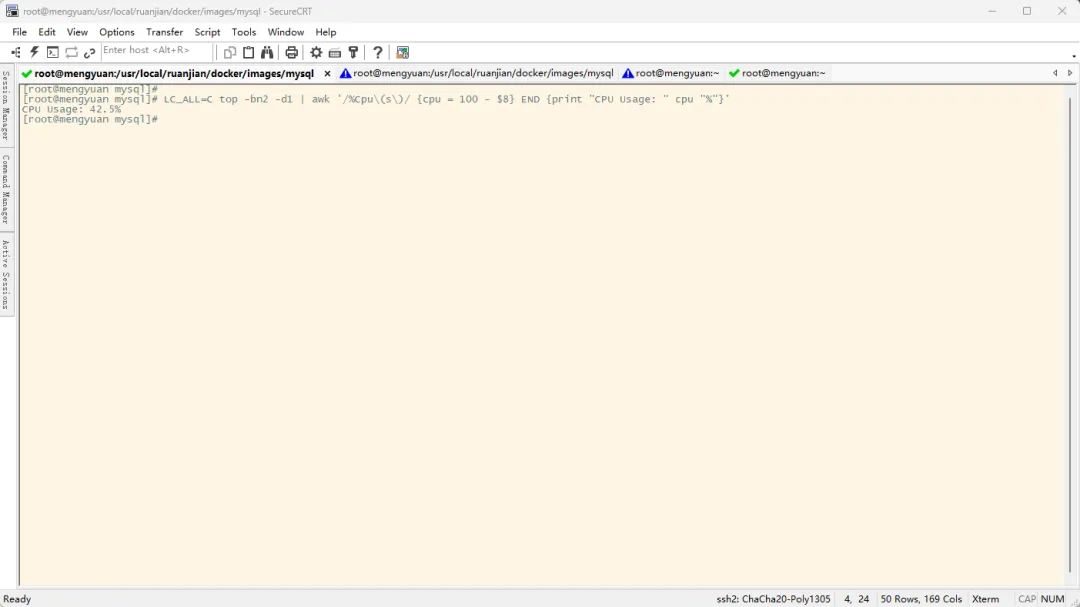
## 参数解析## LC_ALL=C:强制使用C语言环境,确保程序输出的格式是英文且可预测## top:命令## -b:top命令的参数,表示非交互式## -n2:top命令的参数,表示执行2次采样输出结果后退出## -d1:top命令的参数,表示采样之间的间隔时间,单位为秒## awk '/%Cpu\(s\)/ {cpu = 100 - $8} END {print "CPU Usage: " cpu "%"}'## awk:系统自带的一个强大的文本处理工具,专门用于按行分析、提取和处理结构化文本数据## 命令格式:awk '模式 {动作}'## 模式:对哪些行执行操作,可省略## 动作:对匹配行做什么## 命令结果:对匹配行将以空格进行分割,以格式 $num 可以获取到每一个分割部分,num从1开始## /%Cpu\(s\)/:匹配以 %Cpu(s) 开头的行## {cpu = 100 - $8}:使用100减去匹配行的第8个部分的数值,将结果赋值给变量cpu## END {print "CPU Usage: " cpu "%"}':在动作全部执行完毕后,打印变量cpu的值LC_ALL=C top -bn2 -d1 | awk '/%Cpu\(s\)/ {cpu = 100 - $8} END {print "CPU Usage: " cpu "%"}'
- top 命令会采集 CPU 资源信息、内存资源信息、进程信息等大量信息,底层需要读取的文件多、还需要维护状态,属于重量级操作,在初始化时会占用大量 CPU 资源
- top 命令对系统 CPU 使用率的第一次采样数据是不准确的:top 命令在获取系统 CPU 使用率时,底层是通过读取 /proc/stat 文件内容来计算的。但是这个文件是系统自身维护的,记录的是系统自启动以来的 CPU 信息,所以必须采样两次,计算出这个间隔时间内的 CPU 平均使用率。这就是为什么我加工后的 top 命令中有参数 -n2 -d1 的原因,意思就是采样两次、间隔一秒、计算这一秒内的 CPU 平均使用率
由于 top 命令会采集大量信息,属于重量级操作,在初始化时会占用大量 CPU。这种特性对应用服务产生影响相对较大,不适于进行实时监控、日志采集等的高频场景,但是现场排查问题还是很适合的,毕竟操作非常简单、获取到的信息量又大
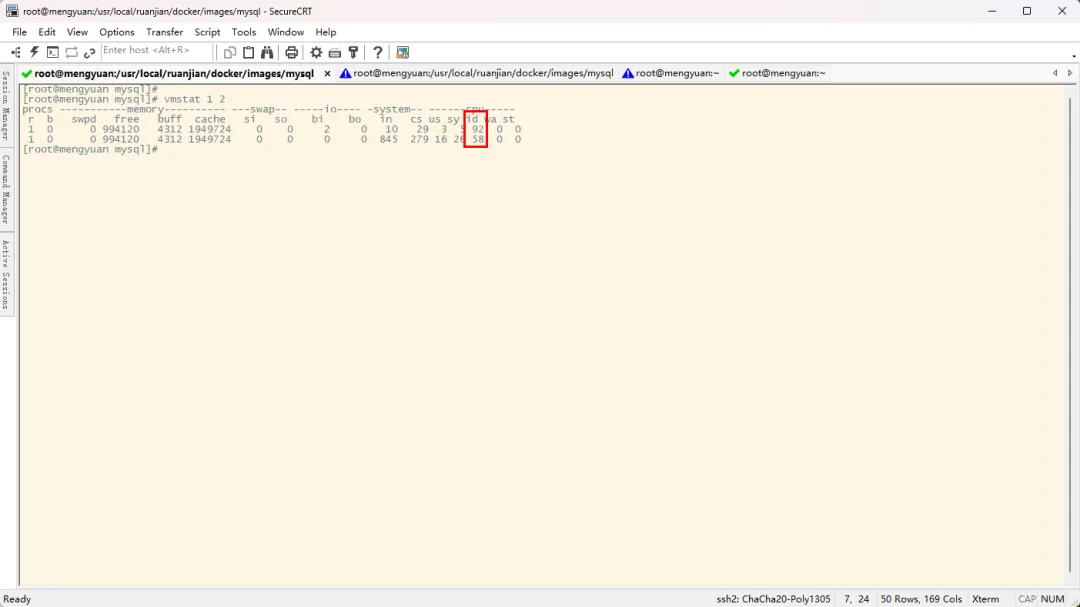
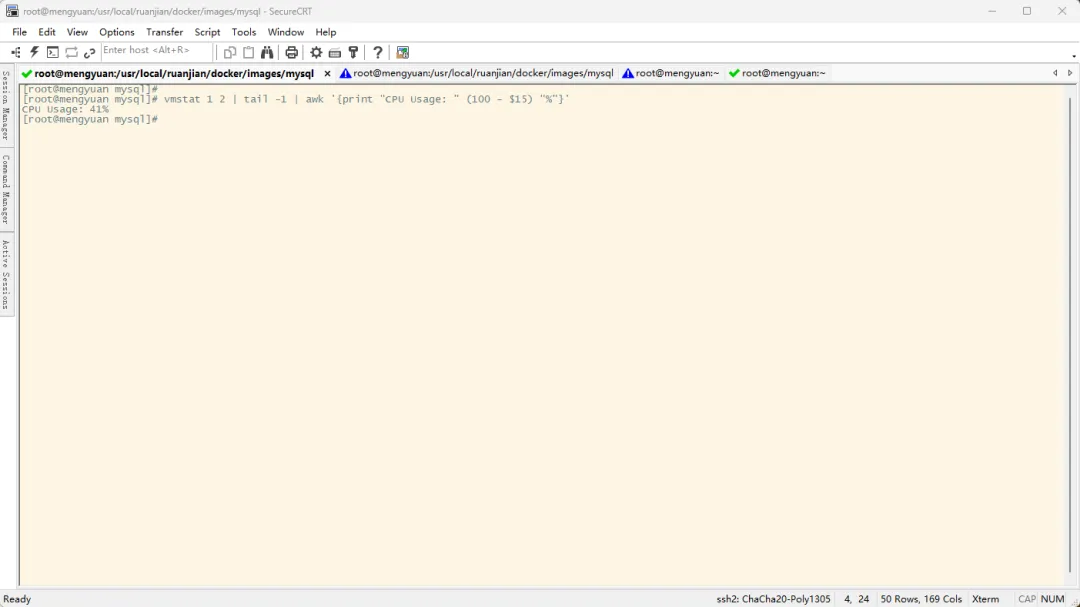
vmstat 命令是系统自带的一个轻量级、高效的命令行工具,用于报告虚拟内存、进程、CPU、I/O、系统活动的统计信息,常用于系统性能监控与故障排查## 采集2次数据,每次采集间隔1秒钟## 为什么采集2次数据:第一次获取到的是系统启动以来的平均值,第二次获取到的才是这一秒钟内的平均值## 仅展示CPU空闲百分比使用率,如图中是红框中的数据,需要使用100减去这个值才能得到CPU已使用率vmstat 1 2
## 参数解析## vmstat 1 2:采样2次,每次采样间隔1秒## tail -1:获取最后一行## awk '{print "CPU Usage: " (100 - $15) "%"}'## awk:系统自带的一个强大的文本处理工具,专门用于按行分析、提取和处理结构化文本数据## 命令格式:awk '模式 {动作}'## 模式:对哪些行执行操作,可省略## 动作:对匹配行做什么## 命令结果:对匹配行将以空格进行分割,以格式 $num 可以获取到每一个分割部分,num从1开始## '{print "CPU Usage: " (100 - $15) "%"}':使用100减去匹配行的第15个部分的数值,将结果进行打印vmstat 1 2 | tail -1 | awk '{print "CPU Usage: " (100 - $15) "%"}'
vmstat 命令属于轻量级命令,在初始化时不会占用大量 CPU现场排查问题、实时监控、日志采集等场景,都是合适的,推荐使用
前面讲了 top 命令、vmstat 命令,也提到了它们的原理是一样的,都是通过获取 /proc/stat 文件内容来计算 CPU 使用率的,那么 /proc/stat 文件到底是什么呢?/proc/stat 文件是 Linux 系统中的一个虚拟文件,它提供了系统自启动以来的底层 CPU、中断、上下文切换、进程创建等全局统计信息。这些数据由内核实时维护,是许多性能监控工具(如 top、vmstat、htop、iostat 等)计算 CPU 使用率和其他指标的基础。另外,所有用户都对这个文件有可读权限哦- 如图,通常来说,第一行,也就是以 cpu 开头的这一行,代表的是所有 CPU 核、超线程的累积值,计算 CPU 使用率也是以这一行为准
- 从第二行开始,以 cpu 和数字开头的行,代表的是系统的 CPU 是多少核的、或者几核几线程的。图中有 cpu0、cpu1,代表系统的 CPU 是 2 核或 1 核 2 线程的
- 接下来解释一下这些 CPU 信息行的每一个数字的意思,这些数字格式是固定的,以空格隔开,从前往后每一个数字的意思分别如下
- user:不含 nice 进程的用户态 CPU 时间
- guest:运行虚拟客户机的不含 nice 进程的用户态时间
- guest_nice:运行虚拟客户机的低优先级用户态时间
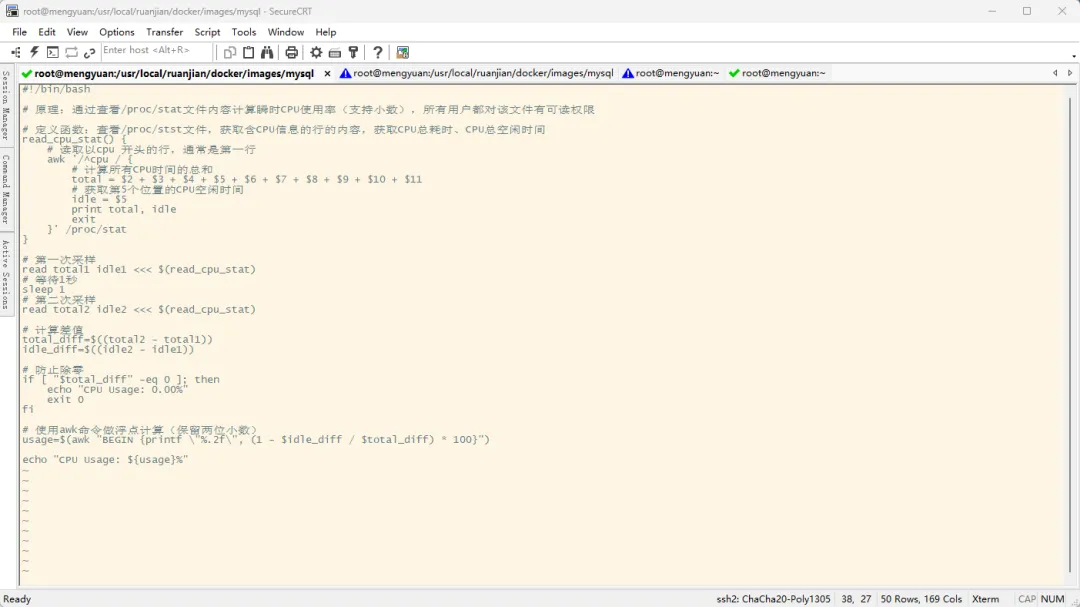
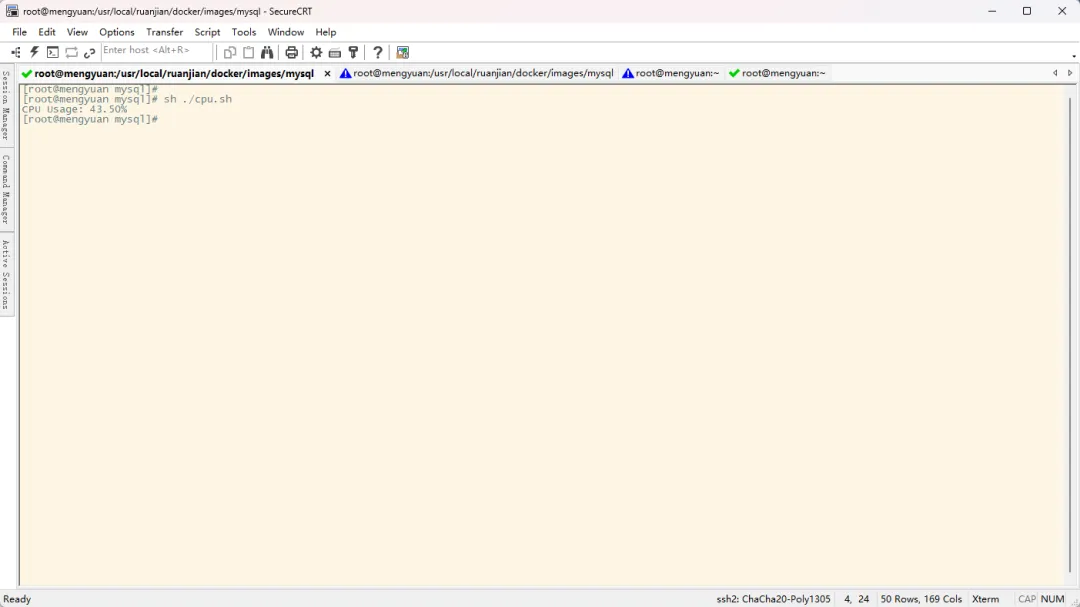
#!/bin/bash# 原理:通过查看/proc/stat文件内容计算瞬时CPU使用率(支持小数),所有用户都对该文件有可读权限# 定义函数:查看/proc/stst文件,获取含CPU信息的行的内容,获取CPU总耗时、CPU总空闲时间read_cpu_stat() { # 读取以cpu 开头的行,通常是第一行 awk '/^cpu / { # 计算所有CPU时间的总和 total = $2 + $3 + $4 + $5 + $6 + $7 + $8 + $9 + $10 + $11 # 获取第5个位置的CPU空闲时间 idle = $5 print total, idle exit }' /proc/stat}# 第一次采样read total1 idle1 <<< $(read_cpu_stat)# 等待1秒sleep 1# 第二次采样read total2 idle2 <<< $(read_cpu_stat)# 计算差值total_diff=$((total2 - total1))idle_diff=$((idle2 - idle1))# 防止除零if [ "$total_diff" -eq 0 ]; then echo "CPU Usage: 0.00%" exit 0fi# 使用awk命令做浮点计算(保留两位小数)usage=$(awk "BEGIN {printf \"%.2f\", (1 - $idle_diff / $total_diff) * 100}")echo "CPU Usage: ${usage}%"
直接从底层文件入手来计算 CPU 使用率,性能高、资源占用少、最灵活现场问题排查使用此种方式不合适、耗时太久,但是非常适用于实时监控、日志采集等高频场景
现场排查问题,推荐使用 top 命令、vmstat 命令;高效、高频获取 CPU 使用率时,推荐使用 vmstat 命令、命令脚本
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
