调度器与中断:CPU 时间被谁切走了?
Linux 调度子系统技术文档系列 · 第 15 篇
生产环境中,服务器偶尔会陷入“假死”:SSH 敲一个命令要等三秒才有回显,网络监控显示 Ping 延迟从 1ms 飙升至 500ms,top 的 %si(软中断)或 %hi(硬中断)占用率居高不下。此时调度器明明在运转,进程却被饿死。CPU 的时间片到底被谁悄悄切走了?
中断是硬件与内核通信的唯一通道,调度器是内核分配 CPU 时间的法官。两者共享同一颗 CPU,却遵循完全不同的执行规则:中断要求“立即响应、绝不等待”,调度要求“公平轮换、随时可切”。理解它们如何在同一个内核栈上共存、如何划定边界、如何交接控制权,是打通调度器与中断子系统的最后一块拼图。
中断上下文 vs 进程上下文:调度器的“禁区”是什么?
内核通过 preempt_count 字段记录当前执行环境的嵌套深度。该字段的低 8 位表示抢占禁用计数,中间 8 位表示软中断禁用计数,高 8 位表示硬中断上下文嵌套层数。in_interrupt() 宏正是通过检查这些位,判断当前是否处于中断上下文。
硬中断上下文之所以被称为调度器的“禁区”,源于三个不可逾越的物理限制:
- 锁与原子性约束:硬中断处理期间通常持有自旋锁(
raw_spinlock),此时若调用 schedule() 发生进程切换,锁将无法释放,其他 CPU 或中断处理函数将陷入永久死锁。 - 栈空间限制:中断上下文运行在独立的 IRQ 栈(通常仅 1~2 页),深度极浅。调度器需要保存完整的寄存器现场、切换页表、操作
task_struct,栈溢出是必然结果。 - 无进程归属:中断发生时不隶属于任何
task_struct,没有用户态虚拟内存上下文,没有 mm_struct。调度器切换的目标是“进程”,而中断没有“自己”可供切走。
因此,内核严格规定:硬中断上下文禁止睡眠、禁止调用 schedule()、禁止访问用户空间。所有需要延迟或可能阻塞的工作,必须推迟到进程上下文或软中断上下文执行。
延迟执行的阶梯:软中断、Tasklet 与 Workqueue 有哪些?
既然硬中断不能调度,内核设计了三级延迟执行机制,将“紧急响应”与“繁重处理”解耦。这就像一个急诊分诊系统:硬中断只做止血包扎,软急诊负责批量检查,普通门诊处理复杂手术。
在源码 kernel/softirq.c 中,这三种机制的层级关系如下:
- Softirq(软中断):静态编译期注册,最多 10 个类型(
NET_RX、BLOCK、TIMER 等)。并发执行、无序列化保证、性能极高,但编写门槛苛刻,且绝对禁止睡眠。 - Tasklet:基于
TASKLET_SOFTIRQ 和 HI_SOFTIRQ 两个软中断实现的轻量包装器。同一 tasklet 在多 CPU 上串行执行,API 简单,适合网卡驱动、USB 子系统等中等频率场景。 - Workqueue(工作队列):完全运行在进程上下文,由内核线程池(
kworker)承载。可睡眠、可调用任意内核 API,灵活性最高,但调度延迟相对较大。
选择逻辑本质是性能、可睡眠性与开发成本的权衡:
- 需要阻塞等待、申请内存、与文件系统交互 →
workqueue - 实时性要求极高、需完全可抢占 →
irq_thread(中断线程化)
中断线程化:把硬中断“赶”进调度器的队列
传统硬中断最大的痛点是:处理期间必须关闭本地中断(local_irq_disable()),导致同级甚至高级中断被阻塞,系统最长不可抢占延迟可达数百微秒。为了解决这一问题,内核引入了 CONFIG_IRQ_FORCED_THREADING 与 CONFIG_PREEMPT_RT,将大部分中断处理逻辑“降级”为内核线程。
在 kernel/irq/manage.c 中,中断线程的主体循环如下:
线程化后,硬中断仅保留极简的“应答与唤醒”逻辑:关闭中断线、标记 pending、唤醒 irq_thread、开中断返回。真正的数据处理在 irq_thread 中以普通进程身份运行,可被更高优先级的实时任务抢占,彻底消除了长尾延迟。
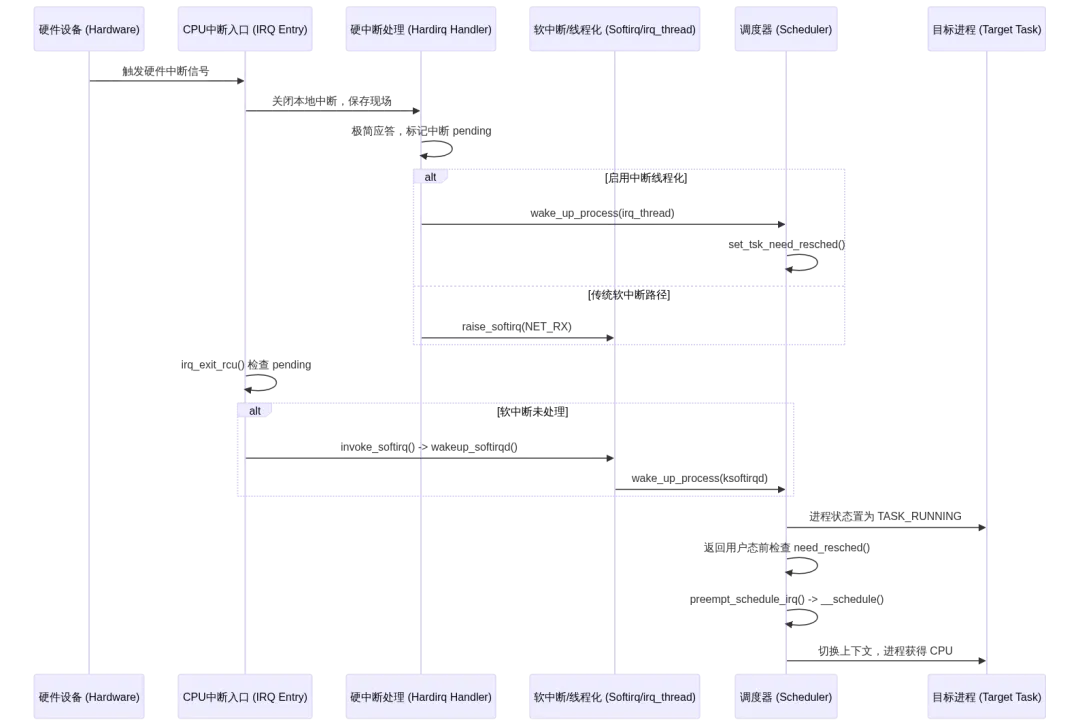
从中断唤醒到触发调度:完整的执行链路
中断与调度器的交接,发生在一个极其精密的状态机中。以下时序图展示了从硬件中断触发,到最终唤醒目标进程并触发调度的完整路径:
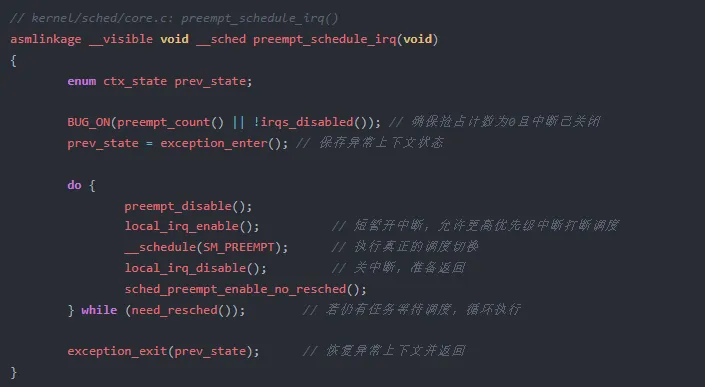
在 kernel/sched/core.c 中,中断返回内核态前的抢占入口是 preempt_schedule_irq():
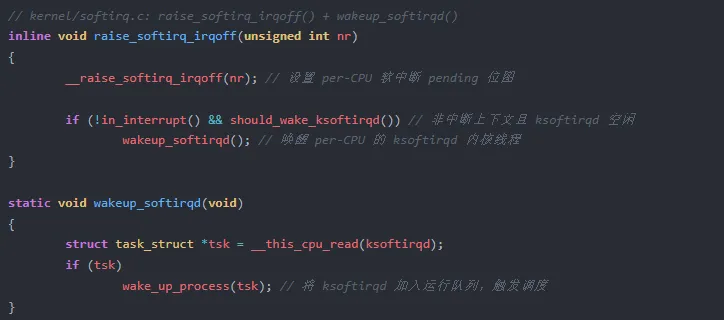
软中断的唤醒触发点位于 kernel/softirq.c:
wake_up_process() 内部调用 try_to_wake_up(),最终通过 set_tsk_need_resched() 在目标运行队列的当前任务上打下 TIF_NEED_RESCHED 标记。CPU 退出中断或系统调用时,检查该标记即进入 preempt_schedule_irq(),完成控制权交接。
用户空间的镜像:如何观测与调优?
内核的中断与调度交互并非黑盒,用户空间提供了完整的观测与干预接口。
/proc/interrupts:按 IRQ 号统计每个 CPU 的硬中断触发次数。若某行数值异常飙升,说明对应设备驱动可能陷入中断风暴。/proc/softirqs:统计各类软中断(NET_RX、TIMER、TASKLET 等)的处理次数。网络包处理延迟高时,NET_RX 计数通常与丢包率强相关。irqbalance 守护进程:动态读取 /proc/interrupts,根据各 CPU 负载与缓存拓扑,自动调整 /proc/irq/*/smp_affinity,将高频中断均匀分散到多核,避免单核软中断积压。- RT 系统的中断线程化:在实时内核中,可通过启动参数
threadirqs 强制开启 force_irqthreads()。配合 chrt -f -p 80 调整 irq/XX-xxx 线程的实时优先级,可实现确定性延迟。 - 网络 NAPI 与中断合并:现代网卡驱动默认启用 NAPI(New API),首次中断后关闭硬件中断,改用轮询(poll)批量收包。配合
ethtool -C 调整 interrupt coalescing(如 rx-usecs),用“延迟中断”换取吞吐量,是调度器与硬件协同的经典范例。
架构哲学与承上启下
中断与调度器的共存,体现了内核设计的核心哲学:即时响应与公平调度必须解耦,硬件的狂暴与进程的从容需要缓冲区。硬中断负责“止血”,软中断负责“转运”,工作队列与中断线程负责“手术”。每一层都严格限定栈深度、锁范围与可睡眠性,通过 preempt_count 状态机与 need_resched 标记无缝衔接。
调度器系列至此完结。我们走完了 CFS 的公平博弈、RT 的严格优先、EEVDF 的虚拟时钟、cgroup 的层级配额,最终在中断与调度的交界处看清了 CPU 时间的真实流向。
但中断本身,仍是一座更深的迷宫。irq_desc 如何描述一条中断线?irq_chip 抽象了怎样差异巨大的中断控制器?GICv3 与 IOAPIC 的路由机制如何影响多核扩展性?MSI/MSI-X 又如何绕过 PIC 直接投递到 LAPIC?
下一系列,我们将正式迈入中断子系统系列。从硬件信号到内核 handle_irq_event_percpu(),拆解每一微秒的延迟来源,看清 CPU 时间被切走的底层物理路径。
本系列文章基于 Linux 6.19.13 内核源码
采用 CC BY-NC-SA 4.0 协议,转载请注明出处


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
