《Pthon深度学习基于PyTorch(第2版)》—习题集
为帮助大家更好地学习和掌握《Python深度学习》一书的核心内容,我们特别编写了这本配套习题集,本习题集通过精选习题,帮助大家查漏补缺、夯实基础,将零散的知识点融会贯通;同时逐题解析答题思路,剖析常见误区,切实提升实战推理与问题解决能力。希望借助这份习题集,能够帮助大家更加从容地应对各类笔试、技术面试及资格认证考核。

习题1.:有一个形状为 (4,5) 的 Tensor,执行 tensor.sum(dim=0, keepdim=True)后,输出形状是多少?如果不设置 keepdim,又是多少?NumPy 中对应参数叫什么?
解题思路:归并操作维度控制。
详细步骤:
1.keepdim=True:沿 dim=0 求和【将压缩行,只剩列】,保留维度,输出形状 (1,5)。
2.keepdim=False(默认):输出形状 (5,)。
3.NumPy 中对应参数也叫 keepdims。
特殊情况:keepdim在广播操作中很有用,可以避免额外插入维度。
总结与拓展:在构建神经网络时,经常用 keepdim来保证张量维度一致,便于后续计算。
习题2:已知 w = torch.tensor([1.0, 2.0], requires_grad=True),b = torch.tensor(0.5, requires_grad=True),x = torch.tensor([3.0, 4.0]),y = w @ x + b,loss = (y - 10)**2。求 loss对 w和 b的梯度(手算)。
解题思路:

详细步骤:
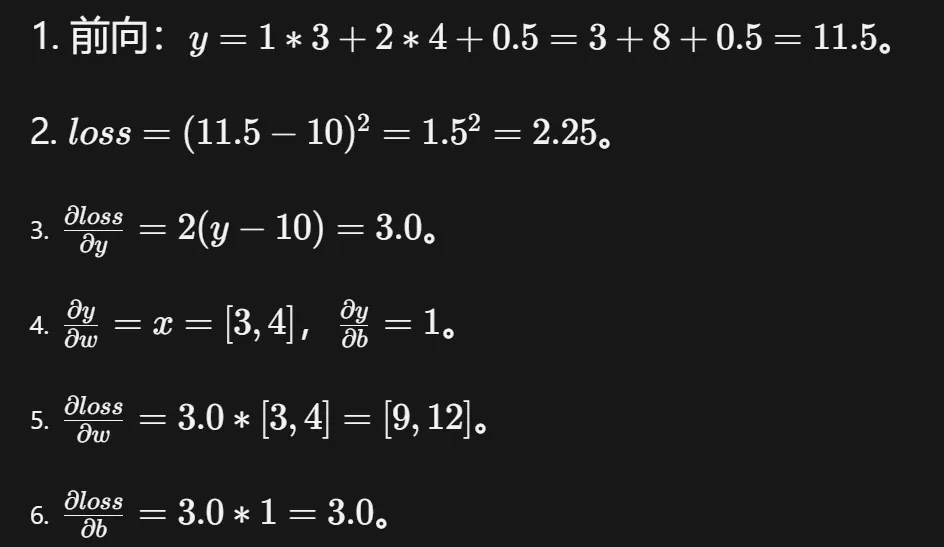
特殊情况:若 w和 b是向量,梯度形状与其一致。
总结与拓展:这是线性回归单样本的梯度计算,理解了它就能理解 SGD 的更新步骤。
以上手工步骤,如果用PyTorch如何实现?
import torch
# 定义输入数据 x(特征向量),这里固定为 [3.0, 4.0],不需要求导
x = torch.tensor([3.0, 4.0])
# 定义权重 w,初始化为 [1.0, 2.0],并开启 requires_grad=True 表示需要计算其梯度
w = torch.tensor([1.0, 2.0], requires_grad=True)
# 定义偏置 b,初始化为 0.5,同样需要计算梯度
b = torch.tensor(0.5, requires_grad=True)
# 前向传播:计算线性模型输出 y = x·w + b(即 3*1 + 4*2 + 0.5 = 11.5)
y = x @ w + b
# 定义损失函数:使用均方误差(MSE)风格,目标值为 10,计算平方误差
loss = (y - 10) ** 2
# 反向传播:自动计算 loss 对所有 requires_grad=True 的变量的梯度
loss.backward()
# 从 w.grad 和 b.grad 中提取计算出的梯度值
dw = w.grad# 损失对 w 的梯度,即 ∂loss/∂w
db = b.grad# 损失对 b 的梯度,即 ∂loss/∂b
# 打印梯度结果,便于调试和验证手动计算
print(dw)# 期望输出: tensor([9., 12.]),因为 ∂loss/∂w = 2*(y-10)*x
print(db)# 期望输出: tensor([3.]),因为 ∂loss/∂b = 2*(y-10)*1
习题3:索引与切片:NumPy 的高级索引(integer array indexing)返回的是副本还是视图?PyTorch 的 Tensor 索引返回的是什么?这对修改数据有何影响?
解题思路:内存共享行为。
详细步骤:

【说明】需要注意的是混合索引(如 arr[:2, [1,2]])的情况。在 NumPy 中,这种组合会退化为高级索引并返回副本;在 PyTorch 中行为也类似。
总结与拓展:
处理PyTorch张量时,可以遵循以下几条原则,就能有效规避视图与副本带来的风险:
1.当你需要一份数据副本,且其不参与梯度计算时: new_tensor = data_tensor.detach().clone() 是最稳妥、最推荐的组合。
2.当你需要改变张量的形状时: 优先使用tensor.reshape(),它能自动处理连续性问题,是应对绝大多数情况的安全选择。仅在确定张量连续、且追求极致性能时,才考虑使用view()。
3.当你需要展平张量时: 优先使用tensor.flatten(),它的行为最可预测,能确保返回一个连续的张量。
习题4:设备(Device)差异:假设有一台有 GPU 的机器,如何将 NumPy 数组 arr转换为 GPU 上的 Tensor?再将这个 GPU Tensor 转换回 NumPy 数组会遇到什么问题?如何解决?
解题思路:设备迁移与格式转换。
详细步骤:
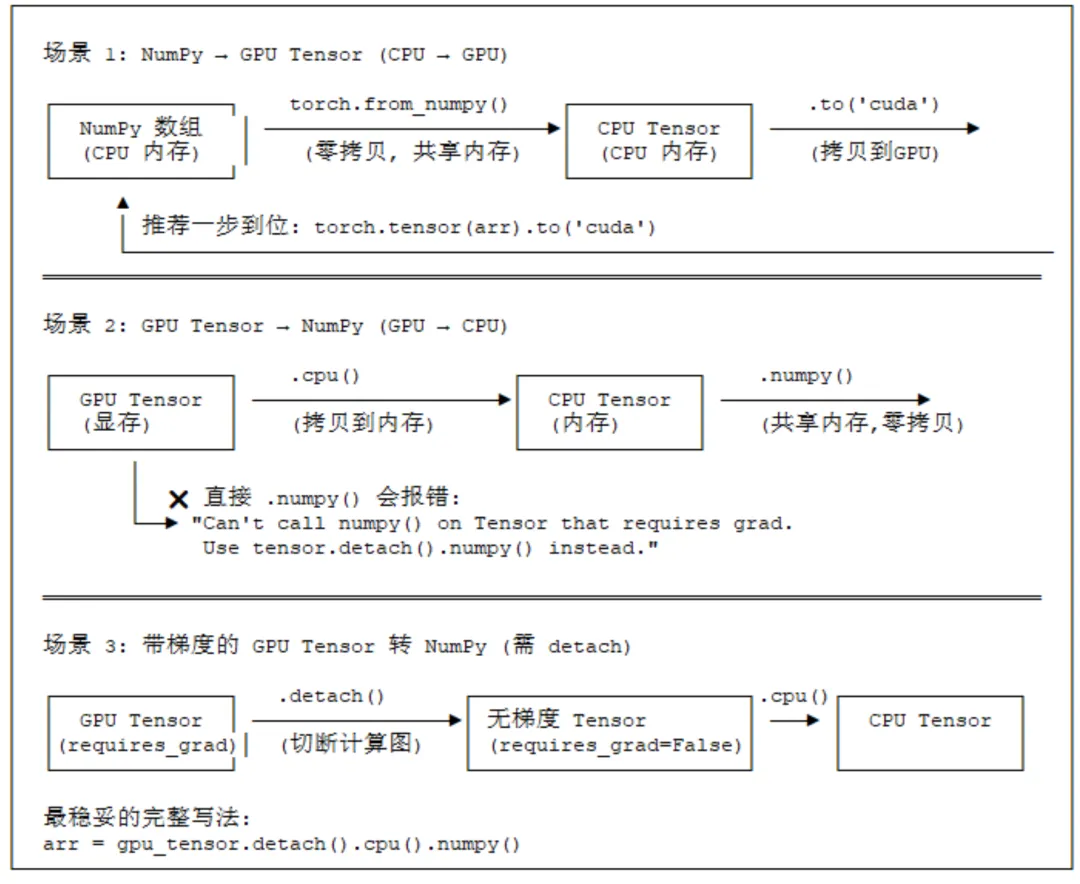
总结与拓展:在分布式训练中,设备转换是常见的性能瓶颈,应尽量减少。
习题5:在PyTorch中,detach()和with torch.no_grad():有何区别?
解题思路:
·detach()返回一个新Tensor,与旧Tensor共享数据,但requires_grad=False,且可与原图断开。
·no_grad()是上下文管理器,其内所有操作不追踪梯度,适用于推理。
·区别:detach()作用在单个Tensor,no_grad()作用于代码块。
习题6:torch.nn.Module中train()和eval()模式的作用是什么?
解题思路:
·train():启用Dropout、BatchNorm等训练层。
·eval():关闭这些层,用于推理。
·举例:BN在训练时使用batch统计量,推理时使用全局统计量。
习题7:在 PyTorch 2.0+ 中,view() 和 reshape() 对非连续内存的行为有何不同?请举例。
解题思路:
·view() 要求内存连续(is_contiguous()),否则报错。
·reshape() 不要求连续,内部会复制数据。
·举例
import torch
x = torch.randn(3,4).t()# 转置后不连续
x.view(4,3)# <2.0可能报错,>=2.0可以成功运行
x.reshape(4,3)# 成功
y=x.contiguous().view(-1) #展平,直接使用x.view(-1) 可能报错
print(y.shape)#展平后的维度为12
z=x.reshape(-1)#展平
·拓展:view() 比 reshape() 更高效(无复制),但需保证连续。
习题8:指出以下代码的优化器更新问题。
optimizer = optim.SGD([w], lr=0.01)
for i in range(10):
loss = (w * x - y).pow(2).sum()
#计算梯度
loss.backward()
#更新参数
optimizer.step()
问题:缺少 optimizer.zero_grad(),梯度会累积。修正:在 step() 前(或后)加 optimizer.zero_grad(),每次循环后梯度清零。
习题9:解释PyTorch中 requires_grad 的作用,以及 backward() 方法的工作原理。
解题思路:
requires_grad:
·标记张量是否需要计算梯度
·叶子节点设置为 True 时,PyTorch会跟踪其上的所有操作
·非叶子节点的 requires_grad 自动为 True(如果操作涉及需要梯度的张量)
backward() 工作原理:
1.从当前张量(标量)开始反向传播
2.利用链式法则计算每个叶子节点的梯度
3.梯度累积到 .grad 属性中
4.计算图在执行一次 backward() 后默认被释放(除非设置 retain_graph=True)
示例:
import torch
x = torch.tensor(2.0, requires_grad=True)
y = x ** 3
z = 2 * y + 1
z.backward()# 利用链式法则:dz/dx = dz/dy * dy/dx = 2 * 3x² = 6 * 4 = 24
print(x.grad)# 梯度累积到.grad属性中。24.0
习题10:解释PyTorch中optimizer.step()包括哪些功能?
解题思路:分析optimizer.step()的源码。
1.直观理解

2.参考源码
optimizer.step()的简单源码:
# torch.optim.SGD.step() 的简化实现
def step(self, closure=None):
withtorch.no_grad():# ← 关键!这里已经包裹了 no_grad,
forparam in self.param_groups[0]['params']:
ifparam.grad is not None:
#执行更新:param = param - lr * param.grad
param.add_(param.grad,alpha=-self.lr)
#add_ 是原地操作(in-place),不创建新张量
资料获取途径
视频连接:
抖音账号:
84911487035
B站主页:
https://space.bilibili.com/391424656
微信公众号【含电子文档及提示词等】:
大模型大智慧

