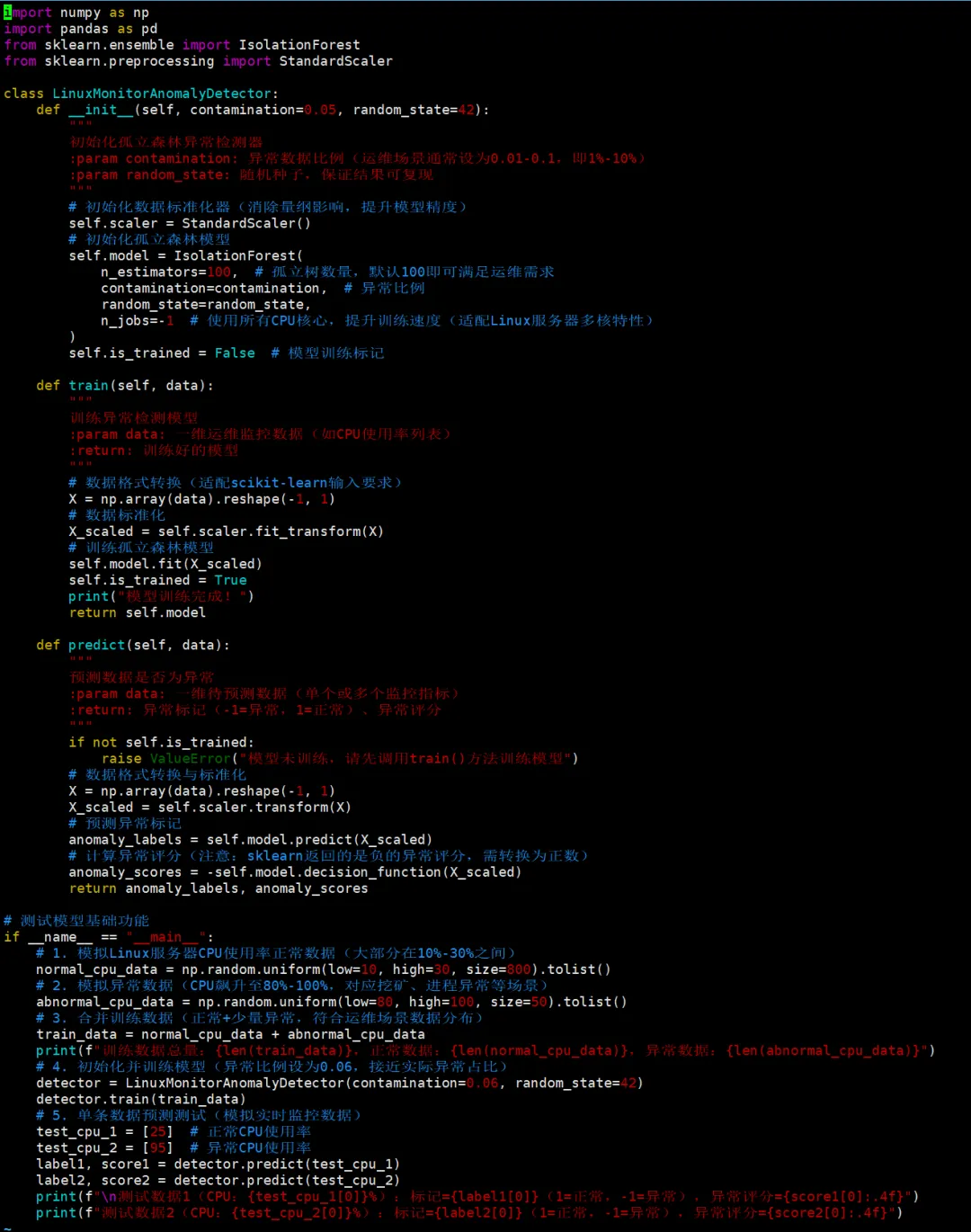
书接昨日!上回说到,AIOps的基础知识以及如何用psutil库采集Linux CPU、内存、磁盘I/O指标。今天接着往下说!先看下这个新名词:孤立森林(Isolation Forest),它是一种无监督异常检测算法(无需标注正常/异常样本,适配运维场景中异常样本稀缺的特点),其核心逻辑围绕异常数据的孤立难度远低于正常数据展开。数据分布特性:在运维监控数据中(如CPU使用率、内存占用),正常数据通常呈现聚集分布(大部分服务器CPU使用率在10%-30%之间),而异常数据(如CPU突然飙升至90%以上)是稀疏且离群的。孤立的本质:孤立森林通过随机选择特征(如CPU使用率)和随机选择分割阈值,对数据进行递归划分,形成多棵“孤立树”(iTree)。对于异常数据,由于其远离数据簇中心,通常只需要很少的划分步骤就能被单独分离出来;而正常数据需要更多的划分步骤才能被孤立。异常评分机制:算法通过计算每个数据样本在所有孤立树中的平均划分步数,生成异常评分(通常范围0-1)。评分越接近1,说明该样本越可能是异常;评分接近0.5时,数据分布较为均匀,难以区分正常与异常;评分接近0时,大概率是正常数据。运维场景适配性无需标注:运维中很难提前收集足够的异常样本,孤立森林无监督特性完美解决该问题。高效快速:处理服务器监控时序数据时,训练和预测速度快,支持实时监控。对离群值敏感:能精准捕捉CPU、内存、流量等指标的突增/突降异常(如挖矿程序、DDOS攻击前兆)。昨天我们已经搭建好了所需要的环境。scikit-learn 中内置了孤立森林模型,可以直接调用使用,并实现异常识别功能,可直接修改适配内存、磁盘IO等其他指标,牛X克拉屎!创建下面这个文件:import numpy as npimport pandas as pdfrom sklearn.ensemble import IsolationForestfrom sklearn.preprocessing import StandardScalerclass LinuxMonitorAnomalyDetector: def __init__(self, contamination=0.05, random_state=42): """ 初始化孤立森林异常检测器 :param contamination: 异常数据比例(运维场景通常设为0.01-0.1,即1%-10%) :param random_state: 随机种子,保证结果可复现 """ # 初始化数据标准化器(消除量纲影响,提升模型精度) self.scaler = StandardScaler() # 初始化孤立森林模型 self.model = IsolationForest( n_estimators=100, # 孤立树数量,默认100即可满足运维需求 contamination=contamination, # 异常比例 random_state=random_state, n_jobs=-1 # 使用所有CPU核心,提升训练速度(适配Linux服务器多核特性) ) self.is_trained = False # 模型训练标记 def train(self, data): """ 训练异常检测模型 :param data: 一维运维监控数据(如CPU使用率列表) :return: 训练好的模型 """ # 数据格式转换(适配scikit-learn输入要求) X = np.array(data).reshape(-1, 1) # 数据标准化 X_scaled = self.scaler.fit_transform(X) # 训练孤立森林模型 self.model.fit(X_scaled) self.is_trained = True print("模型训练完成!") return self.model def predict(self, data): """ 预测数据是否为异常 :param data: 一维待预测数据(单个或多个监控指标) :return: 异常标记(-1=异常,1=正常)、异常评分 """ if not self.is_trained: raise ValueError("模型未训练,请先调用train()方法训练模型") # 数据格式转换与标准化 X = np.array(data).reshape(-1, 1) X_scaled = self.scaler.transform(X) # 预测异常标记 anomaly_labels = self.model.predict(X_scaled) # 计算异常评分(注意:sklearn返回的是负的异常评分,需转换为正数) anomaly_scores = -self.model.decision_function(X_scaled) return anomaly_labels, anomaly_scores# 测试模型基础功能if __name__ == "__main__": # 1. 模拟Linux服务器CPU使用率正常数据(大部分在10%-30%之间) normal_cpu_data = np.random.uniform(low=10, high=30, size=800).tolist() # 2. 模拟异常数据(CPU飙升至80%-100%,对应挖矿、进程异常等场景) abnormal_cpu_data = np.random.uniform(low=80, high=100, size=50).tolist() # 3. 合并训练数据(正常+少量异常,符合运维场景数据分布) train_data = normal_cpu_data + abnormal_cpu_data print(f"训练数据总量:{len(train_data)},正常数据:{len(normal_cpu_data)},异常数据:{len(abnormal_cpu_data)}") # 4. 初始化并训练模型(异常比例设为0.06,接近实际异常占比) detector = LinuxMonitorAnomalyDetector(contamination=0.06, random_state=42) detector.train(train_data) # 5. 单条数据预测测试(模拟实时监控数据) test_cpu_1 = [25] # 正常CPU使用率 test_cpu_2 = [95] # 异常CPU使用率 label1, score1 = detector.predict(test_cpu_1) label2, score2 = detector.predict(test_cpu_2) print(f"\n测试数据1(CPU:{test_cpu_1[0]}%):标记={label1[0]}(1=正常,-1=异常),异常评分={score1[0]:.4f}") print(f"测试数据2(CPU:{test_cpu_2[0]}%):标记={label2[0]}(1=正常,-1=异常),异常评分={score2[0]:.4f}")
 类封装:将检测器封装为LinuxMonitorAnomalyDetector,方便后续复用和扩展(可添加内存、磁盘等多指标检测)。标准化处理:使用StandardScaler消除数据量纲影响,避免因指标范围差异导致模型精度下降。contamination:异常数据比例,运维场景建议设为0.01-0.1,可根据实际监控数据调整。n_jobs=-1:利用Linux服务器多核特性,提升训练和预测速度。decision_function:计算异常评分,sklearn返回负值,转换为正数后更易理解(值越大,异常概率越高)。下面模拟Linux服务器24小时CPU使用率实时监控场景,包含:
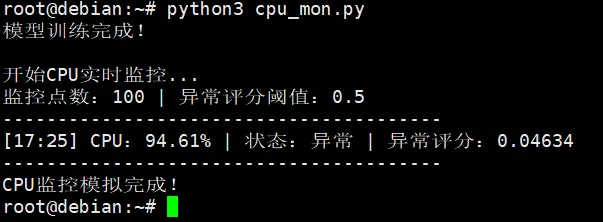
类封装:将检测器封装为LinuxMonitorAnomalyDetector,方便后续复用和扩展(可添加内存、磁盘等多指标检测)。标准化处理:使用StandardScaler消除数据量纲影响,避免因指标范围差异导致模型精度下降。contamination:异常数据比例,运维场景建议设为0.01-0.1,可根据实际监控数据调整。n_jobs=-1:利用Linux服务器多核特性,提升训练和预测速度。decision_function:计算异常评分,sklearn返回负值,转换为正数后更易理解(值越大,异常概率越高)。下面模拟Linux服务器24小时CPU使用率实时监控场景,包含:import numpy as npfrom sklearn.ensemble import IsolationForestfrom sklearn.preprocessing import StandardScalerimport timeclass LinuxCPUAnomalyDetector: def __init__(self, contamination=0.06, random_state=42): self.scaler = StandardScaler() self.model = IsolationForest( n_estimators=100, contamination=contamination, random_state=random_state, n_jobs=-1 ) self.is_trained = False def train(self, data): X = np.array(data).reshape(-1, 1) X_scaled = self.scaler.fit_transform(X) self.model.fit(X_scaled) self.is_trained = True print("模型训练完成!") def predict(self, data): if not self.is_trained: raise ValueError("模型未训练,请先调用train()方法") X = np.array(data).reshape(-1, 1) X_scaled = self.scaler.transform(X) labels = self.model.predict(X_scaled) scores = -self.model.decision_function(X_scaled) return labels[0] == -1, scores[0] # 直接返回是否异常+异常评分def simulate_cpu_monitor(): # 1. 准备训练数据并训练模型 normal_cpu = np.random.uniform(10, 30, 800).tolist() abnormal_cpu = np.random.uniform(80, 100, 50).tolist() train_data = normal_cpu + abnormal_cpu detector = LinuxCPUAnomalyDetector() detector.train(train_data) # 2. 简化模拟实时监控(缩减监控点数,保留核心逻辑) monitor_count = 100 # 简化监控次数,无需2880个点 alert_score = 0.5 anomaly_count = 0 print("\n开始CPU实时监控...") print(f"监控点数:{monitor_count} | 异常评分阈值:{alert_score}") print("-" * 40) for i in range(monitor_count): # 模拟监控时间 monitor_time = time.strftime("%H:%M", time.localtime(time.time() + i * 30)) # 前70个正常,后30个异常 current_cpu = np.random.uniform(10, 30) if i < 70 else np.random.uniform(80, 100) # 预测异常 is_anomaly, anomaly_score = detector.predict([current_cpu]) # 打印监控信息 status = "异常" if is_anomaly else "正常" print(f"[{monitor_time}] CPU:{current_cpu:.2f}% | 状态:{status} | 异常评分:{anomaly_score:.4f}", end="\r") time.sleep(0.01) # 简化告警计数逻辑(无邮件,仅标记连续异常) if is_anomaly and anomaly_score >= alert_score: anomaly_count += 1 if anomaly_count >= 3: print(f"\n【告警】[{monitor_time}] CPU异常飙升:{current_cpu:.2f}%") anomaly_count = 0 else: anomaly_count = 0 print("\n" + "-" * 40) print("CPU监控模拟完成!")if __name__ == "__main__": simulate_cpu_monitor()
 修改上面的脚本,增加服务器内存、磁盘等别的指标的实时监控,就可以快速发现进程异常、DDOS攻击前兆等问题,达到少背锅少加班的实际作用!要学习的东西其实还非常多,这里只是起个抛砖引玉的作用。每个公司的生产环境的情况又是千差万别,比如我实际工作中,就遇到过有台机器的内存长期95%在跑的,但一直也没问题,领导又舍不得出钱升配,都是本着能用就不动的原则,这个时候,监控要东西就要跟着变动了,不能一成不变。
修改上面的脚本,增加服务器内存、磁盘等别的指标的实时监控,就可以快速发现进程异常、DDOS攻击前兆等问题,达到少背锅少加班的实际作用!要学习的东西其实还非常多,这里只是起个抛砖引玉的作用。每个公司的生产环境的情况又是千差万别,比如我实际工作中,就遇到过有台机器的内存长期95%在跑的,但一直也没问题,领导又舍不得出钱升配,都是本着能用就不动的原则,这个时候,监控要东西就要跟着变动了,不能一成不变。


