提供Python/Origin定制化绘图服务,支持先出样图,满意后付款
本期文章将带您探索如何用Python绘制精美的堆叠条形图,是一种用于可视化多组数据的图形表示方法。
堆叠条形图是在普通条形图基础上,将每个条形按分类变量分割为多个子段,用以表示子类别数据,各段堆叠组成完整条形。其主要特点如下:
1.多层细分展示结构:可将每个总类拆分为多个子类,在同一柱条内分层堆叠,直观呈现各部分的数值及占总体的比例。
2.对比与趋势兼顾:既能横向对比不同总类之间的整体大小,也能观察各子类在同类或不同类间的构成差异,尤其适合呈现时间序列中成分的变化趋势。
3.强调累积与占比:通过堆叠形式突出部分对整体的贡献,易于识别主要成分及其在不同类别中的分布情况,同时展现总规模的变动。
1.导入库加载数据:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltcategory_names = ['A', 'B', 'C', 'D', 'E']# --- 读取 Excel 数据 ---try: file_path = 'data.xlsx' # 使用 openpyxl 引擎读取 Excel 文件,Sheet1 工作表,第一行为列名,第一列为索引 data = pd.read_excel(file_path, engine='openpyxl', sheet_name='Sheet1', header=0, index_col=0) # 将 DataFrame 转换为字典格式,便于后续处理 data_dict = data.to_dict(orient='dict') results = {} # 按列名重组数据,确保顺序与 category_names 一致 for col in data.columns: results[col] = [data_dict[col][row] for row in category_names]except Exception as e: # 如果读取文件失败,打印提示并使用预设的示例数据 print(f"数据源提示:{e}") results = { 'Q1': [10, 14, 18, 35, 24], 'Q2': [26, 22, 29, 10, 13], 'Q3': [35, 37, 7, 2, 19], 'Q4': [32, 11, 9, 15, 33], 'Q5': [21, 29, 5, 5, 40], 'Q6': [9, 19, 6, 30, 36] }
2.绘制堆叠条形图
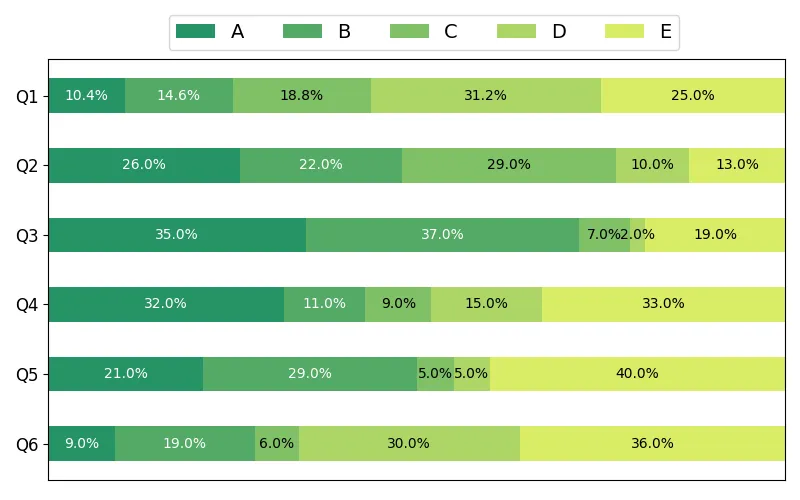
def survey(results, category_names): """ 生成堆叠条形图的函数 参数 ---------- results : dict 问题标签到各分类答案列表的映射 category_names : list of str 分类标签列表 """ # 获取所有问题标签(对应y轴标签) labels = list(results.keys()) # 将数据转换为numpy数组便于计算 data = np.array(list(results.values())) # 【修改点1】数据归一化处理,计算百分比 # 沿行方向求和(每个问题的回答总数) data_totals = data.sum(axis=1) # 计算每个分类的相对比例(0到1之间) data_rel = data / data_totals[:, np.newaxis] # 计算归一化数据的累积和(用于确定每个条块的起始位置) data_cum = data_rel.cumsum(axis=1) try: # 尝试使用新的colormaps API(Matplotlib 3.5+) # PiYG: 粉红-黄绿颜色映射,通过线性采样获取颜色序列 category_colors = plt.colormaps['PiYG']( np.linspace(0.15, 0.85, data.shape[1])) except: # 回退方案:使用旧的get_cmap方法(兼容旧版本) category_colors = plt.get_cmap('PiYG')( np.linspace(0.15, 0.85, data.shape[1])) # 创建图形和坐标轴对象 fig, ax = plt.subplots(figsize=(8, 5)) # 反转y轴,使第一个类别显示在顶部 ax.invert_yaxis() # 隐藏x轴(因为我们要显示的是水平堆叠条形图) ax.xaxis.set_visible(False) # 【修改点2】设置x轴范围为0-1(百分比范围) ax.set_xlim(0, 1)
3.设置坐标轴格式和标签:
# 添加图例:水平排列,放置在图形顶部 ax.legend(ncol=len(category_names), bbox_to_anchor=(0.15, 1), loc='lower left', fontsize=14) # 设置y轴刻度标签的字体大小 ax.tick_params(axis='y', labelsize=12) # 自动调整图形布局,使所有元素都能正常显示 plt.tight_layout()return fig, ax
修改file_path = r'...'代码,改为你自己的Excel文件路径。
file_path = r'F:\data.xlsx' # 设置Excel文件路径
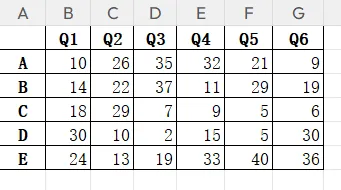
数据格式如下图所示。
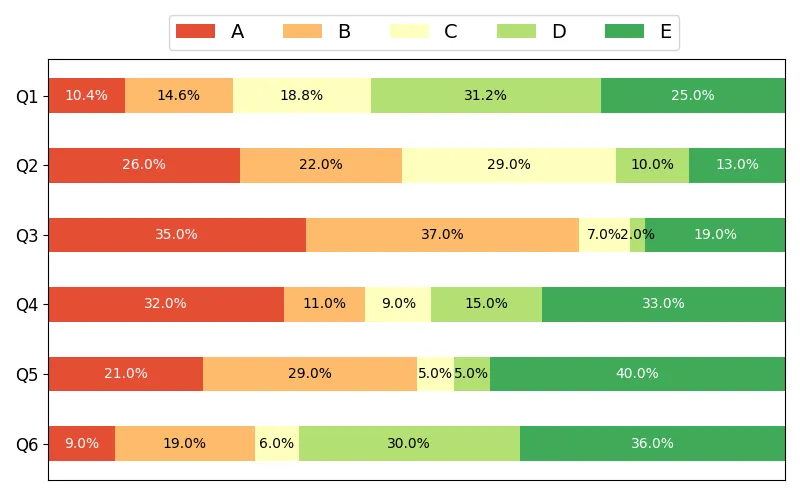
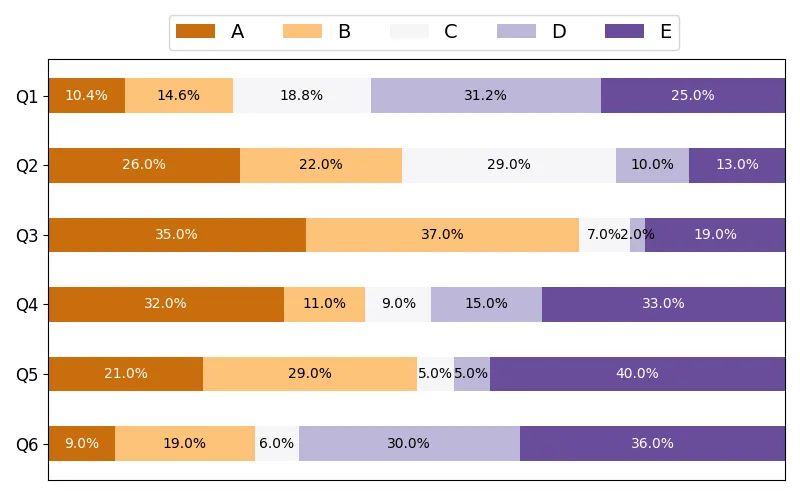
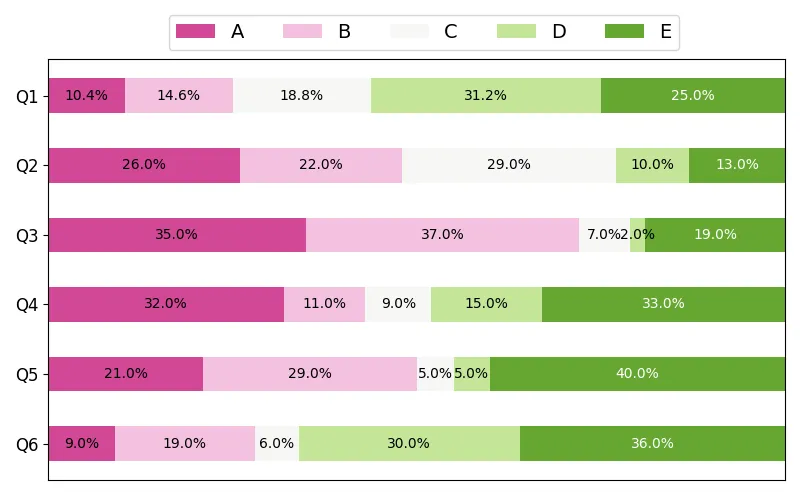
修改代码和文件中的名称,即category_names = ['A', 'B', 'C', 'D', 'E'],根据自己绘图需求修改颜色,修改图形布局。
category_names = ['A', 'B', 'C', 'D', 'E']try: file_path = 'data.xlsx' # 使用 openpyxl 引擎读取 Excel 文件,Sheet1 工作表,第一行为列名,第一列为索引 data = pd.read_excel(file_path, engine='openpyxl', sheet_name='Sheet1', header=0, index_col=0) # 将 DataFrame 转换为字典格式,便于后续处理 data_dict = data.to_dict(orient='dict') results = {} # 按列名重组数据,确保顺序与 category_names 一致 for col in data.columns: results[col] = [data_dict[col][row] for row in category_names] ... try: # 尝试使用新的colormaps API(Matplotlib 3.5+) # category_colors = plt.colormaps['RdYlGn']( # np.linspace(0.15, 0.85, data.shape[1])) # category_colors = plt.colormaps['PuOr']( # np.linspace(0.15, 0.85, data.shape[1])) # category_colors = plt.colormaps['summer']( # np.linspace(0.15, 0.85, data.shape[1])) category_colors = plt.colormaps['PiYG']( np.linspace(0.15, 0.85, data.shape[1])) except: # 回退方案:使用旧的get_cmap方法(兼容旧版本) # category_colors = plt.get_cmap('RdYlGn')( # np.linspace(0.15, 0.85, data.shape[1])) # category_colors = plt.get_cmap('PuOr')( # np.linspace(0.15, 0.85, data.shape[1])) # category_colors = plt.get_cmap('summer')( # np.linspace(0.15, 0.85, data.shape[1])) category_colors = plt.get_cmap('PiYG')( np.linspace(0.15, 0.85, data.shape[1]))
ax.legend(ncol=len(category_names), bbox_to_anchor=(0.15, 1), loc='lower left', fontsize=14) # 设置y轴刻度标签的字体大小 ax.tick_params(axis='y', labelsize=12) # 自动调整图形布局,使所有元素都能正常显示 plt.tight_layout()
【科研绘图】只用Python绘图之相关性热图
【科研绘图】只用Python绘图之单类别散点矩阵图
【科研绘图】只用Python绘图之云雨图
【科研绘图】只用Python绘图之3D瀑布图
如果需要完整代码和数据集,关注公众号,后台回复:堆叠条形图 即可领取!!!
如发现代码的问题和错误,欢迎在评论区指正!
如果觉得有帮助,请点赞、收藏、转发!
如有特定需求,也可通过私信联系!
感谢大家的支持!