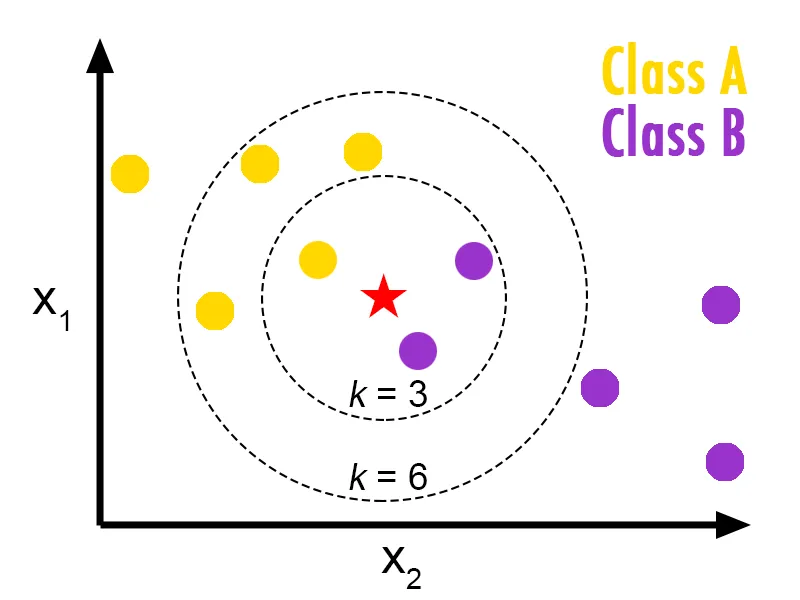
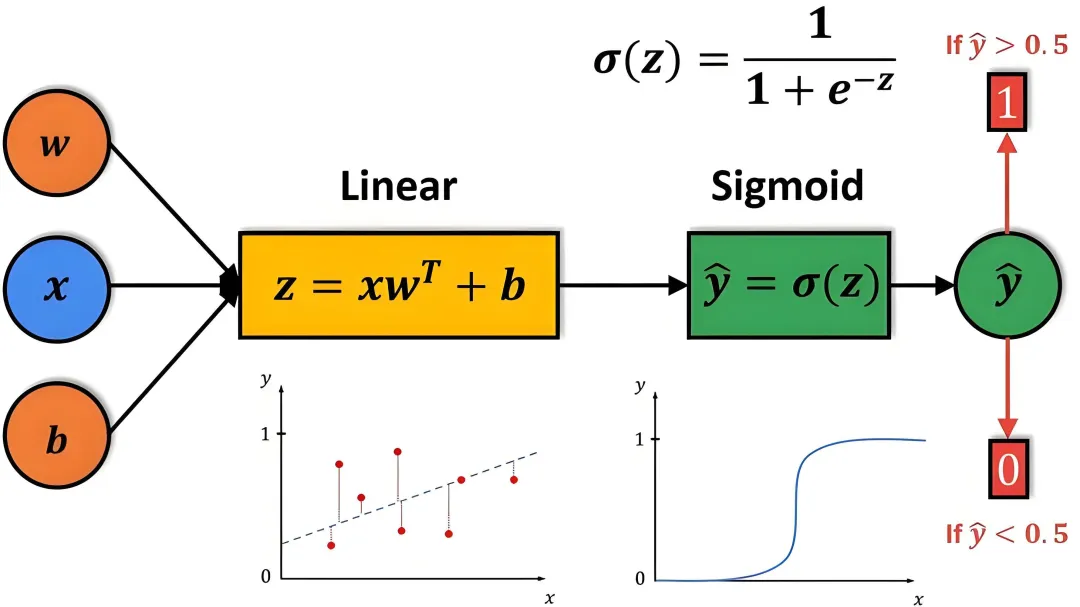
class Perceptron(object): def __init__(self): self.learning_step = 0.00001 self.max_iteration = 5000 def predict_(self, x): wx = sum([self.w[j] * x[j] for j in xrange(len(self.w))]) return int(wx > 0) def train(self, features, labels): self.w = [0.0] * (len(features[0]) + 1) correct_count = 0 time = 0 while time < self.max_iteration: index = random.randint(0, len(labels) - 1) x = list(features[index]) x.append(1.0) y = 2 * labels[index] - 1 wx = sum([self.w[j] * x[j] for j in xrange(len(self.w))]) if wx * y > 0: correct_count += 1 if correct_count > self.max_iteration: break continue for i in xrange(len(self.w)): self.w[i] += self.learning_step * (y * x[i]) def predict(self,features): labels = [] for feature in features: x = list(feature) x.append(1) labels.append(self.predict_(x)) return labels
class MaxEnt(object): def init_params(self, X, Y): self.X_ = X self.Y_ = set() self.cal_Pxy_Px(X, Y) self.N = len(X) # 训练集大小 self.n = len(self.Pxy) # 书中(x,y)对数 self.M = 10000.0 # 书91页那个M,但实际操作中并没有用那个值 # 可认为是学习速率 self.build_dict() self.cal_EPxy() def build_dict(self): self.id2xy = {} self.xy2id = {} for i, (x, y) in enumerate(self.Pxy): self.id2xy[i] = (x, y) self.xy2id[(x, y)] = i def cal_Pxy_Px(self, X, Y): self.Pxy = defaultdict(int) self.Px = defaultdict(int) for i in xrange(len(X)): x_, y = X[i], Y[i] self.Y_.add(y) for x in x_: self.Pxy[(x, y)] += 1 self.Px[x] += 1 def cal_EPxy(self): ''' 计算书中82页最下面那个期望 ''' self.EPxy = defaultdict(float) for id in xrange(self.n): (x, y) = self.id2xy[id] self.EPxy[id] = float(self.Pxy[(x, y)]) / float(self.N) def cal_pyx(self, X, y): result = 0.0 for x in X: if self.fxy(x, y): id = self.xy2id[(x, y)] result += self.w[id] return (math.exp(result), y) def cal_probality(self, X): ''' 计算书85页公式6.22 ''' Pyxs = [(self.cal_pyx(X, y)) for y in self.Y_] Z = sum([prob for prob, y in Pyxs]) return [(prob / Z, y) for prob, y in Pyxs] def cal_EPx(self): ''' 计算书83页最上面那个期望 ''' self.EPx = [0.0 for i in xrange(self.n)] for i, X in enumerate(self.X_): Pyxs = self.cal_probality(X) for x in X: for Pyx, y in Pyxs: if self.fxy(x, y): id = self.xy2id[(x, y)] self.EPx[id] += Pyx * (1.0 / self.N) def fxy(self, x, y): return (x, y) in self.xy2id def train(self, X, Y): self.init_params(X, Y) self.w = [0.0 for i in range(self.n)] max_iteration = 1000 for times in xrange(max_iteration): print 'iterater times %d' % times sigmas = [] self.cal_EPx() for i in xrange(self.n): sigma = 1 / self.M * math.log(self.EPxy[i] / self.EPx[i]) sigmas.append(sigma) # if len(filter(lambda x: abs(x) >= 0.01, sigmas)) == 0: # break self.w = [self.w[i] + sigmas[i] for i in xrange(self.n)] def predict(self, testset): results = [] for test in testset: result = self.cal_probality(test) results.append(max(result, key=lambda x: x[0])[1]) return results