深入解析 Linux systemd: 现代初始化系统的设计与实现
概览摘要
systemd 是 Linux 系统中最重要的底层基础设施之一, 它不仅是初始化系统, 更是整个系统生命周期的管理中枢. 从内核启动到系统运行, 再到优雅关闭, systemd 无处不在. 它通过单元(Unit)抽象、依赖管理、并行启动、事件驱动等创新设计, 彻底改变了 Linux 系统的初始化方式. 相比传统的 SysVinit 方案, systemd 启动速度快 5-10 倍, 这背后隐藏着精妙的架构设计和深思熟虑的工程权衡. 本文将深入剖析 systemd 的核心机制, 包括 Unit 管理、依赖解析、并行启动、事件驱动以及与 cgroup、journald 等组件的集成, 让你理解为什么现代 Linux 发行版都选择了 systemd
核心概念详解
初始化系统的演变
初始化系统是什么?简单说, 它是内核启动完毕后, 第一个运行的用户态程序(PID=1), 负责启动其他所有进程. 这看似简单的工作, 实际上关乎整个系统的启动速度、可靠性和可管理性
传统的 SysVinit 采用串行启动模式: 依次启动 S01xxx、S02xxx、S03xxx 这样的服务, 一个完成才能启动下一个. 这就像工厂流水线一样, 每个工人必须完成手头的工作, 下一个工人才能开始. 虽然逻辑清晰, 但效率很低
systemd 的核心创新是单元化管理 + 依赖驱动 + 并行启动. 不是按固定顺序运行脚本, 而是声明式地描述每个服务的依赖关系, 系统智能地分析依赖图, 然后尽可能并行地启动服务. 这就像从串行流水线升级到了多条并行生产线
Unit: systemd 的抽象基元
Unit 是 systemd 的基本概念, 每个 Unit 代表一个可管理的资源. systemd 定义了 13 种 Unit 类型, 最常见的包括:
- • Service: 后台服务(如 sshd、mysql)
- • Target: 虚拟目标, 用于分组和依赖管理
每个 Unit 都有生命周期状态: inactive(未运行)→ activating(启动中)→ active(运行中)→ deactivating(停止中)→ inactive. Unit 之间通过声明式的依赖关系(Requires、Wants、Before、After 等指令)连接, 形成一个有向无环图(DAG), systemd 通过拓扑排序这个图来确定启动顺序
依赖关系的微妙差别
初次接触 systemd 的人常常困惑于 Wants、Requires、Before、After 这些关键字的区别. 它们看似相似, 实际上代表了不同的语义:
- • Requires vs Wants: Requires 表示硬依赖(如果依赖的 Unit 启动失败, 本 Unit 也失败), Wants 表示软依赖(依赖的 Unit 失败不影响本 Unit). 这就像说"我必须要咖啡"(Requires)vs"我想要咖啡"(Wants)的区别
- • Before vs After: Before 表示"我必须在某 Unit 之前启动", After 表示"我必须在某 Unit 之后启动". 这控制的是时间顺序
关键洞察: 依赖关系在 systemd 中是有向的. A 依赖 B 不意味着 B 也依赖 A. 一个 Unit 可以声明 After: multi-user.target, 但 multi-user.target 不知道 A 的存在
systemd 的并行度
systemd 不是无限并行, 而是通过 DefaultDependencies、Before/After 链等机制保证关键的启动顺序. 比如, 网络必须在需要网络的服务之前启动, 系统日志必须在所有日志输出之前准备好. systemd 通过分析依赖图, 找到可以并行执行的分支, 大幅减少了启动时间
实现机制深度剖析
Unit 文件结构与关键字
Unit 文件是标准的 INI 格式, 通常位于 /etc/systemd/system/ 或 /usr/lib/systemd/system/ 下. 一个典型的 Service Unit 文件如下:
[Unit]# Unit 的元数据和依赖关系Description=Apache HTTP ServerDocumentation=man:httpd(8)After=network-online.targetWants=network-online.targetStartLimitInterval=60StartLimitBurst=3[Service]# 服务启动、停止、重启的具体行为Type=notifyExecStartPre=/usr/sbin/httpd -tExecStart=/usr/sbin/httpd -DFOREGROUNDExecReload=/usr/sbin/httpd -t && systemctl reload httpdRestart=on-failureRestartSec=10sTimeoutStopSec=30sStandardOutput=journalStandardError=journal[Install]# systemctl enable/disable 时的行为WantedBy=multi-user.target
每个字段的含义:
- •
Type: 启动类型. simple(默认)、forking(fork 后父进程退出)、oneshot(一次性任务)、notify(等待 SIGTERM) - •
Restart: 失败后重启策略. always、on-failure、on-success 等 - •
StandardOutput/StandardError: 输出重定向到 journald 便于集中管理日志
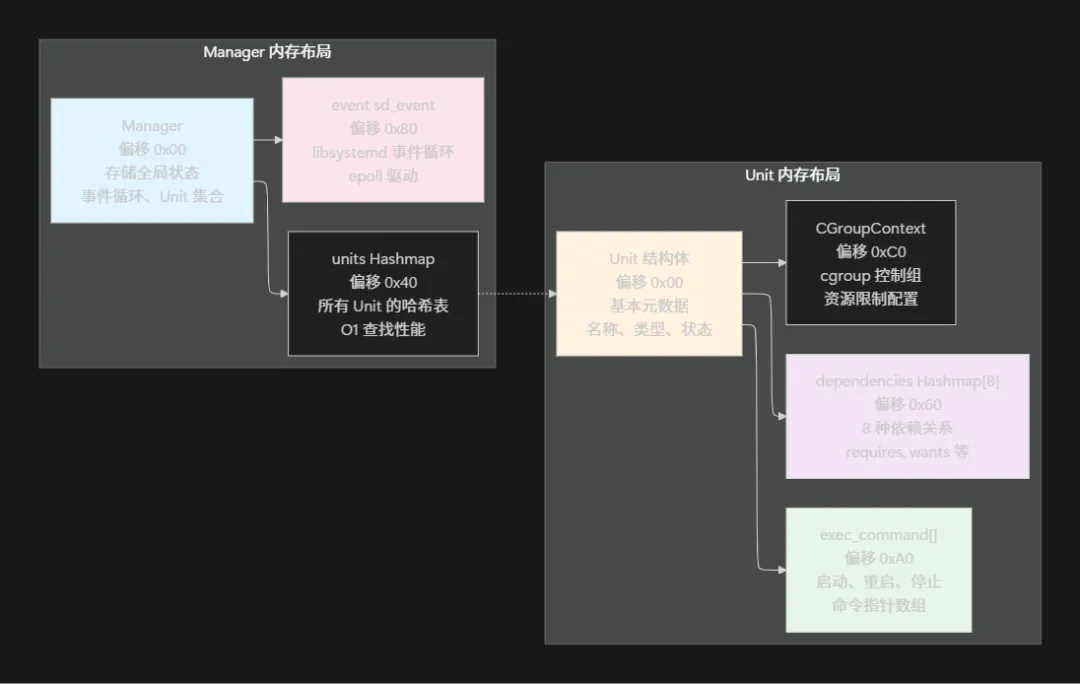
数据结构与内存布局
systemd 的核心数据结构相当复杂, 我们先看 Unit 的基本结构(简化后):
// Unit 结构体, 代表每个 systemd Unitstruct Unit { Manager *manager; // 指向全局管理器 char *id; // Unit 名称, 如 "sshd.service" char *description; // 描述 UnitType type; // Unit 类型 UnitLoadState load_state; // 加载状态 UnitActiveState active_state; // 活跃状态 // 依赖关系图 Hashmap *dependencies[UNIT_NTYPES]; OrderedSet *before, *after; // Before/After 依赖 // 启动和停止的可执行文件 ExecCommand *exec_command[_UNIT_EXEC_COMMAND_MAX]; // 重启策略和失败处理 int restart; usec_t timeout_start_usec; usec_t timeout_stop_usec; // 进程信息 pid_t main_pid; pid_t control_pid; // cgroup CGroupContext cgroup_context;};// Manager 结构体, 全局管理器, 协调所有 Unitstruct Manager { Hashmap *units; // 所有已加载的 Unit OrderedSet *startup_queue; // 待启动的 Unit 队列 // 事件循环 sd_event *event; // libsystemd 的事件循环 sd_event_source *sigchld_event_source; // 依赖关系图分析 Unit **unit_by_name; // 日志和输出 Hashmap *watch_jobs; // 监控中的 Job};// Job 结构体, 代表一个启动或停止任务struct Job { Manager *manager; Unit *unit; JobType type; // start, stop, reload 等 JobState state; // waiting, running, done 等 unsigned id;};
内存布局示意图:
依赖解析与拓扑排序
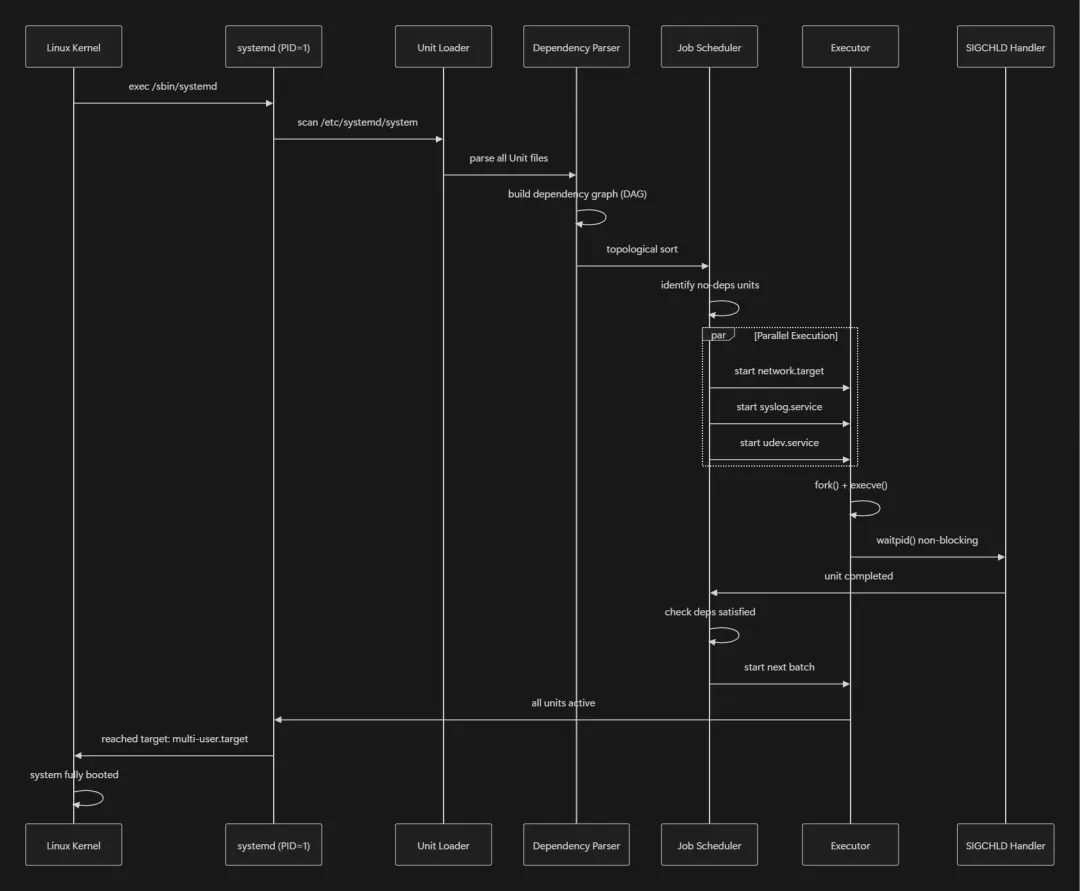
systemd 在启动阶段需要解析复杂的依赖图, 确保正确的启动顺序. 这涉及一个关键的算法: 有向无环图(DAG)的拓扑排序
系统启动时, systemd 首先加载所有 Unit 文件, 构建一个巨大的依赖图. 然后执行拓扑排序, 得到一个启动序列, 确保:
- 1. 如果 A After B, 则 B 的启动必须在 A 之前完成
- 2. 如果 A Requires B, 则 B 必须启动成功, 否则 A 也视为失败
- 3. 如果 A Wants B, 则 B 应该启动, 但 B 失败不影响 A
伪代码逻辑如下:
// 简化的拓扑排序算法void topological_sort(Manager *m, Unit **sorted, int *count) { // 计算每个 Unit 的入度(有多少其他 Unit 依赖于它) for (Unit *u = NULL; (u = hashmap_iterate(m->units, &i, NULL)); ) { u->in_degree = 0; } // 遍历所有依赖关系, 计算入度 for (Unit *u = NULL; (u = hashmap_iterate(m->units, &i, NULL)); ) { for (Unit *dep = NULL; (dep = set_iterate(u->before, &j, NULL)); ) { dep->in_degree++; } } // Kahn 算法: 入度为 0 的 Unit 可立即启动 Queue *q = queue_new(); for (Unit *u = NULL; (u = hashmap_iterate(m->units, &i, NULL)); ) { if (u->in_degree == 0) { queue_push(q, u); } } // 依次取出入度为 0 的 Unit, 减少其后续 Unit 的入度 while (!queue_empty(q)) { Unit *u = queue_pop(q); sorted[(*count)++] = u; for (Unit *dep = NULL; (dep = set_iterate(u->before, &j, NULL)); ) { dep->in_degree--; if (dep->in_degree == 0) { queue_push(q, dep); } } }}
并行启动的事件驱动机制
systemd 不是简单的顺序启动, 而是基于事件驱动的并行启动. 它使用 libsystemd 提供的 sd_event 事件循环(底层是 Linux epoll), 监控子进程的状态变化
核心流程:
// 主事件循环int manager_run(Manager *m) { while (m->running) { // 启动所有依赖已满足的 Unit manager_queue_startup(m); // 等待子进程信号或超时 int r = sd_event_run(m->event, (uint64_t) -1); if (r < 0) { return r; } // 处理子进程状态变化 if (m->sigchld_pending) { manager_reap_children(m); m->sigchld_pending = false; } // 检查是否有 Unit 启动超时 manager_check_timeouts(m); } return 0;}// 加入待启动队列void manager_queue_startup(Manager *m) { for (Unit *u = NULL; (u = hashmap_iterate(m->units, &i, NULL)); ) { if (unit_is_ready_to_start(u) && !unit_is_active(u)) { // 创建一个启动任务 Job *job = job_new(m, JOB_START, u); job_install(m, job); } }}// 监听 SIGCHLD 信号, 处理子进程状态变化static int manager_sigchld_handler(sd_event_source *s, int signum, siginfo_t *si, void *userdata) { Manager *m = userdata; m->sigchld_pending = true; return 0;}// 清理已终止的子进程int manager_reap_children(Manager *m) { siginfo_t si; while (waitid(P_ALL, 0, &si, WNOHANG | WEXITED) > 0) { // 找到对应的 Unit Unit *u = manager_get_unit_by_pid(m, si.si_pid); if (u) { if (si.si_status == 0) { // 子进程成功退出 unit_notify(u, UNIT_SUCCESS); } else { // 子进程失败 unit_notify(u, UNIT_FAILURE); } } } return 0;}
这种事件驱动的设计使得 systemd 可以高效地管理数百个进程, 而不需要频繁的轮询或忙等待
cgroup 集成与资源管理
systemd 深度集成了 Linux cgroup(控制组), 这使得每个 Unit 都可以进行精细的资源管理. 当 Unit 启动时, systemd 自动为其创建对应的 cgroup, 配置内存限制、CPU 限额、IO 限制等
// Unit 的 cgroup 上下文struct CGroupContext { bool cpu_accounting; bool io_accounting; bool blockio_accounting; bool memory_accounting; bool tasks_accounting; // CPU 限制 uint64_t cpu_shares; // CPU 权重(相对值) uint64_t cpu_quota_per_sec_usec; // 每秒 CPU 配额 uint64_t cpu_quota_period_usec; // 配额周期 // 内存限制 uint64_t memory_limit; // 最大内存 uint64_t memory_soft_limit; // 软限制 // IO 限制 uint64_t io_weight; // IO 权重 LIST_HEAD(CGroupIODeviceLimit, io_device_limits); // 进程数限制 uint64_t tasks_max;};// 创建 cgroupint cgroup_context_apply(Unit *u, CGroupContext *c, pid_t pid) { _cleanup_free_ char *path = NULL; // 生成 cgroup 路径: /system.slice/sshd.service path = cgroup_make_path(u->id); // 创建 cgroup cgroup_create(path); // 设置内存限制 if (c->memory_limit > 0) { cgroup_write_u64(path, "memory.limit_in_bytes", c->memory_limit); } // 设置 CPU 限制 if (c->cpu_quota_per_sec_usec > 0) { uint64_t quota = c->cpu_quota_per_sec_usec; uint64_t period = c->cpu_quota_period_usec ?: 100000; cgroup_write_u64(path, "cpu.cfs_quota_us", quota); cgroup_write_u64(path, "cpu.cfs_period_us", period); } // 将进程加入 cgroup cgroup_attach(path, pid); return 0;}
通过 cgroup 集成, systemd 不仅启动服务, 还能隔离和管理资源, 这对于多租户环境或资源受限的系统至关重要
套接字激活机制
systemd 的一个创新特性是套接字激活(socket activation). 传统方式是服务启动时监听网络端口, 而套接字激活让系统提前创建套接字并传递给服务, 这样多个服务可以监听同一个端口, 按需启动
原理很巧妙: systemd 在启动阶段创建服务需要的所有套接字, 监听入站连接. 当有连接到达时, systemd 才真正启动服务, 并通过环境变量 LISTEN_FDS 和 LISTEN_PID 将文件描述符传递给它. 这样做有几个好处:
- 1. 并行启动: 所有套接字可以提前创建, 无需等待服务启动
- 2. 按需启动: 真正有请求时才启动服务, 节省资源
- 3. 服务重启无中断: 旧服务停止, 新服务启动, 同一个套接字无缝切换, 客户端无感知
实现示例:
// 套接字激活的文件描述符传递void service_pass_socket_fds(Unit *u, Service *s) { int n_fds = 0; int fds[256]; // 查询本 Unit 对应的所有 Socket Unit for (Unit *socket = NULL; (socket = set_iterate(u->dependencies[UNIT_SOCKET], &i, NULL)); ) { if (!socket_is_listening(socket)) { continue; } // 获取套接字的文件描述符 Socket *sock = SOCKET(socket); for (SocketPort *p = sock->ports; p; p = p->next) { if (p->fd >= 0) { fds[n_fds++] = p->fd; } } } // 通过环境变量传递 fd 信息 char buf[DECIMAL_STR_MAX(int)]; xsprintf(buf, "%d", n_fds); setenv("LISTEN_FDS", buf, 1); xsprintf(buf, "%d", getpid()); setenv("LISTEN_PID", buf, 1); // fds 在 3-3+n_fds 之间已准备好, service 可直接使用}// 服务端代码获取套接字int main() { int n = sd_listen_fds(0); // 获取 fd 数量 for (int i = 0; i < n; i++) { int fd = SD_LISTEN_FDS_START + i; // 直接使用 fd, 已经是监听状态 while (1) { int client = accept(fd, NULL, NULL); // 处理客户端... } }}
systemd 日志: journald
systemd 自带的 journald 是一个革命性的日志系统. 传统的 syslog 将日志写入 /var/log/messages, 只保存文本, 丢失结构化信息. journald 则把日志当作数据库, 保存为二进制格式, 支持丰富的元数据和查询能力
journald 的数据结构(简化):
// 日志项struct JournalEntry { uint64_t seqnum; // 序列号, 全局唯一递增 uint64_t monotonic_usec; // 单调时间戳 uint64_t realtime_usec; // 实时时间戳 // 数据字段(哈希表) Hashmap *fields; // "MESSAGE", "SYSLOG_IDENTIFIER", etc};// journald 日志库struct Journal { MMapCache *mmap_cache; // 内存映射缓存 // 日志索引, 加速查询 Hashmap *fields_index; // 字段索引 Hashmap *data_hash_table; // 数据去重 Hashmap *entry_array; // 条目数组 uint64_t total_disk_usage;};
journald 与各服务的集成是透明的: 只要服务的 StandardOutput/StandardError 设为 journal, systemd 会自动重定向 stdout/stderr 到 journald 的 Unix 套接字, 完全无需服务代码修改. 这使得系统日志高度集中化
# 查询日志非常强大journalctl -u sshd.service --since "1 hour ago" # 查询 sshd 最近 1 小时的日志journalctl -p err # 只看错误及以上journalctl -f # 实时跟踪日志journalctl --output=json # JSON 格式输出
设计思想与架构
为什么 systemd 胜过 SysVinit?
这个问题的答案深深植根于现代操作系统的发展. 当 SysVinit 在 1990 年代设计时, 服务器通常只有 10-20 个启动脚本, 启动时间不是大问题. 但到了 2010 年代, 嵌入式设备和云服务器启动速度变得关键. systemd 的设计原则非常前卫:
- 1. 并行优先: SysVinit 的 S01, S02, S03 命名天然强制串行;systemd 用依赖图天然支持并行
- 2. 事件驱动: SysVinit 是脚本阻塞式;systemd 基于事件循环, 高效处理异步事件
- 3. 一致的接口: SysVinit 靠 bash 脚本, 五花八门;systemd Unit 文件是标准化的, 机器可读
- 4. 深度集成: systemd 与 cgroup、seccomp、SELinux 等紧密集成, 提供统一的安全隔离
启动速度的提升是显而易见的. 一个典型的云服务器, 用 SysVinit 需要 30 秒启动, 用 systemd 只需 3-5 秒. 这对云计算和容器化是革命性的改进
设计权衡: 复杂性 vs 功能性
systemd 的代码量远大于 SysVinit(systemd 核心约 1.3 MB, SysVinit 仅 50 KB), 这引发了一些批评. 但这是一个合理的权衡:
| | |
|---|
| | |
| | |
| | |
| | |
| | |
| | |
| | PrivateTmp、NoNewPrivileges 等 |
更多代码意味着更多的功能和更好的性能. 在现代系统中, 这个权衡是值得的
可能的替代方案对比
虽然 systemd 已成为 Linux 主流, 但也有其他初始化系统:
systemd 之所以成为事实上的标准, 不仅是因为功能多, 更因为它解决了现代 Linux 系统的一系列真实问题: 启动速度、日志管理、资源隔离、安全加固
systemd 的局限性
任何系统都不是完美的, systemd 也有其限制:
- 1. 过度设计: 某些功能(如 systemd-resolved、systemd-networkd)争议较大, 过度"一统天下"
- 2. 学习曲线: Unit 文件虽比 shell 脚本清晰, 但对新手仍有难度
- 3. 依赖关系解析的复杂性: 大型系统的依赖图可能非常复杂, 难以调试
- 4. 向后兼容性: 一些传统的 shell 脚本方式不再适用
实践示例
创建和管理自定义服务
让我们通过一个完整的例子来演示如何创建和管理一个 systemd 服务. 假设我们要为一个简单的 Python 应用创建服务
首先, 编写应用代码(app.py):
#!/usr/bin/env python3import timeimport signalimport sysdef signal_handler(sig, frame): print("Received SIGTERM, shutting down gracefully...", file=sys.stderr) sys.exit(0)signal.signal(signal.SIGTERM, signal_handler)if __name__ == "__main__": print("Application started", file=sys.stderr) try: while True: print("Service is running...", file=sys.stderr) time.sleep(5) except KeyboardInterrupt: print("Interrupted", file=sys.stderr) sys.exit(0)
然后, 创建 systemd Unit 文件(/etc/systemd/system/myapp.service):
[Unit]Description=My Custom ApplicationDocumentation=man:myapp(1)After=network.targetStartLimitInterval=60StartLimitBurst=3[Service]Type=simpleUser=myappGroup=myappWorkingDirectory=/opt/myappExecStart=/opt/myapp/app.pyRestart=on-failureRestartSec=5sTimeoutStopSec=10s# 输出到 journaldStandardOutput=journalStandardError=journalSyslogIdentifier=myapp# 资源限制MemoryLimit=256MCPUQuota=50%# 安全加固PrivateTmp=yesNoNewPrivileges=yesProtectSystem=strictProtectHome=yes[Install]WantedBy=multi-user.target
使用命令管理服务:
# 重新加载 systemd 配置sudo systemctl daemon-reload# 启动服务sudo systemctl start myapp.service# 查看服务状态systemctl status myapp.service# 查看输出日志journalctl -u myapp.service -f# 启用开机自启sudo systemctl enable myapp.service# 停止服务sudo systemctl stop myapp.service# 重启服务sudo systemctl restart myapp.service# 检查服务的依赖关系systemctl list-dependencies myapp.service
预期输出:
● myapp.service - My Custom Application Loaded: loaded (/etc/systemd/system/myapp.service; enabled) Active: active (running) since Mon 2024-01-15 10:20:35 UTC; 2min 30s ago Process: 1234 ExecStart=/opt/myapp/app.py (code=exited, status=0/SUCCESS) Main PID: 1235 (python3) Tasks: 1 (limit: 1024) Memory: 24.5M / 256M CPUQuota: 50%Jan 15 10:20:35 myhost systemd[1]: Started My Custom Application.Jan 15 10:20:35 myhost myapp[1235]: Application startedJan 15 10:20:40 myhost myapp[1235]: Service is running...Jan 15 10:20:45 myhost myapp[1235]: Service is running...
套接字激活示例
下面演示套接字激活的实际应用. 创建一个简单的网络服务, 使用套接字激活:
创建 echo 服务(echo.service):
[Unit]Description=Simple Echo ServiceAfter=syslog.targetRequires=echo.socket[Service]Type=simpleExecStart=/usr/local/bin/echo-serverStandardOutput=journalStandardError=journalRestart=always[Install]WantedBy=multi-user.target
创建对应的套接字单元(echo.socket):
[Unit]Description=Echo Service SocketBefore=echo.service[Socket]ListenStream=9999Accept=false# 一旦有连接, 立即启动 echo.serviceTrigger=echo.service[Install]WantedBy=sockets.target
echo-server 程序代码(C 实现):
#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <systemd/sd-daemon.h>int main() { // 获取 systemd 传递的文件描述符 int n = sd_listen_fds(1); if (n < 1) { fprintf(stderr, "No socket passed by systemd\n"); return 1; } int fd = SD_LISTEN_FDS_START; // fd = 3 while (1) { char buffer[256]; ssize_t n = read(fd, buffer, sizeof(buffer) - 1); if (n > 0) { buffer[n] = '\0'; printf("Received: %s", buffer); write(fd, buffer, n); // echo 回显 } else { break; } } close(fd); return 0;}
管理套接字激活的服务:
# 启用套接字sudo systemctl enable echo.socketsudo systemctl start echo.socket# 此时 echo.service 还未启动, 监听已准备好sudo systemctl list-units --all | grep echo# 第一次连接, systemd 自动启动 echo.servicenc -w 1 localhost 9999 <<< "hello"# 查看日志确认服务启动journalctl -u echo.service
工具与调试
在开发和调试 systemd 服务时, 以下工具至关重要:
| | |
|---|
| | systemctl status sshd |
| | journalctl -u sshd -n 50 |
| | systemd-analyze plot > startup.svg |
| | systemd-analyze blame | head -20 |
| systemd-analyze critical-chain | | systemd-analyze critical-chain |
| | systemctl show -a sshd.service |
| | systemd-run -p MemoryLimit=512M /bin/bash |
| | coredumpctl list |
| | systemd-cgls |
| | systemd-cgtop |
性能分析的高级用例:
# 查看启动图表(SVG 格式)systemd-analyze plot > startup.svg# 分析最耗时的 Unitsystemd-analyze blame | head -20# 查看临界启动路径systemd-analyze critical-chain# 追踪特定服务的执行journalctl -u myservice -o short-precise# 监控实时的 cgroup 资源占用systemd-cgtop# 查看服务的所有属性systemctl show mysql.service -p MemoryLimit
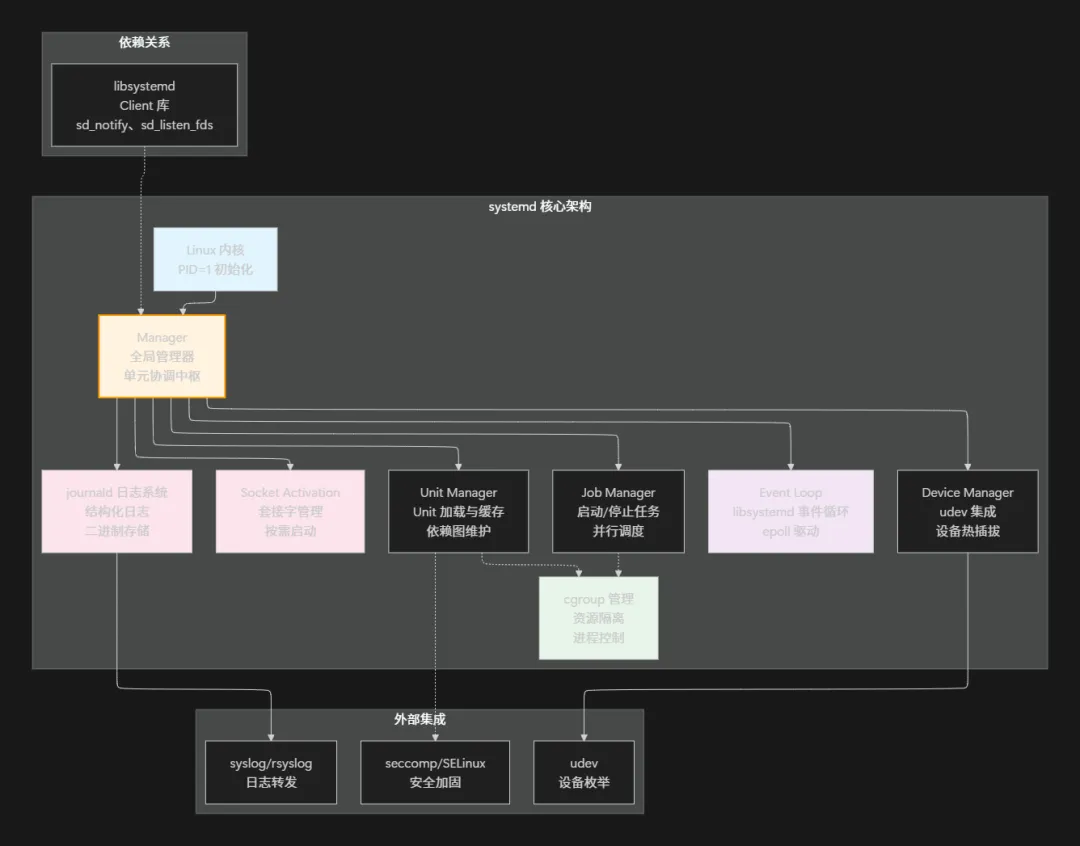
架构总览
systemd 的整体架构可以用以下 Mermaid 图表展示:
更详细的启动流程时序图:
完整的启动依赖树示例:
multi-user.target ← 最终目标 ├─ basic.target │ ├─ sysinit.target │ │ ├─ sys-kernel-debug.mount │ │ ├─ systemd-journal-flush.service │ │ ├─ systemd-tmpfiles-setup.service │ │ ├─ dev-mqueue.mount │ │ └─ ... │ ├─ paths.target │ ├─ slices.target │ │ ├─ system.slice │ │ ├─ user.slice │ │ └─ ... │ └─ ... ├─ getty.target │ └─ getty@tty1.service ├─ network.target │ ├─ network-pre.target │ ├─ network-online.target │ │ └─ systemd-networkd-wait-online.service │ └─ ... ├─ ssh.service (After=network.target) ├─ mysql.service (After=network.target) └─ ...
全文总结
systemd 从根本上改变了 Linux 系统的启动方式, 它的成功不是偶然, 而是源于深思熟虑的架构设计:
| | |
|---|
| Unit 抽象 | | |
| 依赖驱动 | | |
| 并行启动 | | |
| 事件驱动 | | |
| cgroup 集成 | | |
| journald | | |
| 套接字激活 | | |
systemd 的出现标志着 Linux 系统管理从脚本时代进入了现代化时代. 它通过声明式配置、自动化依赖管理和事件驱动架构, 解决了传统初始化系统的根本问题. 虽然复杂性增加了, 但在现代云计算、容器化和微服务的背景下, 这种复杂性是必要的、值得的
未来, systemd 仍在演进: systemd-oomd 用于内存压力管理、systemd-homed 用于用户家目录管理、systemd-sysext 用于系统扩展. 它已经不仅仅是初始化系统, 而是整个 Linux 系统管理的基石

