Python学习第二课(第7节:输入与输出)
- 2026-07-13 08:16:27
Python 中的输入与输出
看到这一节的内容,可能很多人会觉得没啥意思,输入不就是我们输入到电脑里的内容,输出不就是电脑运行代码后显示出来给我们看的结果吗?
其实,输入与输出还真不是想象中这么简单!
学了这么多节课,不知道你发现一个问题没?我们最开始是在 Python 命令行下输入代码,然后在命令行下显示结果,后来慢慢切换到模块文件中输入代码,然后在 Windows 命令行下运行模块文件显示结果。
由于“输入”相对比较简单,学习起来也快,所以,下面我们就开始讲解“输出”!
一、什么是输出?
啊~喂!前面几个站起来的童鞋,我知道你们喜欢打“农药”和“撸啊撸”,请别激动,先坐下来好好听讲!
还记得大明湖畔的夏雨荷吗?

不对,应该是:还记得《Python学习第二课(第1节:函数)》里讲过的 print 函数的参数 file 吗?
不记得也没关系,咱们再来一起温酒斩华雄……呃……温故而知新一次!
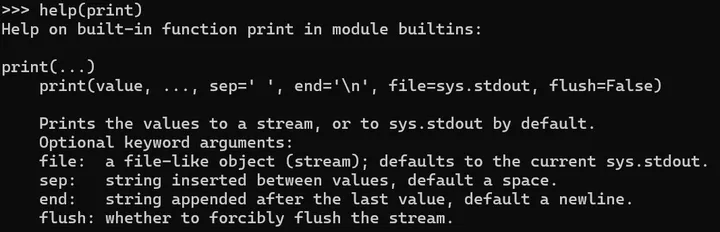
看到了吧,file 默认值为 sys.stdout。这个 stdout 就是标准输出(Standard Output)的简写,也就是系统命令行。下面,尝试在 Python 命令行下输入如下代码:
>>> f = open('1.txt', 'w') # 打开一个文件,模式为写文件>>> print('12345', file=f)>>> f.close() # 一定要养成用完后关闭文件的好习惯!
你会发现此时的 print 函数不再将 12345 显示在命令行,在当前工作目录下会多一个 1.txt 文件,文件内容为 12345。
什么?你还不知道 Python 命令行下如何查看工作目录?在这里不得不补充一个小知识点了:
如何查看 Python 工作目录?
1、使用“运行 -> cmd”打开 Windows 命令行时,工作目录为:C:\Users\<YourUserName>;
2、在文件夹空白位置右键“在终端中打开”命令行时,工作目录为当前文件夹;
3、在地址栏输入“cmd”,然后回车打开命令行时,同上。
啊!你不记得这个命令行是怎么打开的了?没事,在 Python 命令行下输入如下代码即可查看:
>>> import os>>> os.getcwd()
好了,言归正传!刚才的示例代码 f = open('1.txt', 'w') 中的 f 就是一个文件输出对象,在 print 中替代了 sys.stdout 系统标准输出,于是输出的内容就输出到文件 1.txt 中了。
关于将内容写入文件,print 函数的这个用法不是很专业,也显得比较麻烦,所以有专门的 write 函数来进行文件写入。用法如下:
with open('1.txt', 'w') as f:f.write('12345\n')
说明:with 语句是可以省略一些异常捕捉的常用方法,如果出现异常会自动捕捉。
如果不用 with 语句,上面的代码可能就需要写成这样:
f = open('1.txt', 'w')try:data = f.write('12345\n')finally:f.close()
这样写可太麻烦了,一点儿也不优雅!
那么,输出的对象除了系统标准输出和文件之外,还有其他的吗?
那是必须滴!sys 模块除了 stdout 之外,还有一个 stderr,叫做“标准错误输出(Standard Error)”。
在 Linux 中,虽然标准输出(stdout)和标准错误(stderr)是两个不同的输出通道,但它们在终端中看起来是一样的:都直接显示在屏幕上,且字体、颜色和格式也通常相同。也就是说,从用户的角度来看,两者的输出效果是没有区别的。
说到字体、颜色和格式,Windows 命令行默认是没有颜色的,我们可以通过一些方法来让输出的内容变得有点颜色,感兴趣的童鞋可以看看我的这篇文章:
【Python】Windows的CMD命令行下打印彩色的文字,非常好看!
CMOS三好先生,公众号:CMOS都有[Python] Windows 的 CMD 命令行下打印彩色的文字,非常好看!
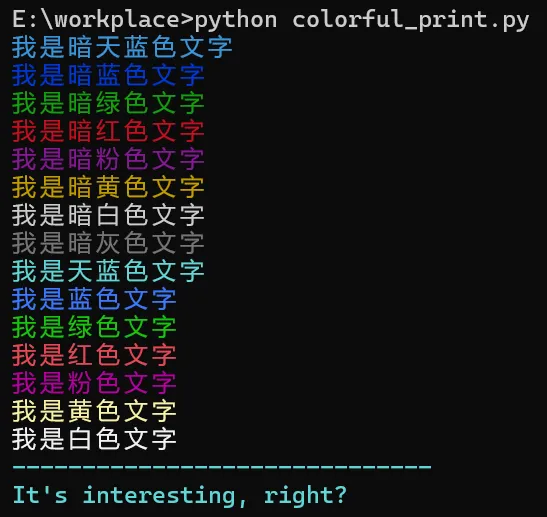
除了颜色,我们还可以设置文字的排版格式。说到这里,又得补充一点小知识,之前一直没有机会讲,那就是——Python 中字符串格式化的方式。
Python 字符串格式化
1、% 格式化
print('%s: %d%s %f %f %.2f' % ('xxx', 520, 1314, 3.1415, 3.1415926, 3.1415926535897))# 输出结果xxx: 5201314 3.141500 3.141593 3.14
其中,%s 表示将传入对象格式化为一个字符串,支持任何可以转换为字符串的对象;
%d 表示格式化的对象是一个整数,如果传入浮点数则会舍弃小数部分,传入字符串就会报错:TypeError: %d format: a number is required, not str;
%f 表示格式化的对象是一个浮点数,默认为保留6位小数,不足部分用0补齐,%.2f 则表示保留2位小数。如果传入整数,则用0补齐小数部分,传入字符串会报错:TypeError: must be real number, not str。
这个例子我特意将 %d 和 %s 写在一起展示结果,就是表示 %d 可以用 %s 来代替,但这样就无法将浮点数的小数部分舍弃。
由于这种格式化的方式非常不灵活,一般只在 Python 2 中使用,Python 3 中已经很少用到。
2、format 函数格式化
print('{}, {}{:.2f}'.format('xxx', 520, 3.1415926))print('{}: {}{}'.format('xxx', 520, 1314, 3.1415926))print('{3:.2f}. {1}{2}, {0}! {1}!!!'.format('xxx', 520, 1314, 3.1415926))
其中,{} 就代表一个字符串格式化需要的参数,{n} 就表示传入参数列表中的第 n-1 个参数(编号从0开始),{:.nf} 就表示保留n位小数。
所以,这种格式化方式明显一看就比第1种要灵活,{} 方式传入的参数个数可以多于字符串格式化需要的参数个数,{n} 方式传入的参数个数更灵活,一个参数可以多次使用,只要数字不超过 n-1 即可。
注意:{} 和 {n} 不能混用!也支持{:d} 和 {:f},表示需要传入整形(传入非整形会报错)和浮点数(一般不这样使用)。
错误示例:
print('{}, {}{}'.format('xxx', 520))print('{}, {}{:d}'.format('xxx', 520, 3.14)) # %d传浮点数不会报错print('{}, {}{:d}'.format('xxx', 520, '314'))
3、f-string 格式化
name = 'xxx'text = 520PI = 3.1415926535897print(f'{name}, {text}!!! {text + 1314}, {PI:.2f}')# 输出结果xxx, 520!!! 1834
这种方式是目前字符串格式化最简单的方式,而且还支持函数调用!比如:
print(f'1~100的和为: {sum(range(1,101))}')print(f'100以内的所有素数:{[i for i in range(2, 101) if all(i % j != 0 for j in range(2, int(i**0.5) + 1))]}')
唯一可能出问题的地方就是会忘记写最前面的 "f",此时就会打印出一堆{xxx变量名}了,不过主流的 IDE 插件都会有相应的提示。
还有唯一的缺点,就是不能预先写好字符串,然后再动态格式化字符串。比如下面是用前两种方式实现的动态格式化字符串的代码(f-string 就无法实现):
i_love_sb = 'I love %s!!!'i_hate_sb = 'I hate {}!!!'for name in ['xxx', 'yyy']:print(i_love_sb % name)print(i_hate_sb.format(name))
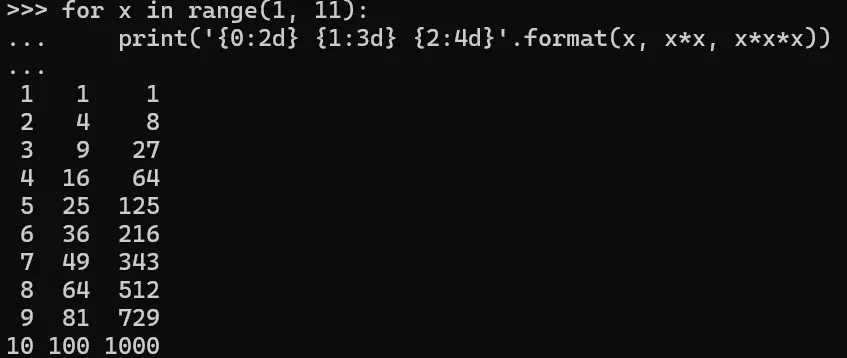
最后,再举一个字符串格式化排版的栗子作为输出的结尾内容:
for x in range(1, 11):print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
运行结果如下:
当然,除了颜色和格式之外,字体也是可以设置的,但我觉得没有什么展示的必要,所以在这里就不展示了。
接下来,我们再来看看输入!
二、什么是输入?
输入确实很简单,就是程序如何接收用户的数据,有两种方式:
1、input 函数接收用户的输入字符串
input 函数在之前课程中的猜数字游戏里已经用到过:
number = input('请输入你想猜的数字:')2、读取用户的文件数据
读取文本文件 1.txt:
with open('1.txt', 'r', encoding='utf8') as f:text = f.read()print(text)
其中,read()函数会读取 1.txt 文件里的全部字符串,read(n)则表示一次性读取n个字符。注意:打开文件后,f.read(n)就会读取前 n 个字符,再次调用就继续读取 n 个字符;f.read()调用一次之后,再次调用不会再次读取文件的字符串,会返回空字符串 ''。
除了 read 函数之外,还有 readline 和 readlines 函数可以读取数据。
readline 一次读取一行数据,并保留行末的'\n'换行符,再次读取则读取下一行的内容,直到最后文末没内容时,返回空字符串 ''。
readlines 一次性读取所有行数,并返回每一行的字符串列表,和 read 函数一样也只能读取一次,多次调用返回空列表 []。
读取二进制文件 2.bin:
with open('2.bin', 'rb') as f: # 二进制文件不能传encoding参数content = f.read()print(content)
一般来说,二进制文件读取后直接 print 会显示乱码,除非你在写入时就是可读的内容,比如:
with open('2.bin', 'wb') as f:n = f.write(b'12345\n') # 二进制文件必须传入byte类型的字符串print(n)# 会生成一个2.bin的二进制文件,n为字符串的长度
那么,如果我想读取文件中的第 m~n 个字符,需要如何读取呢?看看下面的代码就明白了:
with open('1.txt', 'w') as f:f.write('1234567890abcdefg')def read_from_m_2_n(fname, m, n):with open(fname, 'r') as f:f.seek(m - 1)content = f.read(n - m + 1)return contentprint(read_from_m_2_n('1.txt', 5, 12)) # 结果:567890ab
其中,seek() 函数,表示定位到文件的第 m 个字符位置处开始读取,read(n - m + 1) 表示读取的字符范围。
好了,今天的课程就到这里结束了,下节课就开始讲第三课第1节的内容——Python 中的类,这可是面向对象编程必须掌握的概念,听说学会了之后都有对象哦!哈哈,开个玩笑,同学们,下课!

