1. 引言
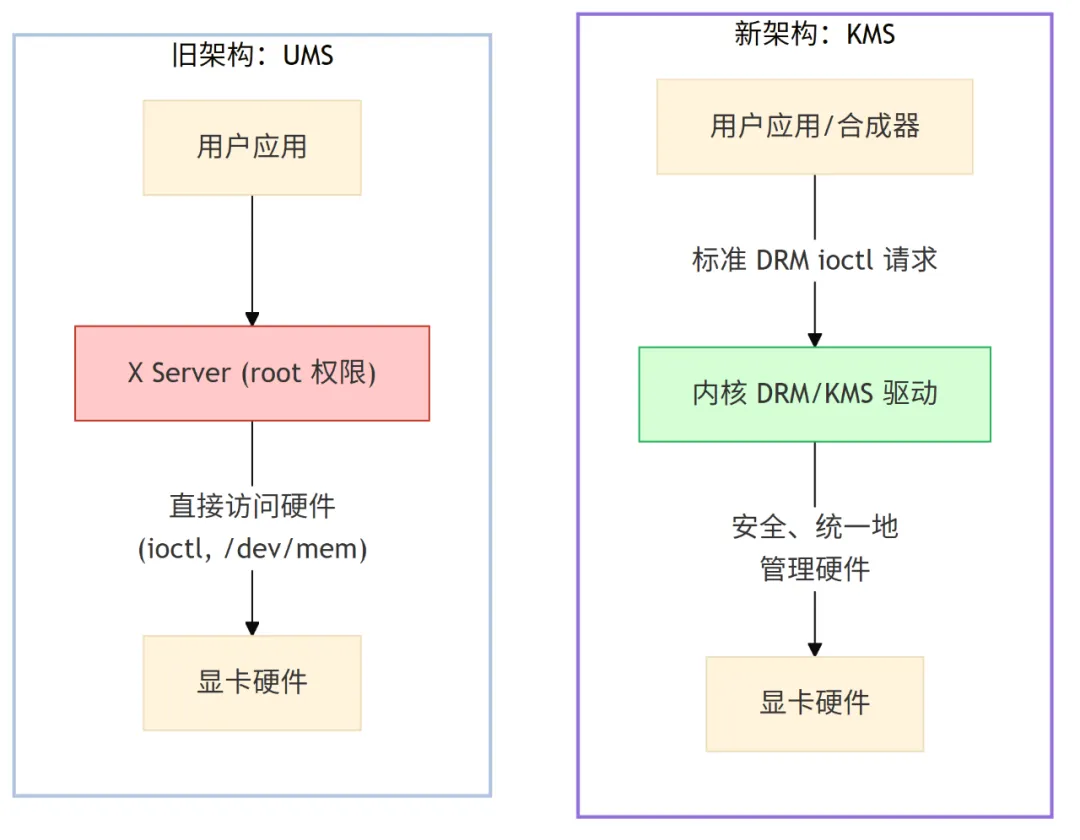
在深入探索 Kernel Mode Setting (KMS) 的技术细节之前,我们有必要先了解它所终结的那个时代——一个由 User-space Mode Setting (UMS) 主导、依赖大量妥协的旧架构。KMS 的出现并非简单的功能增强,而是一场深刻的架构革命,它从根本上重塑了 Linux 图形系统的基石。
在早期,Linux 的图形显示完全由一个在用户空间以 root 权限运行的庞大程序 X Server 所掌控。它绕过内核,直接对显卡硬件进行操作,独揽了设置分辨率、刷新率等所有显示模式的大权。这种 UMS 模式虽然解决了“能否有图形界面”的问题,但其架构上的缺陷也给系统带来了诸多顽疾:
- 稳定性差:一旦
X Server 崩溃,图形界面往往不可用,用户常常需要强制重启。 - 体验不佳:在系统启动过程中,显示控制权会从内核
fbdev 直接切换到 X Server,这种非平滑的过渡常常导致屏幕闪烁。 - 安全隐患:一个庞大且复杂的应用程序以最高权限运行,并且需要访问底层设备节点,蕴藏着巨大的安全风险。
- 权责混乱:内核与用户空间在显示控制上界限模糊,使得虚拟终端(TTY)切换等功能复杂且不可靠。
为了解决这些问题,Kernel Mode Setting (KMS) 应运而生。其核心思想是:将最底层、最核心的显示模式设置功能,统一收归到内核的 DRM(Direct Rendering Manager) 驱动中管理。
这场变革带来了显著的好处:
- 稳定可靠:内核成为显示状态的唯一管理者和最终仲裁者。即使用户态图形服务崩溃,内核仍能将显示切换回基本的文本控制台,保障系统可用性。
- 流畅无缝:从系统启动早期,内核就能直接将显示器设置到最佳分辨率。启动画面与图形桌面环境之间的过渡自然流畅,彻底消除了恼人的闪烁。
- 安全加固:用户态程序无需再以
root 权限直接操作硬件,只需通过 DRM 提供的标准 ioctl 接口发出请求,显著降低了系统的攻击面。
简而言之,KMS 将显示控制的权力从用户空间收归内核,为上层应用提供了稳定、安全、统一的接口,并为 Wayland、现代桌面环境以及高效的多媒体管线奠定了坚实的基础。
KMS 是 DRM 的一部分,负责在内核中配置显示硬件的模式(分辨率、刷新率、时序)和输出状态,并驱动显示管线(planes、CRTC、encoder、connector、panel)。
显示管线通常涉及多个硬件单元(如 GPU 渲染输出、硬件合成模块、Overlay/Planes、缩放器、CRTC、Encoder、Panel),具体实现依赖于不同的 SoC 或显卡架构。它既要保证性能(低延迟、低拷贝),又要保证一致性(避免撕裂),并遵循硬件功能和带宽约束。
在更完整的系统层面,KMS 还需与内存管理(GEM/TTM)、跨设备缓冲共享(DMA-BUF)、同步机制(fence、VBlank)协作,并在某些平台依赖 IOMMU 进行地址映射和隔离。
KMS 与显示管线的角色定位
- KMS:将“设置显示模式”的责任从用户空间移入内核,由内核保证对显示硬件进行统一、原子(atomic)、安全的状态切换。它避免了用户态竞态问题,支持原子化无缝切换,提供统一驱动接口,并能在 DRM master 与其他客户端之间实现合理的资源管理。
- 显示管线:负责将渲染出的像素最终交付到面板(或外部显示器)上,并在过程中根据硬件能力完成缩放、颜色空间转换、叠加(overlay)、去隔行(deinterlace)、亮度与色彩管理等操作。
2. 硬件抽象与显示管线
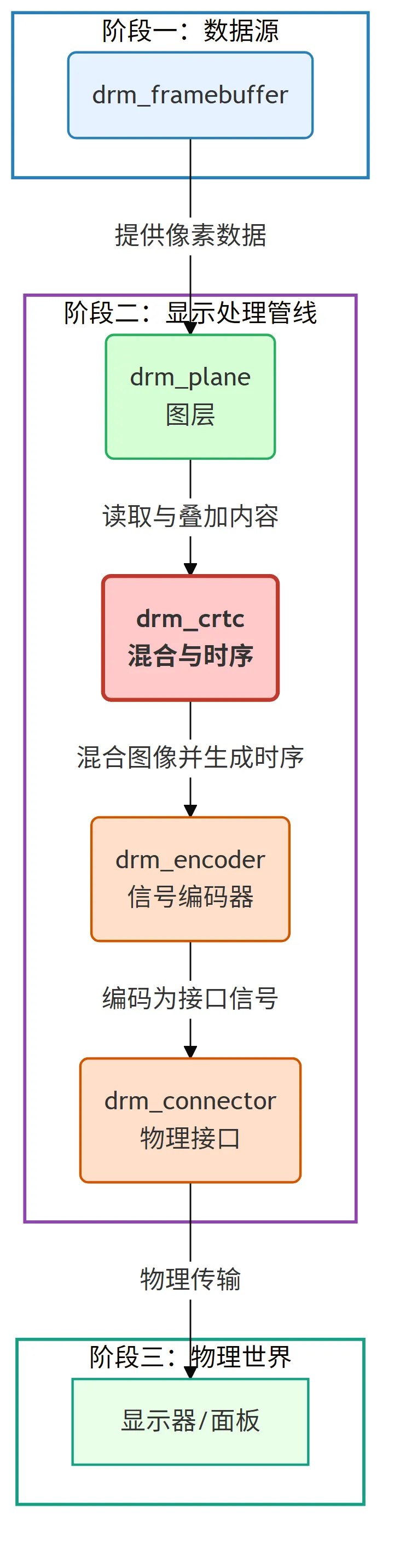
KMS 的核心价值在于:它把形态各异、复杂多变的显示硬件,通过一套统一的软件抽象建模为标准化的逻辑对象。这些对象相互协作,形成了一条从内存中的像素数据流向屏幕的“像素流水线”。理解这条流水线及其每一个“工位”,是掌握 KMS 的第一步。
2.1 像素的旅程
可以把像素的生命周期想象成一次旅行:它最初由 CPU 或 GPU 生成,存放在系统内存中;它的终点,是显示面板上某个发光单元。KMS 的职责,就是管理并规范这段旅程经过的每一个环节。
像素的旅程
下面我们逐一认识这条流水线上的核心组件。
2.2 drm_framebuffer
在 DRM 的世界里,一块通过 GEM 管理的内存(drm_gem_object)本身是“沉默”的,它只是一块未解释的二进制像素数据。drm_framebuffer 的使命,就是为这块内存赋予图像的意义。
drm_framebuffer 本质上是一个元数据容器,它引用一个或多个 drm_gem_object,并附加以下关键信息:
- 尺寸 (Width & Height):图像的宽度与高度,单位为像素。
- 像素格式 (Pixel Format):描述像素的编码方式,以唯一的
FourCC 标识。例如 DRM_FORMAT_ARGB8888、DRM_FORMAT_NV12。 - 内存布局 (Layout):包括
pitch(行跨距)和 modifier(平铺、压缩等特殊布局修饰符)。
用户空间程序通过 DRM_IOCTL_MODE_ADDFB2ioctl 来创建一个 drm_framebuffer。该调用不会复制像素数据,而是返回一个 framebuffer id,用户空间可以在后续操作中通过这个 id 进行绑定。
2.3 drm_plane
drm_plane(图层/平面)是显示管线中第一个真正处理像素的环节,相当于一个“内容拾取器”,从 drm_framebuffer 中读取像素数据并交给后续环节。现代显示硬件通常支持多个 Plane,类似 Photoshop 的图层,可以相互叠加。KMS 将它们分为三类:
- 主图层 (Primary Plane):覆盖全屏的基础图层,每个
CRTC 必须绑定一个。它通常用于显示最底层内容,如桌面背景。某些硬件可能没有真正可见的 Primary Plane,仅依赖 Overlay,此时驱动会创建一个 dummy primary(虚拟/不可见的 Primary Plane)以满足框架要求。 - 叠加图层 (Overlay Plane):支持硬件加速,用于视频播放或其他叠加内容。解码后的帧可以直接交给 Overlay Plane,由显示硬件自动完成色彩空间转换和叠加,实现高效“零拷贝”播放。
- 光标图层 (Cursor Plane):小尺寸图层,专门用于显示鼠标指针,可独立、高效移动,实现流畅动画。
每个 Plane 都拥有一系列可配置的属性,如源/目标矩形(用于裁剪和缩放)、Z 序 (Z-Position)、透明度 (Alpha Blending) 和旋转 (Rotation) 等。每个 CRTC 只能绑定一个 Primary Plane,但可以绑定多个 Overlay Plane 和一个 Cursor Plane。硬件通常按照 “1 Primary + N Overlay + 1 Cursor” 的模式设计,DRM/KMS 框架也基于这一假设进行管理。
2.4 drm_crtc
drm_crtc(CRT Controller,历史遗留名称)是整条流水线的核心调度者,主要承担两大任务:
- 画面混合 (Compositing):
CRTC 负责接收一个或多个 Plane 的像素流,并根据它们的属性(Z 序、位置、透明度等),将它们精确地混合(Composite)成一帧完整的、最终的画面。 - 时序生成 (Timing Generation):这是
CRTC 最本质的功能。它根据 drm_display_mode 结构体,生成驱动显示器刷新所需的一系列精确的电气时序信号,包括分辨率、刷新率、像素时钟(Pixel Clock)以及水平/垂直同步信号(HSync/VSync)等所有关键参数。它就像一个节拍器,严格控制像素扫描与刷新节奏。
CRTC 负责生成像素级时序,但最终的电气信号还需交由 drm_encoder 转换。
2.5 drm_encoder
不同的物理接口需要不同格式的电气信号。drm_encoder (编码器) 的角色,就是一位专业的“信号翻译官”。它接收来自 CRTC 的通用像素流,并将其编码成特定接口所能理解的专用信号格式。例如:
2.6 drm_connector
drm_connector 代表真实的物理输出端口,例如 HDMI-A-1 或 DP-1。它承担与外部显示设备的交互:
- 状态检测 (Connection Status):通过热插拔检测 (
Hot-Plug Detect, HPD) 机制,感知是否有显示器连接或断开,并通知用户空间。 - 能力探测 (Capability Probing):当一个显示器被连接上时,
Connector 会通过 DDC 通道的 I2C 总线读取显示器的 EDID (Extended Display Identification Data)。EDID 像显示器的“身份证”,详细记录了其支持的所有显示模式、制造商信息等。内核解析 EDID 后,会生成一个模式列表,供用户空间选择。 - 面板驱动 (Panel Driver):对于内嵌显示器(如笔记本屏幕或手机屏幕),
Connector 会与专门的面板驱动紧密协作,完成对面板的上电、初始化和背光控制等操作。
通过 Plane → CRTC → Encoder → Connector 的流水线,KMS 将差异巨大的硬件行为统一抽象成一致的软件模型。用户空间无需关心底层硬件的复杂性,只需通过标准接口进行控制。
3. Atomic Modesetting
在 KMS 的演进历程中,没有什么比原子化模式设置 (Atomic Modesetting) 的引入更具革命性了。它彻底改变了用户空间与内核交互的方式,将显示状态的更新从一系列零散、脆弱的操作,升华为一种严谨、可靠的事务性过程。要理解原子化的威力,我们首先要回顾它所取代的“旧世界”——Legacy API。
3.1 Legacy API 的局限性与历史背景
早期的 KMS 提供了一系列独立的 ioctl 调用来控制显示管线的各个部分,这套 API 现在被称为 Legacy API。例如,用户需要通过 drmModeSetCrtc() 来设置显示模式,再通过 drmModeSetPlane() 来配置图层。
这种“一次只做一件事”的 API 设计,在简单的单显示器、单图层场景下尚可应付。但随着显示场景变得日益复杂,其内在的缺陷暴露无遗:
- 缺乏原子性:当一次显示更新需要修改多个对象时(例如,将主显示器从 1080p 切换到 4K,同时将一个视频
Plane 移动到屏幕另一侧),这需要两次独立的 ioctl 调用。如果第一次 drmModeSetCrtc 成功后,第二次 drmModeSetPlane 因资源不足而失败,系统就会进入一个不一致的中间状态:屏幕分辨率变了,但视频层却留在了错误的位置,从而导致画面错乱或闪烁。 - 验证与执行耦合:
Legacy API 的合法性检查与硬件状态的修改是紧密耦合的。上层应用无法“预知”一个操作是否会成功,只能冒险尝试。这让编写健壮的显示管理程序(如 Compositor)变得异常困难,充满了大量的试错和状态回滚逻辑。
这些与生俱来的缺陷,使得 Legacy API 在面对现代多图层、多显示器的复杂需求时力不从心,一场彻底的变革势在必行。
3.2 设计理念与核心原则
Atomic Modesetting API 的设计,正是为了根除 Legacy API 的所有弊病。它的核心理念源自数据库领域的事务 (Transaction) 思想,将一次完整的显示状态变更,视为一个不可分割的事务。
- 批处理与原子性:所有期望的显示状态变更,无论涉及到多少个
Plane、CRTC 或 Connector,都必须被打包在一个单一的请求中,一次性提交给内核。内核承诺,对于这个请求,要么完整地成功应用所有变更,要么在任何一个环节验证失败时,完全不应用任何变更,绝不允许任何不一致的中间状态出现。 - 基于属性的模型:在原子化模型中,所有 KMS 对象(
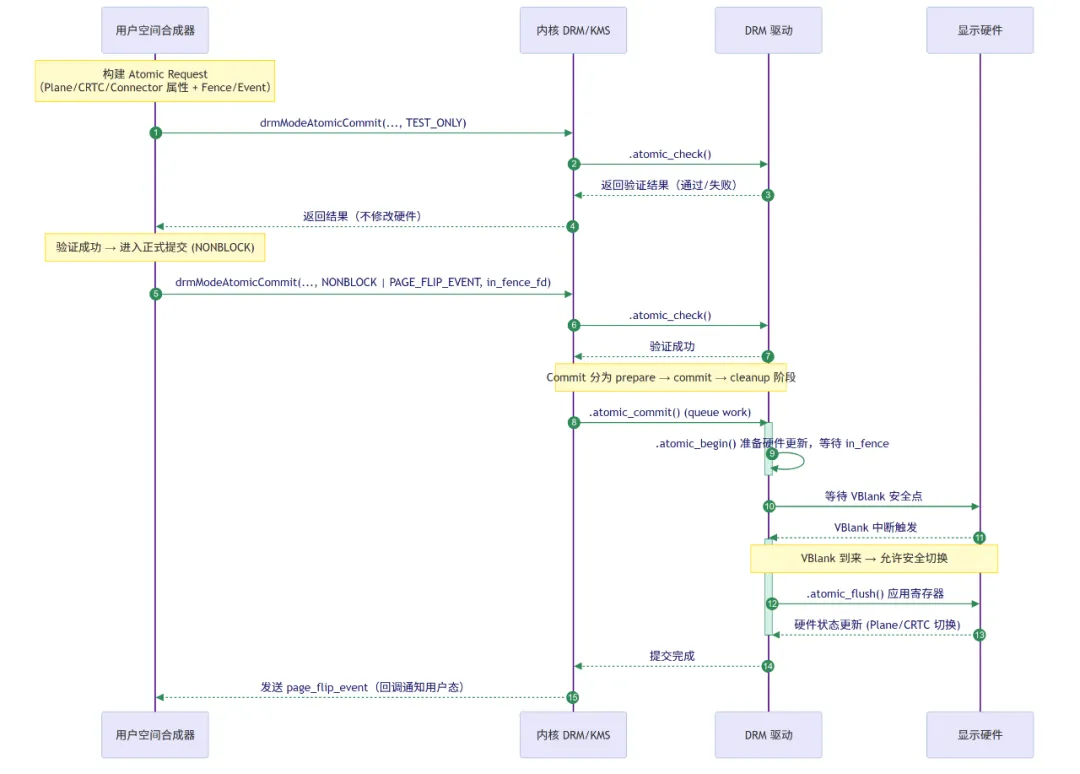
CRTC, Plane等)的状态都由一组标准化的属性 (Property) 来描述。一次模式设置,本质上就是对这些属性值的一次批量更新。用户空间程序在初始化时,必须先向驱动查询所有对象支持的属性及其 ID,然后在后续的请求中通过 ID 来修改属性值。 - 验证与执行分离:这是原子化 API 最精妙的设计。它将状态更新的过程,清晰地划分为两个阶段:验证 (
Check/Test) 和提交 (Commit/Execute)。
3.3 原子化提交机制与两阶段模型
原子化 API 的强大之处,在它安全的两阶段提交流程中体现得淋漓尽致。
3.3.1 测试阶段(Test-Only Commit)
用户空间程序可以先给它的原子化请求打上 DRM_MODE_ATOMIC_TEST_ONLY 的旗标,然后提交给内核。
内核收到这个请求后,会完整地走一遍验证流程,调用驱动的 .atomic_check() 回调。在这个回调中,驱动会进行一次全面的“沙盘推演”,但绝对不会去触碰任何硬件寄存器。它会严谨地检查所有硬件相关的约束,例如:
- 资源核算:检查请求的模式对时钟、内存带宽、显示 FIFO 的需求是否在硬件承载范围之内。
- 能力匹配:检查
Plane 是否支持所请求的像素格式和 modifier,以及缩放比例是否在其硬件能力范围之内。 - 连接拓扑:检查
CRTC、Encoder 和 Connector 的连接关系是否有效。
如果任何一项检查失败,内核会立即中止并向上层返回错误。如果所有检查都通过,则返回成功。这个阶段给了上层应用一种前所未有的能力——无风险地预知一个复杂的状态变更是否可行。
3.3.2 执行阶段(Real Commit)
一旦测试提交成功,用户空间就可以移除 TEST_ONLY 旗标,将完全相同的请求再次发送给内核。
内核收到正式提交请求后,会再次完整地执行一遍验证流程(以防状态被其他进程改变)。只有在第二次验证也通过后,内核才会调用驱动的 .atomic_commit() 回调。在这个回调中,驱动会执行真正的硬件操作,通常会将所有硬件寄存器的更新,都精确地调度在下一次垂直消隐 (VBlank) 期间,一次性地、同步地应用下去,从而保证无缝切换。
值得注意的是,.atomic_commit() 的实现一般是异步的:驱动会先安排更新计划,然后在 VBlank 中断到来时才真正写入寄存器,并通过事件回调 (page_flip_event) 通知用户空间。这种机制避免了直接阻塞,提高了实时性和流畅性。
3.3.3 与同步机制的融合
原子化提交不仅处理模式设置,还深度集成了同步机制。一个原子化请求可以包含一个 in-fence 文件描述符。这意味着 KMS 驱动在执行此次提交(特别是页面翻转)之前,必须等待这个 in-fence 被触发 (signal)。这通常用于确保 GPU 已经完成了对 framebuffer 的渲染,之后显示硬件才能安全地读取它,这是实现生产者-消费者同步、避免渲染未完成内容的关键。
原子化提交
3.4 内核实现与用户空间接口实践
为了管理这个流程,内核引入了 struct drm_atomic_state 对象,它像一个“购物车”,封装了本次事务中所有 KMS 对象的目标状态(如 drm_crtc_state、drm_plane_state 等)。这个对象同时持有新旧两种状态,便于驱动计算差异和执行更新。
在用户空间,开发者通过 libdrm 库来构建和提交原子化请求。下面是一段简化的示例代码,它直观地展示了 API 的使用方式:
#include<xf86drmMode.h>// 假设 fd, crtc_id, plane_id, fb_id, mode_blob_id 等都已获取// 假设 property_active_id, property_mode_id, property_fb_id 等属性 ID 也已查询并缓存// 属性 ID 对应属性名称,是性能优化重点。提前查询并缓存,避免每次提交时重复查询。voidatomic_modeset_example(int fd, uint32_t crtc_id, uint32_t plane_id,uint32_t fb_id, uint32_t mode_blob_id){// 1. 分配一个原子化请求对象 drmModeAtomicReq *req = drmModeAtomicAlloc();if (!req) return;// 2. 向请求中添加属性变更 drmModeAtomicAddProperty(req, crtc_id, property_active_id, 1); drmModeAtomicAddProperty(req, crtc_id, property_mode_id, mode_blob_id); drmModeAtomicAddProperty(req, plane_id, property_fb_id, fb_id);// ... 还可以继续设置 Plane 的 SRC/CRTC 坐标等属性// 3. 测试提交:仅检查可行性,不改变硬件状态int ret = drmModeAtomicCommit(fd, req, DRM_MODE_ATOMIC_TEST_ONLY, NULL);if (ret < 0) {// 测试失败,不能提交 drmModeAtomicFree(req);return; }// 4. 正式提交:请求非阻塞执行,并在完成后触发事件uint32_t flags = DRM_MODE_ATOMIC_NONBLOCK | DRM_MODE_ATOMIC_PAGE_FLIP_EVENT; ret = drmModeAtomicCommit(fd, req, flags, NULL/* userdata */);if (ret < 0) {// 提交失败,根据 errno 判断原因 }// 5. 释放请求对象 drmModeAtomicFree(req);// 后续可通过 poll/select 监听 fd 上的事件,以确认页面翻转完成}
在这段代码中,TEST_ONLY 和正式 COMMIT 的配合,完整地体现了原子化 API 的事务性和安全性。
3.5 小结
Atomic Modesetting 是 KMS 从一个简单的模式设置工具,演变为一个精密、健壮的显示控制框架的里程碑。它不仅解决了历史遗留的技术难题,更为 Wayland 合成器、复杂的硬件合成策略以及未来更高要求的显示场景,提供了坚实、可靠的科学基础。
4. KMS 驱动实现
4.1 DRM 驱动入口
在 DRM(Direct Rendering Manager)框架中,每一个显卡驱动的核心,都是一个静态定义的 struct drm_driver 实例。它并不是某个硬件设备的直接描述,而更像是一个“驱动模板”,里面包含了一系列函数指针(回调 hooks)和驱动元数据。
这些回调函数代表了驱动对 DRM 框架的承诺:
- 当框架需要创建一个缓冲区时,它会调用驱动在
drm_driver 中填好的 .gem_create。 - 当用户空间发来一个
ioctl 请求,核心层会根据请求号跳转到 .ioctls 表里对应的函数。 - 当涉及到模式设置(KMS)时,核心会进入驱动注册的
.atomic_check 和 .atomic_commit。
换句话说,drm_driver 是一个 操作向量表,把通用的 DRM 框架逻辑和具体厂商的硬件实现连接起来。驱动开发者需要在这个结构中填充回调,把自己的硬件特性嵌入到通用框架中。
一个最简化的驱动入口大概长这样:
staticstructdrm_drivermy_drm_driver = { .driver_features = DRIVER_MODESET | DRIVER_GEM | DRIVER_ATOMIC, .fops = &my_drm_fops, .name = "mygpu", .desc = "My GPU DRM Driver", .date = "20250910", .major = 1, .minor = 0, .ioctls = my_ioctls, .gem_create_object = my_gem_create,};
这里最关键的字段是 driver_features,它声明了驱动支持的功能:
DRIVER_MODESET:支持显示模式设置(KMS),否则就是纯渲染设备。
没有这些标记,DRM 框架甚至不会把对应的 ioctl 下发给驱动。
4.2 初始化流程
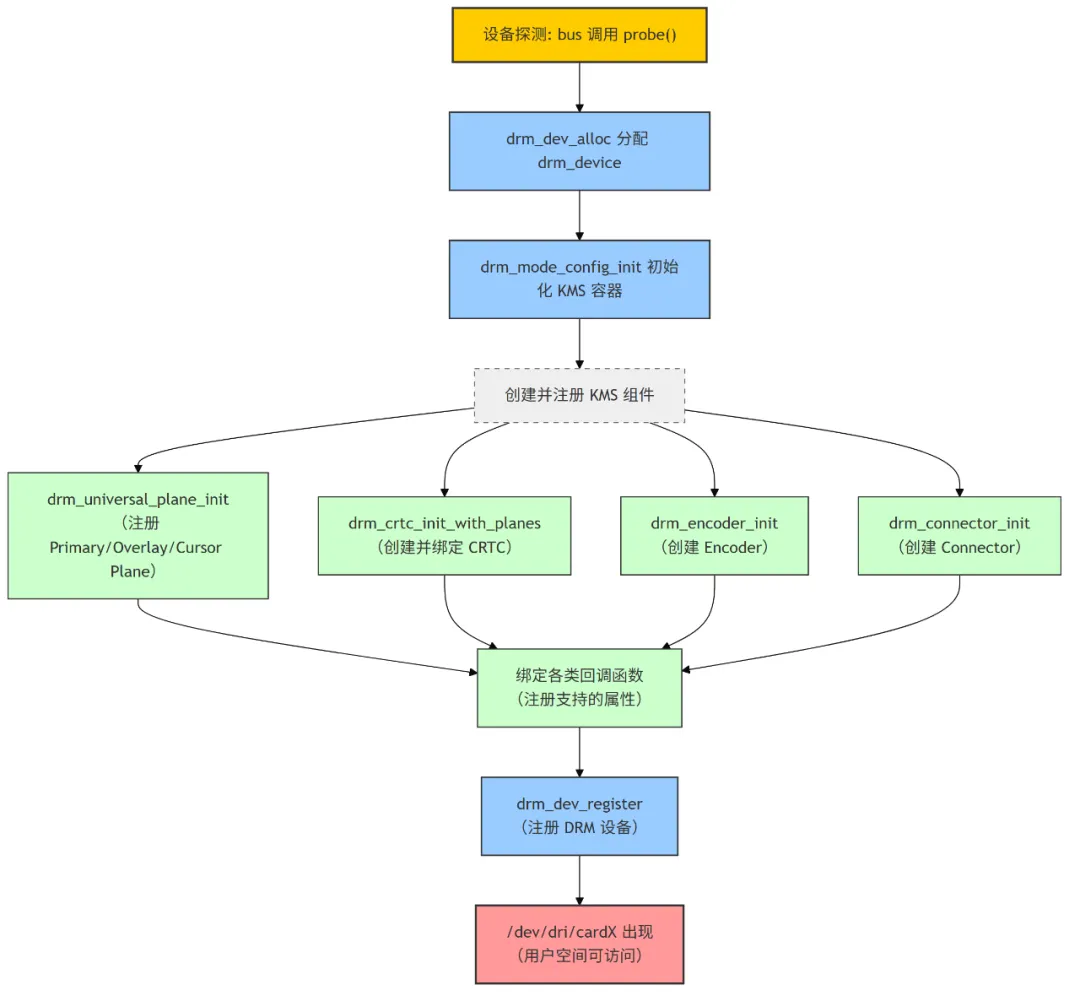
当系统探测到一个显示硬件(比如 PCI 总线上的显卡,或者 SoC 内的 LCD 控制器),内核会调用该驱动的 probe 函数。KMS 初始化的核心步骤如下:
4.2.1 分配 DRM 核心对象
调用 drm_dev_alloc() 创建一个 struct drm_device 实例,它代表一个真实的物理 GPU/显示控制器。这个对象会贯穿整个驱动生命周期。
structdrm_device *dev;dev = drm_dev_alloc(&my_drm_driver, &pdev->dev);
此时,dev 是一个空壳,后续的所有 KMS 组件都会挂接到它下面。
4.2.2 初始化 KMS 配置
drm_mode_config_init(dev);
调用 drm_mode_config_init() 来初始化 drm_device 内部的 drm_mode_config 结构,相当于在 drm_device 中准备一个 mode_config 容器,所有的 CRTC、Plane、Encoder、Connector 都会放在这里,成为 DRM KMS 的资源集合。
4.2.3 创建并注册 KMS 组件
驱动需要按照硬件拓扑,把显示管线的元素一个个创建出来:
- Plane:调用
drm_universal_plane_init() 注册,分为 Primary、Overlay、Cursor 三类。 - CRTC:调用
drm_crtc_init_with_planes() 创建,并绑定一个或多个 Plane。 - Encoder:调用
drm_encoder_init(),代表硬件的信号编码器(LVDS、HDMI、DP)。 - Connector:调用
drm_connector_init(),对应外部可见的物理接口。
在注册的同时,还需要绑定各自的操作函数(drm_crtc_funcs、drm_plane_funcs 等),并声明支持的属性(像素格式、修饰符(modifier)、缩放因子等)。
4.2.4 注册 DRM 设备
最后调用 drm_dev_register(dev, flags),把设备暴露给用户空间。此时 /dev/dri/cardX 和 /dev/dri/controlDX 节点会出现,Xorg、Wayland Compositor 或 modetest 工具就能访问驱动了。
DRM 设备注册
4.3 实现原子化核心
在现代 DRM 驱动中,最关键的部分就是原子模式设置(atomic modesetting)。它保证用户空间提交的一组状态(多个 Plane/CRTC/Connector)要么同时生效,要么全部失败,避免出现“撕裂”或不一致的情况。
驱动必须实现两个核心回调:atomic_check() 和 atomic_commit()。
4.3.1 atomic_check()
这是驱动的“大脑”。当用户空间发来一个原子请求(例如,把两个 Plane 合成到一个 CRTC 上),DRM 核心会把请求转化为一个 drm_atomic_state,并调用驱动的 .atomic_check()。
驱动需要在这里检查所有硬件约束:
- 分辨率限制:Plane 的源/目标矩形是否超出硬件支持范围。
- 带宽预算:多个 Plane 同时工作时,显存带宽是否足够。
- 时钟域/PLL 约束:CRTC 的像素时钟是否在可编程范围内。
- 交叉依赖:某些 Encoder 不能和特定 CRTC 组合。
如果任何条件不满足,必须返回 -EINVAL 或 -ENOMEM,原子请求就会失败。
4.3.2 atomic_commit()
验证通过后,DRM 核心会调用 .atomic_commit() 来应用状态。常见实现分两步:
- 排队:把即将写入寄存器的更新封装成一个任务,放入工作队列。
- 应用:在下一个
VBlank 中断时,安全地写寄存器,更新 Plane 地址、stride、像素格式,更新 CRTC 时序等。
这种方式保证屏幕只会在刷新边界切换,避免撕裂和花屏。
4.3.3 helper 助手函数
编写 .atomic_check 和 .atomic_commit 是非常繁琐的,Linux 提供了一组 atomic helpers:
drm_atomic_helper_check():检查标准的属性约束。drm_atomic_helper_commit():自动帮你分阶段调用 prepare_fb、commit_planes 等。drm_atomic_helper_wait_for_vblanks():等待所有更新完成。
DRM 驱动通常只需要在回调中调用这些 helper,然后在关键地方加上自己的硬件操作即可。
4.4 实战要点
- 电源管理:CRTC、Encoder、PLL 可能在不同电源域,切换状态时要小心启停。
- 中断处理:VBlank、Hotplug、错误中断,都要在 ISR 中反馈给 DRM 核心。
- GEM/缓冲区管理:在 commit 之前,必须确保 framebuffer 已经被
pin 到物理显存或 IOMMU 映射。 - 同步 Fence:Overlay Plane 经常和视频解码器协作,需要通过
dma_fence 确保缓冲区写完再显示。 - 多显示器支持:CRTC、Encoder、Connector 的组合可能非常复杂(比如 DP-MST),atomic 框架能很好地统一描述。
5. 图形合成机制
在现代图形桌面系统中,用户最终看到的画面远比一张静态图像复杂得多。它通常由数十甚至上百个独立的视觉元素动态构成:窗口、菜单、面板、光标以及视频流等。这些元素需要被整合为统一的最终画面,这一过程被称为合成 (Composition)。
合成在哪里发生?由谁来完成?这是决定图形系统性能、功耗和灵活性的核心问题。KMS 通过其 Plane 模型,为系统提供了两种强大的合成策略:GPU 合成和硬件合成 (DPU 合成)。现代合成器 (Compositor) 的任务之一,就是如何根据场景和硬件能力,在这两者之间做出最佳的选择。
5.1 GPU 合成
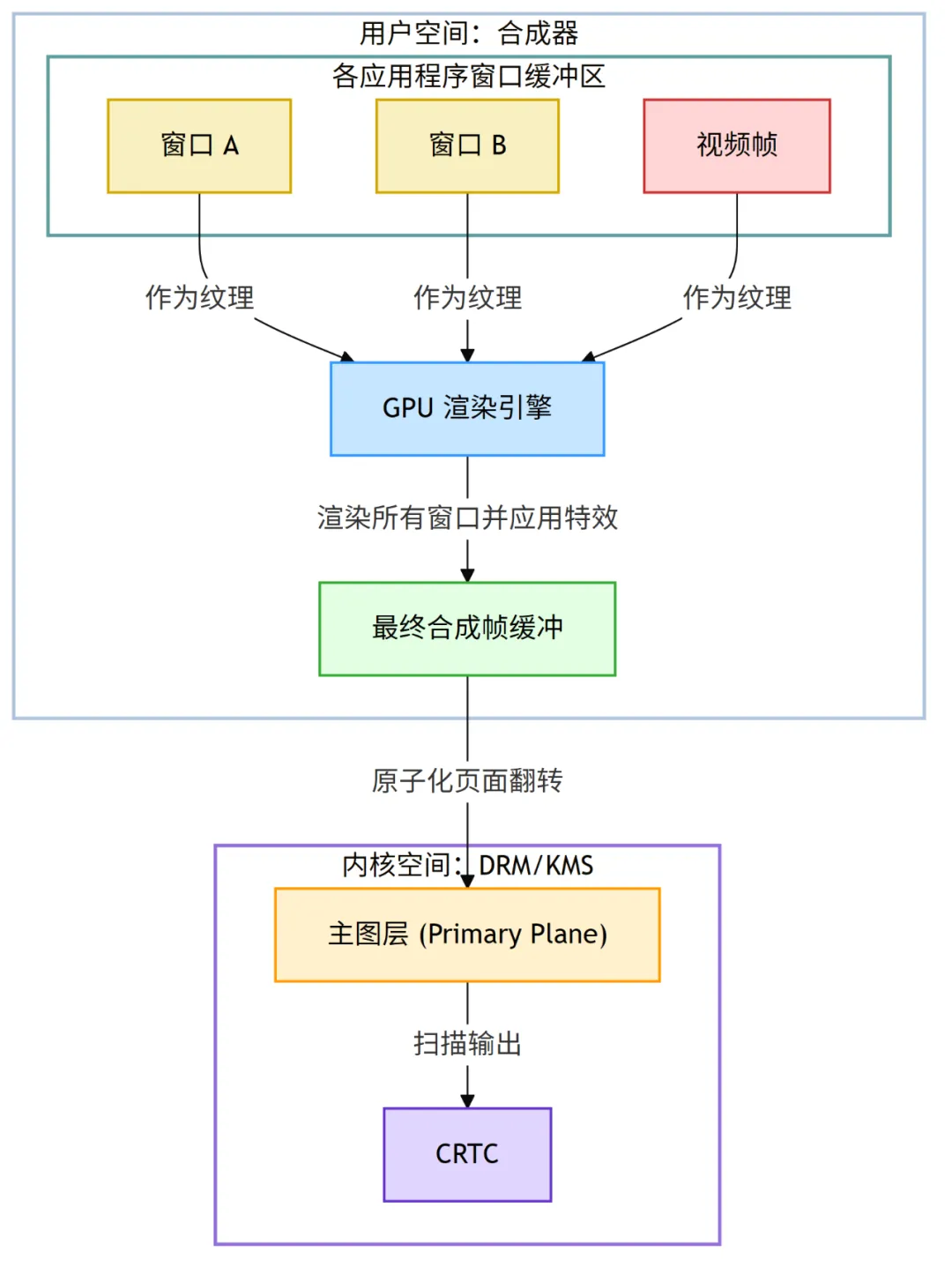
GPU 合成是当前最通用、应用最广泛的合成方式,其典型工作流程如下:
- 窗口即纹理:对于合成器来说,屏幕上的每一个窗口都是一块独立的内存缓冲区。合成器将这些缓冲区作为纹理 (Texture) 上传到 GPU。
- GPU 渲染:合成器扮演着一个特殊的 3D 应用程序的角色。在每一帧,它都会命令 GPU 将所有窗口的纹理,按照正确的堆叠顺序和位置,绘制到一个临时的、屏幕大小的后台缓冲区 (
Back Buffer) 上。 - 最终呈现:当所有窗口都被绘制完毕后,这个包含了完整桌面场景的后台缓冲区,就成了一个最终的合成品。合成器会为这个缓冲区创建一个
drm_framebuffer,并通过一次原子化的页面翻转,将其提交给 DRM 驱动的主图层 (Primary Plane) 进行显示。
优势:
- 灵活性极高:GPU 可处理几乎无限数量的图层,支持透明、模糊、动画等丰富的视觉效果。
劣势:
- 性能开销大:GPU 需额外参与合成,增加内存带宽和计算负担。
- 功耗较高:持续 GPU 活动导致能耗上升,尤其在移动终端影响显著。
5.2 硬件合成
硬件合成(又称硬件叠加,Hardware Overlay)遵循截然不同的理念。它依赖显示控制器(通常称为 DPU, Display Processing Unit)内部的多 Plane 单元,将合成过程尽量转移至专用硬件,以绕开 GPU。
工作流程如下:
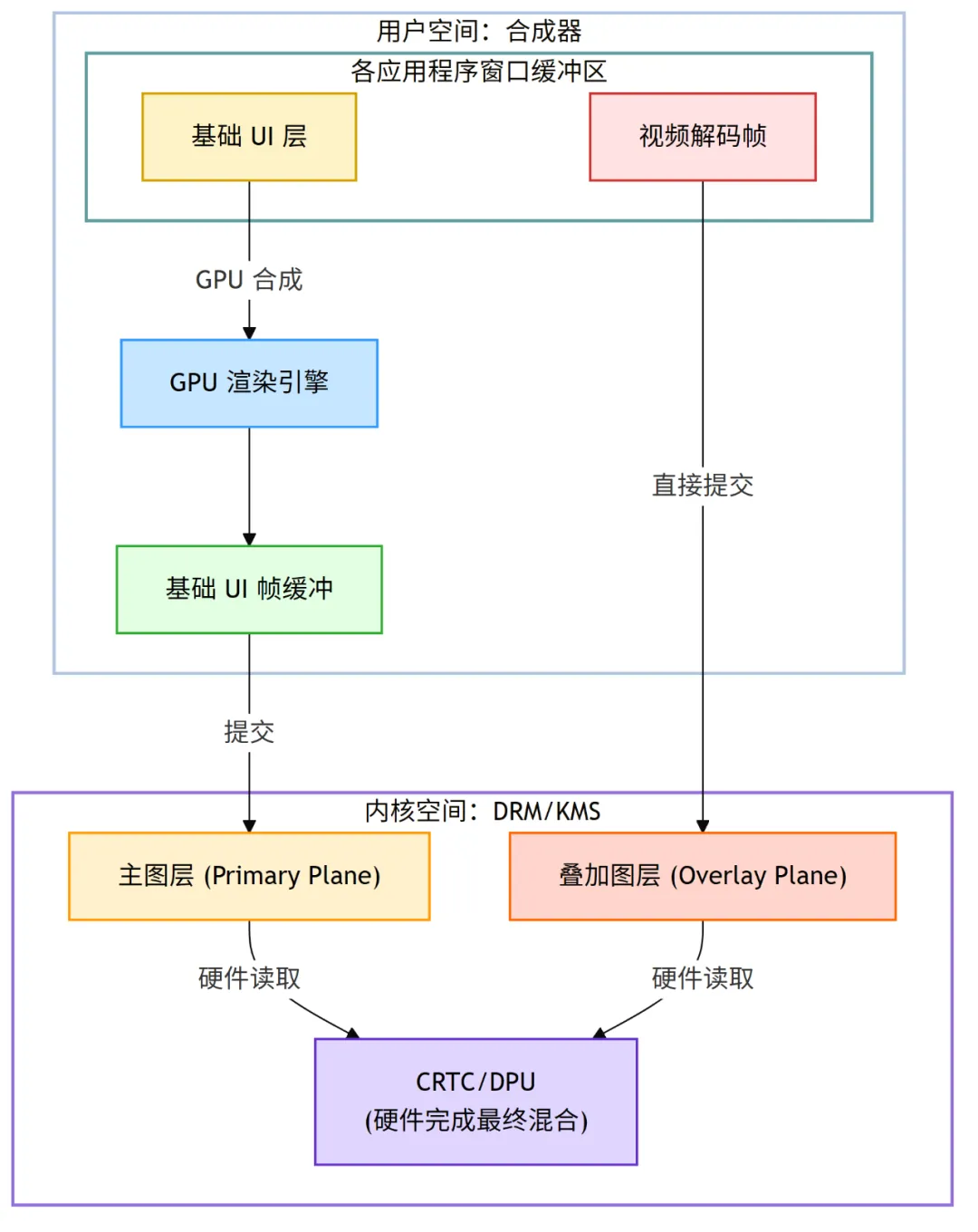
- 智能调度:合成器分析当前的场景,识别出最适合用独立
Plane 来处理的“特殊”图层。 - 对于正在播放的视频,合成器会直接将视频解码器输出的
drm_framebuffer 提交给一个叠加图层 (Overlay Plane)。 - 对于鼠标指针,它会被提交给专用的光标图层 (Cursor Plane)。
- 对于其他普通的 UI 元素,合成器可能仍然会使用 GPU 将它们合成到一个基础层,并提交给主图层 (Primary Plane)。
- 硬件混合:合成器通过一次原子化提交,将这多个
Plane 的信息一次性告知 KMS。显示硬件 (DPU) 会在内部实时地、自动地完成图层的读取、色彩空间转换、缩放和最终的混合。
优势:
- 低延迟、低功耗:数据路径短,避免拷贝,实现真正的零拷贝(zero-copy)。
劣势:
- 资源有限:
Plane 数量固定,通常只有 3-4 个,不足以覆盖所有窗口。 - 功能受限:不同
Plane 对像素格式、缩放范围等能力各不相同,限制了其使用场景。
5.3 混合策略
面对两种各有千秋的策略,现代合成器(如 Wayland)并不会单纯依赖 GPU 或硬件合成,而是采用了一种动态的、智能的混合策略。合成器会持续地分析屏幕场景,并尝试最大化地利用硬件 Plane。它的决策逻辑通常是:
- 优先使用硬件合成:视频流、光标等场景适合交由硬件
Plane 进行合成。 - 剩余部分由 GPU 合成:普通窗口通过 GPU 渲染整合至主
Plane。
为了保证正确性与稳定性,合成器会先构造一个最优的合成方案,并通过 DRM_MODE_ATOMIC_TEST_ONLY 提交方式向内核进行“试运行”。
- 若方案失败:例如硬件
Plane 不支持某格式,系统会优雅回退(fallback)到 GPU 合成路径。
通过这一“规划—测试—提交/回退”的循环机制,现代 Linux 桌面系统能够在性能、能耗与视觉效果之间,持续维持动态最优平衡。
6. 像素格式、修饰符与内存布局
为了让显示硬件能够正确读取并呈现 drm_framebuffer 中的数据,它必须理解这块显存的数据编码与排列,具体由三个核心要素构成:像素格式(Pixel Format)、内存布局(Memory Layout) 与修饰符(Modifier)。三者共同定义了像素数据在内存中的编码方式与排列结构。
6.1 像素格式的编码规则
像素格式定义了如何使用二进制数据来表示一个像素的颜色信息。在 DRM 中,每种格式都由一个唯一的 FourCC (Four-Character Code) 码来标识。
RGB 格式:UI 和通用图形渲染中最常见的格式家族。
DRM_FORMAT_ARGB8888: 每个像素占用 32 位 (4 字节),包含 Alpha (透明度)、红、绿、蓝四个通道,每个通道 8 位。DRM_FORMAT_XRGB8888: 与 ARGB8888 类似,但忽略 Alpha 通道 (X 表示无关),常用于不透明的界面元素。DRM_FORMAT_RGB565: 每个像素占用 16 位 (2 字节),其中红色占 5 位,绿色占 6 位,蓝色占 5 位。它以牺牲色彩精度为代价来节省内存,常见于低功耗的嵌入式设备。
YUV 格式:主要用于视频。人眼对亮度 (Luma, Y) 的敏感度远高于色度 (Chroma, UV),因此 YUV 格式通过将亮度和色度分离存储,并降低色度的分辨率(即“色度半采样”),可以在人眼几乎无法察觉图像质量损失的情况下,大幅节省带宽。
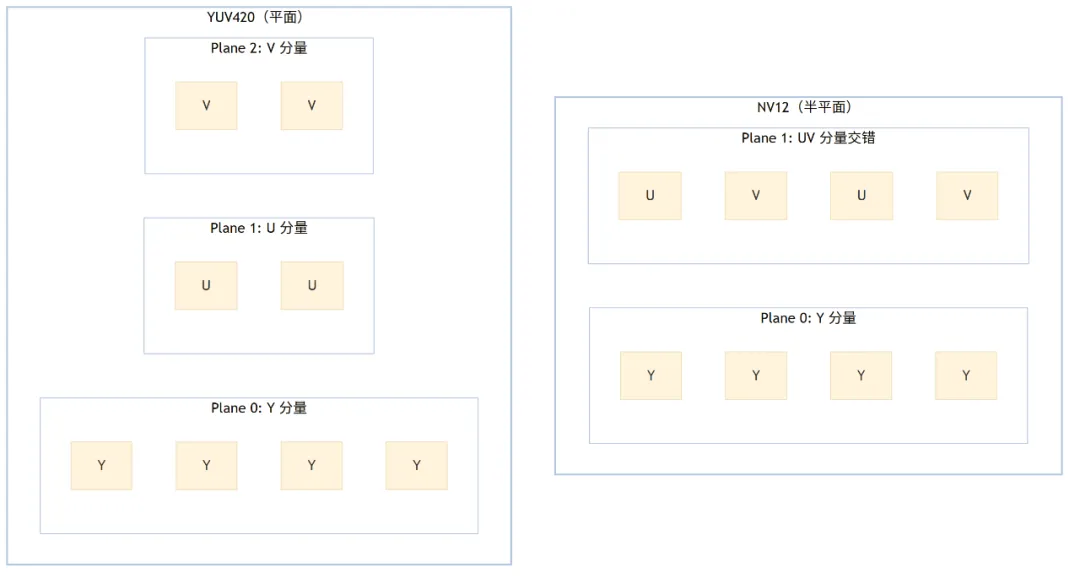
YUV 平面布局有多种,如 4:2:0、4:2:2,半平面和平面是其中两种常见方式:
- 半平面 (Semi-Planar) 格式:如
DRM_FORMAT_NV12,这是最常见的视频格式之一。它将所有像素的 Y 分量连续存储在一个平面 (plane) 中,然后将 U 和 V 分量交错存储在第二个平面中。 - 平面 (Planar) 格式:如
DRM_FORMAT_YUV420,它将 Y、U、V 三个分量分别存储在三个独立的平面中。
YUV 之所以能分平面,是因为它的设计本身就是亮度/色度分离,而 RGB 每个像素都是完整的数据单元,硬件扫描输出时一次读取整像素,拆平面会增加带宽需求且几乎没有收益。
6.2 像素的内存排列
仅仅知道每个像素的格式是不够的,硬件还需要知道这些像素在内存中是如何排列的。
Stride (行跨距):也称 Pitch,它定义了从图像的一行像素的起始位置,到下一行像素起始位置的字节数。这个值不一定等于 宽度 × 每像素字节数。因为许多硬件为了实现内存突发读取或者平铺/压缩布局的兼容,会要求每一行的起始地址都对齐到特定的边界(例如 64 字节或 128 字节)。因此,Stride 通常是大于或等于 宽度 × 每像素字节数 的最小对齐值。驱动在创建 drm_framebuffer 时会计算并返回正确的 Stride。
6.3 修饰符的引入与演进
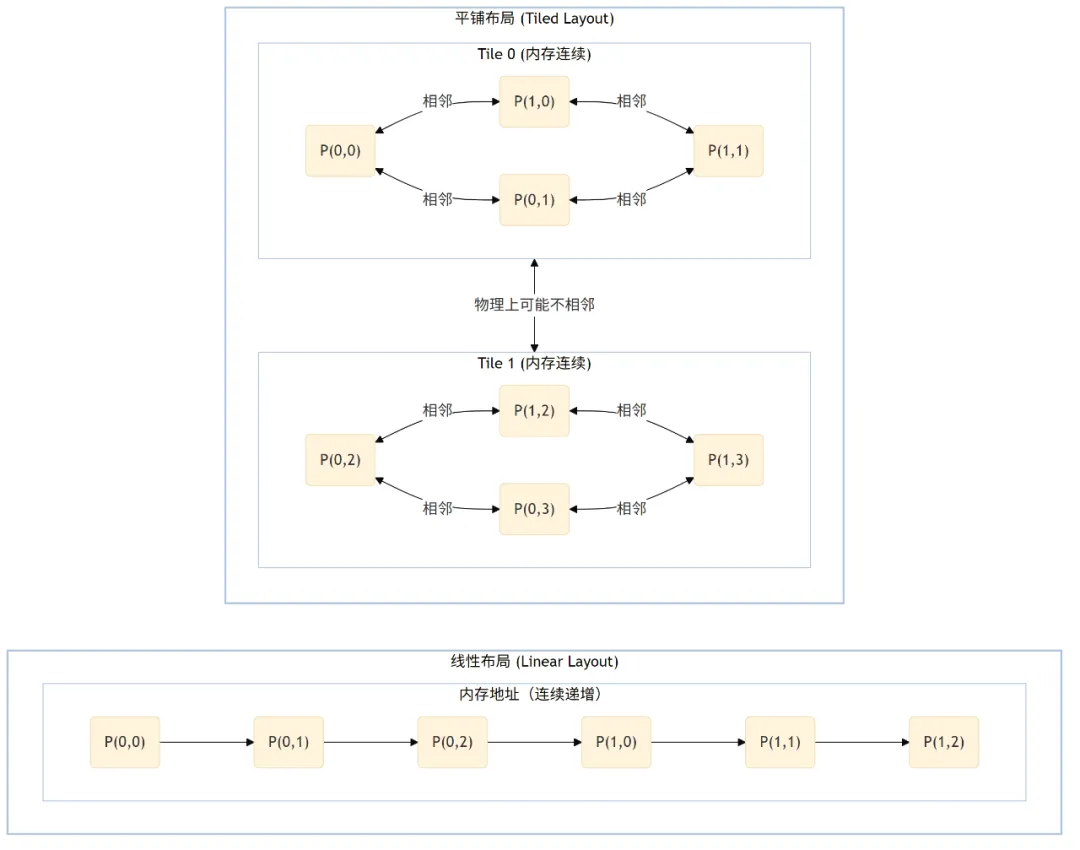
传统上,像素在内存中是按线性 (Linear) 方式存储的:从左到右,从上到下,依次排列,就像我们阅读文本一样。这种布局对 CPU 非常友好,但在 2D 图形处理中效率低下。为了解决这个问题,现代 DRM 引入了一个至关重要的概念——Modifier (修饰符)。
Modifier (DRM_FORMAT_MOD_*) 是一个 64 位的数值,它作为像素格式的扩展,精确地描述了像素在内存中的物理排列方式,例如是线性、平铺还是经过了压缩。
平铺 (Tiling) 布局:与线性布局不同,平铺布局将像素数据组织成一个个小的 2D 块 (tile)。当显示控制器或 GPU 需要读取某个像素时,由于内存的局部性原理,它很可能马上就需要读取其周围的像素。在一个 tile 内,像素及其相邻像素在物理内存中也是相邻的(不同 tile 之间可能存在间隔)。这极大地提升了内存缓存的命中率,显著降低了内存延迟和总线带宽消耗。不同厂商有自己的平铺实现,例如 Intel 的 X-tiling 和 Y-tiling。
压缩 (Compression) 布局:为了进一步降低带宽,特别是在高分辨率 (4K/8K) 场景下,许多 SoC 引入了帧缓冲压缩技术,例如 ARM 的 AFBC (ARM Frame Buffer Compression)。这是一种感知上无损的实时压缩算法,可以在数据写入内存时进行压缩,在硬件读取时实时解压。Modifier 也被用来标识这些压缩格式。
驱动会通过属性 (property) 报告其支持的 Modifier 列表,用户空间(如 Mesa/GBM)在创建缓冲区时可以指定一个 Modifier,从而充分利用硬件的性能优势。但这也带来了新的挑战:平铺或压缩后的缓冲区,其内存布局对于 CPU 来说通常是不可理解的,需要通过 GPU/CPU 映射 API 或解压接口访问,否则直接 mmap 读取会出现乱码。
线性布局 vs 平铺布局
6.4 缓存一致性问题
当 CPU 与 GPU/DPU 等硬件同时访问同一块显存时,必须保证缓存一致性(Cache Coherency)。例如,当 CPU 更新了一块 drm_framebuffer 的内容后,这些更新可能仍停留在 CPU 缓存中,尚未写回主内存。如果此时 DPU 直接去主内存读取,就会读到旧的数据。
为此,DRM 驱动在进行 DMA 操作前后需使用内核 DMA API(如 dma_sync_single_for_device),确保数据在缓存与主存之间正确同步:
- 刷新(flush):将 CPU 缓存中的更新写回主存。
- 失效(invalidate):使 CPU 缓存无效,确保其读取最新的主存内容。
7. 多显示器、热插拔与 MST
现代计算环境早已超越了单屏的限制。开发者、设计师和普通用户都越来越依赖于多显示器带来的广阔工作空间。KMS 从设计之初就充分考虑了这种动态、复杂的现实需求,提供了一套强大而灵活的机制来管理多显示器配置、响应设备的即时插拔,甚至支持 DisplayPort MST 这样的高级特性。
7.1 多显示器配置
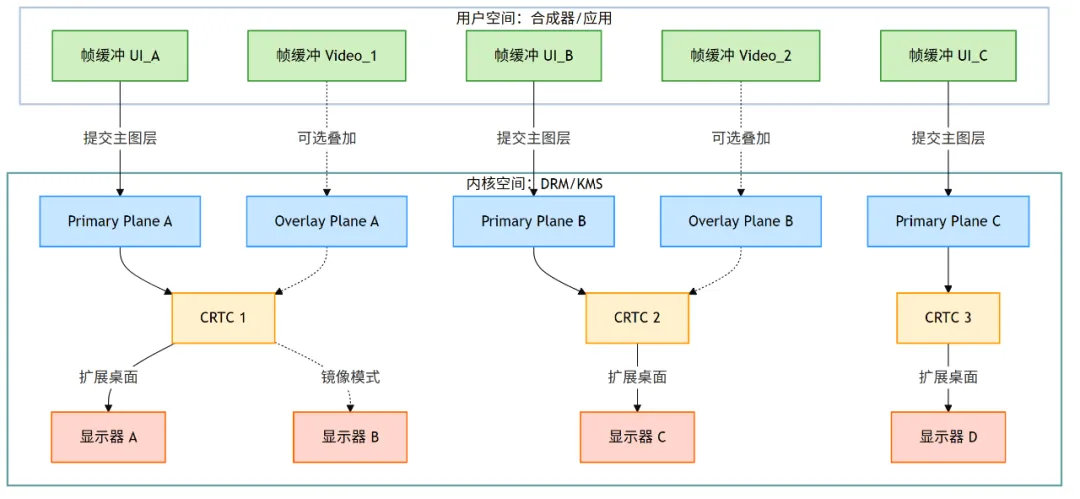
通过原子化模式设置,用户空间的合成器可以精确地控制每一个显示器(Connector)由哪一个时序引擎(CRTC)驱动,从而实现两种经典的多显示器模式。
7.1.1 镜像模式(Clone Mode)
- 概念:让两个或多个显示器显示完全相同的内容,常用于演示、教学和会议场景。
- KMS 实现:在 KMS 模型中,实现镜像模式意味着将多个
drm_connector 对象“附加”到同一个drm_crtc 上。它们共享同一条扫描链路,因此会使用相同的显示时序 (mode) 并输出同一个 drm_framebuffer 的内容。 - 核心约束:镜像模式要求所有参与显示器都能支持某个公共分辨率和刷新率。如果其中一个显示器能力较低(例如仅支持 1080p),就必须牺牲另一个显示器的高分辨率能力。
这种模式的优势是简单、直观,但缺点也很明显:受限于“最小公分母”显示模式,无法充分发挥高端显示器的性能。
7.1.2 扩展桌面(Extended Desktop)
- 概念:将多个显示器拼接成一个逻辑上连续的虚拟桌面,每个显示器显示不同的部分。这是多任务工作最常见和最高效的模式。
- KMS 实现:扩展桌面依赖每个
Connector 绑定不同的 CRTC。这样每个显示器可以拥有独立的分辨率、刷新率和 Framebuffer。 - 用户空间职责:显示器之间如何排列(左、右、上下)、窗口如何分布,都由合成器(Wayland Compositor、X Server)来决定。KMS 只负责“点亮”屏幕,不关心窗口的摆放逻辑。
扩展模式虽然灵活,但存在一些实际的约束条件:
- 硬件带宽限制:同时驱动多个高分辨率显示器(如双 4K@60Hz)需要显卡输出链路和内存带宽足够,否则可能被迫降低刷新率。
- CRTC 数量限制:硬件中可用的
CRTC 数目通常有限(2~6 个),超过数量的显示器无法同时驱动。 - Plane 分配冲突:合成器可能需要多个 Plane(例如一个视频播放窗口),但 Plane 资源有限,可能会导致某些窗口需要回退到 GPU 合成。
7.2 热插拔生命周期
热插拔 (Hotplug) 指在系统运行时动态连接或移除外部显示器。KMS 提供了一个完整的事件处理机制,确保显示栈能及时响应这些变化。
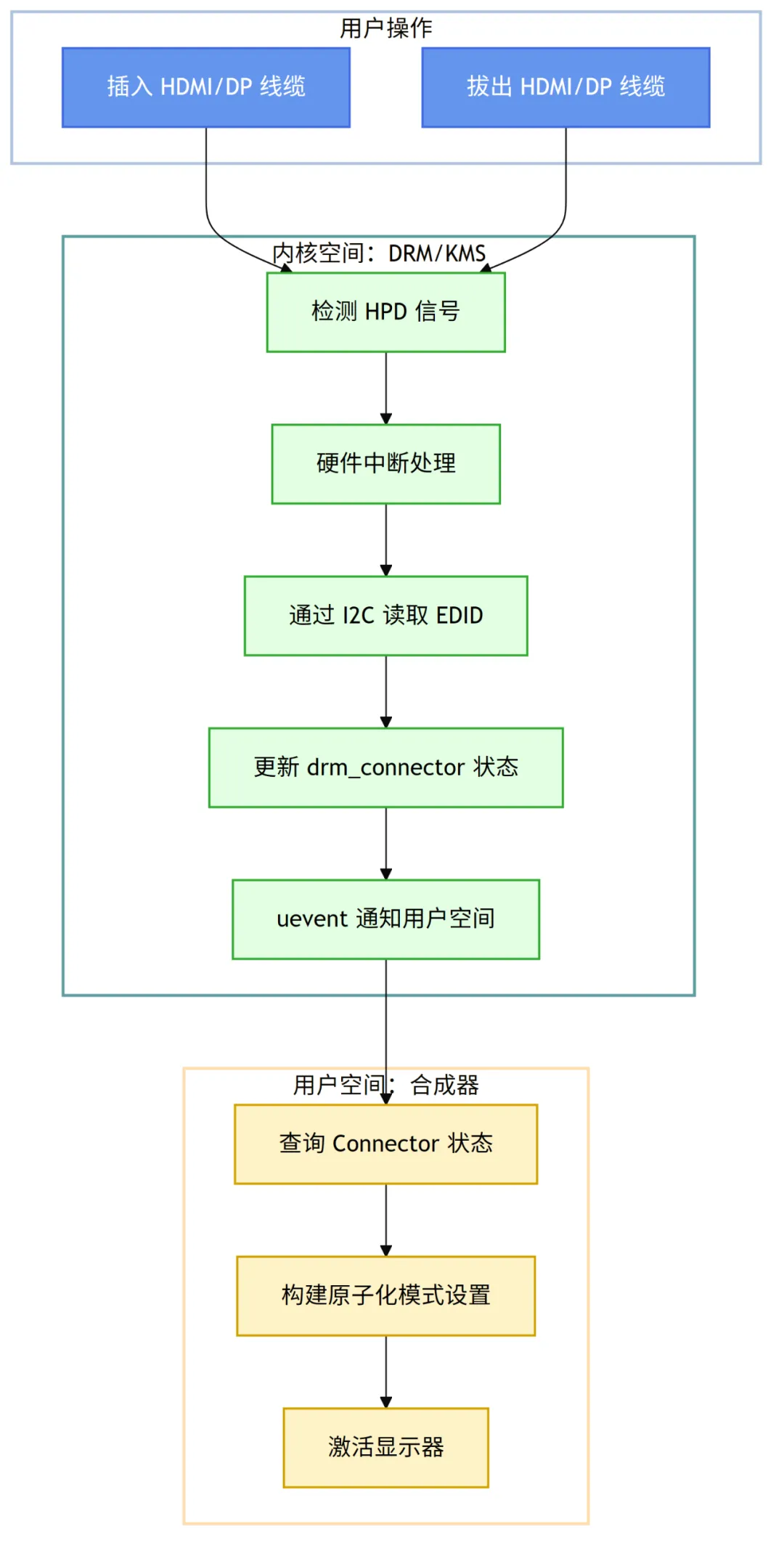
当用户插入一根 HDMI 或 DisplayPort 线缆时,事件流程如下:
- HPD 信号触发:显示器通过线缆上的
Hot Plug Detect (HPD) 引脚向显卡发送电平变化。HDMI 与 DisplayPort 在细节上略有不同:HDMI 的 HPD 更简单,而 DP 的 HPD 同时还可能触发链路训练过程。 - 硬件中断:显卡硬件检测到 HPD 信号的变化,产生一个硬件中断,通知 CPU。
- 驱动响应:DRM 驱动的中断处理程序被调用。它会安排一个工作任务,去通过
DDC/I2C 读取新连接显示器的 EDID 数据。读取成功后,更新对应的 drm_connector 对象的状态为“已连接” (connected);如果读取失败(某些廉价设备常见),驱动可能使用默认模式作为 fallback(如 1024x768)。 - 通知用户空间:内核更新完状态后,会通过
uevent 机制向用户空间广播一个事件。系统的会话管理器(如 logind)、图形合成器或窗口系统会监听到这个事件。 - 模式重新配置:合成器收到事件后,会重新查询 DRM 驱动以获取所有
Connector 的最新状态。它发现了一个新的、已连接的显示器,便会读取其支持的模式列表(来自 EDID),然后根据用户设置或默认策略(如扩展桌面)构建一个新的原子化模式设置请求,激活新显示器。
拔掉线缆时,会触发逆向流程:状态改为 disconnected → 内核广播事件 → 合成器关闭对应屏幕 → 窗口被迁移或隐藏。
这个机制保证了用户几乎无感知的“即插即用”体验。
热插拔流程
7.3 DisplayPort MST
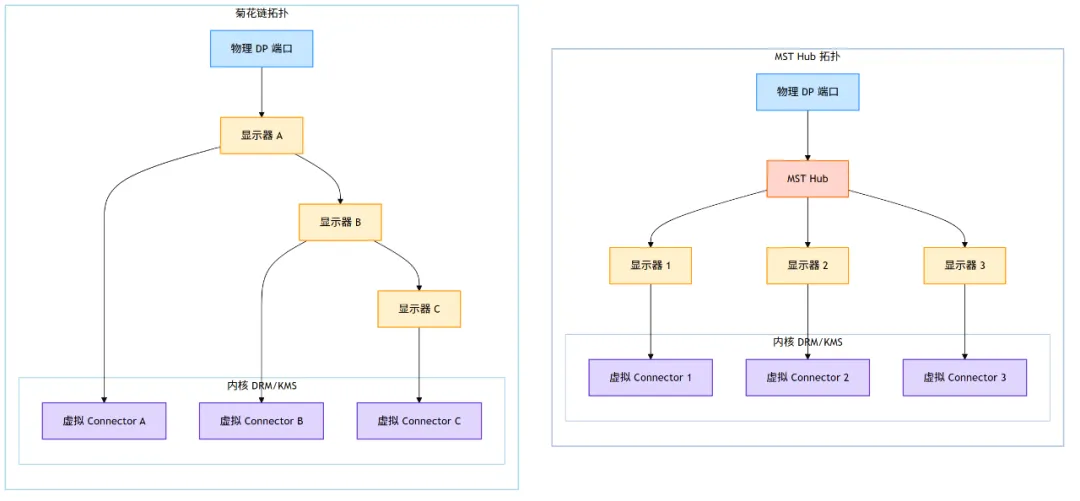
DisplayPort 标准引入了 MST (Multi-Stream Transport) 技术,允许在一根物理 DP 链路上传输多个独立的视频流,从而通过一个接口驱动多个显示器。
7.3.1 MST 的两种典型形态
- 菊花链 (Daisy-chaining):显示器本身内置 MST Hub,第一个显示器连接电脑,第二个连接到第一个,以此类推。
- MST Hub:类似 USB Hub 的设备,将一个 DP 接口扩展为多个 DP/HDMI 接口。
7.3.2 KMS 处理流程- 拓扑发现:当一个支持 MST 的设备(Hub 或显示器)连接到物理 DP 端口时,DRM 驱动会与该设备通信,发现其下游连接的所有显示器的拓扑结构。
- 虚拟化 Connector:对于每一个通过 MST 发现的独立显示器,驱动会在内核中创建一个虚拟的
drm_connector 对象来代表它。从用户空间看,它们与物理 Connector 无差别:都有 EDID、模式列表,可独立绑定 CRTC。 - 带宽分配与链路训练:DP 链路总带宽是固定的(取决于 DP 版本和 lane 数),需要动态分配给不同显示器。例如:DP 1.4 x4 lane 最大 25.92 Gbps,可以拆分为 “4K@60Hz + 1080p@60Hz” 两个流。驱动需在后台处理链路训练(Link Training)和流带宽分配,用户空间只看到“能否点亮”。
- 透明管理:用户空间无需关心链路复杂性,只看到一组普通的 Connector。热插拔事件同样适用,拔掉菊花链中的中间显示器时,驱动会更新拓扑并通知用户空间。
MST 让一个笔记本 DP 口就能驱动多个显示器,大大提高了多显示器部署的灵活性,但也增加了驱动实现的复杂性。
8. 电源与时钟管理
在现代计算设备,尤其是笔记本电脑、手机等依赖电池续航的设备中,功耗管理是一门至关重要的艺术。显示子系统是设备中的耗电大户之一:点亮的屏幕面板、高速运转的显示控制器 (CRTC)、以及为 HDMI/DP 等接口提供信号的物理层 (PHY),都在持续消耗着宝贵的电量。
KMS 框架不仅要负责画面的正确显示,还必须与 Linux 内核的电源管理框架紧密集成,以实现精细、高效的能耗控制。一个优秀的 DRM 驱动,其大部分代码都可能与电源和时钟管理相关。
8.1 功耗的来源与控制
显示管线中的主要功耗来源包括:
- 显示引擎:包括
CRTC、Plane 等,它们需要时钟 (clock) 才能运转。 - 信号接口:
Encoder 和 PHY 在进行高速信号传输时,功耗非常显著。 - 内存总线:在高分辨率和高刷新率下,频繁的内存读取会增加总线功耗。
KMS 的功耗管理核心思想很简单:在不需要时,果断关闭。这意味着关闭空闲组件的时钟、切断其电源域 (power domain),以及命令面板关闭背光。
8.2 运行时电源管理
Linux 内核提供了一套标准的运行时电源管理 (Runtime PM) 框架,允许设备在不被使用时自动进入低功耗状态,在需要时再被唤醒。KMS 驱动正是 Runtime PM 的重度使用者。
8.2.1 空闲状态的定义
在 KMS 的世界里,显示硬件的“空闲”状态通常被定义为所有 CRTC 都不活动 (inactive)。这种情况发生在:
- 用户空间通过
DPMS (Display Power Management Signaling) 命令主动关闭屏幕。
8.2.2 挂起与唤醒
当驱动检测到所有 CRTC 都已关闭,它可以通过 Runtime PM 框架将整个显示硬件“运行时挂起” (runtime suspend)。在这个过程中,驱动会执行一系列操作,如关闭时钟 (disable clock)、断电 (power gate)、关闭背光等。当用户空间发起一次新的原子化请求,试图将某个 CRTC 的 ACTIVE 属性设为 true 时,Runtime PM 框架会首先“运行时唤醒” (runtime resume) 设备,驱动会重新开启必要的时钟和电源,然后再执行模式设置。
8.3 系统级休眠与恢复
Runtime PM 主要处理设备自身的空闲状态,而当整个系统进入休眠(如“挂起到内存”,Suspend-to-RAM)时,则需要另一套机制。DRM 驱动通过实现标准的 suspend 和 resume 回调来支持系统级的电源管理。
suspend:当系统准备休眠时,驱动的 suspend 回调会被调用。它会执行一个完整的、有序的关闭流程,确保所有显示硬件都进入最低功耗状态,并保存当前显示配置的关键信息。resume:当系统从休眠中被唤醒时,resume 回调被调用。它会按照与 suspend 相反的顺序,重新上电并初始化硬件,最后恢复到系统休眠前的显示状态,让用户看到熟悉的桌面。
8.4 原子化模式设置中的电源逻辑
在现代 KMS 驱动中,电源状态的切换与原子化模式设置流程紧密绑定。一次模式设置,本质上也是一次电源状态的配置。
- 通过属性控制:用户空间通过修改
CRTC 的 ACTIVE 属性来控制一个显示通道的开关。将 ACTIVE 设为 false 的原子化请求,就是一条关闭该 CRTC 及其所连接的显示器的命令。 - 驱动的职责:驱动的
.atomic_check() 和 .atomic_commit() 回调函数,不仅要检查模式和 framebuffer 的合法性,还必须负责管理完成这次状态变更所需要的时钟和电源。例如,在 .atomic_check() 中,它需要检查请求的时钟频率是否能够被硬件支持;在 .atomic_commit() 中,它需要先开启相关的时钟和电源域,然后再去写真正的模式设置寄存器。
通过将电源管理逻辑深度整合到原子化状态机中,KMS 确保了每一次显示状态的变更,都伴随着精确、高效的功耗状态切换,为现代设备提供了至关重要的续航保障。
原子模式设置中的电源管理
9. 色彩管理、HDR 与内容保护
在现代显示系统中,能够“显示”只是最低要求,用户真正关心的是如何显示得更真实、更舒适、更安全。无论是设计师对色彩精准度的追求,玩家对 HDR 游戏的期待,还是影视行业对内容保护的要求,都推动了 KMS 在基础模式设置之外,逐步引入色彩管理、HDR 以及内容保护机制。
9.1 色彩管理
色彩管理的目标,是让“屏幕上显示的颜色”与“创作者设想的颜色”尽可能一致。这看似简单,却涉及到 显示器特性、人眼感知、色彩空间差异 等复杂因素。
在 KMS 框架中,色彩管理的关键角色主要由 CRTC 和 Plane 承担:
9.1.1 伽马校正(Gamma Correction)
Gamma LUT(查找表)用于对像素的 R/G/B 通道数值进行非线性映射,以补偿显示面板本身的非线性电光响应。这样,经过 LUT 校正后的像素值在显示器输出时能够产生更符合线性预期的人眼亮度感受,从而提升图像的自然性与准确性。每个 CRTC 通常支持一个 Gamma LUT,但具体实现取决于硬件,有些设备只提供简单的伽马系数调整。
用户空间应用(如合成器或色彩校准工具)可以向内核提交自定义的 LUT,从而实现亮度曲线和对比度的精细调节。这一步骤能有效补偿显示面板的非线性响应,使图像与人眼观感更匹配。
9.1.2 色彩空间转换(Color Space Conversion, CSC)
现代 GPU/显示控制器往往在硬件层面支持 YUV ⇄ RGB 转换。
典型场景是视频解码器输出 YUV420,而显示面板要求 RGB888。通过 CSC,驱动可以在合成阶段直接完成转换,减少 CPU/GPU 额外负担。
一些高级硬件还支持从 sRGB、Adobe RGB、DCI-P3 等色彩空间之间转换,以满足专业显示需求。
9.1.3 查找表扩展(LUT/3D LUT)
高端硬件会提供多级 LUT,不仅能调整亮度,还能实现饱和度、色调映射。
三维 LUT(3D LUT)甚至能对颜色进行整体映射,广泛用于电影后期和专业调色。
KMS 通过属性机制(如 CRTC:DEGAMMA_LUT、CRTC:GAMMA_LUT、CRTC:CTM),为用户空间提供了一套灵活的接口,既能覆盖基础校正,又能支撑高级调色。
查找表扩展
9.2 HDR
HDR(High Dynamic Range)已经成为电视、显示器和游戏中越来越常见的技术。它的核心目标是扩展亮度范围和色彩深度,让画面更接近真实世界的光影。
在 KMS 中,HDR 支持通常包含以下几个方面:
HDR 元数据传递
HDR10、Dolby Vision 等标准都要求传输内容元数据,例如色彩空间、最大亮度、最小亮度、EOTF(电光转换函数)。这些元数据通过 Connector 属性暴露,合成器可在原子提交时附带传递。 EOTF(Electro-Optical Transfer Function,电光转换函数)定义了数字视频信号到显示设备实际物理亮度的映射方式,是保证 HDR 内容准确还原的关键。常见标准包括 PQ(Perceptual Quantizer) 和 HLG(Hybrid Log-Gamma)。PQ 是 HDR10、Dolby Vision 等 HDR 标准的基础,用于电影和流媒体,覆盖极宽的亮度范围;HLG 则兼顾了 HDR 与 SDR 的兼容性,常用于电视广播。
面板能力协商
并非所有显示器都支持 HDR,或者支持的规格不同(HDR10、HLG、Dolby Vision)。用户空间需要通过 Connector 查询硬件能力,然后选择匹配的模式和输出格式。
色调映射(Tone Mapping)
当源内容的动态范围大于显示器能力时,驱动或硬件需要执行 Tone Mapping,避免“过曝”或“死黑”。部分硬件支持在合成器阶段完成色调映射,而在其他场景下则可能依赖 GPU 着色器处理。
HDR 的引入不仅增加了管线的复杂度,也带来了性能和带宽挑战。例如,10-bit 或 12-bit 色深会显著提升显存带宽消耗,需要驱动在 atomic_check 阶段做更严格的带宽验证。
9.3 内容保护
随着数字媒体版权的普及,内容保护同样成为显示系统的重要组成部分。最典型的机制是 HDCP(High-bandwidth Digital Content Protection)。
当前广泛支持的 HDCP 版本包括 2.2 和 2.3,后者主要用于更高安全需求的超高清内容。驱动需兼容不同版本的认证流程,以保障内容安全与兼容性。
在 KMS 中,HDCP 通常体现在以下方面:
属性控制
每个 Connector 可以暴露一个 HDCP 属性,例如 HDCP Content Type 和 HDCP State。用户空间应用(如媒体播放器)在播放受保护内容时,可以请求开启 HDCP。
硬件认证
HDCP 要求显示端与源设备之间完成密钥交换和加密认证。驱动负责与显示器(通过 HDMI/DP 链路)进行握手,并在成功后允许内容输出。
状态反馈
若显示器不支持 HDCP,或认证失败,驱动会通过事件回调通知用户空间。应用可选择降级输出(例如,降低分辨率或拒绝播放)。
通过这种机制,KMS 在保障版权内容安全的同时,也保持了统一的原子化接口,避免了驱动与应用之间的复杂交互。
9.4 小结
无论是色彩管理、HDR 还是内容保护,它们看似属于不同领域,但在 KMS 框架下都有着相同的实现路径:
- 通过属性(Property)扩展能力,而不是修改核心架构。
这使得 KMS 成为一个开放且可演进的平台,既能覆盖基础的桌面显示需求,又能适配专业、消费电子和娱乐领域的最新显示技术。随着未来 VR/AR、超高刷新率以及动态色彩映射的发展,KMS 的属性模型仍将是最核心的扩展载体。
10. 调试与诊断
KMS 横跨内核与用户空间,牵涉驱动、显示控制器、面板/显示器、Mesa、合成器等多个子系统,出现问题时往往需要从多层同时排查。下面给出系统化的诊断方法、常用工具与命令示例,以及实用的调试清单,帮助你快速定位问题根源并生成可复现的调试包。
10.1 内核与系统日志
在遇到显示问题时,检查内核日志永远是第一步。
# 实时查看内核日志journalctl -kfdmesg -w# 按需查看系统日志journalctl -k -b -u <service># 过滤出 drm/i915/amdgpu 等关键词dmesg | grep -i drmjournalctl -k | grep -i drm
详细的 DRM 日志
# 开启海量的调试打印echo drm.debug=0x1f > /sys/module/drm/parameters/debug
提示:启用大量内核调试会产生海量日志并可能影响系统性能或填满日志分区,请在可控环境下使用并及时关闭。
10.2 sysfs 与 debugfs
内核通过 sysfs 和 debugfs 为用户暴露大量状态信息。
查看所有 DRM 设备与 Connector 的状态
ls -l /sys/class/drm# 显示 connected/disconnectedcat /sys/class/drm/card0-DP-1/status
驱动暴露的内部状态
ls -l /sys/kernel/debug/dri/cat /sys/kernel/debug/dri/0/state
debugfs 下的文件按驱动不同会有大量差异(例如 i915、amdgpu 等有各自的调试文件),但通常会包含当前的 CRTC/Plane/Connector 状态、GEM 对象信息、带宽统计等。
10.3 drm_info
drm_info(libdrm 提供的工具)通过 ioctl 查询并解析 DRM 驱动上报的所有信息,以人类可读形式输出。内容包括:
- 每个
Connector 的连接状态、支持的模式列表。 - 每个
CRTC 和 Plane 的信息,以及它们支持的所有属性 (property) 及其当前值。 - 驱动所支持的
GEM 对象信息和 Modifier 列表。
10.4 modetest
modetest(libdrm-tests 包)允许你绕过整个上层图形栈(X Server, Wayland 合成器),直接通过 DRM API 与内核驱动交互,进行主动的功能测试。这对于判断问题是在驱动层还是在上层应用层至关重要。
# 枚举资源。列出驱动资源与 id(用于后续命令查询 id)modetest -M <driver_name># 测试模式设置。在某个 connector@crtc 上设置一个模式(用 modetest 输出中看到的 id/mode)modetest -M <driver> -s <connector_id>@<crtc_id>:<mode_name># 测试图层 (Plane)。在屏幕指定位置用一个 plane 显示测试彩条modetest -M <driver> -P <plane_id>@<crtc_id>:<w>x<h>[+x+y]
如果 modetest 可以单独点亮并显示测试图,而桌面环境不行,那么问题通常在用户空间(合成器/Mesa/Wayland)而非内核驱动。
10.5 ftrace/trace-cmd
当问题是动态发生的(例如,随机闪烁、性能抖动或同步问题)时,静态快照不足以定位问题,此时,我们需要 ftrace 这样的内核追踪工具来捕捉事件发生的瞬间。trace-cmd 是 ftrace 的一个友好前端。
DRM 核心和各个驱动都定义了大量的追踪点 (tracepoint)。你可以用 trace-cmd 来记录这些事件。例如,要追踪一次完整的原子化提交过程:
# 开始记录所有 drm 相关的 tracepointsudo trace-cmd record -e drm# 在另一个终端中,执行触发问题的操作(例如,启动游戏)# ...# 停止记录sudo trace-cmd stop# 查看记录结果trace-cmd report
在生成的报告中,可以看到 drm_atomic_check、drm_atomic_commit 的执行流程、vblank 中断的发生时间、dma_fence 的触发,以及页面翻转完成事件的精确时间戳。
10.6 其他常用工具
journalctl -k -b:查看本次引导的内核日志(方便找启动阶段的 KMS 输出)。udevadm monitor --kernel:观察热插拔(HPD)事件是否到达内核。strace/ltrace:strace -f -e trace=ioctl -p <pid-of-compositor>,跟踪合成器(Wayland/X)对 DRM ioctl 的调用(确定问题在上层还是下层)。- GPU 特定工具:
intel_gpu_top(Intel),radeontop(AMD)等用于观察 GPU 利用率、活跃状态(可以区分是 GPU 负载还是显示子系统空闲导致的问题)。
10.7 调试清单
面对一个棘手的显示问题,一个系统性的调试流程如下:
- 查日志:检查
dmesg,并尝试用 drm.debug 内核参数获取更详细的日志。 - 读状态:通过
sysfs 查看 Connector 状态;检查 debugfs 中的 state 文件,看驱动内部记录的状态是否与预期一致。 - 看快照:使用
drm_info 确认硬件能力和当前状态是否符合预期。 - 做隔离:使用
modetest 进行最简单的模式设置和 Plane 测试,将问题范围缩小。 - 抓踪迹:对于动态和性能问题,使用
trace-cmd 捕获事件序列,进行深度分析。 - 善用原子化测试:在开发中,多使用
DRM_MODE_ATOMIC_TEST_ONLY 来预验证你的状态变更,能提前发现大量潜在问题。
从日志→快照→隔离测试→动态追踪,逐步缩小问题范围。掌握 dmesg/drm_info/modetest/trace-cmd/debugfs 等工具,并按上面的清单收集信息,通常可以在短时间内定位到是硬件、内核驱动还是用户空间(合成器/Mesa)的问题。