诸位,在上一课《Python学习|RS Python入门02:列表、字典与流程控制:像元集合的编队与行军令【一】》中,知道怎么用[]按顺序存一堆像元值、波段名称或者坐标点。比如一个像素的7个波段值可以存成列表[b1, b2, b3, b4, b5, b6, b7],靠位置索引来访问,但实际处理遥感数据时,经常遇到这种情况:
1)你知道要操作的是近红外波段,但不想记它在第几个位置
2)不同数据源的波段顺序不一样,用位置索引很容易出错
3)除了波段数据,还有一堆相关属性要一起管理(分辨率、投影、采集时间等)
这时候就需要字典(Dictionary)了。
什么是字典?
字典(Dictionary)是Python中一种基于哈希表实现的键值对映射数据结构。它通过{}定义,存储形式为{键1: 值1, 键2: 值2, ...},其中键必须是不可变类型(如字符串、数字、元组),值可以是任意类型。
首先,我们来创建几个字典,我们可以采取如下的方式去定义列表:
meta = {"sensor": "Landsat8", "date": "2023-06-15", "cloud_cover": 12.5} # 直接创建meta_dict = dict(sensor="Landsat8", date="2023-06-15") # dict()构造函数empty_dict = {} # 空字典
而后我们可以查看以下我们创建的列表,输入以下命令:
print(meta)print(meta_dict )print(empty_dict)
当然,假设我们不知道上面的bands是什么类型,也可以查看我们创建的类型:
print(type(meta)) # <class 'dict'>
1)无序性:在Python 3.7+中,字典虽然保持插入顺序,但这种"有序"与列表的顺序有本质区别:
metadata = {"platform": "Sentinel-2A", "acquisition_time": "10:30:00Z"}print(metadata["platform"]) # "Sentinel-2A"
2)键的唯一性:每个键必须是唯一且不可变的(字符串、数字、元组):
band_info = { "B01": "Coastal Aerosol", "B02": "Blue", "B01": "Coastal Aerosol (443nm)" # 覆盖第一个B01}print(band_info["B01"]) # "Coastal Aerosol (443nm)"
然后我们可以看到输出的是Coastal Aerosol(443nm),而非Coastal Aerosol。也就是说键重复时,后值覆盖前值。3)值的任意性:值可以是任何数据类型,包括列表、字典等嵌套结构
image_metadata = { "basic_info": { "satellite": "Landsat 9", "sensor": "OLI/TIRS", "acquisition_date": "2023-09-20" }, "processing_info": { "level": "L1TP", "system_correction": True, "terrain_correction": False }, "bands": ["B1", "B2", "B3", "B4", "B5", "B6", "B7"]}
也就是我们可以看到,遥感元数据的典型嵌套结构,字典中的值是任意的类型(type),只要符合key与value对应关系即可。3.1 场景一:影像头文件信息
# Landsat影像标准元数据结构landsat_header = { "FILE_TYPE": "L1T", "DATA_TYPE": "INT16", "SPATIAL_RESOLUTION": 30, # 米 "PROJECTION": "UTM", "DATUM": "WGS84", "ZONE": 50, "UL_CORNER": (440000.0, 3500000.0), # 左上角坐标 "LR_CORNER": (500000.0, 3450000.0), # 右下角坐标 "BANDS": 11, "ROWS": 5000, "COLUMNS": 5000, "SUN_ELEVATION": 55.4, "SUN_AZIMUTH": 135.2}
# Sentinel-2波段参数详解sentinel2_bands = { "B01": { "name": "Coastal Aerosol", "center_wavelength": 443.9, # nm "bandwidth": 20, "resolution": 60, # 米 "description": "用于海洋颜色和气溶胶研究" }, "B02": { "name": "Blue", "center_wavelength": 496.6, "bandwidth": 65, "resolution": 10, "description": "水体穿透、土壤植被区分" }, "B08": { "name": "NIR", "center_wavelength": 832.8, "bandwidth": 115, "resolution": 10, "description": "植被生物量、水体边界" }}
nir_info = sentinel2_bands["B08"]print(f"波段名: {nir_info['name']}")print(f"中心波长: {nir_info['center_wavelength']}nm")
3.3 场景三:处理流程配置
# 影像预处理参数配置preprocessing_config = { "input_path": "/data/raw/landsat/", "output_path": "/data/processed/", "operations": { "radiometric_correction": { "method": "DOS", "atmospheric_model": "Mid-Latitude Summer", "aerosol_model": "Urban" }, "geometric_correction": { "method": "Polynomial", "order": 2, "gcp_count": 25 }, "terrain_correction": { "enabled": True, "dem_source": "SRTM", "resampling": "Bilinear" } }, "output_format": "GTiff", "compression": "LZW", "nodata_value": -9999}
接下来为了更好的给大家理解:我们来通过两个完整的流程进行模拟:
案例1:单景影像快速处理
def quick_process_single_scene(): scene_info = { "id": "L8_20230615", "file": "LC08_20230615.tif", "bands": { "red": 3, # 红色波段在第4个位置(索引3) "nir": 4, # 近红外波段在第5个位置 "swir": 5 # 短波红外波段 } } print(f"处理影像: {scene_info['id']}") steps = { "1_load": "读取影像数据", "2_extract": "提取需要的波段", "3_cloudmask": "简单云掩膜", "4_calculate": "计算植被指数", "5_output": "保存结果" } for step_name, step_desc in steps.items(): print(f"步骤{step_name}: {step_desc}") results = { "ndvi_range": [0.1, 0.8], "mean_ndvi": 0.45, "veg_area_km2": 125.6, "output_file": "L8_20230615_ndvi.tif" } return results
scene_result = quick_process_single_scene()print(f"NDVI均值: {scene_result['mean_ndvi']}")print(f"输出文件: {scene_result['output_file']}")
而后便可看到如下结果:
案例2:两期影像变化检测
def simple_change_detection(): time1 = { "date": "2020-06-15", "ndvi_file": "ndvi_2020.tif", "stats": {"mean": 0.52, "max": 0.89} } time2 = { "date": "2023-06-15", "ndvi_file": "ndvi_2023.tif", "stats": {"mean": 0.48, "max": 0.85} } print(f"对比{time1['date']} 和{time2['date']}") change_results = { "mean_change": time2["stats"]["mean"] - time1["stats"]["mean"], "change_map": "ndvi_change_2020_2023.tif", "change_categories": { "decreased": {"threshold": -0.2, "area_km2": 15.3}, "stable": {"threshold": 0.1, "area_km2": 85.7}, "increased": {"threshold": 0.2, "area_km2": 24.6} } } print(f"平均NDVI变化: {change_results['mean_change']:.3f}") print(f"植被减少面积: {change_results['change_categories']['decreased']['area_km2']} km²") return change_results
change_result = simple_change_detection()
我们便可看到如下结果:
4.1 访问与修改
我们先定义一个字典:
metadata = {"satellite": "Terra", "sensor": "MODIS"}
上面我们已经提到了,可以访问某一元素,想一下使用什么方法?是的,直接访问,或者由key去访问。
sensor = metadata["sensor"] # 直接访问date = metadata.get("acquisition_date", "Unknown") # 安全访问,不存在返回默认值
此外,我们还可以对其进行修改等操作,且看如下两种方式:
metadata["orbit_number"] = 12345 # 添加新键metadata["sensor"] = "MODIS/Terra" # 修改已有键
metadata.update({ "processing_level": "L1B", "cloud_cover": 15.2, "quality_flag": "Good"})
4.2 常用字典方法
我们再来创建一个传感器字典:
spectral_bands = ["Blue", "Green", "Red", "NIR"]
可以对该字典进行如下操作:
1)获取所有键
keys = sensor_dict.keys() # dict_keys(['platform', 'instrument', 'launch_date'])
2)获取所有值
values = sensor_dict.values() # dict_values(['Aqua', 'MODIS', '2002-05-04'])
3)获取所有键值对
items = sensor_dict.items() # dict_items([('platform', 'Aqua'), ...])
4)删除元素
value = sensor_dict.pop("launch_date") # 删除并返回值sensor_dict.clear() # 清空字典
4.3 字典推导式
试想一下,我们有一组Landsat波段标识符 ["B1", "B2", "B3", "B4"],想要快速创建一个字典,将每个波段标识符映射到更详细的波段名称上。传统方法需要循环遍历和逐一赋值,但使用字典推导式,我们可以一行代码完成:
bands = ["B1", "B2", "B3", "B4"]band_names = {band: f"Band_{band[-1]}" for band in bands}
便可得到如下的结果:
那么,如何在遥感数据处理中应用这种简洁的语法呢?
1. 波段波长映射
假设我们有四个波段的中心波长值,想要创建波段名称到波长的映射字典:
wavelengths = [443, 490, 560, 665]
spectral_dict = {f"Band_{i+1}": wavelengths[i] for i in range(len(wavelengths))}
进一步我们来查看创建的字典:
便可得到如下结果:
2. 筛选传感器数据
当我们需要从多个传感器数据中筛选出满足特定条件的数据时,比如找出分辨率小于等于30米的传感器:
先来定义一个传感器参数的字典:
sensor_data = { "Landsat8": {"bands": 11, "resolution": 30}, "Sentinel2": {"bands": 13, "resolution": 10}, "MODIS": {"bands": 36, "resolution": 250}, "QuickBird": {"bands": 4, "resolution": 0.6}}
接下来我们做个筛选高分辨率传感器(分辨率≤30米):high_res = {k: v for k, v in sensor_data.items() if v["resolution"] <= 30}print("高分辨率传感器:")for sensor, info in high_res.items(): print(f" {sensor}: {info['resolution']}米分辨率")
3. 批量处理文件名映射
假设我们有不同年份的影像,需要创建年份到文件名的映射:
years = ["2020", "2021", "2022", "2023"]seasonal_images = { year: { "spring": f"LC08_{year}0601.tif", "autumn": f"LC08_{year}1001.tif" } for year in years}
for year, files in seasonal_images.items(): print(f"{year}年: 春季-{files['spring']}, 秋季-{files['autumn']}")
当然还有诸多使用场景,如针对特定区域进行特定方法处理等等,在此不再展开赘述,后面倘若会用到我们会展开详细讲解,也可以使用if语句进行替代。
字典推导式不仅让代码更加简洁优雅,更重要的是它提高了数据处理的可读性和可维护性。在遥感数据处理中,面对大量的波段、时间序列和空间区域数据,这种高效的字典创建方式可以显著提升开发效率。
5.1键的选择与不可变性
下面我会展示一些有效的键:
valid_keys = { "string_key": "value1", # 字符串(最常用) 123: "value2", # 整数 (1, 2, 3): "value3", # 元组(可哈希) True: "value4" # 布尔值}
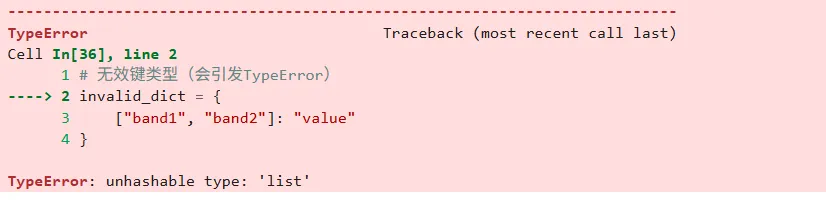
invalid_dict = { ["band1", "band2"]: "value" }
我们可以看到如下的运行结果:
究其缘由,是由于列表不可哈希。
5.2 处理缺失键的问题
我们有三种方法可以处理:
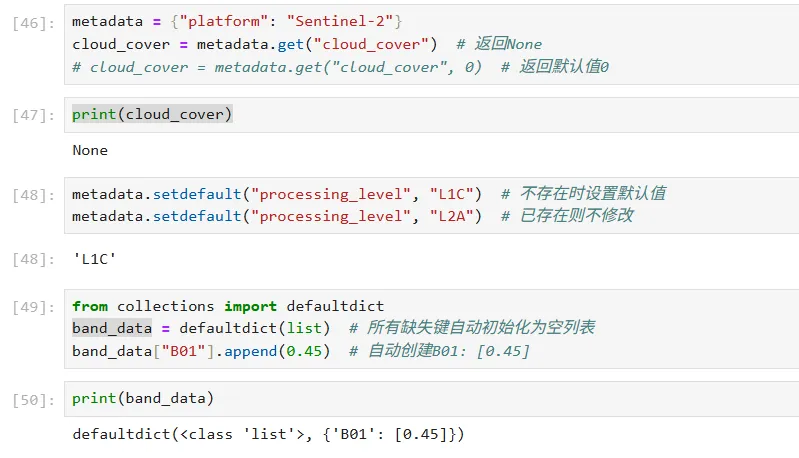
metadata = {"platform": "Sentinel-2"}cloud_cover = metadata.get("cloud_cover") # 返回Nonecloud_cover = metadata.get("cloud_cover", 0)# 返回默认值0
metadata.setdefault("processing_level", "L1C") # 不存在时设置默认值metadata.setdefault("processing_level", "L2A") # 已存在则不修改
from collections import defaultdictband_data = defaultdict(list) # 所有缺失键自动初始化为空列表band_data["B01"].append(0.45) # 自动创建B01: [0.45]
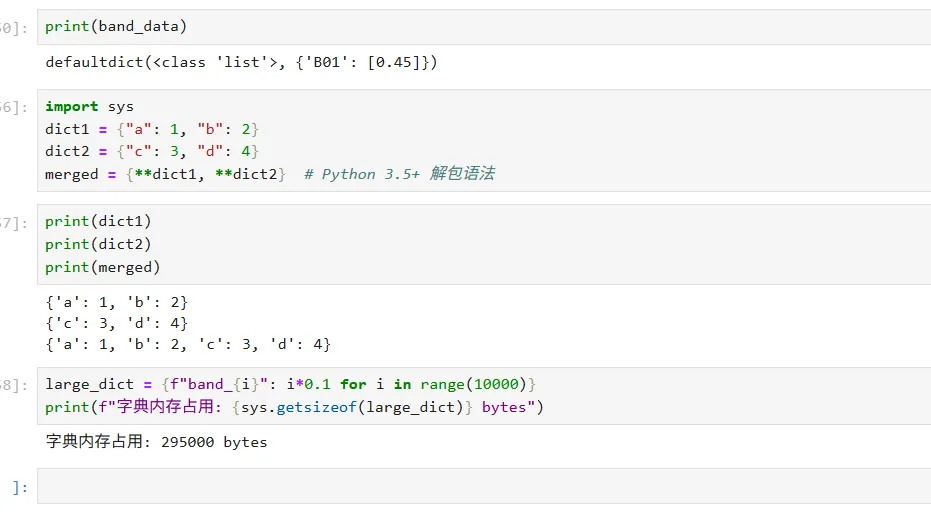
我们可以查看一些运行的结果(这是一部分,剩下的结果可由读者自行运行):5.3 性能考虑与内存使用
import sysdict1 = {"a": 1, "b": 2}dict2 = {"c": 3, "d": 4}merged = {**dict1, **dict2} # Python 3.5+ 解包语法
large_dict = {f"band_{i}": i*0.1 for i in range(10000)}print(f"字典内存占用: {sys.getsizeof(large_dict)} bytes")
6.1 复杂嵌套结构
首先我们先来定义一些元数据文件:
dataset_metadata = { "identification": { "title": "Landsat 8 Surface Reflectance", "abstract": "大气校正后的地表反射率数据", "keywords": ["Landsat", "Surface Reflectance", "USGS"] }, "extent": { "spatial": { "bbox": [73.0, 18.0, 135.0, 54.0], # 四至范围 "crs": "EPSG:4326" }, "temporal": { "start": "2013-02-11", "end": "2023-12-31", "resolution": "16 days" } }, "bands": { "B01": { "name": "Coastal Aerosol", "units": "reflectance", "scale": 0.0001, "offset": -0.1, "valid_range": [0, 10000] } }, "quality_indicators": { "cloud_cover": { "value": 15.3, "unit": "percent", "assessment": "moderate" }, "radiometric_quality": "high", "geometric_accuracy": 12.5 }}
from functools import reducedef deep_get(dictionary, keys, default=None): return reduce(lambda d, key: d.get(key, default) if isinstance(d, dict) else default, keys.split("."), dictionary)cloud_value = deep_get(dataset_metadata, "quality_indicators.cloud_cover.value")print(f"云量: {cloud_value}%")
便可得到如下结果图:
6.2 与JSON的互操作
我们可以与JSON进行转换操作,也就是可以字典转JSON(用于存储或传输)、序列化为JSON字符串、从JSON文件读取等:
import jsonmetadata_dict = { "platform": "Sentinel-2", "tile": "50TPF", "date": "2023-08-15"}json_str = json.dumps(metadata_dict, indent=2, ensure_ascii=False)"""{ "platform": "Sentinel-2", "tile": "50TPF", "date": "2023-08-15"}"""with open("metadata.json", "w", encoding="utf-8") as f: json.dump(metadata_dict, f, indent=2)with open("metadata.json", "r", encoding="utf-8") as f: loaded_metadata = json.load(f)
好了,不常用的便不再展开赘述,除此之外还有一些分隔路径等操作,估计不会太用到,节省大家的学习时间,便不展开讲解。键值映射:通过键快速访问值,适合结构化数据存储
无序但有序:Python 3.7+保持插入顺序,但不应依赖顺序
键的唯一性:键必须可哈希且唯一
灵活嵌套:支持多层嵌套,适合复杂元数据结构
高效访问:基于哈希表实现,键查找时间复杂度O(1)
JSON兼容:与JSON格式天然互转,便于数据交换
安全访问:使用get()方法避免KeyError异常
通过字典,我们已经学会了如何为遥感数据创建清晰的结构化容器——无论是传感器参数、影像元数据还是处理配置,都能在这个灵活的空间中找到自己的位置并快速定位。字典让数据有了“档案”,但真正让程序拥有实用价值的,是让它能够像分析师一样思考和决策——面对云覆盖30%的影像,是该直接采用还是进行云去除?针对不同传感器数据,该自动调用哪套定标参数?
这就需要条件判断(if-elif-else)——让程序能够基于数据的状态和规则,自主选择执行路径,从而实现对复杂遥感场景的智能响应与自动化处理。
如果你觉得“原来Python也能讲得这么遥感”,点个关注,后续系列推文将第一时间推送:
结构、控制流、函数、面向对象……
每一步都用卫星影像、波段、像元做例子,拒绝枯燥抽象。
附赠可运行的 Notebook 源码,自行上传即可上手。本公众号后台回复【RS Python入门02】即可获取本节 Notebook 源码。