“ 近年来,基于深度学习的代码漏洞检测方法不断涌现,但一个核心问题始终存在:模型往往“看见”漏洞,却并不真正“理解”漏洞。单一模型通常只能捕获某一视角下的代码特征,难以同时兼顾语法结构、语义依赖与上下文逻辑。
为此,研究者提出了M2CVD,一种通过多模型协同(Multi-Model Collaboration)增强漏洞理解能力的检测框架,旨在从多个认知视角对代码进行联合分析,从而提升漏洞检测的准确性与可解释性。”- 📄 论文标题:M2CVD: Enhancing Vulnerability Understanding through Multi-Model Collaboration for Code Vulnerability Detection
- 📅 发表时间:ACM transactions on software engineering and methodology, 2025
💡开源代码:
https://github.com/HotFrom/M2CVD
方法介绍
M2CVD的核心思想并非设计一个“更大的模型”,而是让多个能力互补的模型进行协同分析。整体流程可概括为以下三个阶段:
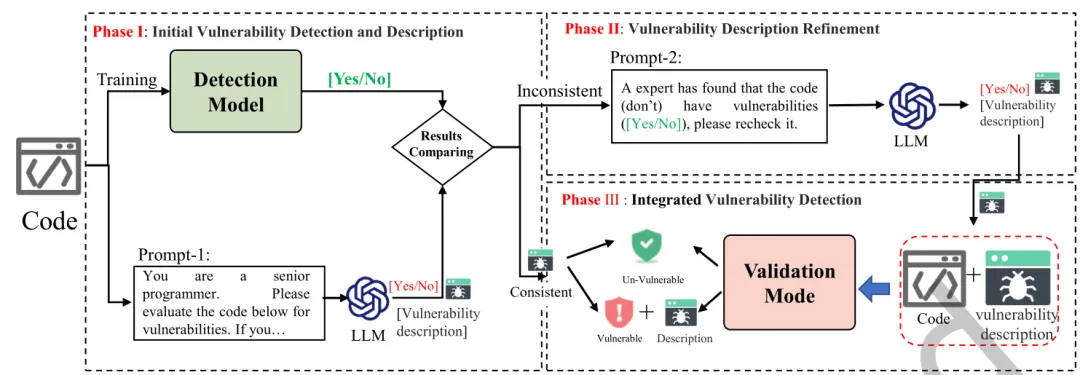
① 多视角特征建模利用不同模型分别关注代码的语法、语义与上下文信息。② 协同特征对齐③ 联合漏洞判定图 1. M2CVD整体流程
小结:M2CVD 关注的不是“模型替代”,而是“模型协作”。
关键机制
- 多模型协同而非单模型堆叠,强调模型之间的互补与对齐。
- 特征级协同机制,不仅融合结果,更对齐中间语义表示。
- 更贴近“漏洞理解”目标,从模式匹配走向语义认知。
小结:M2CVD 框架的关键,是使多模型从“并列存在”走向“协同理解”。实验在两个主流漏洞数据集Devign和Reveal上验证了M2CVD 的有效性,主要实验结果如下。
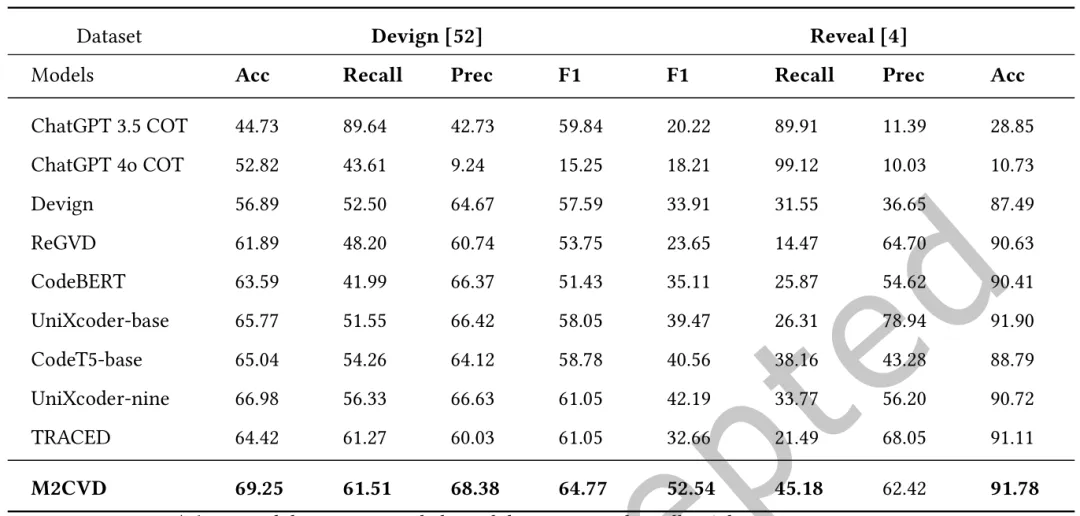
(1)实验首先将M2CVD与七种基线方法在两个数据集上的表现进行比较,如表1所示。表1. 不同模型在Devign和Reveal数据集上的比较结果
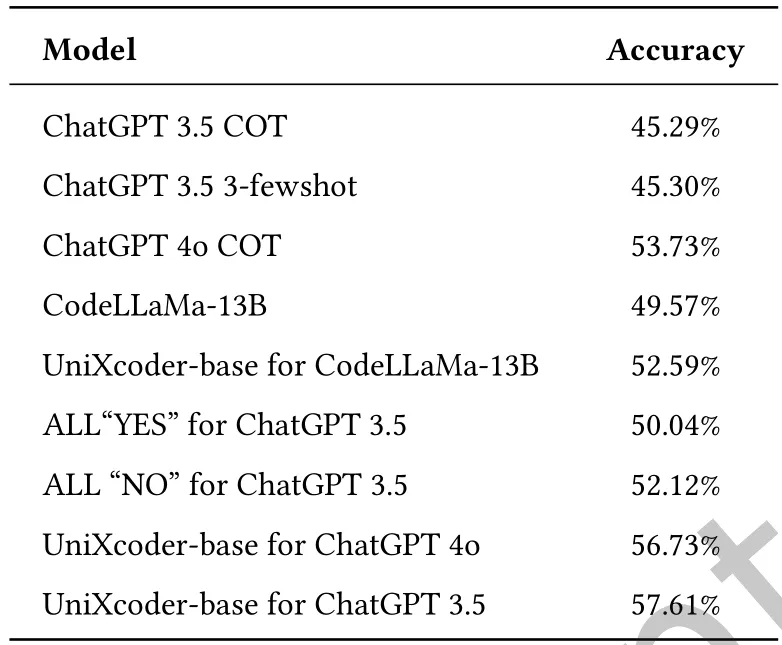
(2)为了详细阐述M2CVD框架中第二阶段反馈对代码漏洞检测性能的影响,基于Devign数据集及其默认划分方案建立了一个比较实验,结果见表2。
表2. 第二阶段不同配置下大型语言模型的准确性对比
小结:M2CVD的性能表现表明,相较于单一模型,其通过协同机制在不同实验条件下有效实现了代码缺陷检测任务的更高性能。此外,验证了M2CVD的漏洞描述精炼过程能显著提升代码漏洞检测的准确性。
📌 总结
M2CVD从“如何理解漏洞”这一根本问题出发,提出以多模型协同的方式构建更全面的代码语义认知体系。该工作表明,未来漏洞检测的提升方向,可能不止是更大的模型,而是更合理的模型协作方式。
📣 欢迎留言讨论
你认为多模型协同是否会成为漏洞检测的主流范式?
在工程实践中,多模型带来的计算成本是否值得?
📌 点赞 + 收藏 + 分享,你的支持,是我们持续解析高水平软件安全论文的最大动力!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
