在 RAG 和 AI Agent 等爆火的背后,是一个默默撑起这些明星技术的核心组件——向量检索。它不仅大大拓宽传统语义检索(关键词检索)的边界,和大模型的配合更是浑然天成。然而,关于如何发挥这项技术的真正潜力,却很少有人了解。要让向量模型和向量数据库的组合真正跑出效果,关键在于——选对“度量空间”。
尽管基于图的向量检索算法,如HNSW、NSG等,因其优秀的检索速度备受青睐,但往往被忽视的是,他们都是面向欧式空间设计的向量检索算法。“度量错配”在很多场景下是毁灭性的,很多适合用“最大内积”检索的向量数据,搭配欧式向量算法,往往会出现“检索结果和query语义无关”的问题。
回看最大内积检索领域,其实还没有出现类似HNSW、NSG这样现象级的检索算法。之前的很多工作往往只在某些数据集上面表现良好,但换了数据集,效果就会剧烈退化。基于此,我们联合浙江大学成功把最大内积检索算法研究拉到了和欧式空间相同的水位,创新方法——PSP,可以将先有图算法经过最简单的改造,就可以实现最大内积检索效能30%增长!
我们发现,最大内积研究进入瓶颈主要有两大核心原因。
之前在最大内积检索领域的研究泾渭分明地分成两种范式:
1) 把最大内积转换为最小欧式距离,进而可以用HNSW、NSG来解决。但这种转化往往会伴随着信息损失或者拓扑空间的非线性转换,而这些问题会对搜索效果带来不同程度的负面影响。
2)不进行空间转化,直接在内积空间进行检索。这样做的好处是避免了信息损失或空间扭曲,但相对应的痛点是,缺少有效手段对无效检索空间进行裁剪,进而难以达到更好的检索速度。
为什么在内积空间直接做检索这么难呢?最核心原因在于内积空间并不是一个严格意义上的“度量空间”。从数学上来说,一个空间可以称之为“度量空间”,需要满足诸多条件,典型地,我们最常接触的欧式空间就是一个度量空间。而作为一个“残缺空间”,内积空间缺少的最重要的属性就是“三角不等式”。
根据NSG论文的理论部分,HNSW、NSG、SSG等state-of-the-art的向量检索算法之所以能如此高效,就是因为他们都利用了三角不等式对索引结构(图结构)进行了高效的裁剪。而我们以内积作为距离度量,构建的三角形,不满足我们耳熟能详的那句口诀“三角形中任意两边之和大于第三边,而任意两边之差小于第三边”。正是这一属性的确实,阻碍了最大内积检索算法进一步发展。
我们对这一问题进行了深入研究,从理论上证明了一件事情:对任意搜索请求,即Query点q,它在一个为欧式距离设计的图索引结构上,可以通过简单的贪心算法找到全局最优的最大内积解。
对基于图的向量检索算法熟悉的同学可能了解,这类方法都利用贪心算法进行检索:当我们从随机点开始在图上游走时,NSG这类算法会从路径上的点的邻居中,寻找一个距离目标“最近”的邻居进行跳转,这样从邻居的邻居逐步跳转到全局最优解。
而这种贪心算法曾经隐含的理论要求的是,如果我构建图用的是欧式距离表达“远和近”,那么我贪婪游走也需要用欧式距离来定义远和近。而PSP团队的研究成果的意义在于,如果构建图用的是欧式距离,在贪婪游走的时候可以用内积来定义远和近,最终到达的终点就是全局最优的最大内积解!
因此,我们就可以仅仅修改检索(贪婪游走)算法中的两行代码,就实现将一个现有的欧式算法向最大内积的适配:
我们发现,最大内积检索的过程中,会存在大量冗余计算,而这些冗余是可以通过合理引导搜索行为来规避的。
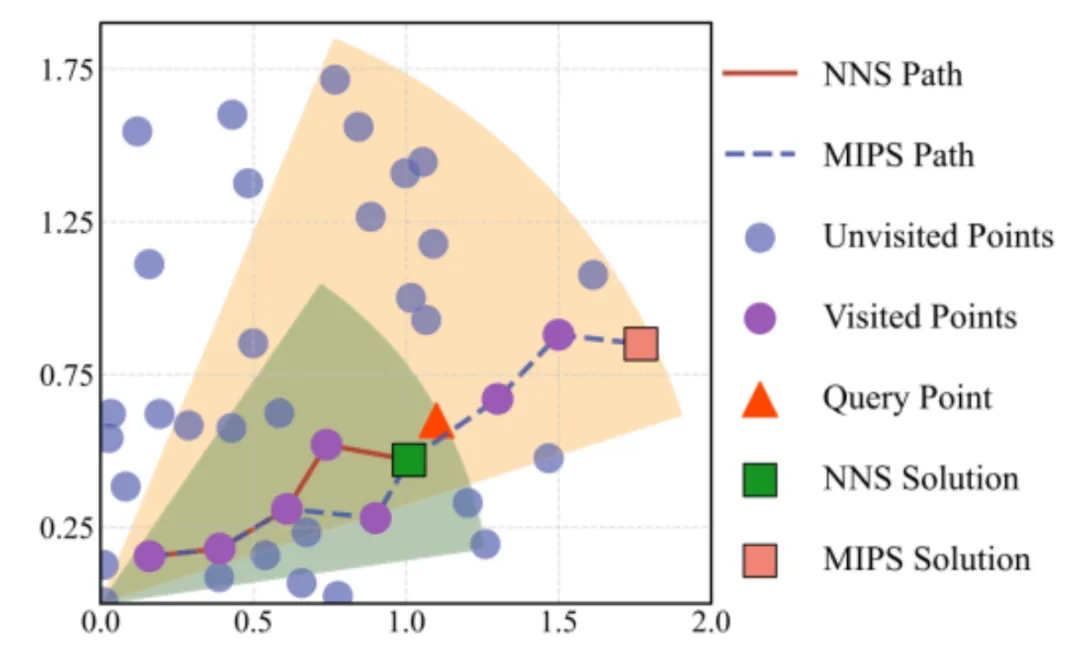
最大内积中的搜索行为与欧式空间中的搜索行为有极大差异,如下图所示:
上图中,绿色方框(query)的最近欧式近邻是红色三角,但它的最大内积近邻是橙色方块。因此,在搜索query的最近欧式邻居的时候,游走行为会很快在三角形附近停止,但搜索他的最大内积邻居会继续走到“外围”橙色方块附近。
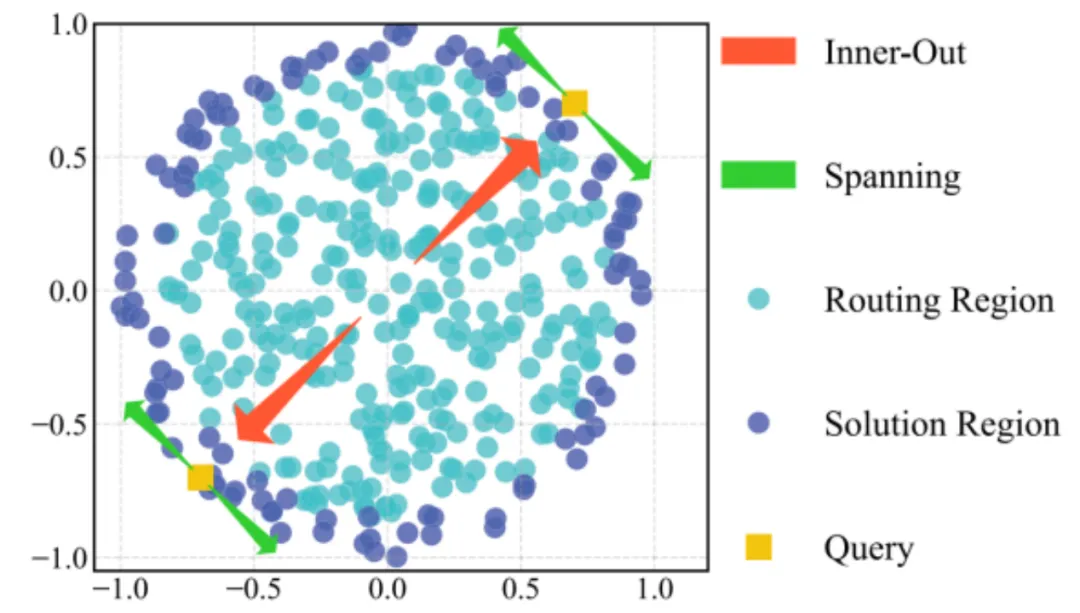
从更宏观的角度看,我们团队发现,最大内积检索的解空间往往在数据集“外围”(不同于欧式距离最近邻,可以存在于数据空间的任意位置)。因此,最大内积的搜索行为往往服从一种“由内而外,再外围扩展”的模式(如上图右图)。
针对这种特性,PSP会设计针对性的策略,让图上搜索的起始点就尽量分布在距离“答案”更近的区域。
同时,冗余不仅仅发生在搜索过程的前段,也非常多地集中在搜索过程的后段。
如上图,我们发现,在图索引上搜索到精确解的“最少步数”因Query而异,呈现明显的长尾分布(图a),而他们也通过大量实验挖掘出四类“特征”帮助我们判断搜索应该在什么时候停下来(图b)。这四类特征可以在搜索过程中以非常低的成本被计算和记录,实现自适应的“早停”策略。
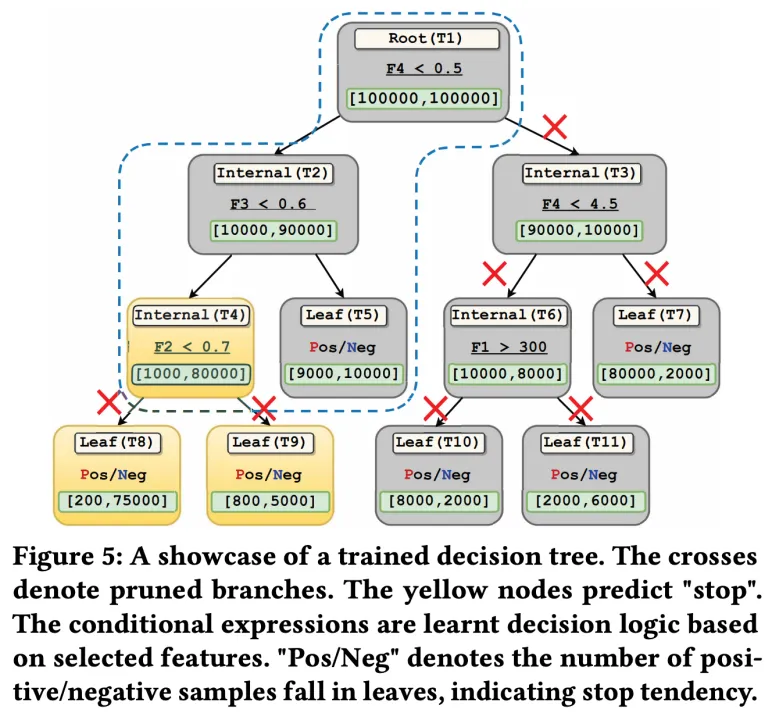
具体来说,可以在数据库中随机采样一部分点作为query,通过对它们进行搜索来收集最优停止步数前后的数据构成可分类的样本,再用这个样本去训练一颗决策树,就可以辅助搜索过程判断停止条件:
如上图,通过对决策树剪枝,可以让整棵数保留较小的高度。之所以选择决策树作为分类器,是因为它可以有效拟合少量样本,并直接翻译为if-else语句嵌入搜索代码中,实现高效的“停止判断”。
为了充分测试PSP算法的效果,我们在8个大规模、高纬度的数据集上进行了充分测试。从维度看,DBpedia100K和DBpedia1M分别高达1536和3072维,用OpenAI text-embedding-3-large模型抽取;从数量看,最大的数据集Commerce100M包含1亿数据库点。
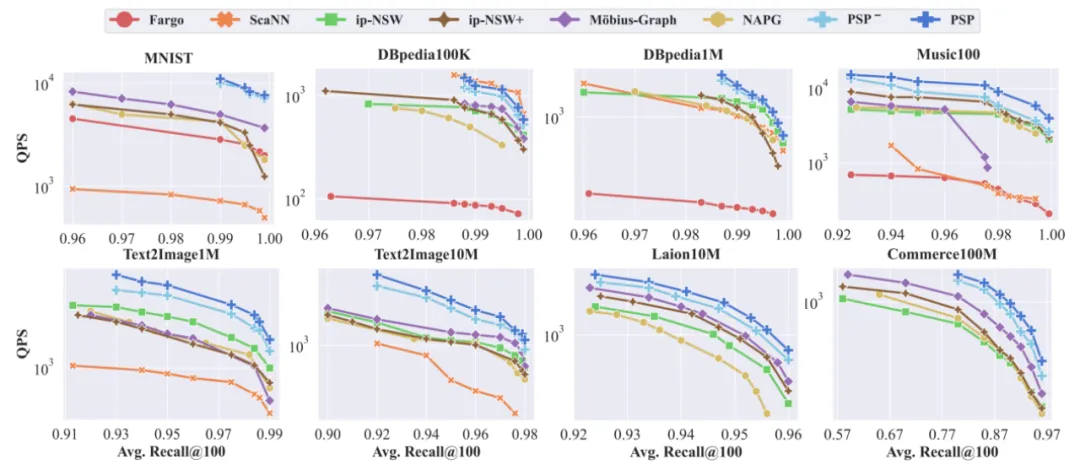
比较向量检索算法,我们往往关注相同召回率下的检索速度,即Query-Per-Second(QPS),从上图中不难看出,PSP相对于现有state-of-the-art的方法有着稳定、明显的提升。在MNIST数据上,甚至超过第二名4倍之多。
值得注意的是,baseline的方法里,往往有一些会在图中“缺席”。这是因为它们性能远差于其它方法,而很难和其它方法画到同一张图中。比如ip-HNSW在MNIST数据集中缺席;ScaNN在Laion10M和Commerce100M上缺席等等,这突出了PSP的表现稳定性。
另外,所使用的数据集包含了“文搜文”、“图搜图”、“文搜图”、“推荐系统召回”等诸多数据模态,体现出PSP强大的泛化性。
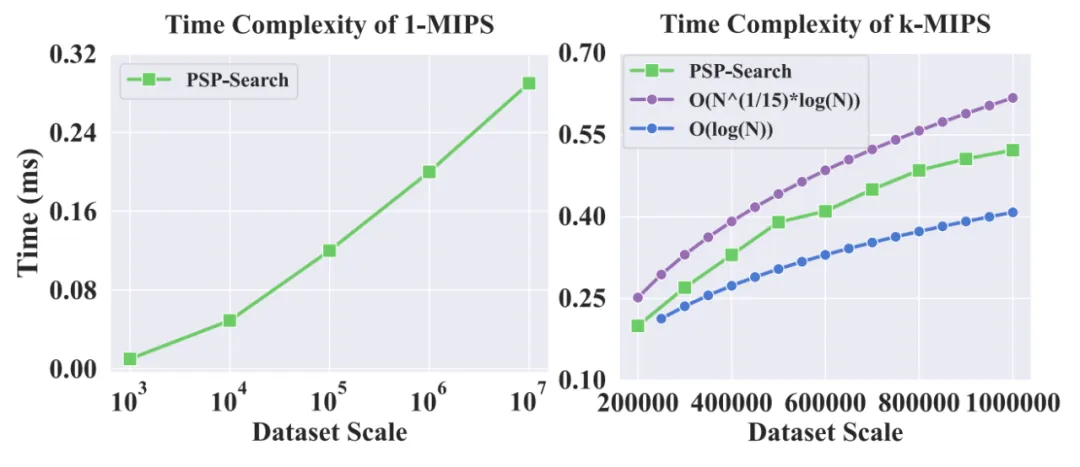
除了比较检索性能,另外一个考察向量检索算法的应用价值的重要维度是scalability。好的检索检索需要远低于线性增长的时间复杂度(time complexity)。
上图可以看出,PSP在Top 1-近邻上表现出log(N)速率增长的时间复杂度。而在Top-K检索上表现出接近log(N)的复杂度,这体现出PSP优秀的可扩展性,即在十亿乃至百亿级别的数据上进行高效检索的潜力。
论文链接:
https://arxiv.org/pdf/2503.06882
Github链接:
https://github.com/ZJU-DAILY/PSP
我是傅聪Cong,《业务驱动的推荐系统:方法与实践》作者,高性能向量检索算法NSG、SSG、PSP、MAG的发明者,生成式推荐模型OnePiece的发明者,资深算法专家,现居新加坡。
我们的算法团队和国内外很多一流大学和实验室都有长期paper合作,方向不限于大模型、搜推广、机器学习!
我们也非常欢迎各界研究者,一起合作探索出产学研结合、高可用性的算法!
开源主页:https://github.com/CongFu92