Linux io_uring 深度剖析: 重新定义高性能I/O的架构革命
一、引言: 为什么需要io_uring?
1.1 传统I/O模型的瓶颈
在io_uring出现之前, Linux已经历了多种I/O模型的演进:
但问题始终存在: 系统调用开销. 每次I/O操作都需要从用户态切换到内核态, 这个代价在现代高速存储设备面前显得格外沉重
1.2 存储设备的革命性变化
看看这个数据对比:
HDD时代 (2000年): ~100 IOPS, 延迟~10msSSD时代 (2010年): ~100K IOPS, 延迟~100μs NVMe时代 (2020年): ~1M IOPS, 延迟~10μs
当存储延迟从毫秒级降到微秒级, 系统调用开销(通常500-1000纳秒)就变得不可忽视. 这正是io_uring诞生的时代背景
二、io_uring的设计哲学
2.1 核心理念: 共享内存的协作
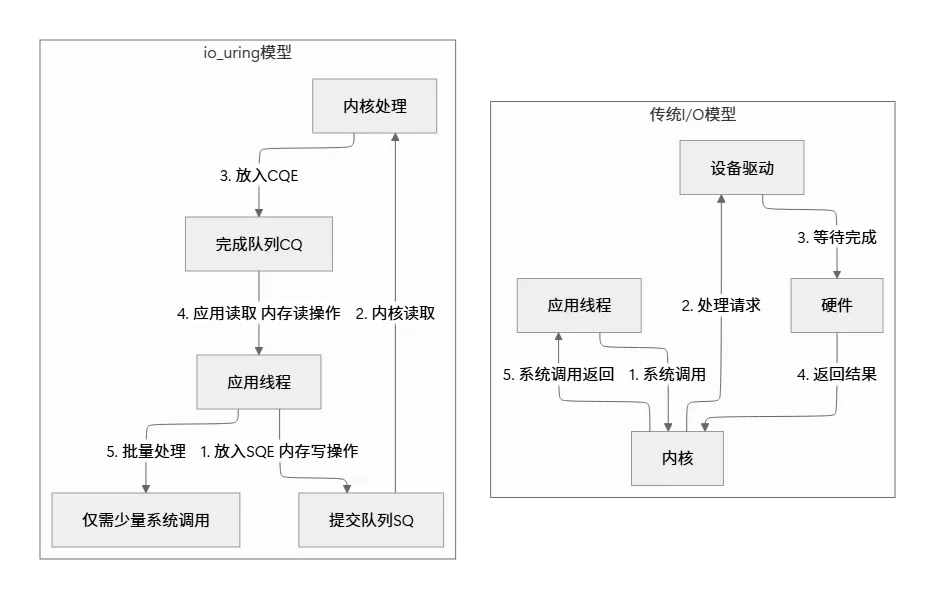
io_uring的核心思想可以用一句话概括: 通过用户态和内核态共享的内存区域, 实现零拷贝的请求提交和完成通知
这就像一个高度优化的餐厅后厨系统:
- • 传统模型: 每次点菜都要跑到厨房通知厨师(系统调用)
- • io_uring: 在餐厅和厨房之间放一个旋转传送带(共享环形队列), 顾客把订单放上传送带, 厨师直接取单, 做好后再放回另一个传送带
2.2 三大设计原则
- 1. 零拷贝: 请求和响应通过内存共享传递, 无需数据拷贝
- 2. 零系统调用: 理想情况下, I/O操作完全不需要系统调用
- 3. 批处理友好: 一次可以提交多个请求, 一次可以收割多个完成
三、核心架构与实现机制
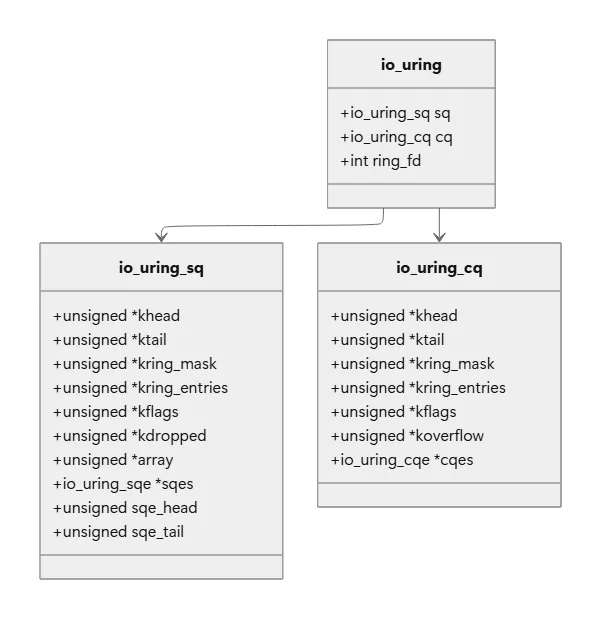
3.1 三个核心数据结构
/* 提交队列条目 - 代表一个I/O请求 */struct io_uring_sqe { __u8 opcode; /* 操作类型: read/write/accept等 */ __u8 flags; /* 标志位 */ __u16 ioprio; /* I/O优先级 */ __s32 fd; /* 文件描述符 */ __u64 off; /* 文件偏移 */ __u64 addr; /* 缓冲区地址或用户数据 */ __u32 len; /* 缓冲区长度 */union { __kernel_rwf_t rw_flags; /* R/W标志 */ __u32 fsync_flags; /* fsync标志 */ __u16 poll_events; /* poll事件 */ __u32 sync_range_flags; /* sync范围标志 */ }; __u64 user_data; /* 用户数据, 用于关联请求和响应 */union { __u16 buf_index; /* 固定缓冲区索引 */ __u64 __pad2[3]; /* 填充 */ };};/* 完成队列条目 - 代表一个完成的I/O */struct io_uring_cqe { __u64 user_data; /* 对应SQE的user_data */ __s32 res; /* 结果(类似返回值) */ __u32 flags; /* 标志位 */};/* 环结构 - 管理整个队列 */struct io_uring {struct io_uring_sq sq; /* 提交队列状态 */struct io_uring_cq cq; /* 完成队列状态 */ unsigned flags; /* io_uring标志 */ int ring_fd; /* io_uring文件描述符 */};
3.2 环形队列的魔法
环形队列是io_uring性能的关键. 它的设计非常精妙:
关键点:
- •
khead、ktail指针由内核和用户空间共享
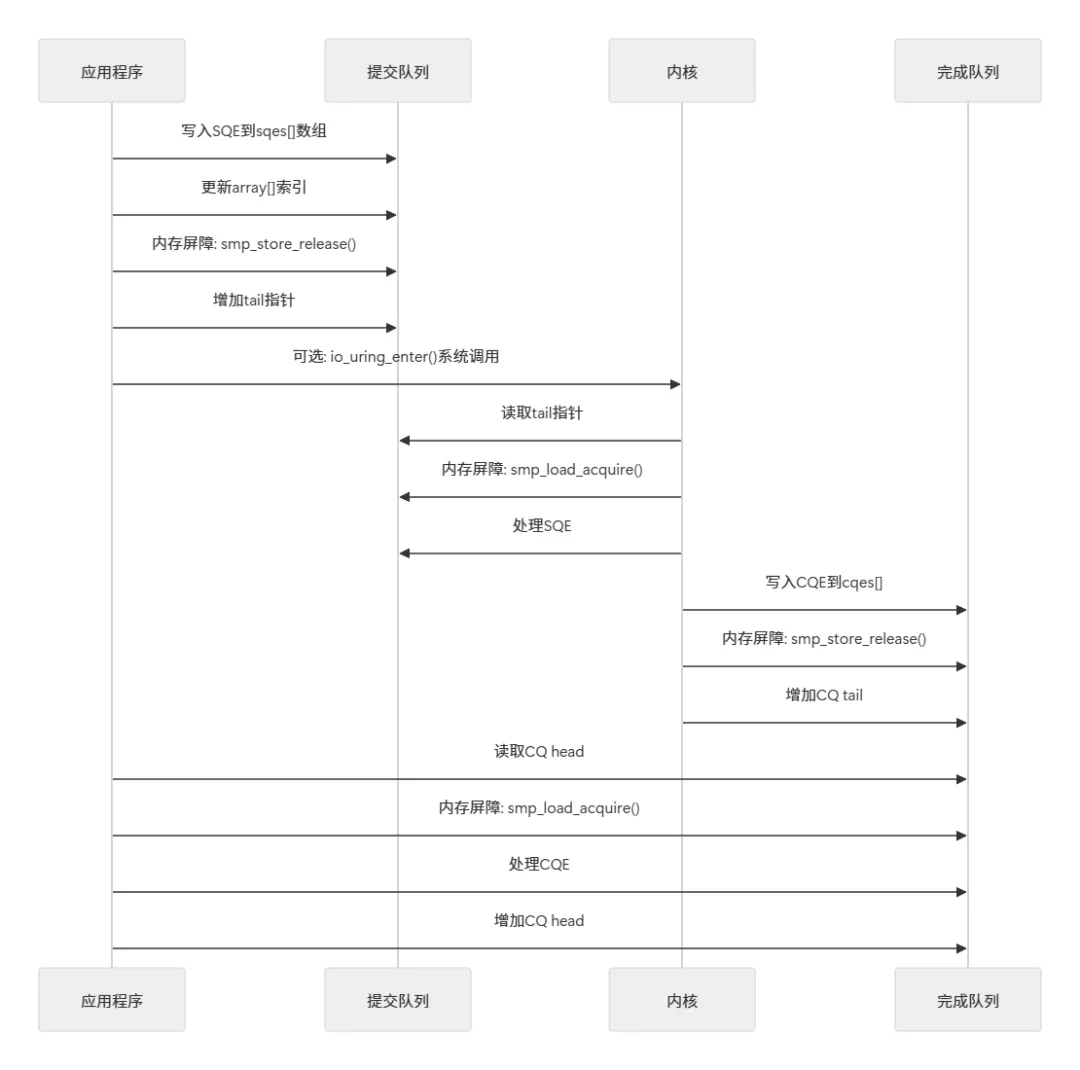
3.3 队列的同步机制
3.4 五种工作模式详解
四、io_uring的工作流程深度剖析
4.1 初始化阶段
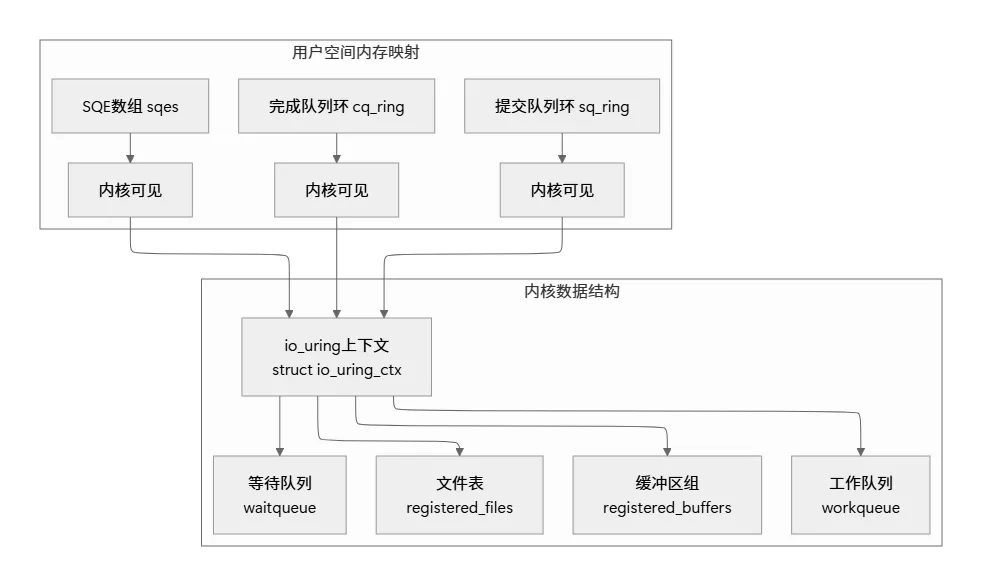
// 简化的初始化流程struct io_uring ring;io_uring_queue_init(ENTRIES, &ring, 0);// 实际发生的步骤: // 1. 内核创建io_uring实例// 2. 分配并映射三个内存区域: // - 提交队列环 (sq_ring)// - 完成队列环 (cq_ring) // - 提交队列条目数组 (sqes)// 3. 返回io_uring文件描述符
初始化过程的内存布局:
4.2 请求提交阶段
// 获取一个SQEstruct io_uring_sqe *sqe = io_uring_get_sqe(&ring);// 设置请求参数io_uring_prep_read(sqe, fd, buf, size, offset);sqe->user_data = (uintptr_t)my_data; // 用户自定义标识// 提交请求io_uring_submit(&ring);// 内部发生什么?// 1. 填充sqes数组中的条目// 2. 更新array映射// 3. 更新sq.tail指针// 4. 根据模式决定是否触发系统调用
4.3 内核处理阶段
内核视角的处理流程:
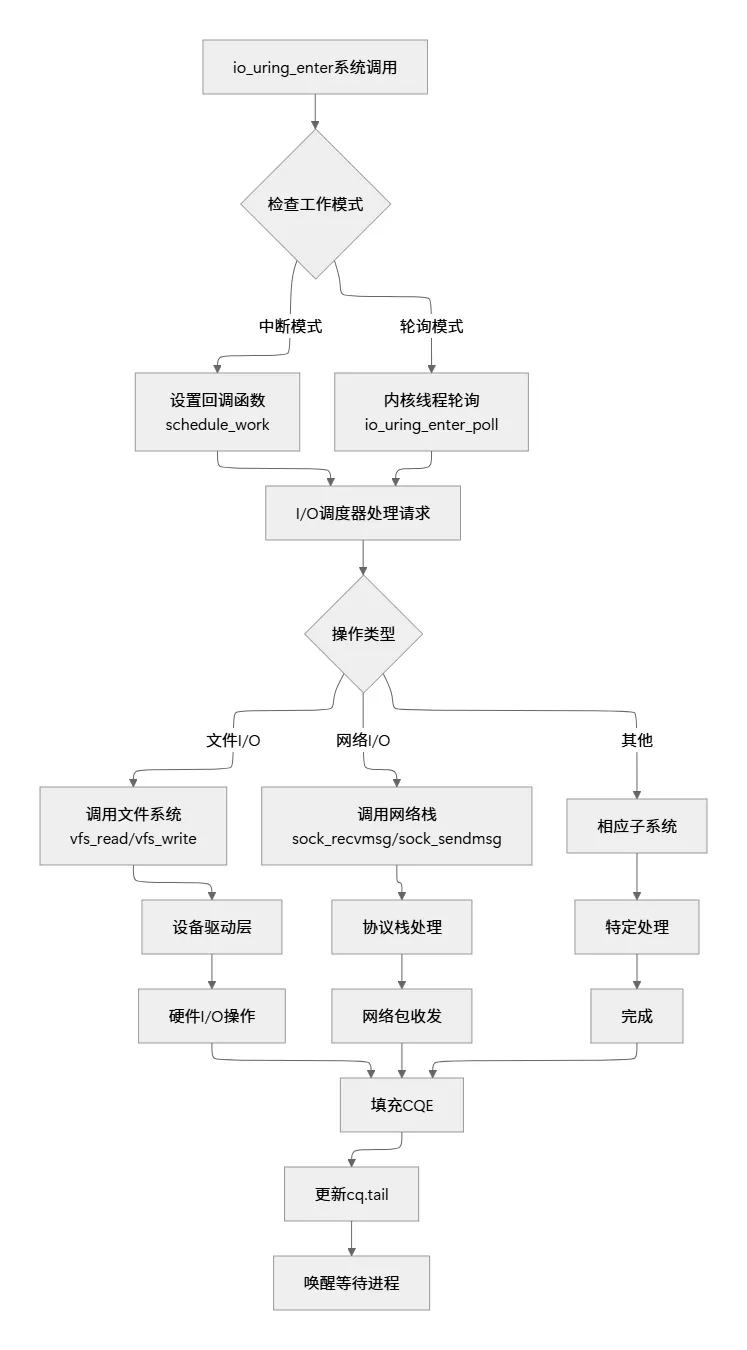
4.4 完成收割阶段
// 等待完成事件struct io_uring_cqe *cqe;int ret = io_uring_wait_cqe(&ring, &cqe);// 或者非阻塞检查int ret = io_uring_peek_cqe(&ring, &cqe);// 处理所有完成的请求unsigned head;int count = 0;io_uring_for_each_cqe(&ring, head, cqe) { // 处理完成事件 process_completion(cqe); count++;}// 标记这些CQE已处理io_uring_cq_advance(&ring, count);
五、高级特性详解
5.1 链接的SQE(链式操作)
io_uring支持请求依赖关系, 类似CPU的指令流水线:
// 创建链式操作: 读取 -> 处理 -> 写入struct io_uring_sqe *sqe1 = io_uring_get_sqe(&ring);struct io_uring_sqe *sqe2 = io_uring_get_sqe(&ring);struct io_uring_sqe *sqe3 = io_uring_get_sqe(&ring);// 读取数据io_uring_prep_read(sqe1, fd_in, buf1, size, 0);sqe1->flags |= IOSQE_IO_LINK; // 链接到下一条// 处理数据(假设是自定义操作)io_uring_prep_nop(sqe2);sqe2->flags |= IOSQE_IO_LINK; // 继续链接// 写入结果io_uring_prep_write(sqe3, fd_out, buf2, size, 0);// 不需要链接标志io_uring_submit(&ring);// 这三个操作会按顺序执行
5.2 固定文件和缓冲区
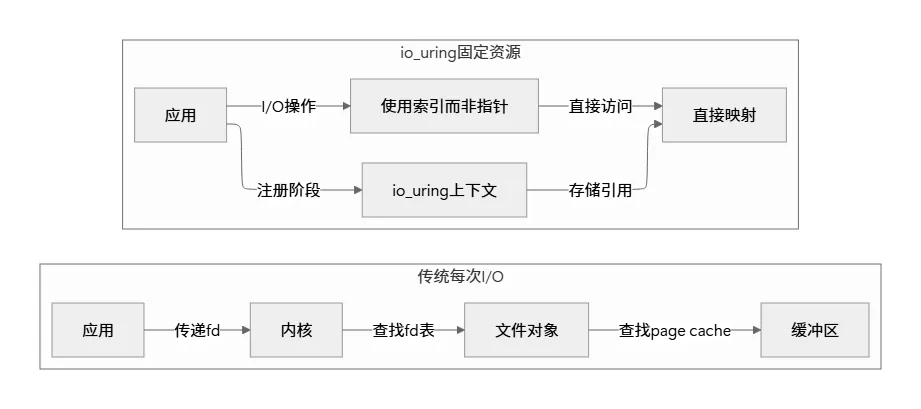
// 注册固定文件int fds[] = {fd1, fd2, fd3};io_uring_register_files(&ring, fds, 3);// 使用固定文件struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);io_uring_prep_read(sqe, 0, buf, size, 0); // 使用索引0sqe->flags |= IOSQE_FIXED_FILE;// 注册固定缓冲区struct iovec iov = {buf, size};io_uring_register_buffers(&ring, &iov, 1);// 使用固定缓冲区io_uring_prep_read_fixed(sqe, fd, 0, size, 0, 0); // 缓冲区索引0
5.3 轮询模式的工作原理
轮询模式是io_uring性能的终极武器:
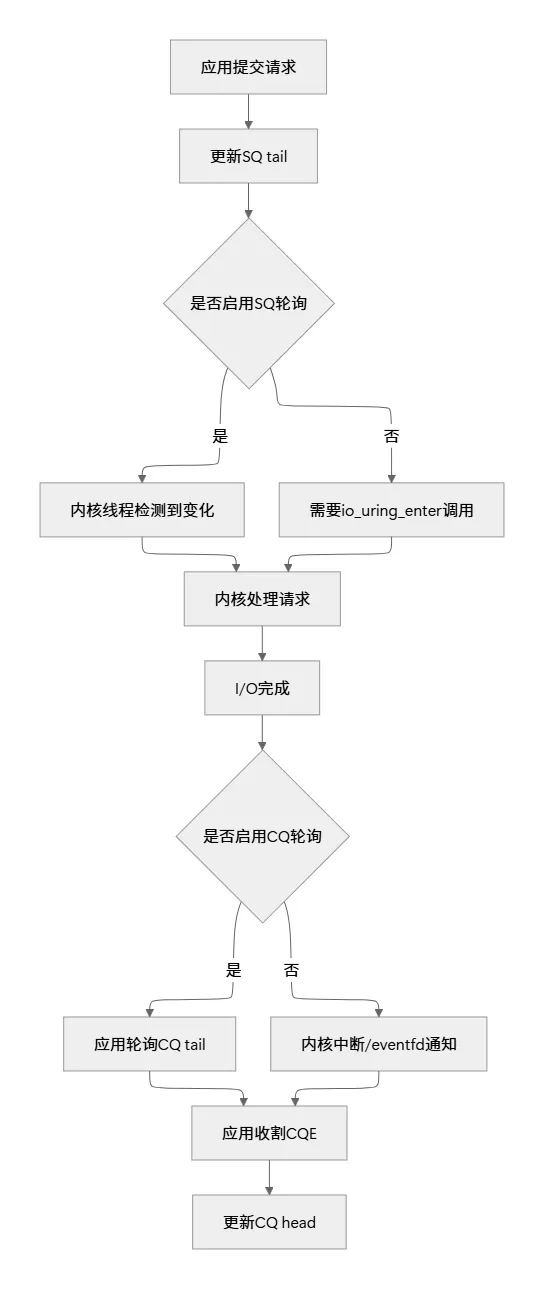
性能对比:
中断模式: 应用 <--中断--> 内核 <--中断--> 硬件轮询模式: 应用 <--内存访问--> 内核 <--轮询--> 硬件
六、实战示例: 构建简单的echo服务器
6.1 完整架构设计
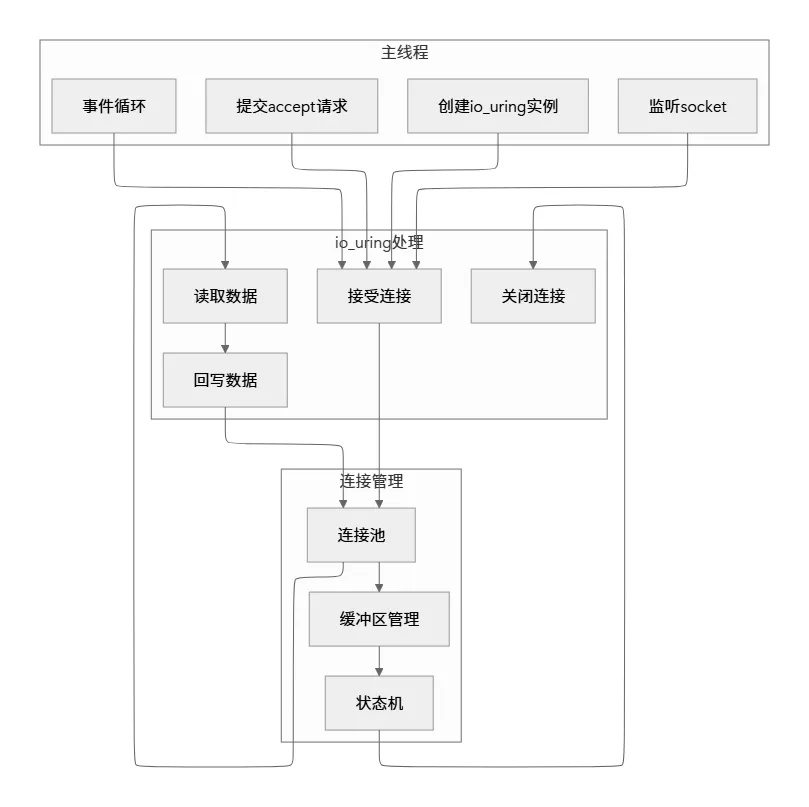
6.2 核心代码实现
#include <liburing.h>#include <string.h>#define ENTRIES 256#define MAX_CONNECTIONS 1024struct conn_info { int fd; unsigned type; // 类型: ACCEPT, READ, WRITE};int main() { // 1. 初始化io_uringstruct io_uring ring; io_uring_queue_init(ENTRIES, &ring, IORING_SETUP_SQPOLL); // 2. 创建监听socket int listen_fd = setup_listening_socket(8080); // 3. 提交初始accept请求struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);struct conn_info conn_i = { .fd = listen_fd, .type = ACCEPT }; io_uring_prep_multishot_accept(sqe, listen_fd, NULL, NULL, 0); io_uring_sqe_set_data64(sqe, (uint64_t)&conn_i); io_uring_submit(&ring); // 4. 事件循环 while (1) {struct io_uring_cqe *cqe; int ret = io_uring_wait_cqe(&ring, &cqe); if (ret < 0) break;struct conn_info *conn_i = (struct conn_info*)io_uring_cqe_get_data64(cqe); int res = cqe->res; if (conn_i->type == ACCEPT) { // 新连接 if (res > 0) {struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);struct conn_info *new_conn = malloc(sizeof(struct conn_info)); new_conn->fd = res; new_conn->type = READ; io_uring_prep_read(sqe, res, buffer, BUFFER_SIZE, 0); io_uring_sqe_set_data64(sqe, (uint64_t)new_conn); } // 重新提交accept(多shot模式) if (!(cqe->flags & IORING_CQE_F_MORE)) { sqe = io_uring_get_sqe(&ring); io_uring_prep_multishot_accept(sqe, listen_fd, NULL, NULL, 0); io_uring_sqe_set_data64(sqe, (uint64_t)&conn_i); } } else if (conn_i->type == READ) { if (res > 0) { // 读取成功, 准备写回 struct io_uring_sqe *sqe = io_uring_get_sqe(&ring); conn_i->type = WRITE; io_uring_prep_write(sqe, conn_i->fd, buffer, res, 0); io_uring_sqe_set_data64(sqe, (uint64_t)conn_i); } else { // 连接关闭 close(conn_i->fd); free(conn_i); } } else if (conn_i->type == WRITE) { // 写回完成, 准备下一次读 struct io_uring_sqe *sqe = io_uring_get_sqe(&ring); conn_i->type = READ; io_uring_prep_read(sqe, conn_i->fd, buffer, BUFFER_SIZE, 0); io_uring_sqe_set_data64(sqe, (uint64_t)conn_i); } io_uring_cq_advance(&ring, 1); io_uring_submit(&ring); } io_uring_queue_exit(&ring); return 0;}
七、性能优化与最佳实践
7.1 性能调优参数
7.2 内存对齐的重要性
// 错误示例: 未对齐的内存访问char buffer[1024];struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);io_uring_prep_read(sqe, fd, buffer, 1024, 0); // 可能未对齐// 正确示例: 确保内存对齐#define ALIGN_UP(x, align) (((x) + (align) - 1) & ~((align) - 1))size_t aligned_size = ALIGN_UP(1024, 4096);void *buffer = aligned_alloc(4096, aligned_size); // 页面对齐// 或者使用io_uring的固定缓冲区特性struct iovec iov = {buffer, aligned_size};io_uring_register_buffers(&ring, &iov, 1);
7.3 负载均衡策略
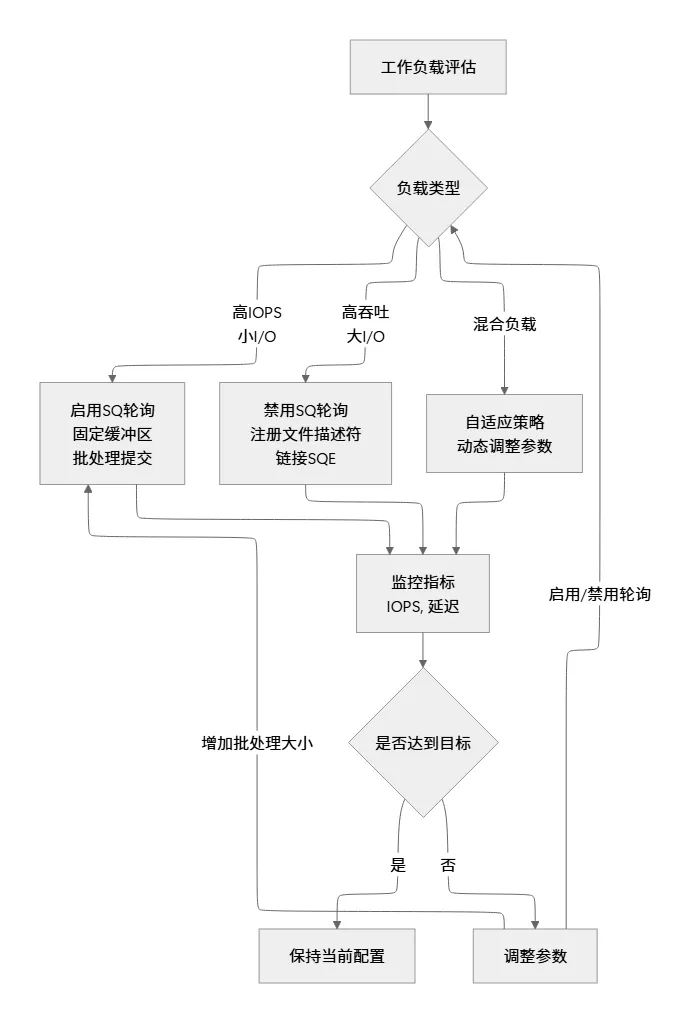
八、调试与监控工具
8.1 常用工具命令
# 1. 查看io_uring统计信息cat /proc/<pid>/io_uring# 输出示例: # SQEs: submitted=1000000, completed=999980# CQEs: reaped=999980, dropped=0# Poll: active=1, wakeups=50# 2. 使用bpftrace跟踪io_uringsudo bpftrace -e 'tracepoint:io_uring:io_uring_submit_sqe { printf("pid %d submitted sqe %llx\n", pid, args->sqe);}tracepoint:io_uring:io_uring_complete { printf("pid %d completed cqe %llx, res %d\n", pid, args->cqe, args->res);}'# 3. perf分析io_uring性能perf record -e io_uring:* -agperf report# 4. 使用liburing提供的工具./tools/io_uring-cp input.txt output.txt # 高性能文件复制./tools/io_uring-test # 运行测试套件
8.2 调试技巧
// 在调试版本中跟踪资源#define DEBUG_ALLOC 1#ifdef DEBUG_ALLOC static atomic_long_t sqe_count = 0; #define GET_SQE() ({ \ struct io_uring_sqe *__sqe = io_uring_get_sqe(&ring); \ if (__sqe) atomic_inc(&sqe_count); \ __sqe; \ })#endif
# 使用gdb检查io_uring状态gdb -p <pid>(gdb) call (void)io_uring_dump_status(uring_ptr)
九、io_uring生态系统
9.1 相关库和框架
| | |
|---|
| liburing | | |
| uring-rs | | |
| iouring | | |
| TokuMX | | |
| SPDK | | |
| Ceph | | |
9.2 内核集成状态
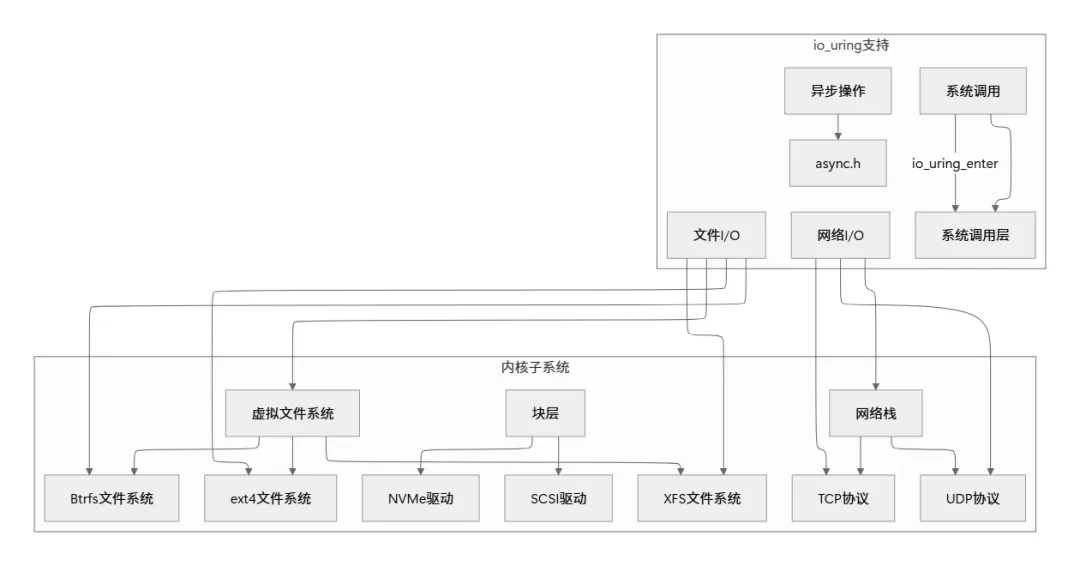
io_uring已深度集成到Linux内核多个子系统:
十、总结
10.1 技术对比表
| | | |
|---|
| 异步支持 | | | |
| 系统调用 | | | |
| 内存拷贝 | | | |
| 批处理 | | | |
| 链接操作 | | | |
| 轮询模式 | | | |
| 固定资源 | | | |
| 适用场景 | | | |
10.2 核心优势总结
- 1. 极致性能: 通过共享内存、零拷贝、批处理实现微秒级延迟
- 2. 统一模型: 统一文件、网络、定时器等各种I/O操作
- 4. 生态系统: 得到主流应用和内核子系统的广泛支持

