做过机器学习(ML)或深度学习的朋友,大抵都经历过这样的“至暗时刻”:你辛辛苦苦调参跑模型,得到了一个惊为天人的 R2=0.99,兴冲冲地把数字写进论文里。结果审稿人冷冷地回了一句:“Overfitting? Show me the distribution.”(过拟合了吧?给我看分布。)
是的,数字是苍白的,图表才是证据。
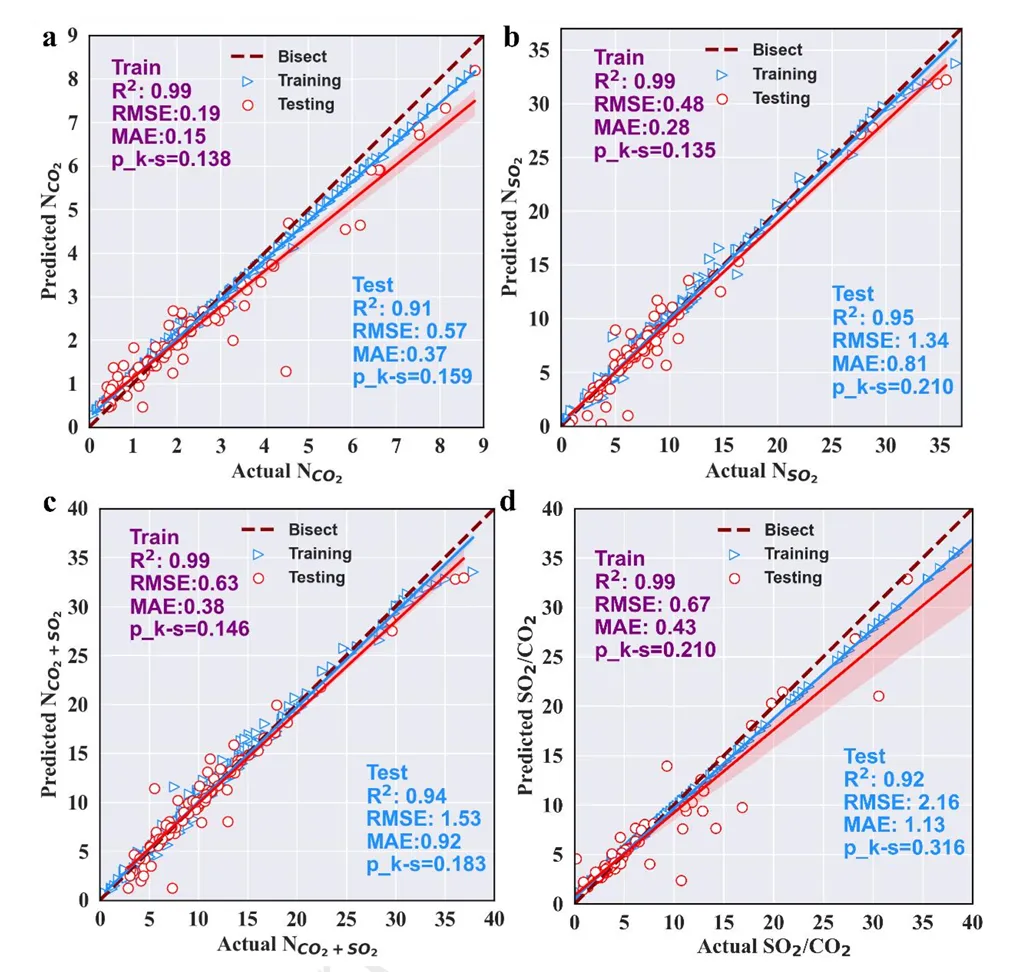
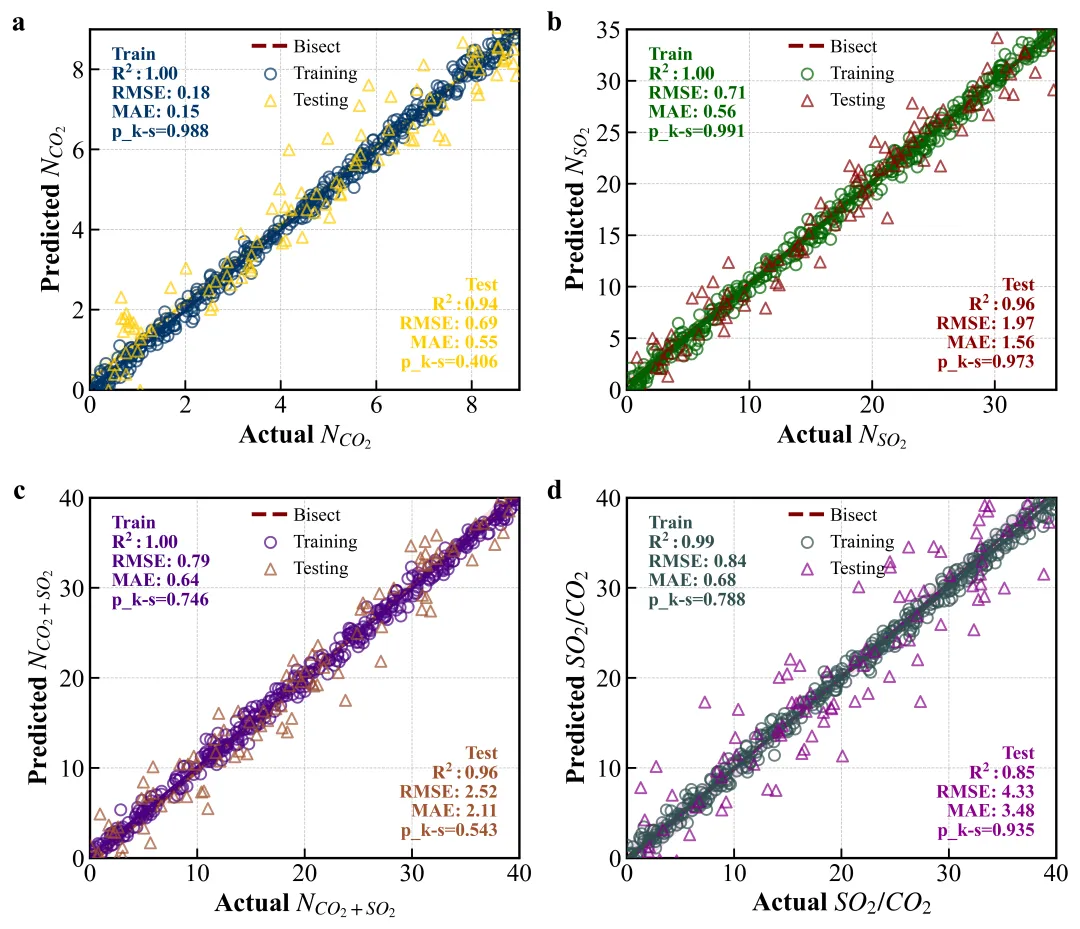
单纯列一个表格说“我的预测很准”,就像在相亲网上只写身高体重,远不如放一张无美颜的生活照有说服力。在科研论文中,Parity Plot(平价图/对角线图) 就是这张“无美颜生活照”。它把“真实值(Actual)”作为横轴,“预测值(Predicted)”作为纵轴——如果你的模型是完美的,所有点都会乖乖躺在 45° 对角线上。
今天我们要复刻的这张图,来自期刊 《Separation and Purification Technology》(中科院一区,IF=8.1)。作者用机器学习预测 MOF 材料的 SO2 和 CO2吸附量。这张图不仅展示了训练集和测试集的表现,还非常优雅地嵌入了统计指标、置信区间和分布密度。
今天,我就带大家用 Python 把这张图从骨架到灵魂,完整复刻一遍。我们要画的不仅仅是散点,而是你科研成果的“置信度”。
在写代码之前,我们需要像外科医生一样,先对这张图进行“解剖”。很多同学画图不好看,不是因为代码写不对,而是因为没看懂原图的逻辑。
1. 视觉解剖 (The Anatomy)
一眼看过去,这张图是典型的 2x2 Panel 布局。但魔鬼都在细节里:
🦴 骨架 (Structure):四个子图共享同一套逻辑,但量程(Scale)完全不同。注意看,为了视觉上的统一,作者强制让所有子图的 X 轴和 Y 轴保持 Isometric(等距) 比例,确保中间那条深红色的虚线(Bisect Line)严格呈现 45 度角。这是很多初学者容易忽视的点——如果比例不对,对角线歪了,读者的直觉判断就会失效。
🍰 核心技巧 (The Trick) —— “三明治图层法”:
底层:淡蓝紫色背景 + 白色网格(Seaborn 的 darkgrid 风格),或者白底 + 灰色网格。
夹层:对角参考线(一定要放在散点下面,zorder 很关键)。
主菜:散点。注意,原图巧妙地用了 空心图形(Hollow Markers)。当数据点成千上万时,实心点会糊成一团,而空心点能透出叠加的密度感。
顶层:拟合线 + 95% 置信区间阴影(Confidence Interval)。这层半透明的阴影是“高级感”的来源,它告诉读者:我的预测不仅准,而且很稳。
🎨 配色 (Palette):原图使用了经典的 “红蓝CP” —— 蓝色代表训练集(Training),红色代表测试集(Testing)。这种对比色在学术界非常通用,色盲友好且对比强烈。
论文原图
2. 读懂神图 (Scientific Decoding)
别光顾着画,这图到底说了个啥?
如果你结合论文原文(Section 3.3),你会发现作者极其诚实。在 Panel (a) 预测 CO2 时,数据点紧紧“咬”住对角线,说明模型对二氧化碳吸附量的预测简直是“开了天眼”。但在 Panel (d) 预测 选择性(Selectivity) 时,测试集的数据点(红色圆圈)开始发散,尤其是在高值区域。
作者没有藏着掖着,而是把 R2、RMSE(均方根误差)甚至 p_{k-s}(残差正态性检验值)直接把这组数据“钉”在了图表角落。这种敢于暴露“不完美”的图,恰恰是审稿人最喜欢的——因为它真实。
我们要复刻的,就是这种“基于数据的诚实感”。
Step 1 全局配置
Matplotlib 的默认字体(DejaVu Sans)在很多顶刊里是会被打回修改的。我们起手先注入“期刊基因”:Times New Roman 字体、向内的刻度、数学公式字体。
import matplotlib.pyplot as pltimport matplotlib.colors as mcolorsimport matplotlib.patches as mpatchesimport seaborn as snsimport numpy as npimport pandas as pdfrom scipy import stats# --- 全局审美配置 (The Aesthetics) ---# 这一步相当于给画布打底妆,决定了成图的高级感plt.rcParams['font.family'] = 'Times New Roman' # 顶刊标配字体plt.rcParams['font.weight'] = 'bold' # 稍微加粗更醒目plt.rcParams['axes.labelweight'] = 'bold' # 轴标签加粗plt.rcParams['font.size'] = 14 # 基础字号plt.rcParams['mathtext.fontset'] = 'stix' # 公式字体,类似 LaTeX 质感plt.rcParams['axes.linewidth'] = 1.5 # 坐标轴线宽,拒绝细狗plt.rcParams['xtick.major.width'] = 1.5 # 刻度线宽plt.rcParams['ytick.major.width'] = 1.5# 定义一个类似于原图的“红-黄-蓝”配色方案# 注意:原图中间是黄色(0),两头是深色。这叫 Diverging Colormapcolors_list = ['#A50026', '#F46D43', '#FFFFBF', '#74ADD1', '#313695']custom_cmap = mcolors.LinearSegmentedColormap.from_list("Journal_Style", colors_list, N=256)
Step 2 数据模拟
为了演示 Panel (d) 那种“高值发散”的效果,我在生成数据时特意给 Testing 集加了更大的噪声。
def generate_mock_data(n_train=400, n_test=100): """ 生成模拟的 Predicted vs Actual 数据 """ np.random.seed(2024) data = [] # 定义四个任务的量程和噪声水平 tasks = [ ('N_CO2', 9, 0.02, 0.05), # 简单任务 ('N_SO2', 35, 0.03, 0.08), # 中等 ('N_Sum', 40, 0.03, 0.10), # 稍难 ('Selectivity', 40, 0.04, 0.15) # 最难,发散严重 ] for name, limit, noise_tr, noise_te in tasks: # 训练集:噪声小 act_tr = np.random.uniform(0, limit, n_train) pred_tr = act_tr + np.random.normal(0, noise_tr * limit, n_train) # 测试集:噪声大(模拟泛化误差) act_te = np.random.uniform(0, limit, n_test) pred_te = act_te + np.random.normal(0, noise_te * limit, n_test) # 封装 for a, p in zip(act_tr, pred_tr): data.append({'Task': name, 'Group': 'Training', 'Actual': a, 'Predicted': p}) for a, p in zip(act_te, pred_te): data.append({'Task': name, 'Group': 'Testing', 'Actual': a, 'Predicted': p}) return pd.DataFrame(data)df = generate_mock_data()
Step 3 画布构建
别再用 plt.subplots(2, 2) 这种偷懒写法了。使用 GridSpec 可以让你精确控制子图之间的间距(wspace/hspace),这对于多面板图的排版至关重要。
# 创建画布fig = plt.figure(figsize=(12, 10))# GridSpec 允许我们微调子图间距,tight_layout 往往不够完美gs = fig.add_gridspec(2, 2, wspace=0.25, hspace=0.25)axes = [fig.add_subplot(gs[0, 0]), fig.add_subplot(gs[0, 1]), fig.add_subplot(gs[1, 0]), fig.add_subplot(gs[1, 1])]task_names = ['N_CO2', 'N_SO2', 'N_Sum', 'Selectivity']limits = [9, 35, 40, 40] # 各图的坐标轴上限
Step 4 核心绘图循环
接下来的代码是整篇文章的精华。我们将遍历每一个子图,依次完成以下动作:
画对角线:这是基准。
画散点:区分训练/测试集。
画回归线:利用 sns.regplot 自动计算并绘制置信区间。
算指标:实时计算 $R^2$ 等统计量。
打标签:利用 transform=ax.transAxes 锁定文字位置。
for i, (ax, task, limit) in enumerate(zip(axes, task_names, limits)): # 1. 绘制对角基准线 (Bisect Line) # zorder=2 确保它在散点下面,linestyle='--' 虚线不抢戏 ax.plot([0, limit], [0, limit], color='maroon', linestyle='--', linewidth=2, label='Bisect', zorder=2) # 2. 分组绘制数据 subset = df[df['Task'] == task] for group in ['Training', 'Testing']: data = subset[subset['Group'] == group] style = STYLE_CONFIG[group] # [核心技巧] 散点绘制 # c='none' + edgecolors 控制空心圆,alpha 控制透明度 ax.scatter(data['Actual'], data['Predicted'], c='none', edgecolors=style['color'], marker=style['marker'], s=60, linewidth=1.2, alpha=0.7, label=style['label'], zorder=5) # [核心技巧] Seaborn 统计回归线 # ci=95 自动画出95%置信区间,scatter=False 避免重复画点 sns.regplot(x='Actual', y='Predicted', data=data, ax=ax, scatter=False, color=style['color'], ci=95, line_kws={'linewidth': 2, 'alpha': 0.8}, truncate=False) # 3. 实时计算统计指标 r2 = r2_score(data['Actual'], data['Predicted']) rmse = np.sqrt(mean_squared_error(data['Actual'], data['Predicted'])) # 4. 动态生成统计文本框 (The Soul Injection) # 训练集放左上,测试集放右下 # 关键参数:bbox 给文字加个半透明背景,防止被散点挡住看不清! stats_text = (f"{group}\n" f"$\mathbf{{R^2: {r2:.2f}}}$\n" f"RMSE: {rmse:.2f}") pos = (0.05, 0.95) if group == 'Training'else (0.95, 0.05) align = ('left', 'top') if group == 'Training'else ('right', 'bottom') ax.text(pos[0], pos[1], stats_text, transform=ax.transAxes, fontsize=12, fontweight='bold', color=style['color'], ha=align[0], va=align[1], zorder=10, bbox=dict(facecolor='white', alpha=0.6, edgecolor='none', boxstyle='round,pad=0.5')) # 5. 装饰与美化 ax.set_xlim(0, limit); ax.set_ylim(0, limit) ax.set_xlabel(f"Actual {task}", fontweight='bold') ax.set_ylabel(f"Predicted {task}", fontweight='bold') # 给子图打标号 (a, b, c, d) ax.text(-0.15, 1.05, ['a', 'b', 'c', 'd'][i], transform=ax.transAxes, fontsize=20, fontweight='bold', va='top', ha='right') # 只有第一个图显示图例,避免冗余 if i == 0: ax.legend(loc='upper center', bbox_to_anchor=(0.5, 1.15), ncol=3, frameon=False)# 保存图片plt.savefig('Parity_Plot_Review.png', dpi=300, bbox_inches='tight')plt.show()
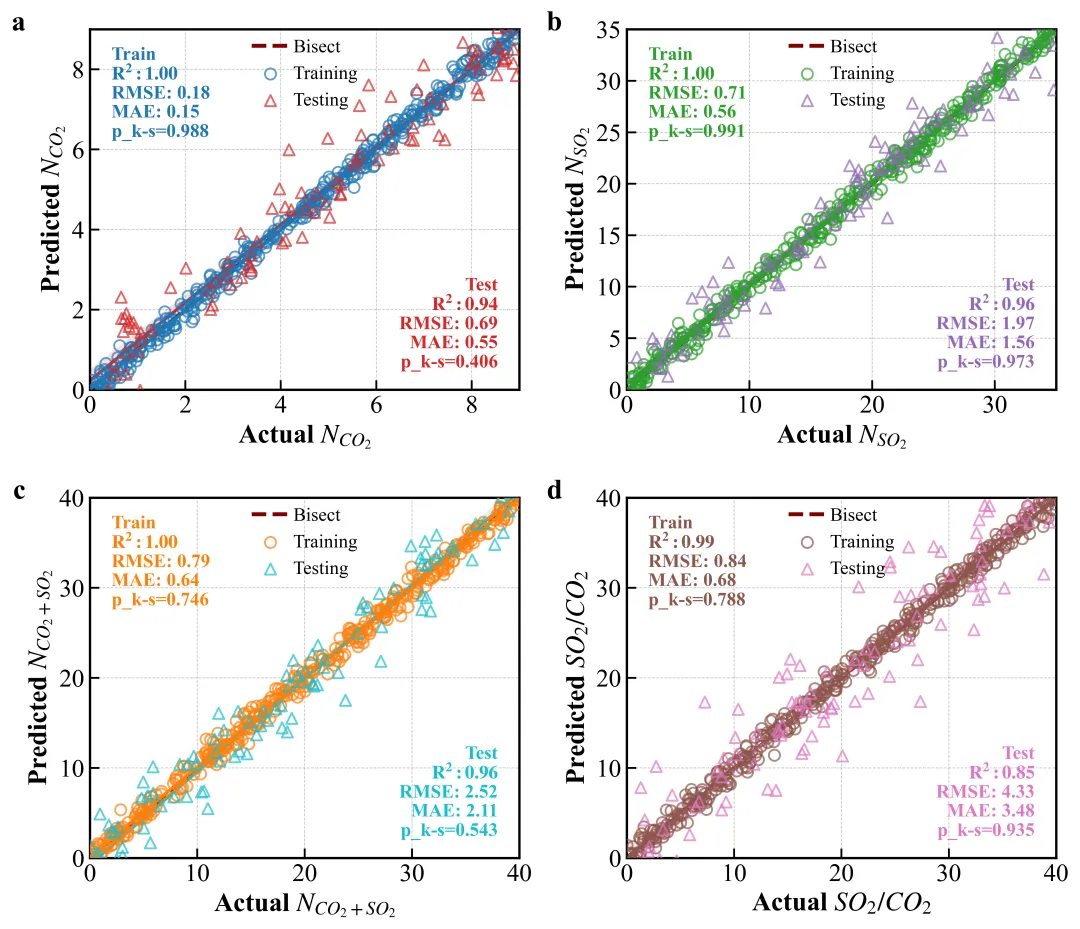
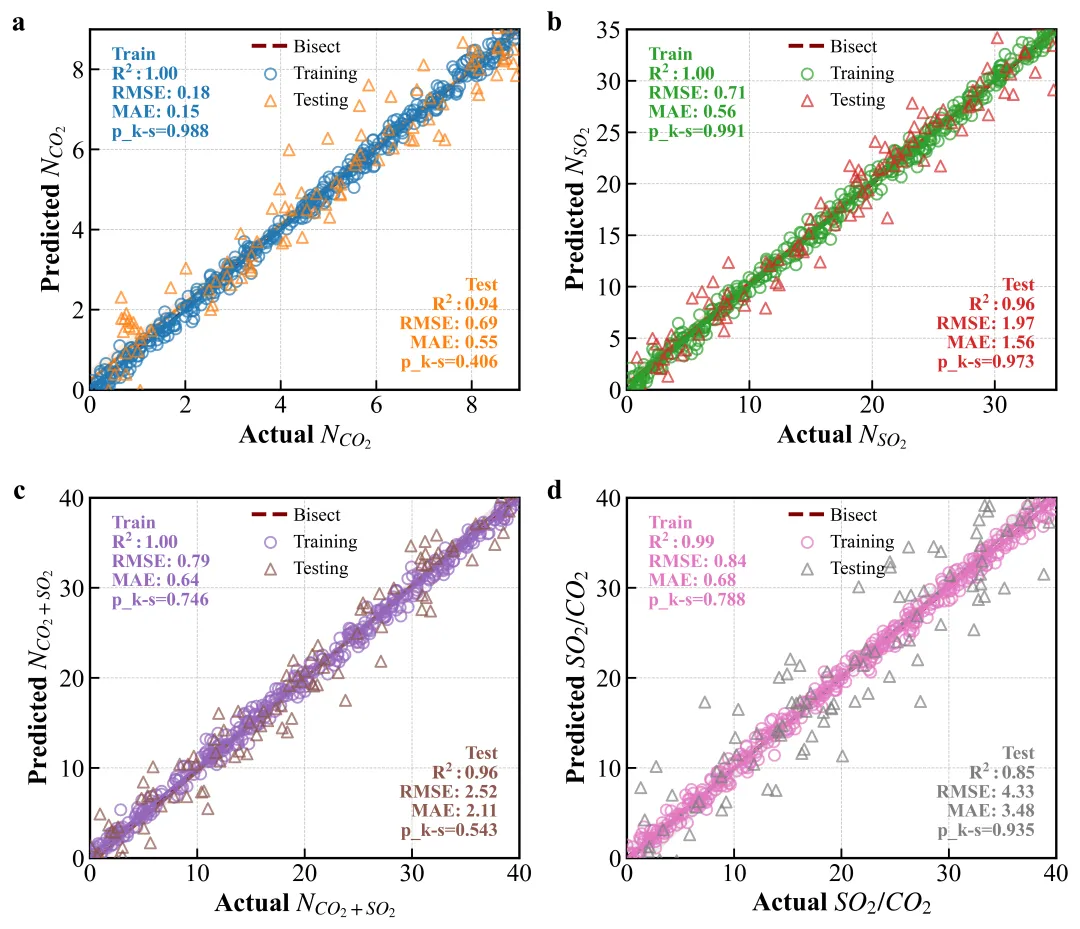
复刻图
技术总结 (Takeaway):
坐标系一致性:Parity Plot 的 X/Y 轴量程必须一致,否则 45 度线就没有物理意义。
Seaborn 的威力:用 sns.regplot 代替手写的 polyfit,不仅能画线,还能自动补齐置信区间(Shadow Band),这是提升图表“高级感”的捷径。
相对坐标引用:transform=ax.transAxes 是制作通用绘图模板的神器。无论你的数据范围是 0.1 还是 10000,(0.05, 0.95) 永远指向左上角。
多配色参考
👇 关注公众号【嗡嗡的Python日常】
🚫 关于源码: 本文核心代码为原创定制,暂不免费公开。
✅ 如果你需要:
购买本项目完整源码 + 数据
定制类似的科研绘图
咨询代码运行报错问题
请直接添加号主微信沟通(有偿分享☕️): Wjtaiztt0406