并行计算 (二) GPU从3D着色器编程到AI向量计算
- 2026-06-27 20:40:02
本篇是这个系列的第二篇,上一篇我们了解到GPU如何基于SM的计算单元和Wrap调度器来实现并行计算,并通过CPU和GPU协作,来实现CUDA的编程,那么这些GPU的并行计算都是用于什么的呢?其实早期SM主要用于3D游戏的着色器渲染,用于实现更炫酷,更逼真的光影效果,随着AIGC在这些年的爆火,GPU并行计算的可编程性在AI框架和CUDA编程的双重推动下,成为AI算子的一个实现方式。
这个话题会从「什么是着色器?3D模型渲染为什么要转换成三角形且使用着色器来实现 -->什么是GLSL,其与CPU是如何配合实现的 --> 一个简单的着色器demo实现3D正方体渲染 --> 为什么说向量运算是AI模型训练和推理的基础?它对并行计算有什么要求 --> 如何基于CUDA实现一次向量计算」这几个维度来介绍如何基于GPU实现着色器和向量计算的。
一、什么是着色器?3D 模型渲染,为何必拆三角形 + 必用着色器?
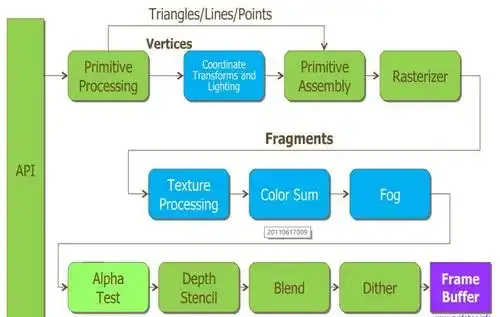
1. 什么是着色器?
着色器(Shader)是运行在GPU上的小程序,用于实现图形渲染管线中的特定阶段计算。它取代了传统图形处理中固定的渲染流程,使开发者能够自定义渲染效果,实现更丰富的视觉体验。
3D模型在渲染前必须转换为三角形,这是因为:
1. 三角形是最基本的图元:如知识库[10]所述,"三角形作为最基础的图元,其像素化处理过程直接影响渲染质量和性能表现"。任何复杂的3D形状都可以由三角形网格表示。 2. GPU的并行处理特性:GPU特别擅长处理大量相同类型的操作。三角形的像素化处理(将三角形转换为屏幕上可见的像素)可以被GPU的并行架构高效完成,正如知识库[1]所述,"GPU特别擅长同时处理许多小任务,非常适合这种精细的操作"。 3. 渲染管线的标准化:图形API(如OpenGL、DirectX)将渲染流程标准化为顶点处理、几何处理、光栅化和像素处理等阶段。三角形作为基础图元,能无缝融入这一流程。
使用着色器实现渲染的优势在于:
• 顶点着色器:处理顶点位置、法线等几何信息 • 几何着色器:可生成新顶点,改变图元(如将点转换为三角形) • 片段着色器:计算每个像素的颜色
2. 为什么所有 3D 模型,都要拆解成「三角形面片」?
不管是游戏中的人物、场景、正方体,还是工业建模的复杂曲面,在送入 GPU 渲染前,一定会被拆解为无数个三角形的拼接组合。这不是人为规定的标准,而是图形学原理 + GPU 硬件设计的双重最优解,也是唯一解,核心原因有 3 点,优先级从高到低,缺一不可:
1. 三角形是「最小的平面几何基元」,无任何几何失真:GPU 只能处理平面图形,而 3D 模型的表面都是曲面。三角形由三个顶点唯一确定一个平面,不会出现扭曲、重叠、变形;如果用四边形 / 多边形,极易出现非平面的扭曲,导致渲染错误。任何曲面都可以通过「足够多的小三角形」无限逼近,三角形数量越多,模型的曲面越平滑,画质越好。 2. GPU 硬件「原生集成三角形光栅化单元」,极致硬件加速:GPU 芯片上,除了 SM 计算单元、Warp 调度器,还有一个独立的固定功能硬件模块 —— 三角形光栅化单元。这个模块是 GPU 出厂固化的电路,专门负责将三角形的顶点坐标,快速填充为屏幕上的像素点,其效率是软件实现的百倍以上,GPU 天生为三角形设计,处理三角形的效率无出其右。 3. 三角形的计算逻辑极简,完美适配 GPU 并行计算:三角形仅有 3 个顶点,顶点的颜色、法线、纹理坐标等属性,可通过「线性插值」快速计算出三角形内部所有像素的对应属性。这个插值计算是纯并行、无依赖的,刚好匹配 GPU 的 SIMT 架构,而多边形的插值计算复杂,会产生大量串行逻辑,完全发挥不出 GPU 的并行优势。
3:为什么 3D 渲染,必须用着色器实现?
这个问题的答案,本质是「GPU 的核心能力是并行计算,而着色器是 GPU 并行计算在图形渲染上的唯一落地形式」,也是 CPU 与 GPU 的核心能力差异体现,核心原因有 3 点:
1. CPU 完全无法支撑实时 3D 渲染的并行计算需求:CPU 是「强单核、少线程」的架构,擅长串行逻辑处理。一张 1080P 的屏幕有 207 万个像素,一个 3D 模型有几十万甚至上千万个顶点,每个顶点 / 像素都需要独立的计算逻辑,CPU 串行处理需要几秒甚至十几秒,而 GPU 通过着色器的并行线程,仅需几毫秒就能完成,这是数量级的效率差距。 2. 着色器的「可编程性」,打破了固定渲染管线的局限性:早期 GPU 没有可编程着色器,只有「固定渲染管线」—— 渲染逻辑是 GPU 固化的,开发者只能调整少量参数,无法自定义光影、材质效果,3D 画面的表现力极其有限。而着色器的出现,让开发者可以自定义并行计算逻辑:修改顶点着色器就能实现模型变形、动画效果;修改片元着色器就能实现卡通渲染、光线追踪、全局光照等特效,着色器的可编程性,是 3D 游戏画质飞跃的核心驱动力。 3. 着色器的执行流程,完美匹配 3D 渲染的流水线:3D 渲染的完整流程是「顶点数据输入 → 顶点着色器并行变换 → 三角形装配 → 光栅化生成像素 → 片元着色器并行上色 → 屏幕输出」。这个流水线中,两个最核心的计算密集型环节,都是着色器的并行计算,没有着色器,GPU 只能处理原始的顶点 / 像素数据,无法完成任何有意义的 3D 渲染。
二、什么是GLSL,其与CPU是如何配合实现的
GLSL(OpenGL着色器语言)是用于编写着色器的编程语言,是OpenGL图形API的一部分,也是目前最通用、跨平台的着色器语言(适配 OpenGL/Vulkan,兼容绝大多数 GPU),我们日常开发的着色器程序,90% 都是基于 GLSL 编写的。它是一种类似C的高级语言,专为GPU着色器编程设计。
GLSL与CPU的协作流程:
1. CPU准备数据:CPU通过OpenGL API设置渲染状态,准备顶点数据、纹理等。 2. CPU编译GLSL:CPU将GLSL代码编译为GPU可执行的着色器程序。 3. CPU 配置渲染管线 + 传递参数:CPU 通过图形 API,配置 GPU 的渲染管线状态,并将第一步准备好的数据传递并绑定到 GPU 的指定内存地址 4. GPU执行着色器:GPU在渲染管线中调用编译好的着色器,对顶点、图元和像素进行处理。 5. GPU 输出渲染结果,CPU 完成收尾:GPU 完成所有像素的颜色计算后,将最终的像素数据写入「帧缓冲区」,并将帧缓冲区的内容输出到屏幕上,形成我们看到的 3D 画面;CPU 此时可以执行后续的收尾工作,比如释放临时资源、更新下一帧的相机参数等,为下一次渲染做准备。
三者分工的核心总结
CPU = 总指挥 + 后勤保障:负责串行调度、数据准备、配置管理、指令发送,不做任何密集计算;
GLSL = GPU 的并行计算代码:是运行在 GPU 上的「并行小程序」,负责实现渲染的核心计算逻辑;
GPU = 超级并行计算工人:负责执行 GLSL 代码,完成海量顶点 / 像素的并行计算,依靠 SM+Warp 发挥极致算力;
三者的协作,本质是「CPU 的串行优势」与「GPU 的并行优势」的完美结合,也是所有 GPU 编程(包括 CUDA)的核心思想。
三、实战 Demo:GLSL 着色器实现 3D 正方体渲染
这个示例展示了如何通过GLSL着色器实现3D正方体渲染。CPU负责设置渲染状态和数据,GPU则通过着色器执行顶点变换和像素着色.
// main.cpp - 完整的旋转彩色立方体#include<GL/glew.h>#include<GLFW/glfw3.h>#include<glm/glm.hpp>#include<glm/gtc/matrix_transform.hpp>#include<glm/gtc/type_ptr.hpp>#include<iostream>#include<vector>// 着色器源代码constchar* vertexShaderSource = R"(#version 460 corelayout(location = 0) in vec3 aPos;layout(location = 1) in vec3 aColor;out vec3 vertexColor;uniform mat4 model;uniform mat4 view;uniform mat4 projection;void main() { gl_Position = projection * view * model * vec4(aPos, 1.0); vertexColor = aColor;})";constchar* fragmentShaderSource = R"(#version 460 corein vec3 vertexColor;out vec4 FragColor;void main() { FragColor = vec4(vertexColor, 1.0);})";// 立方体数据:36个顶点(12个三角形 * 3个顶点)float vertices[] = {// 位置 // 颜色// 前平面 (红色)-0.5f, -0.5f, 0.5f, 1.0f, 0.0f, 0.0f,0.5f, -0.5f, 0.5f, 1.0f, 0.0f, 0.0f,0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 0.0f,0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 0.0f,-0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 0.0f,-0.5f, -0.5f, 0.5f, 1.0f, 0.0f, 0.0f,// 后平面 (绿色)-0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 0.0f,0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 0.0f,0.5f, 0.5f, -0.5f, 0.0f, 1.0f, 0.0f,0.5f, 0.5f, -0.5f, 0.0f, 1.0f, 0.0f,-0.5f, 0.5f, -0.5f, 0.0f, 1.0f, 0.0f,-0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 0.0f,// 左平面 (蓝色)-0.5f, 0.5f, 0.5f, 0.0f, 0.0f, 1.0f,-0.5f, 0.5f, -0.5f, 0.0f, 0.0f, 1.0f,-0.5f, -0.5f, -0.5f, 0.0f, 0.0f, 1.0f,-0.5f, -0.5f, -0.5f, 0.0f, 0.0f, 1.0f,-0.5f, -0.5f, 0.5f, 0.0f, 0.0f, 1.0f,-0.5f, 0.5f, 0.5f, 0.0f, 0.0f, 1.0f,// 右平面 (黄色)0.5f, 0.5f, 0.5f, 1.0f, 1.0f, 0.0f,0.5f, 0.5f, -0.5f, 1.0f, 1.0f, 0.0f,0.5f, -0.5f, -0.5f, 1.0f, 1.0f, 0.0f,0.5f, -0.5f, -0.5f, 1.0f, 1.0f, 0.0f,0.5f, -0.5f, 0.5f, 1.0f, 1.0f, 0.0f,0.5f, 0.5f, 0.5f, 1.0f, 1.0f, 0.0f,// 上平面 (品红色)-0.5f, 0.5f, -0.5f, 1.0f, 0.0f, 1.0f,0.5f, 0.5f, -0.5f, 1.0f, 0.0f, 1.0f,0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 1.0f,0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 1.0f,-0.5f, 0.5f, 0.5f, 1.0f, 0.0f, 1.0f,-0.5f, 0.5f, -0.5f, 1.0f, 0.0f, 1.0f,// 下平面 (青色)-0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 1.0f,0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 1.0f,0.5f, -0.5f, 0.5f, 0.0f, 1.0f, 1.0f,0.5f, -0.5f, 0.5f, 0.0f, 1.0f, 1.0f,-0.5f, -0.5f, 0.5f, 0.0f, 1.0f, 1.0f,-0.5f, -0.5f, -0.5f, 0.0f, 1.0f, 1.0f};// 编译着色器辅助函数GLuint compileShader(GLenum type, constchar* source){ GLuint shader = glCreateShader(type);glShaderSource(shader, 1, &source, NULL);glCompileShader(shader);// 检查编译错误 GLint success;glGetShaderiv(shader, GL_COMPILE_STATUS, &success);if (!success) {char infoLog[512];glGetShaderInfoLog(shader, 512, NULL, infoLog); std::cout << "着色器编译错误: " << infoLog << std::endl; }return shader;}intmain(){// 初始化GLFWif (!glfwInit()) return-1;// 创建窗口 GLFWwindow* window = glfwCreateWindow(800, 600, "3D立方体Demo", NULL, NULL);if (!window) {glfwTerminate();return-1; }glfwMakeContextCurrent(window);// 初始化GLEWif (glewInit() != GLEW_OK) { std::cout << "GLEW初始化失败" << std::endl;return-1; }// 启用深度测试glEnable(GL_DEPTH_TEST);// 编译链接着色器 GLuint vertexShader = compileShader(GL_VERTEX_SHADER, vertexShaderSource); GLuint fragmentShader = compileShader(GL_FRAGMENT_SHADER, fragmentShaderSource); GLuint shaderProgram = glCreateProgram();glAttachShader(shaderProgram, vertexShader);glAttachShader(shaderProgram, fragmentShader);glLinkProgram(shaderProgram);// 清理着色器对象glDeleteShader(vertexShader);glDeleteShader(fragmentShader);// 创建顶点缓冲区和顶点数组对象 GLuint VBO, VAO;glGenVertexArrays(1, &VAO);glGenBuffers(1, &VBO);glBindVertexArray(VAO);glBindBuffer(GL_ARRAY_BUFFER, VBO);glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);// 位置属性glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0);glEnableVertexAttribArray(0);// 颜色属性glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)(3 * sizeof(float)));glEnableVertexAttribArray(1);// 解绑glBindBuffer(GL_ARRAY_BUFFER, 0);glBindVertexArray(0);// 渲染循环while (!glfwWindowShouldClose(window)) {// 清除缓冲glClearColor(0.1f, 0.1f, 0.1f, 1.0f);glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);// 使用着色器程序glUseProgram(shaderProgram);// 创建变换矩阵float time = glfwGetTime();// 模型矩阵:旋转 glm::mat4 model = glm::mat4(1.0f); model = glm::rotate(model, time * glm::radians(50.0f), glm::vec3(0.5f, 1.0f, 0.0f));// 视图矩阵:摄像机位置 glm::mat4 view = glm::mat4(1.0f); view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f));// 投影矩阵:透视投影 glm::mat4 projection = glm::perspective( glm::radians(45.0f), // 视野800.0f / 600.0f, // 宽高比0.1f, // 近平面100.0f// 远平面 );// 传递矩阵给着色器 GLint modelLoc = glGetUniformLocation(shaderProgram, "model"); GLint viewLoc = glGetUniformLocation(shaderProgram, "view"); GLint projLoc = glGetUniformLocation(shaderProgram, "projection");glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));glUniformMatrix4fv(viewLoc, 1, GL_FALSE, glm::value_ptr(view));glUniformMatrix4fv(projLoc, 1, GL_FALSE, glm::value_ptr(projection));// 绘制立方体glBindVertexArray(VAO);glDrawArrays(GL_TRIANGLES, 0, 36);// 交换缓冲并检查事件glfwSwapBuffers(window);glfwPollEvents(); }// 清理资源glDeleteVertexArrays(1, &VAO);glDeleteBuffers(1, &VBO);glDeleteProgram(shaderProgram);glfwTerminate();return0;}四、向量运算是AI模型训练和推理的基础?它对并行计算有什么要求
向量运算是AI模型训练和推理的核心,原因如下:
1. 神经网络的基本操作:神经网络的前向传播和反向传播本质上是大量的矩阵和向量运算。每个神经元的计算可以表示为向量点积,整个网络的计算可以视为矩阵运算。 2. 数据表示:AI模型中的输入数据、权重和激活值通常表示为向量或矩阵。例如,图像可以表示为像素向量,文本可以表示为词嵌入向量。 3. 计算效率:向量运算可以通过并行计算显著加速。正如知识库[1]所述,"GPU特别擅长同时处理许多小任务,非常适合这种精细的操作"。
4.1 对并行计算的要求:
1. 高度并行性:每个向量元素的计算可以独立进行,需要大量计算单元同时处理。 2. 数据局部性:向量运算通常访问连续内存,有利于GPU的高速缓存。 3. 高吞吐量:需要处理大量数据,要求计算单元数量多、计算速度快。 4. 低延迟:在推理阶段,需要快速响应,要求计算延迟低。
这些要求与GPU的架构完美匹配,使得GPU成为AI计算的理想平台。
五、实战 Demo:CUDA实现一次向量计算
CUDA是NVIDIA开发的并行计算平台,它允许开发者利用GPU的并行计算能力来加速计算密集型任务。
以下是一个简单的向量点积公式CUDA实现:dot=∑i=0N−1A[i]∗B[i],是 AI 模型中最核心的运算之一 —— 注意力分数、卷积运算、全连接层,本质都是向量点积的组合。
#include<iostream>#include<vector>#include<cuda_runtime.h>// CUDA核函数:并行计算向量元素的乘积,存入临时数组__global__ voidvecDotKernel(constfloat* A, constfloat* B, float* temp, int N){int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) { temp[idx] = A[idx] * B[idx]; // 并行计算逐元素乘积 }}// CPU主机端函数:调度GPU计算+最终求和floatvecDot(const std::vector<float>& h_A, const std::vector<float>& h_B, int N){int dataSize = N * sizeof(float);float *d_A, *d_B, *d_temp;std::vector<float> h_temp(N, 0.0f);float dotResult = 0.0f;// 分配显存+拷贝数据cudaMalloc((void**)&d_A, dataSize);cudaMalloc((void**)&d_B, dataSize);cudaMalloc((void**)&d_temp, dataSize);cudaMemcpy(d_A, h_A.data(), dataSize, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B.data(), dataSize, cudaMemcpyHostToDevice);// 启动核函数int blockSize = 32;int gridSize = (N + blockSize - 1) / blockSize; vecDotKernel<<<gridSize, blockSize>>>(d_A, d_B, d_temp, N);// 拷贝乘积结果回CPU+求和cudaMemcpy(h_temp.data(), d_temp, dataSize, cudaMemcpyDeviceToHost);for (int i = 0; i < N; ++i) { dotResult += h_temp[i]; }// 释放显存cudaFree(d_A);cudaFree(d_B);cudaFree(d_temp);return dotResult;}// 主函数:测试向量点积intmain(){constint vecDim = 1024;std::vector<float> h_A(vecDim, 1.0f);std::vector<float> h_B(vecDim, 2.0f);float dot = vecDot(h_A, h_B, vecDim); std::cout << "向量点积的最终结果:" << dot << std::endl; // 预期:1024*2=2048return0;}这个CUDA程序展示了如何利用GPU的并行计算能力高效地执行向量运算:
1. 内存分配:在CPU和GPU上分配内存 2. 数据传输:将数据从CPU内存复制到GPU内存 3. 核函数执行:GPU执行并行计算 4. 结果传输:将结果从GPU内存复制回CPU内存
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- UG编程-1月6号时实录制年底最后一期新班开班现场,与第1次课安排学习计划
- 农业银行签约完用款错误代码IPAY、MPAY、C102解决办法!
- 艾德克斯IT-N6700系列高压可编程直流电源上市:六重保护+波形可视化,测试稳了!
- 当计算机教授不让孙女学编程:艺术,是写给生命的“高级代码”
- Day6《富有的习惯》健康是财富的底层代码|这场读书共创会,把富有的习惯刻进日常
- 我的 TRAE 编程体验-简介篇
- 中国象棋人机对战游戏代码(Windows电脑端)
- AI编程最佳实践的集大成者 OpenCode
- 既然代码只在本地能跑,那就把电脑一起上线吧!
- 少儿编程的前世今生:源于一只小乌龟的学习理论
