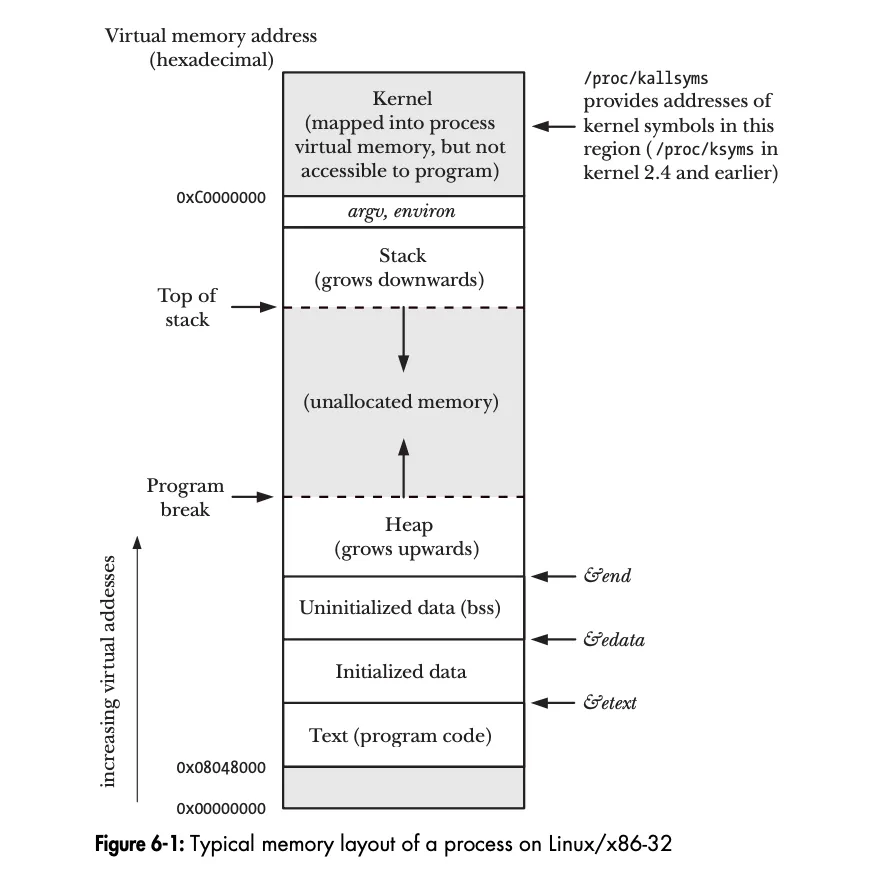
在Unix系统中, 内存的分配分为两类: 堆上和栈上, 各有其优缺点. 在栈上分配内存的优点是会随着函数调用的返回, 内存自动回收没有内存泄漏的风险, 但是其不适合较大的数据结构和动态数据结构, 以及数据在函数返回之后就不可再使用. 在堆上分配内存恰好可以弥补栈内存的缺点, 其缺点就是需要牢记内存的释放, 否则就容易引起内存泄漏, 这也就是为什么很多函数在调用的最后, 需要再调用一次清理函数的原因.
堆上分配内存
一个进程可以通过增加堆的大小来分配内存。堆是一个可变大小的连续虚拟内存区域,它紧接在进程的未初始化数据段之后开始,并会随着内存的分配和释放而增减大小。在C语言中, 通常是使用malloc系列函数来分配或者重分配内存的, 使用free函数来释放函数. 在GO语言中, 开发者不能指定在堆还是在栈上申请内存, 而是由编译器通过逃逸分析来确定的, 这个在上篇文章中已经解释过了.
内存管理的实现
在最开始的时候, 内存是一整块的空白区域, 那么频繁的申请和释放之后, malloc和free怎么维护和管理内存的呢? 这个就是最有趣的地方了.
malloc() 的实现方式很简单。它首先会扫描由 free() 之前释放的内存块所构成的列表,以找到一个大小不低于其需求的内存块。(这种扫描策略可能会因实现方式的不同而有所差异;例如,可以采用首次适应策略或最佳适应策略。)如果该块恰好是所需大小,则将其返回给调用者。如果它更大,则对其进行分割,以便返回一个大小合适的内存块给调用者,并在空闲列表中留下一个较小的空闲块。
如果空闲列表中没有足够大的块,则 malloc() 会调用 sbrk() 来分配更多内存。为了减少对 sbrk() 函数的调用次数,而不是精确地分配所需的字节数,malloc() 会以更大的单位(虚拟内存页面大小的若干倍)来增加程序的基址,将多余的内存放入可用内存列表中。
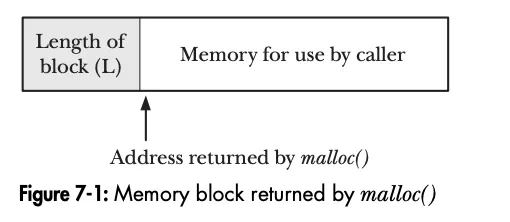
当 free() 函数将一块内存放入可用内存列表中时,它如何知道这块内存的大小呢?这是通过一种技巧来实现的。当 malloc() 分配这块内存时,它会额外分配一些字节来存放一个包含该块大小的整数。这个整数位于内存块的开头;返回给调用者的地址实际上指向了这个长度值之后的位置。如下图, 调用malloc()的时候, 会返回内存的位置, 但是实际上它的前面还有一段空间是保存了这段内存的长度.如下图:
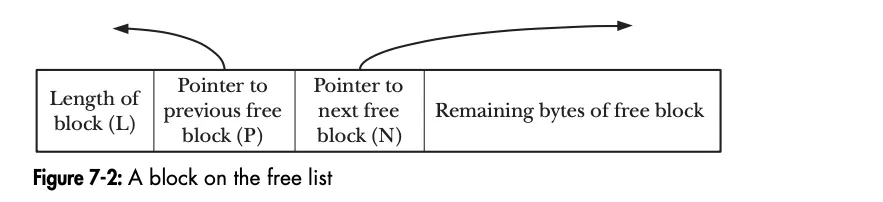
当一个块被放置到(双向链表形式的)空闲列表中时,free() 函数会利用该块自身的字节来将该块添加到列表中。空闲的区域实现为一个双向链表, 其实现包括了区间的长度, 前一个空闲区域的地址, 后一个空闲区域的地址, 和空闲的长度, 如下图: .
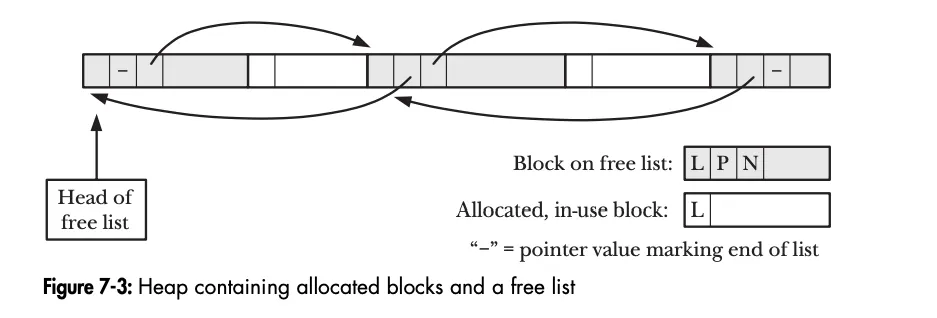
随着内存块随着时间的推移被释放和重新分配,空闲列表中的内存块将会与已分配并正在使用的内存块相互交织在一起。如下图所示, 白色的为已分配的内存空间, 灰色的为空闲区域, 放malloc()调用的时候, 就会去空闲列表中查询空闲的区域来分配内存了.
当调用free()时, 会检查相邻的前后两块内存是否为空闲的, 如果是空闲的话, 就会进行区间的合并, 这样就把两块小内存合并成一块大的空闲区域了.
内存泄漏
如果我们正在编写一个长期运行的程序(例如一个 shell 程序或网络守护进程),并且该程序会反复为各种目的分配内存,那么我们就应该确保在使用完内存后将其释放。如果不这样做,就会导致内存持续增长,直至达到可用虚拟内存的极限,届时再尝试分配内存就会失败。这种情况被称为内存泄漏。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
