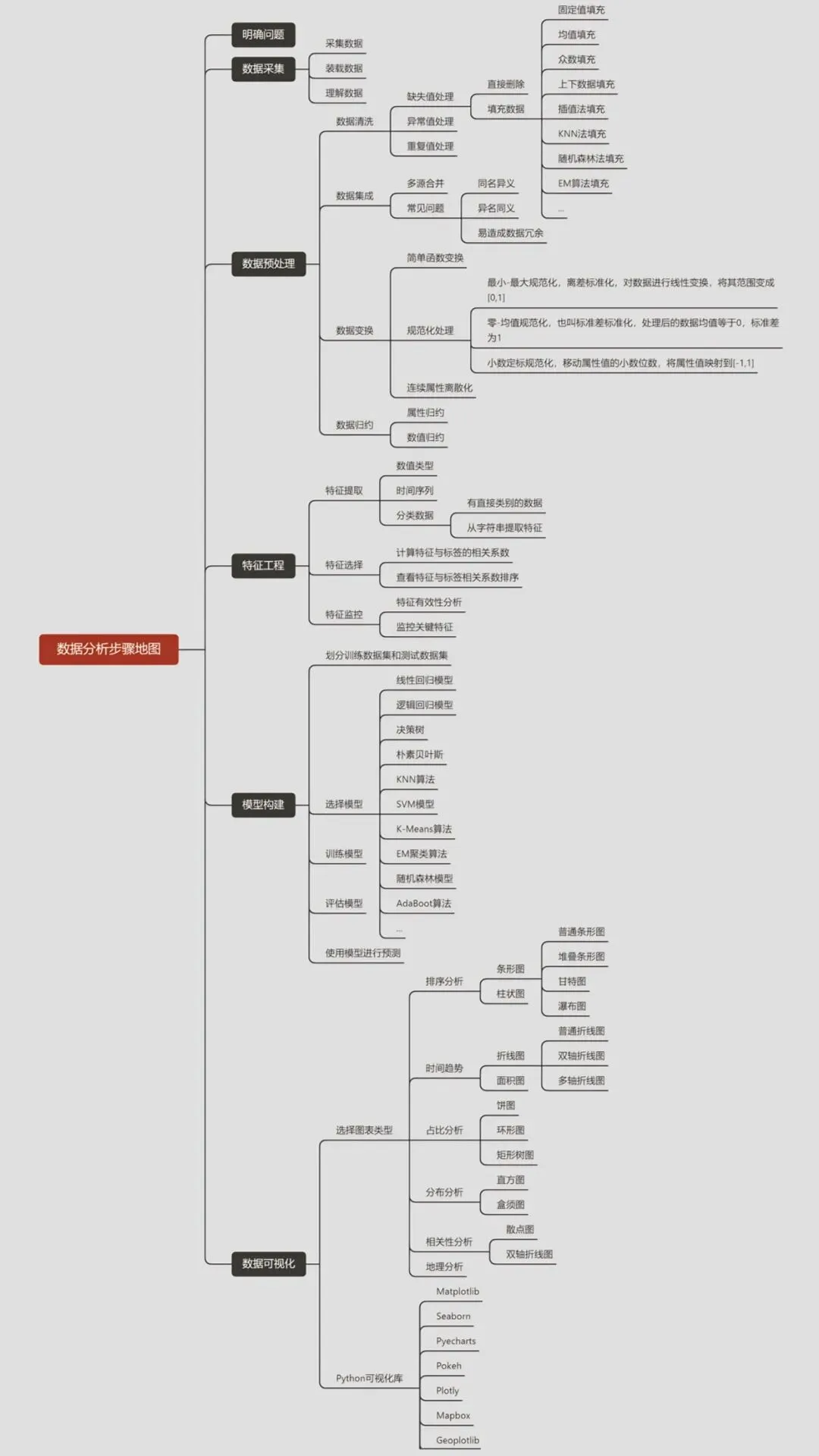
想靠 Python 做数据分析?其实整个过程是一套清晰的 “流水线”—— 从数据进来,到最后出结论,每个环节都有明确的动作。这张步骤地图,正好能帮我们理清楚全流程:
先明确要解决的问题,再围绕问题采集、装载数据,最后把数据 “读明白”—— 这是分析的基础,没数据后面都是空谈。
拿到的数据往往是 “脏” 的:先 “清洗”(补缺失值、清异常值、删重复值),再把多源数据 “集成”(避开同名异义、数据冗余的坑),接着做 “变换”(比如把数据规范到 0-1 区间)、“归约”(压缩数据规模)—— 这步是让数据从 “能用” 变 “好用”。
特征是模型的核心:从数值、时间序列里 “提取” 特征,通过相关性分析 “筛选” 有用特征,再 “监控” 特征有效性 —— 好特征才能撑起好模型。
把数据分成训练 / 测试集,从线性回归、决策树、K-Means 等模型里选合适的,训练后评估效果,没问题就可以用模型做预测。
选对应的图表:排序用条形图,趋势用折线图,占比用饼图…… 再用 Python 的 Matplotlib、Seaborn 等库画出来,让数据结论 “一眼看懂”。
这套流程把数据分析拆成了清晰的环节,Python 工具链又能覆盖每一步 —— 从数据到价值,按步骤来就不慌。
———————————————————————————————————