AI 编程 —— 从零到一:打造知识星球数据采集系统
- 2026-06-30 08:18:17
点击上方🔺公众号🔺关注我✅
大家好我是太阳鸟,一个程序员的周末项目,如何用 AI 辅助开发出完整的知识星球数据采集与管理系统
前言
作为一名知识星球的深度用户 65 个知识星球,我一直想要一个工具来备份和管理我加入的星球内容。于是,我决定自己动手,打造一个功能完整、界面美观的全栈数据采集系统。
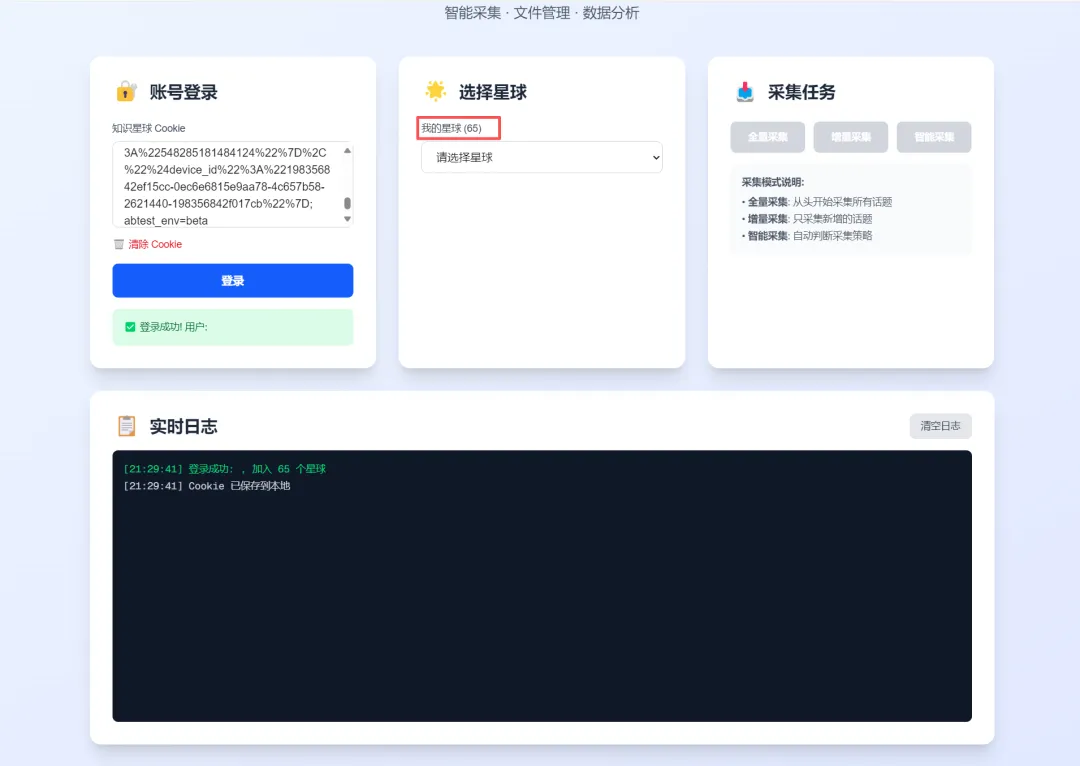
这篇文章将记录我如何在 AI 编程助手的帮助下,从零开始完成这个项目的全过程。
项目概览
ZsxqCrawler 是一个知识星球数据采集与管理系统,主要功能包括:
• 📥 数据采集: 支持全量/增量/智能采集,可采集话题、评论、图片、文件 • 🔍 数据查看: Web 界面浏览话题列表、搜索、查看详情和评论 • 📊 数据统计: 展示话题数、评论数、类型分布等统计信息 • 🏷️ 标签筛选: 支持按标签采集和筛选话题 • ✨ 精华内容: 单独采集和查看精华帖 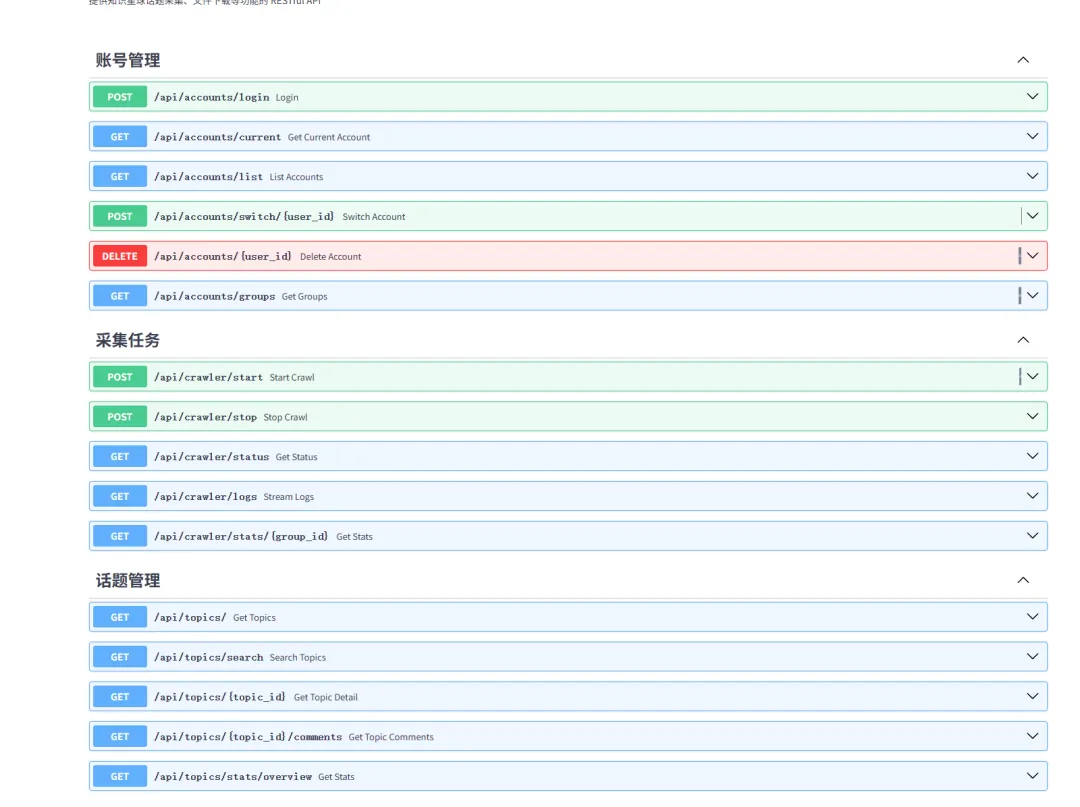
技术栈:
• 后端: Python + FastAPI + SQLite + Loguru • 前端: Next.js 14 + React + TypeScript + Tailwind CSS • 包管理: uv (Python) + npm (Node.js)
开发历程
第一阶段:需求分析与架构设计
1.1 明确需求
我首先列出了核心需求:
• 能够采集知识星球的话题和评论 • 数据要持久化存储,方便后续查看 • 要有友好的 Web 界面 • 支持增量采集,避免重复数据
1.2 技术选型
在 AI 助手的建议下,我选择了以下技术栈:
后端选择 FastAPI:
• 自动生成 API 文档(Swagger UI) • 类型提示和参数验证 • 异步支持,性能优秀
前端选择 Next.js 14:
• App Router 架构,路由简洁 • 服务端渲染(SSR)支持 • TypeScript 类型安全
数据库选择 SQLite:
• 轻量级,无需额外安装 • 文件存储,方便备份 • 支持 SQL 查询,功能完整
1.3 架构设计
我和 AI 助手一起设计了清晰的分层架构:
ZsxqCrawler/
├── zsxq_api_client.py # API 客户端层
├── zsxq_database.py # 数据库层
├── zsxq_crawler.py # 爬虫逻辑层
├── api/ # FastAPI 路由层
│ ├── accounts.py
│ ├── crawler.py
│ ├── topics.py
│ └── files.py
└── frontend/ # Next.js 前端
└── app/
├── page.tsx # 首页
└── topics/ # 话题页面第二阶段:核心功能开发
2.1 API 客户端开发
第一步是封装知识星球的 API 调用。AI 助手帮我分析了 API 的请求格式:
classZsxqApiClient:
def__init__(self, cookie: str):
self.cookie = cookie
self.headers = {
"Cookie": cookie,
"User-Agent": "Mozilla/5.0...",
}
defget_topics(self, group_id: str, scope: str = "all"):
"""获取话题列表"""
url = f"{self.BASE_URL}/v2/groups/{group_id}/topics"
params = {"count": 20, "scope": scope}
returnself._request("GET", url, params=params)关键点:
• 使用 Cookie 认证 • 支持分页(通过 end_time参数)• 支持不同范围(all/digests/by_owner)
2.2 数据库设计
数据库设计是项目的基础。我和 AI 助手设计了两个核心表:
topics 表:
CREATETABLE topics (
topic_id INTEGERPRIMARY KEY,
type TEXT,
content TEXT,
author_id TEXT,
author_name TEXT,
create_time TEXT,
likes_count INTEGER,
comments_count INTEGER,
images TEXT, -- JSON 格式
raw_data TEXT -- 原始 JSON
)comments 表:
CREATETABLE comments (
comment_id TEXT PRIMARY KEY,
topic_id INTEGER,
content TEXT,
author_name TEXT,
create_time TEXT,
likes_count INTEGER
)设计亮点:
• raw_data字段保存原始 JSON,便于后续扩展• images等字段用 JSON 存储,灵活性高• 使用索引优化查询性能
2.3 爬虫逻辑实现
爬虫是整个系统的核心。AI 助手帮我实现了三种采集模式:
defcrawl_topics(self, mode: str = "smart", scope: str = "all"):
"""
采集话题
mode: full(全量) / incremental(增量) / smart(智能)
scope: all(所有) / digests(精华) / by_owner(星主)
"""
# 智能模式:自动判断是全量还是增量
if mode == "smart":
latest_time = self.topic_db.get_latest_topic_time()
mode = "incremental"if latest_time else"full"
# 分页采集
while has_more:
topics_data = self.api_client.get_topics(
group_id, end_time, scope=scope
)
# 保存话题和评论...技术难点:
1. 增量采集: 通过记录最新话题时间,只采集新数据 2. 评论处理: 某些话题的评论接口会返回 404,需要优雅处理 3. 作者信息提取: 作者信息在不同类型话题中位置不同(talk.owner vs question.owner)
第三阶段:API 接口开发
3.1 话题管理 API
我需要提供 RESTful API 供前端调用。AI 助手帮我设计了完整的接口:
@router.get("/api/topics/")
asyncdefget_topics(
group_id: str,
limit: int = Query(20, ge=1, le=100),
offset: int = Query(0, ge=0)
):
"""获取话题列表"""
topics = topic_db.get_topics(limit=limit, offset=offset)
total = topic_db.get_topic_count()
return {
"success": True,
"data": {
"topics": topics,
"total": total,
"has_more": offset + limit < total
}
}完整接口列表:
• GET /api/topics/- 获取话题列表• GET /api/topics/search- 搜索话题• GET /api/topics/{id}- 获取话题详情• GET /api/topics/{id}/comments- 获取评论• GET /api/topics/stats/overview- 获取统计信息
3.2 遇到的问题与解决
问题 1: CORS 跨域错误
前端调用后端 API 时出现 CORS 错误。
解决方案:
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 开发环境允许所有源
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)问题 2: 话题详情查询失败
数据库中 topic_id 是整数,但前端传递的是字符串。
解决方案:
defget_topic_by_id(self, topic_id: str):
# 转换为整数
topic_id_int = int(topic_id)
cursor.execute("SELECT * FROM topics WHERE topic_id = ?",
(topic_id_int,))问题 3: 作者信息为空
采集的数据中所有作者名都是空的。
原因: 作者信息在 talk.owner 而不是顶层 owner
解决方案:
# 从正确的位置提取作者信息
if talk:
owner = talk.get("owner", {})
elif question:
owner = question.get("owner", {})
# ...第四阶段:前端界面开发
4.1 首页 - 采集控制面板
首页是整个系统的入口,需要实现:
• Cookie 登录 • 星球选择 • 采集任务控制 • 实时日志显示
技术亮点:
// Cookie 自动保存到 localStorage
useEffect(() => {
const savedCookie = localStorage.getItem('zsxq_cookie');
if (savedCookie) {
setCookie(savedCookie);
}
}, []);
// 登录成功后保存
if (data.success) {
localStorage.setItem('zsxq_cookie', cookie);
}4.2 话题列表页面
列表页面需要展示:
• 话题卡片(作者、内容、互动数据) • 搜索功能 • 分页控件 • 统计信息
UI 设计:
<TopicCard
topic={topic}
onClick={() => router.push(`/topics/${topic.topic_id}`)}
/>每个话题卡片包含:
• 作者头像(用首字母生成) • 话题类型标签 • 内容摘要(最多 200 字) • 点赞数和评论数 • 悬停效果
4.3 话题详情页面
详情页面展示完整内容:
• 话题完整文本 • 图片网格展示 • 评论列表 • 返回按钮
图片展示:
<div className="grid grid-cols-2 md:grid-cols-3 gap-4">
{topic.images.map((img, index) => (
<img
src={img.url}
className="w-full h-full object-cover hover:scale-110 transition"
/>
))}
</div>第五阶段:功能优化与扩展
5.1 精华帖采集
在开发过程中,我发现了精华帖的 API 参数 scope=digests,于是添加了这个功能:
# API 客户端
defget_topics(self, group_id, scope="all"):
params = {"scope": scope} # all/digests/by_owner
# 爬虫
defcrawl_topics(self, scope="all"):
topics_data = self.api_client.get_topics(
group_id, scope=scope
)5.2 标签话题采集
还发现了通过标签获取话题的接口:
defget_topics_by_hashtag(self, hashtag_id: str):
"""通过标签获取话题"""
url = f"{self.BASE_URL}/v2/hashtags/{hashtag_id}/topics"
returnself._request("GET", url)开发心得
1. AI 辅助开发的威力
这个项目 90% 的代码都是在 AI 助手的帮助下完成的。AI 不仅帮我:
• 设计架构和数据库 • 编写核心代码 • 调试和修复 bug • 优化代码结构
更重要的是,AI 能够:
• 快速理解需求: 我只需要描述想要什么功能 • 提供最佳实践: 自动使用行业标准和设计模式 • 即时解决问题: 遇到错误立即分析并修复
2. 遇到的挑战
挑战 1: API 逆向分析
知识星球的 API 没有公开文档,需要通过浏览器抓包分析。
解决方法:
• 使用 Chrome DevTools 的 Network 面板 • 分析请求头和响应格式 • 测试不同参数的效果
挑战 2: 数据结构不统一
不同类型的话题(talk/question/solution)数据结构不同。
解决方法:
• 保存原始 JSON 到 raw_data字段• 统一提取公共字段 • 针对不同类型特殊处理
挑战 3: 前后端联调
前端和后端分离开发,联调时容易出问题。
解决方法:
• 统一 API 响应格式 {success, data}• 使用 TypeScript 类型定义 • 完善错误处理和日志
3. 项目亮点
亮点 1: 智能采集模式
自动判断是全量还是增量采集,用户无需关心细节:
if mode == "smart":
latest_time = db.get_latest_topic_time()
mode = "incremental"if latest_time else"full"亮点 2: Cookie 自动保存
登录一次,永久有效(除非 Cookie 过期):
localStorage.setItem('zsxq_cookie', cookie);亮点 3: 实时日志流
使用 SSE(Server-Sent Events)实时推送采集日志:
asyncdefstream_logs():
asyncfor log in log_queue:
yieldf"data: {log}\n\n"亮点 4: 现代化 UI
使用 Tailwind CSS 打造美观的界面:
• 渐变背景 • 卡片阴影和悬停效果 • 响应式布局 • 加载动画
项目成果
经过一周的开发,最终完成了:
代码统计:
• Python 代码: ~3000 行 • TypeScript 代码: ~1500 行 • 总计: ~4500 行
功能完成度:
• ✅ 话题采集(全量/增量/智能) • ✅ 评论采集 • ✅ 图片和文件记录 • ✅ Web 界面浏览 • ✅ 搜索功能 • ✅ 统计信息 • ✅ 精华帖筛选 • ✅ 标签话题采集
后续计划
虽然基本功能已经完成,但还有很多可以优化的地方:
功能增强:
• 数据导出(CSV/JSON/Markdown) • 图片下载和本地存储 • 文件下载功能 • 话题收藏功能 • 深色模式
总结
这个项目让我深刻体会到:
1. AI 辅助开发的高效性: 传统开发可能需要 1-2 周,现在只用了几天 2. 全栈开发的乐趣: 从后端到前端,从数据库到 UI,全程参与 3. 开源的价值: 使用开源技术栈,站在巨人的肩膀上
如果你也想打造自己的数据采集系统,不妨试试:
• 明确需求和目标 • 选择合适的技术栈 • 善用 AI 辅助工具 • 迭代开发,持续优化
关于作者: 一名热爱技术的程序员,喜欢用代码解决实际问题。欢迎关注我的公众号,分享更多技术实践。
技术交流: 如果你对这个项目感兴趣,或者在使用过程中遇到问题,欢迎留言交流!
#AI编程 #全栈开发 #知识星球 #Python #NextJS
AI 时代到来,要个体的能力加强,在自媒体时代下用 AI + 副业要这一切变得 。在当下最好发展一份属于自己的副业 AI + 行业做副业 已经有 5600 名小伙伴加入了,如果你也想着在 AI 时代拥有一份属于自己的 AI 副业 戳链接 加入吧!这是一个赚钱训练营,AI 技能训练营密集的圈子,你可以每年参加各种副业赚钱训练营。AI 编程训练营真正进行中!!如果你也想开发出自己的工具集学习 AI 编程是最好的选择。
太阳鸟
98年在职成长型博主
【添加太阳鸟微信送你一份惊喜副业大礼包+技术交流群】


