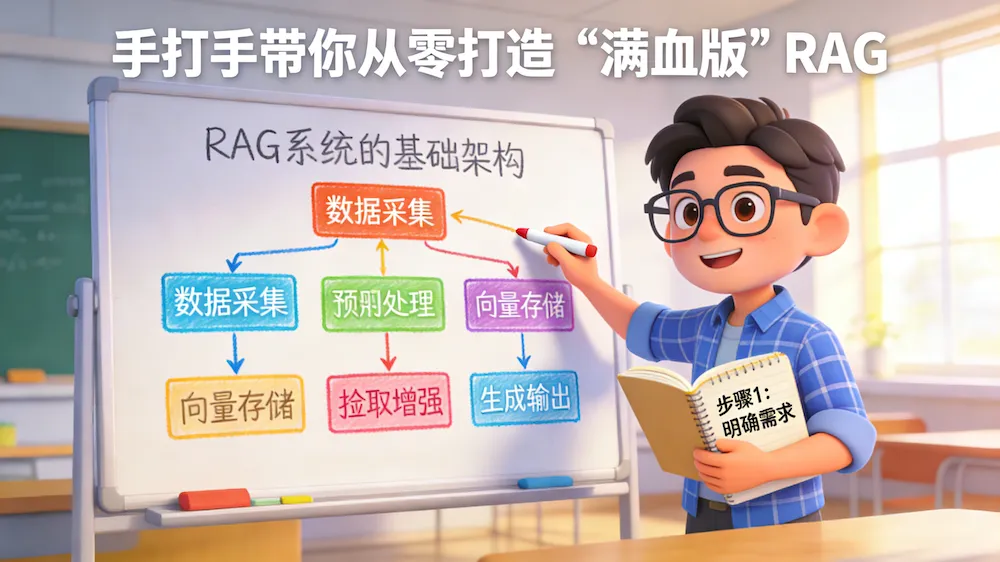
作者:飞哥(一位喜欢讲故事的全栈开发者,擅长把复杂的代码翻译成“人话”)关键词:RAG, ChromaDB, LangChain, 混合检索, Rerank, 自动化评估
大家好,我是飞哥!👋
上一期我们用 Python 列表手搓了一个“玩具级”的 RAG(检索增强生成)Demo。虽然跑通了流程,但在真实复杂的业务场景下,它有三个致命伤:
- 1. 记不住:长文档(比如 100 页的 PDF)怎么塞进去?(切片问题)
- 2. 找不准:搜“苹果”,它分不清是手机还是水果。(检索精度问题)
- 3. 不知道好坏:老板问“现在的准确率是多少”,你只能凭感觉回答“还行”。(评估问题)
今天,飞哥就带大家补齐这些短板,用 Python 打造一个工业级、满血版的 RAG 系统!🚀
飞哥叮嘱:一定要下载完整代码自己运行一下!完整代码获取方式在文章末尾。
第一步:聪明的“切刀” (Text Splitter) 🔪
1. 为什么要切片?(Anchor & Analogy)
大家平时吃吐司面包,是一口吞下一整条吗?肯定不是,我们会把它切成一片一片的吃。
Embedding 模型也一样,它的“胃口”(Context Window)是有限的。如果你把一整本 100 页的书直接扔给它,它不仅吃不下(报错),就算吃下了也消化不良(丢失细节)。
所以,切片的本质,就是把“大块知识”嚼碎成“好消化的小块”,方便模型理解和检索。 🍞
2. 怎么切才科学?
如果你简单粗暴地“每 500 字切一刀”,可能会把一句话切成两半,导致上下文丢失。
最佳实践是使用 递归字符切分 (Recursive Character Text Splitter)。它的逻辑像剥洋葱:
3. 代码实战 (LangChain)
from langchain.text_splitter import RecursiveCharacterTextSplittertext = "这里是一篇很长的文档......"# 初始化切分器splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每块约 500 字符 chunk_overlap=50# 重叠 50 字符,防止上下文丢失(关键!))chunks = splitter.split_text(text)print(f"切分完成,共 {len(chunks)} 块")
一句话记住它:切片要像切藕一样“藕断丝连”(保留 Overlap),才能保证语意不断!
📂 完整代码示例:对应示例代码:week_07_04_hybrid_search.py(包含数据加载 week_07_04_data.txt[1] 与切片逻辑)
第二步:给数据安个家 (Vector DB - ChromaDB) 🏠
1. 为什么要用向量数据库?
之前的 Demo 我们用 Python list 存数据,一关机数据就没了(内存易失)。这就好比你把钱都塞在枕头底下,不仅不安全,还很难找。
我们需要一个专业的向量数据库,它不仅能持久化存储(存硬盘),还能用HNSW 算法在亿级数据中毫秒级找到你想要的内容。
2. 为什么选 ChromaDB?
市面上有 Milvus、Pinecone、Elasticsearch 等大佬。但对于 Python 开发者和中小型应用,ChromaDB 是飞哥的首选:
- • 极简:
pip install chromadb 就能用,不用装 Docker,不用配服务器。 - • 本地化:数据直接存成并在本地文件,像 SQLite 一样方便。
3. 代码实战:使用 BGE 模型入库
我们在生产环境中,推荐使用 BGE (BAAI/bge-small-zh-v1.5) 这种专业的中文 Embedding 模型,而不是简单的规则匹配。
import chromadbfrom chromadb.utils import embedding_functions# 1. 初始化 Chroma 客户端(持久化到本地目录)client = chromadb.PersistentClient(path="./my_knowledge_base")# 2. 加载 BGE 中文模型 (会自动下载,很方便)ef = embedding_functions.SentenceTransformerEmbeddingFunction( model_name="BAAI/bge-small-zh-v1.5")# 3. 创建或获取集合 (Collection)collection = client.get_or_create_collection( name="company_policy", embedding_function=ef)# 4. 存入数据 (自动计算向量)collection.upsert( documents=["出差每日补贴 300 元", "打车报销需要发票"], metadatas=[{"category": "finance"}, {"category": "transport"}], ids=["doc1", "doc2"])print("数据入库成功!")
📂 完整代码示例:week_07_03_chroma_crud.py(包含完整的增删改查操作)
第三步:不再脸盲 (混合检索 & 重排序) 🎯
1. 纯向量检索的痛点
向量检索擅长语义模糊匹配(搜“交通工具”能找到“汽车”)。但有时候它会“想太多”。比如用户搜“双指互点”(一个特定的手势操作),向量检索可能会给你返回“每天吃一个苹果”(因为语义不明时它可能乱联想)。
这时候,我们需要关键词检索 (BM25) 来救场。BM25 擅长精准字面匹配。
混合检索 (Hybrid Search) = 向量检索 (70%) + 关键词检索 (30%)。
- • 类比:警察抓人,先用画像(向量)找个大概,再用指纹(关键词)确认身份。🕵️♂️
2. 代码实战:LangChain 混合检索
注意:中文环境使用 BM25 必须配合分词工具(如 jieba),否则它会把一句话当成一个超长单词。
from langchain.retrievers import EnsembleRetrieverfrom langchain_community.retrievers import BM25Retrieverimport jieba# 0. 定义中文分词函数defchinese_tokenizer(text):return jieba.lcut(text)# 1. 向量检索器 (擅长语义)# vectorstore 是你之前初始化好的 Chroma 向量库vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})# 2. 关键词检索器 (擅长字面)# 关键:传入 preprocess_func 处理中文bm25_retriever = BM25Retriever.from_documents( documents, preprocess_func=chinese_tokenizer)# 3. 强强联合 (Ensemble)ensemble_retriever = EnsembleRetriever( retrievers=[vector_retriever, bm25_retriever], weights=[0.7, 0.3] # 权重可调)# 4. 搜索docs = ensemble_retriever.invoke("双指互点")
📂 完整代码示例:week_07_04_hybrid_search.py(包含 Jieba 分词与混合检索实现)
3. 终极优化:重排序 (Rerank) ⚖️
混合检索找回来的 Top 50 可能是“鱼龙混杂”的。为了给大模型最精准的上下文,我们需要引入 Rerank 模型 进行“精排”。
- • Retrieval (初筛):海选,快但粗糙。选出 Top 50。
- • Rerank (精排):决赛,慢但精准。用 Cross-Encoder 模型给这 50 条逐一打分,选出 Top 3。
from sentence_transformers import CrossEncoder# 加载 Rerank 模型reranker = CrossEncoder('BAAI/bge-reranker-base')# 假设 docs 是初筛回来的文档列表query = "苹果手机"doc_texts = [d.page_content for d in docs]# 打分scores = reranker.predict([(query, doc) for doc in doc_texts])# 根据分数重新排序ranked_results = sorted(zip(docs, scores), key=lambda x: x[1], reverse=True)# 取前 3 名final_top_3 = ranked_results[:3]
📂 完整代码示例:week_07_05_rerank.py (包含 Cross-Encoder 重排序逻辑)
第四步:严苛的考官 (RAG 自动化评估) 📝
1. 为什么要评估?
不要迷信自己的代码!你需要量化指标。业界常用的指标有:
- • Hit Rate (命中率):正确答案的关键词在检索结果里吗?
- • Faithfulness (忠实度):AI 是不是在瞎编(幻觉)?
2. 用大模型当裁判 (LLM Judge)
我们可以写一段 Prompt,让更强的大模型(如 DeepSeek, GPT-4)来评估我们的 RAG 系统。
裁判 Prompt 示例:
你是一位严格的 RAG 系统评估员。请根据以下【参考资料】和【AI 回答】,判断回答是否忠实于资料。如果回答中包含了资料里没有的信息,请判为“幻觉”。请打分 (0-1) 并给出理由。
在实战代码中,我们可以遍历测试集,自动计算出 RAG 系统的平均得分。
📂 完整代码示例:week_07_06_evaluation.py(包含 RAG 评估与 LLM Judge 实现,需配置 .env))
总结 📚
今天我们把 RAG 系统从“玩具”升级到了“工业级”:
- 1. 切片 (Splitter):用递归切分保留上下文。
- 2. 存储 (ChromaDB):用本地向量库实现持久化。
- 3. 检索 (Hybrid):向量 + 关键词 + Rerank,确保又快又准。
💡 飞哥作业:建议大家动手把代码跑一遍!尝试把 embedding_function 换成 OpenAI 的,或者把数据换成你自己的私有文档,看看效果有什么不同?
创作不易,记得关注飞哥,点赞、收藏哦~,下期带你把这个 RAG 引擎封装成真正的 FastAPI 接口!👋
👉 关注”爱码说“,回复"RAG"获取完整示例代码