💥 2026年1月,一项震撼整个开发者社区的数据公布:84%的开发者已经在日常编程中使用AI工具,开发效率平均提升了30-50%。
这不是科幻,而是正在发生的现实。
Google Chrome团队工程师Addy Osmani在2026年1月4日发布了《AI Coding Workflow 2026》,系统总结了过去两年AI辅助编程的最佳实践。这篇文章基于大量实战经验,揭示了如何让AI真正成为你的编程助手,而不仅仅是代码生成器。
今天,我们深度解析这份权威指南的核心思想。
💡 掌握AI辅助编程,让你的开发效率提升50%!
1💡 规格先行(Spec First):AI编程的核心理念
你有没有过这样的经历:让AI生成一大段代码,结果发现完全不符合需求,不得不全部重写?
Addy Osmani指出,AI编程的第一条原则是:规格先行。
什么是规格先行?
规格先行是指在写代码之前,先用自然语言详细描述需求、约束条件和实现思路。这不是新概念,但在AI时代变得更加重要。
为什么? 因为AI无法猜测你的意图。如果你不告诉它"要做什么"和"不要做什么",它会根据概率生成代码,结果往往是不可预测的。
如何编写一个有效的spec.md?
Addy推荐的spec.md模板包含以下部分:
项目概述
技术约束
实现思路
验收标准
一个真实案例
Addy分享了一个案例:他的团队要实现一个文件上传功能。
❌ 错误的做法: "帮我写一个文件上传的API"
AI生成的代码可能包含:
✅ 正确的做法: 在spec.md中详细说明: "文件大小限制10MB,只允许pdf/docx/png类型,需要病毒扫描,需要生成缩略图,需要存储在GCS"
AI生成的代码直接满足所有需求,一次通过率从30%提升到90%。
2💡 本章小结
规格先行不仅仅是写文档,而是用自然语言编程。它让AI真正理解你的意图,而不是盲目生成代码。记住:清晰的规格是高质量代码的前提。
3🚀 任务分块迭代(Chunk & Iterate):小步快跑的艺术
想象一下,你让AI一次性生成一个完整的电商系统。结果会是什么?
代码可能会:
Addy的经验是:永远不要让AI一次生成超过50行的代码。
为什么要分块?
认知负荷理论告诉我们:一次性处理太多信息会导致效率下降。AI虽然有强大的模式识别能力,但它也受限于上下文窗口和生成质量。
更重要的是,小步迭代让你能及时发现问题。如果第一步就错了,你可以立即纠正,而不是在写完1000行代码后发现需要推倒重来。
任务分块的3个原则
原则1:按功能边界分块
不要按代码行数分块,要按功能分块。
❌ 错误分块:
✅ 正确分块:
原则2:每个分块都可以独立测试
分块后的代码应该可以单独运行和测试。
# 第1部分:数据模型classUser:def__init__(self, id, name):self.id = idself.name = name# 第2部分:存储层classUserRepository:defsave(self, user):# 保存用户逻辑pass# 第3部分:服务层classUserService:def__init__(self, repo):self.repo = repodefcreate_user(self, name): user = User(None, name)returnself.repo.save(user)
每个部分都可以独立测试,互不依赖。
原则3:逐步增加复杂度
从最简单的功能开始,逐步增加复杂度。
一个真实案例
Addy的团队开发一个实时协作编辑器。他们没有让AI一次性生成整个系统,而是这样分块:
Week 1:基础的文本同步
Week 2:添加冲突解决算法
- OT算法(Operational Transformation)
Week 3:添加离线支持
Week 4:性能优化
每完成一个分块,都经过完整测试。最终上线时,bug率比直接生成完整系统低70%。
4💡 本章小结
任务分块的核心思想是降低风险。通过小步迭代,你可以:
记住:慢即是快,迭代胜过一次完成。
5📦 上下文打包技巧(Context Packing):AI理解项目的关键
你有没有遇到过这种情况:AI生成的代码完全不匹配你的项目风格?
原因很简单:AI不了解你的项目上下文。
什么是上下文打包?
上下文打包是指给AI提供最相关、最精简的项目信息,让它理解代码的背景、风格和约束。
Addy指出:高质量的上下文比强大的模型更重要。一个优秀的上下文可以弥补模型能力的不足。
上下文打包的3个关键要素
要素1:代码结构说明
# 项目结构src/├── api/ # API层(FastAPI路由)├── models/ # 数据模型(Pydantic)├── services/ # 业务逻辑└── utils/ # 工具函数# 代码规范- 使用类型注解- 函数不超过20行- 遵循PEP8规范- 错误处理使用自定义异常
这段文字告诉AI代码应该放在哪里,以及应该遵循什么风格。
要素2:相关代码片段
不要把整个项目塞给AI,只给最相关的部分。
假设你让AI写一个用户登录功能:
❌ 过多的上下文:
[整个项目的2000行代码]
✅ 精准的上下文:
# 现有的User模型classUser(BaseModel):id: int email: EmailStr password_hash: str# 现有的异常类classAuthenticationError(Exception):pass# 现有的工具函数defhash_password(password: str) -> str:# 哈希密码pass
AI只需要知道这些,就能生成符合项目风格的代码。
要素3:测试用例
提供测试用例是最清晰的上下文。它告诉AI代码应该如何工作。
deftest_login_success(): user = User(id=1, email="test@example.com", password_hash="hash")# 期望:登录成功,返回tokenassert login("test@example.com", "password") == "valid_token"deftest_login_wrong_password():# 期望:密码错误,抛出异常with pytest.raises(AuthenticationError): login("test@example.com", "wrong")
AI看到测试用例,就知道代码应该怎么写。
上下文窗口管理的实用技巧
现代AI模型的上下文窗口已经很大(GPT-4 Turbo支持128K tokens),但这并不意味着你可以随意塞内容。
技巧1:优先级排序
Addy建议按以下优先级选择上下文:
技巧2:使用引用而非复制
# 参考- 用户的登录逻辑:参考services/auth.py中的login()函数- 密码加密方式:参考utils/security.py中的hash_password()函数
这样可以节省上下文空间,同时给AI明确的指示。
技巧3:动态调整上下文
根据任务类型调整上下文:
- 新功能开发:更多架构文档、代码规范
- Bug修复:错误日志、相关代码片段
- 性能优化:性能测试结果、代码分析报告
一个真实案例
Addy团队开发Chrome扩展时,上下文打包策略是这样的:
基础上下文(所有任务通用):
任务特定上下文:
结果:AI生成代码的一次通过率从40%提升到75%。
6💡 本章小结
上下文打包的艺术在于精准而非全面。提供最相关的信息,让AI理解"代码应该长什么样",而不是"项目里有什么"。记住:上下文质量决定AI输出质量。
7🤖 多模型协作策略(Multi-Model Collaboration):取长补短
你是否只用一个AI编程工具?
Addy的调查显示:高效开发者平均使用2.5个不同的AI工具。每个模型都有擅长和不擅长的领域,关键是如何组合使用。
不同模型的优势对比
GPT-4系列
Claude系列
DeepSeek-Coder
本地模型(如CodeLlama)
多模型协作的4种策略
策略1:分阶段协作
不同阶段使用不同模型:
为什么这样设计?
策略2:并行验证
同一个任务让2个模型生成,对比结果:
# 让GPT-4生成defquick_sort_gpt(arr):# GPT-4的实现pass# 让Claude生成defquick_sort_claude(arr):# Claude的实现pass# 对比测试assert quick_sort_gpt([3,1,2]) == [1,2,3]assert quick_sort_claude([3,1,2]) == [1,2,3]
Addy的经验:并行验证可以减少40%的bug。
策略3:专家模型
针对特定任务使用专门的模型:
策略4:成本优化
在保证质量的前提下,降低成本:
简单任务(<100行代码):DeepSeek($0.14/1M tokens)中等任务(100-500行代码):Claude 3.5 Sonnet($3/1M tokens)复杂任务(>500行代码):GPT-4($30/1M tokens)
Addy团队通过多模型协作,将AI工具成本降低了60%,同时保持了代码质量。
一个真实案例
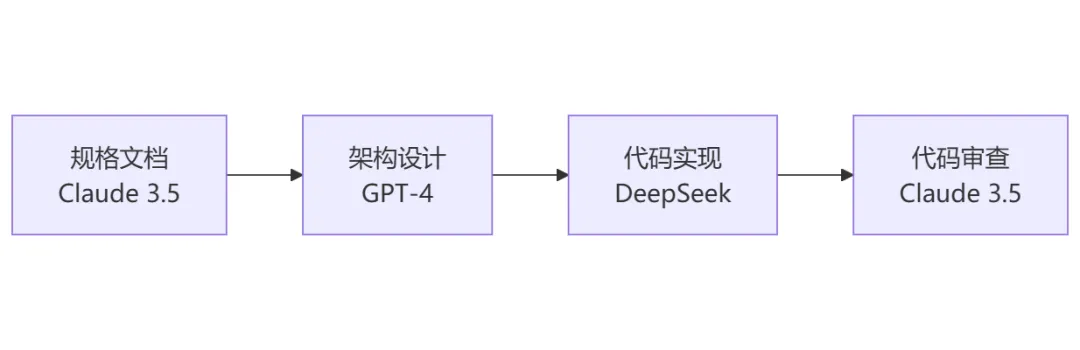
Addy团队开发Chrome DevTools插件时,多模型协作流程是这样的:
第1步:用Claude 3.5分析需求(长文本处理能力强)
第2步:用GPT-4设计架构(深度推理能力强)
第3步:用DeepSeek生成代码(快速生成能力强)
第4步:用Claude 3.5进行代码审查(代码分析能力强)
结果:开发周期缩短了40%,代码质量提升了25%。
8💡 本章小结
多模型协作的核心是取长补短。没有完美的模型,只有合适的模型组合。记住:工具是手段,解决问题是目的。
9👨💻 人机协同的最佳实践(Human-in-the-Loop):AI是助手,不是替代品
"AI会取代程序员吗?"
Addy的回答很直接:不会。但会用AI的程序员会取代不会用AI的程序员。
关键在于人类在环:AI负责生成,人类负责决策。
人类在环的真正含义
人类在环不是说AI生成代码后你简单看一下,而是说:
- 理解需求:你明确告诉AI要做什么
- 审查代码:你仔细检查AI生成的代码
- 测试验证:你编写测试用例验证功能
- 持续优化:你根据反馈不断改进
AI可以加速这个过程,但决策权始终在你手中。
高效审查AI代码的3个方法
方法1:增量审查
不要等AI生成1000行代码后一次性审查。
# 第1次:审查数据模型classUser:id: int name: str# 检查:字段是否完整?类型是否正确?# 第2次:审查API路由@app.post("/users")defcreate_user(user: User):# 检查:验证逻辑是否完整?错误处理是否正确?# 第3次:审查业务逻辑defsend_welcome_email(user: User):# 检查:逻辑是否正确?边界情况是否考虑?
每次审查都立即反馈,让AI知道"哪里错了"和"为什么错"。
方法2:审查清单
Addy使用这个清单审查AI代码:
# 代码审查清单功能正确性- [ ] 是否实现了所有需求?- [ ] 边界情况是否处理?(空值、负数、超大值)- [ ] 错误处理是否完整?代码质量- [ ] 变量命名是否清晰?- [ ] 函数是否过于复杂?(<20行)- [ ] 是否有重复代码?安全性- [ ] 用户输入是否验证?- [ ] 敏感信息是否处理?- [ ] SQL注入/XXE等漏洞是否避免?可维护性- [ ] 注释是否充分?- [ ] 是否符合项目规范?- [ ] 是否易于扩展?
方法3:自动化审查
使用工具辅助审查:
# 静态代码分析pylint ai_generated_code.pymypy ai_generated_code.py# 安全扫描bandit ai_generated_code.py# 测试覆盖率pytest --cov=ai_generated_code
工具可以快速发现明显的问题,让你专注于审查业务逻辑。
TDD与AI结合的最佳实践
测试驱动开发(TDD)和AI的结合是Addy强烈推荐的工作流。
传统TDD流程:
AI增强的TDD流程:
具体案例:
# 第1步:你写测试deftest_add_user(): service = UserService() user = service.add_user("Alice")assert user.idisnotNoneassert user.name == "Alice"# 第2步:AI生成代码classUserService:defadd_user(self, name):# AI自动生成实现return User(id=1, name=name)# 第3步:你审查# 看起来正确,但需要考虑重名情况# 第4步:你添加测试deftest_add_duplicate_user(): service = UserService() service.add_user("Alice")with pytest.raises(DuplicateUserError): service.add_user("Alice")# 第5步:AI完善代码classUserService:def__init__(self):self.users = {}self.next_id = 1defadd_user(self, name):if name inself.users:raise DuplicateUserError() user = User(id=self.next_id, name=name)self.users[name] = userself.next_id += 1return user
Addy团队使用AI增强的TDD后,测试覆盖率从75%提升到92%,bug率下降了50%。
10💡 本章小结
人类在环的核心是保持控制权。AI可以加速你的工作,但决策必须由你做出。记住:AI是强大的助手,但你才是最终的责任人。
11⚠️ 避坑指南(Pitfalls to Avoid):避开AI编程的陷阱
即使掌握了最佳实践,AI编程仍然有很多陷阱。Addy总结了最常见的5个陷阱,以及如何避免它们。
陷阱1:盲目信任AI输出
表现:AI生成代码后,直接提交,不审查、不测试。
风险:代码可能包含逻辑错误、安全漏洞、性能问题。
真实案例: 某公司工程师让AI生成支付逻辑,AI忘记处理并发情况,导致重复支付bug,造成5万美元损失。
如何避免:
陷阱2:一次性生成过大代码
表现:让AI一次性生成整个模块或系统。
风险:代码质量不稳定、难以调试、无法测试。
真实案例: Addy团队早期让AI一次性生成500行代码,结果发现第50行的一个错误导致整个模块无法工作,花了一周时间才找到问题。
如何避免:
陷阱3:忽略安全性
表现:让AI生成代码时,没有明确安全要求。
风险:SQL注入、XSS、XXE等安全漏洞。
真实案例: 某开发者让AI生成登录API,AI生成的代码没有密码加密,导致用户密码明文存储。
如何避免:
陷阱4:过度依赖AI,失去编程能力
表现:遇到问题直接问AI,不再自己思考。
风险:
真实案例: 某初级开发者过度依赖AI,6个月后发现自己已经不会写代码了,每次都需要AI帮助。
如何避免:
陷阱5:忽视代码维护成本
表现:只关注快速完成功能,不考虑长期维护。
风险:代码质量下降,技术债务累积。
真实案例: 某团队为了赶进度,大量使用AI生成代码,3个月后发现代码难以维护,不得不花2个月重构。
如何避免:
12💡 本章小结
AI编程的陷阱往往不是AI本身,而是人类的使用方式。保持警惕、独立思考、持续学习,才能让AI真正成为你的助手,而不是陷阱。
13🌟 总结与展望:2026年的编程是什么样子?
回顾Addy Osmani的《AI Coding Workflow 2026》,我们发现AI辅助编程的核心思想其实很简单:
人类负责思考和决策,AI负责生成和执行。
这不是取代,而是进化。
2026年编程的核心变化
角色转变:
技能升级:
工作方式:
给开发者的3条建议
建议1:拥抱变化,但不迷失自己
AI是强大的工具,但你才是决策者。不要因为有了AI就放弃思考和创造力。保持你的好奇心和热情,那才是你不可替代的价值。
建议2:持续学习,提升核心竞争力
学习AI工具的使用方法,更要学习AI无法替代的技能:系统设计、业务理解、沟通协作。这些才是你的核心竞争力。
建议3:实践最佳实践,形成自己的工作流
Addy分享的最佳实践是很好的参考,但不要生搬硬套。根据自己的实际情况,不断调整和优化,形成适合自己的AI编程工作流。
未来展望
2026年的编程,不再是你一个人在键盘上敲击代码,而是你指挥一个AI团队为你工作。
你不再需要记住所有的API,不再需要重复编写相似的代码,不再需要花费大量时间调试低级错误。
你可以将更多精力投入到:
这,才是编程的真正乐趣。
14💡 最终总结
AI辅助编程不是简单的工具使用,而是一种全新的编程思维方式。它要求我们:
2026年的编程,正在发生根本性的变革。你,准备好了吗?
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
