常用数据结构之列表-2
列表的内置方法(核心重点)
上一节我们学习了列表的基础用法(创建、核心运算、遍历),本节课将深入列表的进阶知识——包括列表的内置方法、高效创建列表的生成式、嵌套列表的使用,以及最后通过双色球选号案例巩固列表的综合应用。掌握这些内容,能让你真正灵活运用列表解决实际问题。
列表作为Python中最常用的容器类型,内置了大量实用方法,用于简化“添加、删除、查询、排序”等操作。调用列表方法的语法很固定:列表名.方法名(参数)。这里先明确一个概念:这种“通过变量调用方法”的语法,本质是“对象调用自身方法”(列表是一种对象)。后续学习面向对象编程时会详细讲解,现在大家只需记住“列表名.方法名”的调用格式即可。
添加元素
列表是可变容器(可修改内部元素),添加元素是最常用的操作之一,核心有两种场景:“在末尾追加”和“在指定位置插入”。
(1)append():在列表末尾追加元素(推荐,效率最高)
语法:列表.append(元素),直接在列表最后添加一个元素,不影响其他元素的位置。
(2)insert():在指定索引位置插入元素
语法:列表.insert(索引, 元素),在指定索引处插入元素,原索引及后续元素会自动向后移动(索引从0开始)。
languages = ['Python', 'Java', 'C++']languages.append('JavaScript')print(languages) # ['Python', 'Java', 'C++', 'JavaScript']languages.insert(1, 'SQL')print(languages) # ['Python', 'SQL', 'Java', 'C++', 'JavaScript']
小提示:append()只能在末尾添加一个元素,且效率比insert()高(insert()可能需要移动大量元素),日常开发中优先用append()。
删除元素有4种常用方式,适用场景不同,重点掌握它们的区别和注意事项:
(1)remove(元素):根据“元素值”删除(删除第一个匹配项)
语法:列表.remove(要删除的元素),通过元素值定位并删除,只删除第一个匹配的元素。
注意:如果要删除的元素不在列表中,会触发ValueError错误,导致程序崩溃。建议删除前先用in判断元素是否存在。
(2)pop(索引):根据“索引”删除(默认删最后一个,返回被删元素)
语法:列表.pop(索引),通过索引定位并删除元素,会返回被删除的元素(可赋值给变量备用)。
注意:如果索引越界(超出有效范围),会触发IndexError错误。省略索引时,默认删除最后一个元素(等价于pop(-1))。
(3)clear():清空列表所有元素(列表本身仍存在,变为空列表)
语法:列表.clear(),直接清空列表内容,不删除列表对象。
languages = ['Python', 'SQL', 'Java', 'C++', 'JavaScript']if'Java'in languages: languages.remove('Java')if'Swift'in languages: languages.remove('Swift')print(languages) # ['Python', 'SQL', C++', 'JavaScript']languages.pop()temp = languages.pop(1)print(temp) # SQLlanguages.append(temp)print(languages) # ['Python', C++', 'SQL']languages.clear()print(languages) # []
说明:pop方法删除元素时会得到被删除的元素,上面的代码中,我们将pop方法删除的元素赋值给了名为temp的变量。当然如果你愿意,还可以把这个元素再次加入到列表中,正如上面的代码languages.append(temp)所做的那样。
小疑问解答:如果列表中有多个重复元素(如['Python', 'Java', 'Python'),调用remove('Python'只会删除第一个匹配的元素,后续重复元素不受影响(大家可自行验证)。
(4)del 列表[索引]:关键字删除(根据索引,性能略优)
语法:del 列表[索引],通过索引删除元素,与pop(索引)功能类似,但不会返回被删除的元素。
优势:底层字节码指令更简洁,性能比pop()略好(日常开发中差异可忽略,按需选择即可)。
items = ['Python', 'Java', 'C++']del items[1]print(items) # ['Python', 'C++']
元素位置和频次
日常开发中常需要“查找元素位置”或“统计元素出现次数”,这两个方法能直接满足需求:
(1)index(元素, 起始索引):查找元素的索引位置
语法:列表.index(要找的元素, 起始索引),返回元素第一次出现的索引;可选参数“起始索引”表示从该位置开始查找。
注意:如果元素不存在,会触发ValueError错误。
(2)count(元素):统计元素出现的次数
语法:列表.count(元素),返回元素在列表中出现的次数;如果元素不存在,返回0(不会报错)。
items = ['Python', 'Java', 'Java', 'C++', 'Kotlin', 'Python']print(items.index('Python')) # 0# 从索引位置1开始查找'Python'print(items.index('Python', 1)) # 5print(items.count('Python')) # 2print(items.count('Kotlin')) # 1print(items.count('Swfit')) # 0# 从索引位置3开始查找'Java'print(items.index('Java', 3)) # ValueError: 'Java' is not in list
元素排序和反转
对列表元素进行“排序”或“反转顺序”是高频需求,这两个方法能直接实现,无需手动写循环:
(1)sort():对列表元素排序(默认升序)
语法:列表.sort(),直接修改原列表的顺序(默认按字符编码/数字大小升序)。若需降序,可加参数reverse=True(如items.sort(reverse=True))。
(2)reverse():反转列表元素的顺序
语法:列表.reverse(),直接修改原列表,将元素顺序完全颠倒(不是排序,只是反转)。
items = ['Python', 'Java', 'C++', 'Kotlin', 'Swift']items.sort()print(items) # ['C++', 'Java', 'Kotlin', 'Python', 'Swift']items.reverse()print(items) # ['Swift', 'Python', 'Kotlin', 'Java', 'C++']
列表生成式(高效创建列表的神器)
上一节我们用[]或list()创建列表,但如果需要“根据规则动态生成列表”(如筛选、转换元素),传统的for循环+append()会比较繁琐。而列表生成式能让代码更简洁、性能更优。下面,我们将通过3个高频场景,直观感受列表生成式的优势:
场景一:创建一个取值范围在1到99且能被3或者5整除的数字构成的列表。
items = []for i inrange(1, 100):if i % 3 == 0or i % 5 == 0: items.append(i)print(items)
使用列表生成式做同样的事情,代码如下所示。
items = [i for i inrange(1, 100) if i % 3 == 0or i % 5 == 0]print(items)
场景二:有一个整数列表nums1,创建一个新的列表nums2,nums2中的元素是nums1中对应元素的平方。
nums1 = [35, 12, 97, 64, 55]nums2 = []for num in nums1: nums2.append(num ** 2)print(nums2)
使用列表生成式做同样的事情,代码如下所示。
nums1 = [35, 12, 97, 64, 55]nums2 = [num ** 2for num in nums1]print(nums2)
场景三: 有一个整数列表nums1,创建一个新的列表nums2,将nums1中大于50的元素放到nums2中。
nums1 = [35, 12, 97, 64, 55]nums2 = []for num in nums1:if num > 50: nums2.append(num)print(nums2)
使用列表生成式做同样的事情,代码如下所示。
nums1 = [35, 12, 97, 64, 55]nums2 = [num for num in nums1 if num > 50]print(nums2)
使用列表生成式创建列表不仅代码简单优雅,而且性能上也优于使用for-in循环和append方法向空列表中追加元素的方式。为什么说生成式有更好的性能呢,那是因为 Python 解释器的字节码指令中有专门针对生成式的指令(LIST_APPEND指令);而for循环是通过方法调用(LOAD_METHOD和CALL_METHOD指令)的方式为列表添加元素,方法调用本身就是一个相对比较耗时的操作。对这一点不理解也没有关系,记住“强烈建议用生成式语法来创建列表”这个结论就可以了。
嵌套列表(列表中的列表)
Python允许列表中的元素是任意类型,包括列表本身——这种“列表包含列表”的结构,称为嵌套列表。嵌套列表最常用的场景是表示“表格”或“矩阵”(如学生成绩表、二维数据)。
scores = [[95, 83, 92], [80, 75, 82], [92, 97, 90], [80, 78, 69], [65, 66, 89]]print(scores[0])print(scores[0][1])
对于上面的嵌套列表,每个元素相当于就是一个学生3门课程的成绩,例如[95, 83, 92],而这个列表中的83代表了这个学生某一门课的成绩,如果想访问这个值,可以使用两次索引运算scores[0][1],其中scores[0]可以得到[95, 83, 92]这个列表,再次使用索引运算[1]就可以获得该列表中的第二个元素。
如果想通过键盘输入的方式来录入5个学生3门课程的成绩并保存在列表中,可以使用如下所示的代码。
scores = []for _ inrange(5): temp = []for _ inrange(3): score = int(input('请输入: ')) temp.append(score) scores.append(temp)print(scores)
如果想通过产生随机数的方式来生成5个学生3门课程的成绩并保存在列表中,我们可以使用列表生成式,代码如下所示。
import randomscores = [[random.randrange(60, 101) for _ inrange(3)] for _ inrange(5)]print(scores)
说明:上面的代码[random.randrange(60, 101) for _ in range(3)] 可以产生由3个随机整数构成的列表,我们把这段代码又放在了另一个列表生成式中作为列表的元素,这样的元素一共生成5个,最终得到了一个嵌套列表。
列表实战
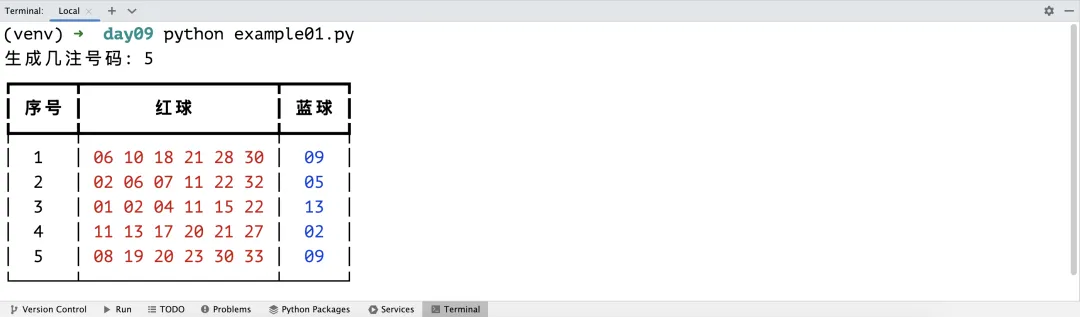
下面我们通过一个双色球随机选号的例子为大家讲解列表的应用。双色球是由中国福利彩票发行管理中心发售的乐透型彩票,每注投注号码由6个红色球和1个蓝色球组成。红色球号码从1到33中选择,蓝色球号码从1到16中选择。每注需要选择6个红色球号码和1个蓝色球号码,如下所示。