我们今天不学习新的知识点,只处理前面学元组和列表留下的作业,大家若是对作业解答有不同见解,都可以留言交流。
作业:
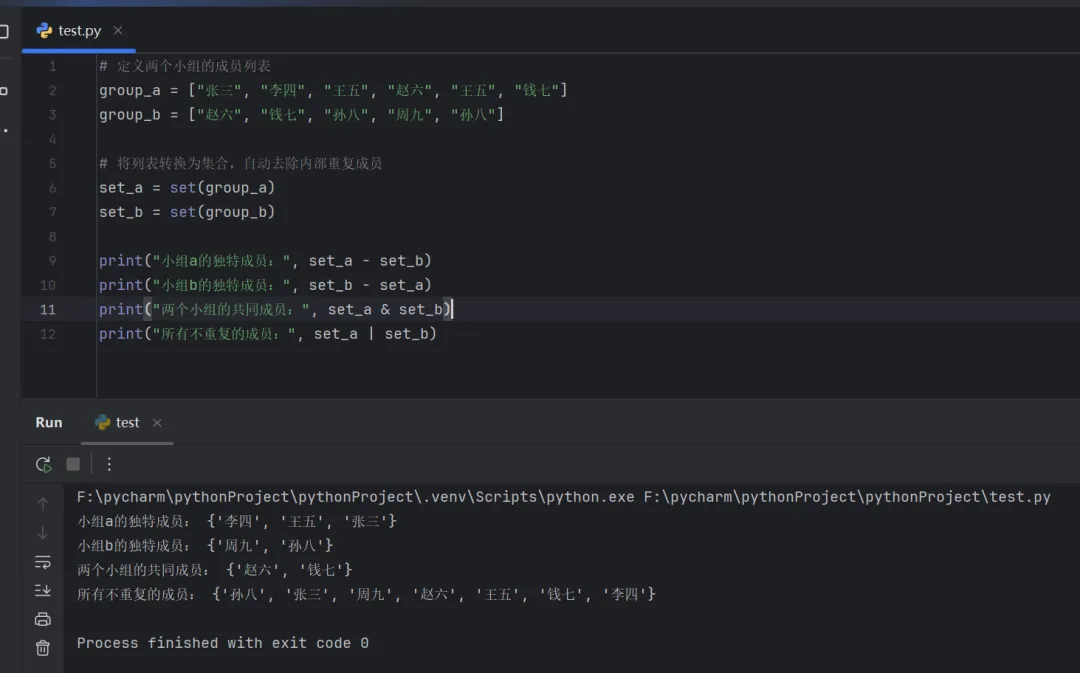
已知两个小组成员:
小组a成员有:"张三"、"李四"、"王五"、"赵六"、"王五"、"钱七",
小组b成员有:"赵六"、"钱七"、"孙八"、"周九"、"孙八"。
请按照以下要求进行操作:
① 求小组a的独特成员;
② 求小组b的独特成员;
③ 求两个小组的共同成员;
④ 求所有不重复的成员。
# 定义两个小组的成员列表group_a = ["张三", "李四", "王五", "赵六", "王五", "钱七"]group_b = ["赵六", "钱七", "孙八", "周九", "孙八"]# 将列表转换为集合,自动去除内部重复成员set_a = set(group_a)set_b = set(group_b)print("小组a的独特成员:", set_a - set_b)print("小组b的独特成员:", set_b - set_a)print("两个小组的共同成员:", set_a & set_b)print("所有不重复的成员:", set_a | set_b)
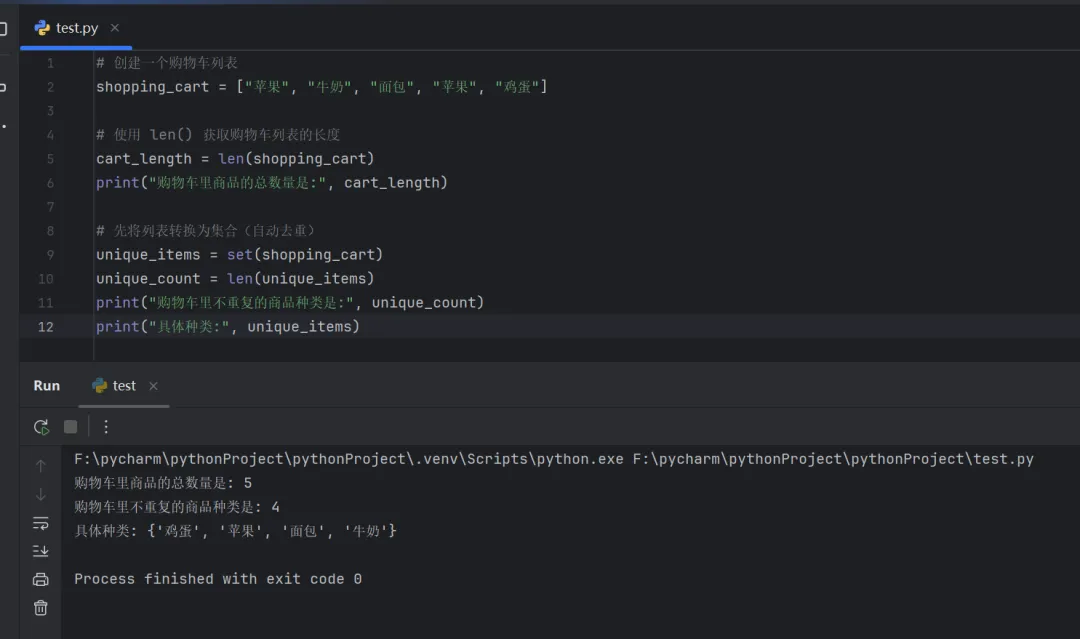
作业:
已知一个购物车列表里有:"苹果"、"牛奶"、"面包"、 "苹果"、"鸡蛋",请按照以下要求进行操作:
① 购物车里商品的总数量;
② 购物车里不重复的商品种类以及具体种类。
# 创建一个购物车列表shopping_cart = ["苹果", "牛奶", "面包", "苹果", "鸡蛋"]# 使用 len() 获取购物车列表的长度cart_length = len(shopping_cart)print("购物车里商品的总数量是:", cart_length) # 先将列表转换为集合(自动去重)unique_items = set(shopping_cart)unique_count = len(unique_items)print("购物车里不重复的商品种类是:", unique_count) print("具体种类:", unique_items)
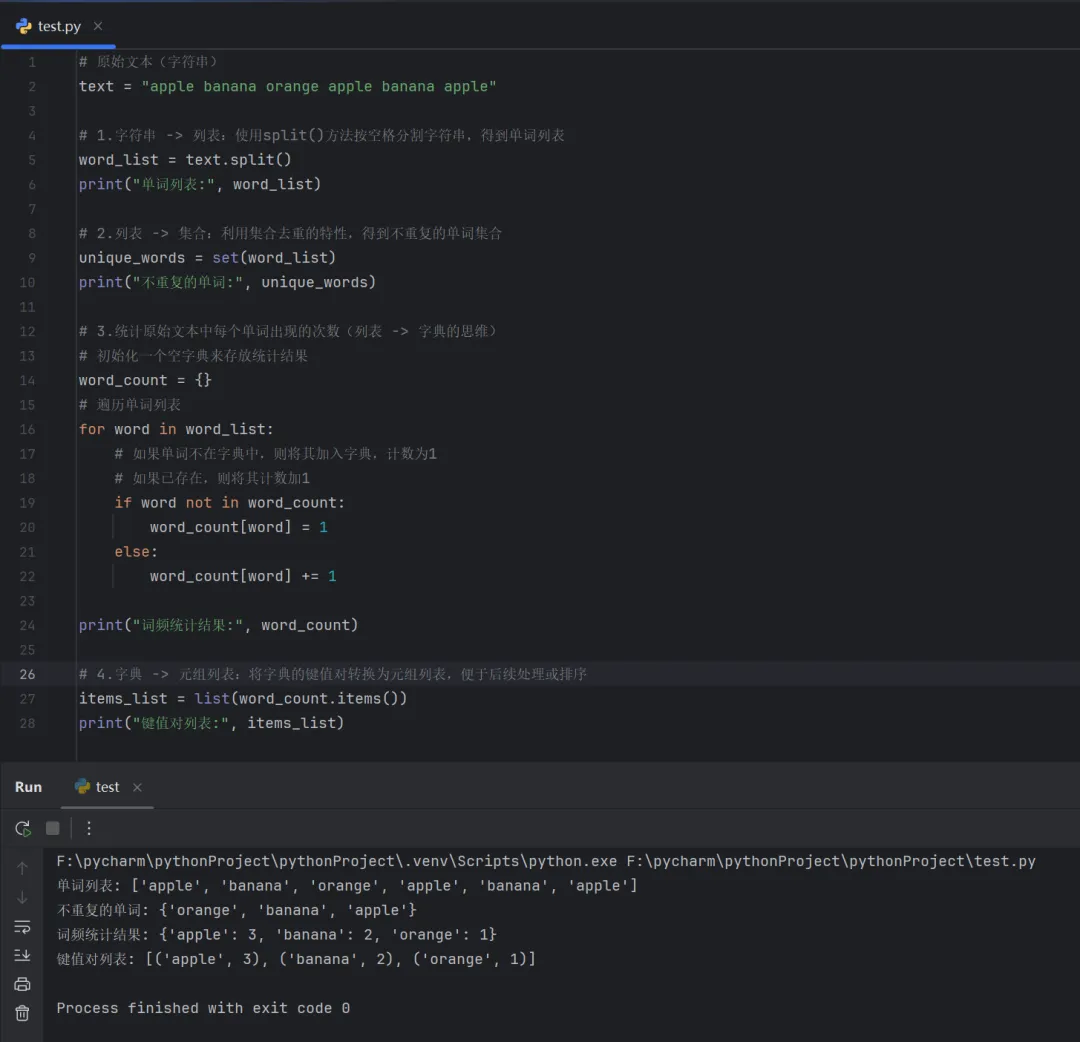
作业:
有一段文本"apple banana orange apple banana apple",请按照以下要求进行操作:
1、按空格分割字符串,得到单词列表;
2、去重,得到不重复的单词集合;
3、统计原始文本中每个单词出现的次数;
4、将第3步的结果转换为元组列表。
# 原始文本(字符串)text = "apple banana orange apple banana apple"# 1.字符串 -> 列表:使用split()方法按空格分割字符串,得到单词列表word_list = text.split()print("单词列表:", word_list) # 2.列表 -> 集合:利用集合去重的特性,得到不重复的单词集合unique_words = set(word_list)print("不重复的单词:", unique_words)# 3.统计原始文本中每个单词出现的次数(列表 -> 字典的思维)# 初始化一个空字典来存放统计结果word_count = {}# 遍历单词列表for word in word_list: # 如果单词不在字典中,则将其加入字典,计数为1 # 如果已存在,则将其计数加1 if word not in word_count: word_count[word] = 1 else: word_count[word] += 1print("词频统计结果:", word_count)# 4.字典 -> 元组列表:将字典的键值对转换为元组列表,便于后续处理或排序items_list = list(word_count.items())print("键值对列表:", items_list)
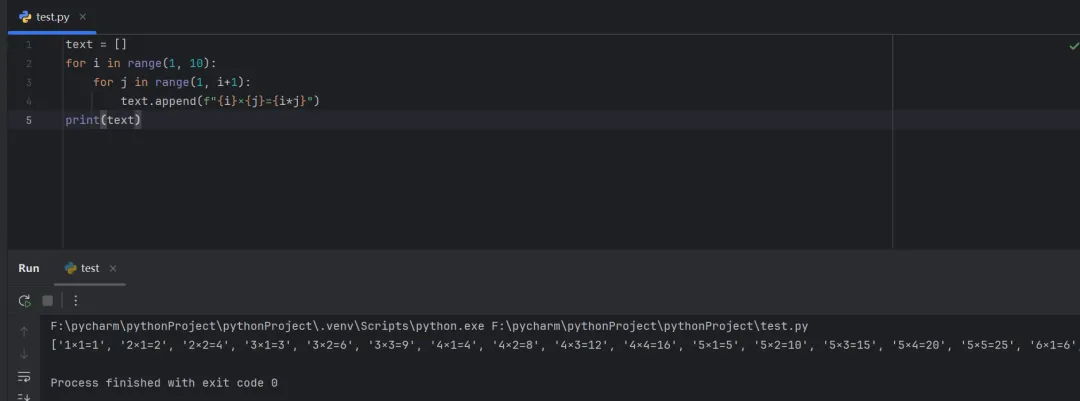
作业:
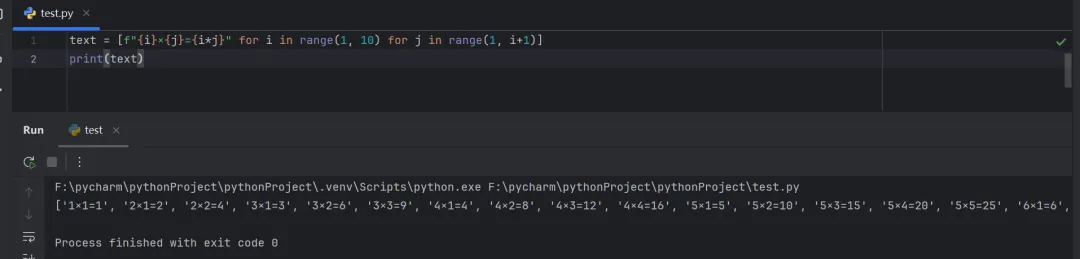
使用for循环嵌套列表推导式,生成一个9*9乘法表。
传统for循环写法:
text = []for i in range(1, 10): for j in range(1, i+1): text.append(f"{i}×{j}={i*j}")print(text)
# 代码分析:# 外层循环:for i in range(1, 10)控制乘法的第一个数(1到9);# 内层循环:for j in range(1, i+1)控制乘法的第二个数(1到i),确保只生成j≤i的项,避免重复;# 表达式:f"{i}×{j}={i*j}"使用f-string格式化字符串,生成每个乘法项。
使用for循环嵌套列表推导式:
text = [f"{i}×{j}={i*j}"for i in range(1, 10) for j in range(1, i+1)]print(text)
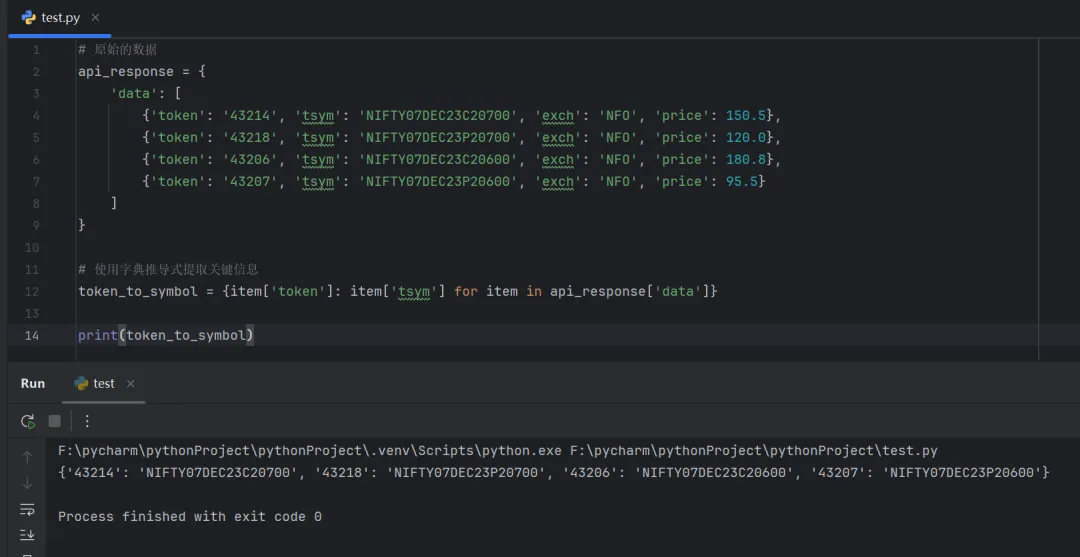
api_response = { 'data': [ {'token': '43214', 'tsym': 'NIFTY07DEC23C20700', 'exch': 'NFO', 'price': 150.5}, {'token': '43218', 'tsym': 'NIFTY07DEC23P20700', 'exch': 'NFO', 'price': 120.0}, {'token': '43206', 'tsym': 'NIFTY07DEC23C20600', 'exch': 'NFO', 'price': 180.8}, {'token': '43207', 'tsym': 'NIFTY07DEC23P20600', 'exch': 'NFO', 'price': 95.5} ]}
{'43214': 'NIFTY07DEC23C20700', '43218': 'NIFTY07DEC23P20700', '43206': 'NIFTY07DEC23C20600', '43207': 'NIFTY07DEC23P20600'}
代码实现:
# 原始的数据api_response = { 'data': [ {'token': '43214', 'tsym': 'NIFTY07DEC23C20700', 'exch': 'NFO', 'price': 150.5}, {'token': '43218', 'tsym': 'NIFTY07DEC23P20700', 'exch': 'NFO', 'price': 120.0}, {'token': '43206', 'tsym': 'NIFTY07DEC23C20600', 'exch': 'NFO', 'price': 180.8}, {'token': '43207', 'tsym': 'NIFTY07DEC23P20600', 'exch': 'NFO', 'price': 95.5} ]}# 使用字典推导式提取关键信息token_to_symbol = {item['token']: item['tsym'] for item in api_response['data']}print(token_to_symbol)
今日学习完毕,课后作业:
有空的小伙伴,可以参考代码运行,还是建议不看着代码自己手打,学习效率更好。明天继续学习新的python知识点。











 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
