0. 前情回顾
上一节我们介绍了opencv-contrib库以及传统的人脸识别算法,包括Eigenfaces、Fisherfaces和LBPH。但从实践情况看,传统的人脸识别算法在复杂环境下(如光照变化、角度变化等)的识别率较低。为了提高一些场景下的识别率,我们可以将传统的人脸识别算法与人脸检测算法结合起来。好了,今天我们就重点说说人脸检测。
1. 目标检测
人脸检测属于计算机视觉中的目标检测范畴,其目标是在图像或视频中定位和识别出人脸区域。 下面使用了论文《Object Detection in 20 Years: A Survey》中的一张图,来简单回顾下目标检测的发展历程。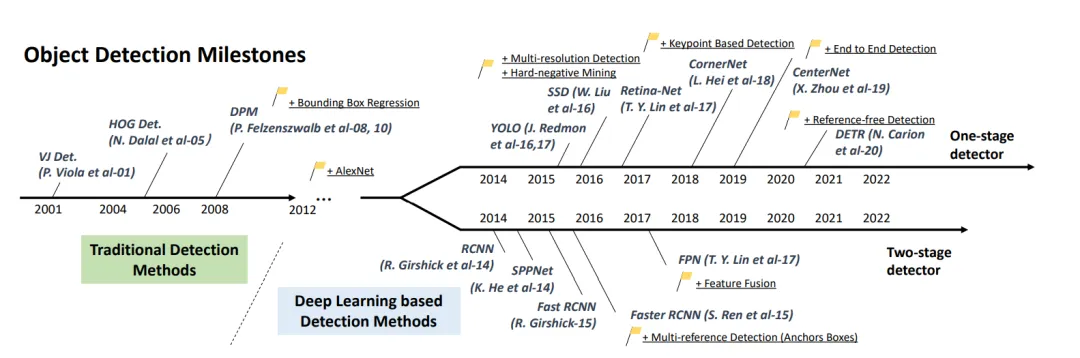
1.1 手工特征时代
这个时期是传统的检测方法时代,主要特点是手工设计特征 + 滑动窗口 + 分类器。 请出主要代表:Viola-Jones (2001):Haar-like 特征 + AdaBoost + 级联结构 → 实时人脸检测HOG + SVM (2005):用于行人检测,捕捉边缘方向DPM (2008–2010):将物体分解为“根 + 部件”,可变形匹配,PASCAL VOC 冠军多年
1.2 两阶段深度学习
将检测分成两个阶段:先生成候选区域(Region Proposal),再分类+回归。 请出主要代表:R-CNN:用 Selective Search 生成 2000 个候选框 → 逐个送入 CNN → SVM 分类Fast R-CNN:共享卷积特征 + RoI Pooling → 速度提升 10 倍Faster R-CNN:用 RPN(Region Proposal Network) 替代 Selective Search → 全卷积、端到端 它的优势是精度高,成为学术标准。但是也有缺点,两阶段的速度受到了些许的限制。
1.3 单阶段深度学习
让检测一步到位,直接在特征图上预测边界框。 请出主要代表:YOLO v1 (You Only Look Once):将图像划分为 S×S 网格,每个网格预测 B 个框 → 实时检测SSD(Single Shot MultiBox Detector):在多个尺度特征图上检测 → 更好处理小目标RetinaNet:提出 Focal Loss,解决前景/背景极端不平衡问题 → 单阶段精度首次超越两阶段 它的优势就是快,并能够在移动端和嵌入式部署。
1.4 Transformer与无锚框
主要代表是DETR:用Transformer编码器-解码器直接输出固定数量的检测结果,无需NMS后处理(好省心),真正端到端。它的缺点是训练慢、小目标性能差。
1.5 小总结
2. 基于Viola-Jones算法的cv2.CascadeClassifier
cv2.CascadeClassifier是OpenCV中用于基于Haar特征或LBP特征的级联分类器(Cascade Classifier) 的核心类,主要用于实时目标检测,尤其在人脸、眼睛、身体等刚性物体检测中广泛应用。经过许多年的发展,它依然凭借着速度快、内存占用低、无需GPU、部署简单,在嵌入式设备、实时视频流、教学和轻量级应用中占据重要地位。
2.1 Viola-Jones算法背后的故事
很多年前,微软研究院来了两位年轻的员工(有人称他们为科学家): 保罗·维奥拉(Paul Viola):一个数学天才,喜欢思考“怎么用最简单的方法解决问题”; 迈克尔·琼斯(Michael Jones):一个工程高手,总想着“这玩意儿能不能跑在普通电脑上?” 他们在寻找一个通用的目标检测方案。
有一天,保罗盯着一张人脸照片发呆。他忽然想到:“人脸其实有很多明暗规律啊! 眼睛比脸颊暗; 鼻梁比两边亮; 嘴巴下方比上方暗……” 于是他画了一些简单的“黑白格子”来捕捉这些规律:
[白][黑] → 能检测垂直边缘(比如鼻梁)
[黑]
[白] → 能检测水平边缘(比如眼睛)
[白][黑][白] → 能检测一条亮线(比如眉毛)
通过这些规律,不用理解“这是眼睛”,只要知道“这里暗、那里亮”就够了!而这些格子,就是后来大名鼎鼎的Haar-like特征。
但问题来了:一张图有成千上万个位置,每个位置又有上万个格子组合——这要算到猴年马月呢? 这时,迈克尔拍了下桌子:“我们能不能提前算好一张‘速查表’?”他们想到了一个叫**积分图(Integral Image)**的妙招: 先花一点时间,把整张图变成一张“累加和地图”; 之后,任何矩形区域的亮度和,只要查4个数就能算出来!从此,特征计算的速度就像坐上了火箭。
但还有最后一个大问题:怎么判断一个区域是不是人脸? 传统方法是训练一个“超级大脑”来判断——但太慢了。 保罗和迈克尔想了个绝招:别用一个大脑,用一串小关卡! 他们设计了一座“级联筛子塔”: 第一层:只用 2 个最简单的格子(比如“眼睛暗不暗?”)→ 如果连这都过不了,立刻扔掉!(90% 的背景在这就被筛掉了) 第二层:用 10 个稍复杂的格子再检查 → 又筛掉一大半。 …… 最后一层:用几百个格子精细确认。结果95%的区域在第一关就被淘汰,根本不用算后面的!
于是,他们俩在2001年将这个重大发现发表在了论文中:Rapid Object Detection using a Boosted Cascade of Simple Features
2.2 “Haar-like特征”指的是什么?
Alfréd Haar(1885–1933)是一位匈牙利数学家,师从著名数学家 David Hilbert。他在博士论文中首次构造了一组分段常数的正交函数基,用于函数逼近。这组基就是今天所说的 Haar 小波,是所有小波分析的起点。所以,“Haar” 不是一个缩写,而是人名,发音近似 “哈”(/hɑːr/)。 Viola和 Jones在2001年并没有直接使用Haar小波,而是受其启发,设计了一类更简单的矩形特征,称为 Haar-like Features(类 Haar 特征)。 这些特征由相邻矩形区域的像素和之差构成,例如:
| | |
|---|
| 边缘特征 | ■■□□ | |
| 线特征 | □■□ | |
| 中心环绕 | □□□ □■□ □□□ | |
2.3 CascadeClassifier支持的特征类型
OpenCV提供两类预训练级联模型:
| | |
|---|
| Haar 特征 | .xml(如 haarcascade_frontalface_default.xml) | |
| LBP 特征 | .xml(如 lbpcascade_frontalface.xml) | |
2.4 OpenCV自带的常用预训练模型
安装 OpenCV 后,这些文件通常位于:
- Python:
site-packages/cv2/data/ - C++: OpenCV 源码的
data/haarcascades/ 目录
人脸相关
| |
|---|
haarcascade_frontalface_default.xml | |
haarcascade_frontalface_alt.xml | |
haarcascade_profileface.xml | |
haarcascade_eye.xml | |
haarcascade_eye_tree_eyeglasses.xml | |
lbpcascade_frontalface.xml | |
其他
haarcascade_fullbody.xml:全身人haarcascade_upperbody.xml:上半身haarcascade_smile.xml:微笑检测
💡 获取路径(Python):
import cv2
print(cv2.data.haarcascades) # 输出级联文件目录
3. CascadeClassifier的实践
3.1 创建分类器
# 加载 Haar 模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 或加载自定义路径
face_cascade = cv2.CascadeClassifier('my_face_model.xml')
注意:检查是否加载成功!
if face_cascade.empty():
raise IOError("无法加载级联分类器")
3.2 检测目标:detectMultiScale()
faces = face_cascade.detectMultiScale(
image, # 输入图像(建议灰度图)
scaleFactor=1.1, # 图像缩放比例(用于多尺度检测)
minNeighbors=5, # 每个候选框需有多少个邻居才保留(越大越严格)
minSize=(30, 30),# 最小检测尺寸
maxSize=(300, 300)# 最大检测尺寸(可选)
)
参数说明:
| | |
|---|
scaleFactor | 每次图像缩放的比例(>1)
值越小,检测越细,速度越慢 | |
minNeighbors | | |
minSize | | |
flags | 旧版参数(如 CV_HAAR_SCALE_IMAGE),新版可忽略 | |
返回值:Nx4 的 NumPy 数组,每行为 [x, y, w, h](左上角坐标 + 宽高)
3.3 完整人脸检测示例
import cv2
# 1. 加载分类器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
if face_cascade.empty():
raise IOError("无法加载人脸级联文件")
# 2. 读取图像
img = cv2.imread('group.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 3. 检测人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30)
)
# 4. 绘制结果
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 5. 显示
cv2.imshow('Detected Faces', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
检测结果如下: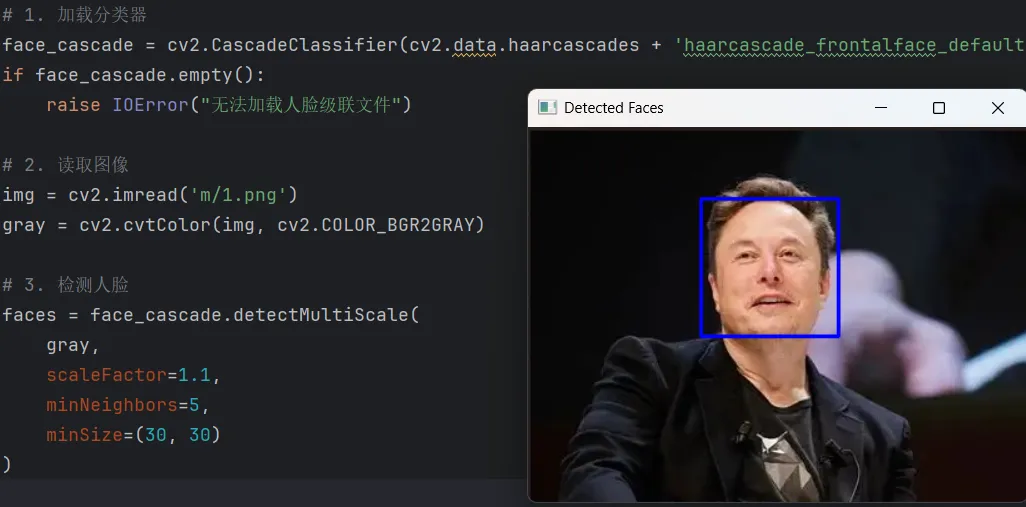
4. 人脸识别前加入人脸检测
最关键的环节来了,我们要将人脸检测功能加入到上一节的人脸识别中,这样可以强化训练和验证。 首先,加载Haar人脸检测器:
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
if face_cascade.empty():
raise IOError("❌ 无法加载 Haar 人脸检测模型!")
其次新增方法,检测图像中最大的人脸并会返回剪裁后的灰度图:
defdetect_largest_face(img):
if img isNone:
returnNone
if len(img.shape) == 3:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
else:
gray = img.copy()
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60)
)
if len(faces) == 0:
returnNone
# 选择面积最大的人脸(通常是最清晰/最近的)
areas = [w * h for (x, y, w, h) in faces]
idx = np.argmax(areas)
x, y, w, h = faces[idx]
face_crop = gray[y:y + h, x:x + w]
return face_crop
从每个文件夹加载图像,自动检测并裁剪人脸:
defload_and_crop_faces_from_folders(folder_dict):
images = []
labels = []
skipped = 0
for name, label in folder_dict.items():
folder_path = name
ifnot os.path.exists(folder_path):
print(f"⚠️ 警告:文件夹 {folder_path} 不存在,跳过")
continue
for filename in os.listdir(folder_path):
ifnot filename.lower().endswith(('.png', '.jpg', '.jpeg')):
continue
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path)
if img isNone:
skipped += 1
continue
# 关键步骤:检测并裁剪人脸
face_img = detect_largest_face(img)
if face_img isNone:
print(f"⚠️ 未在 {img_path} 中检测到人脸,跳过")
skipped += 1
continue
images.append(face_img)
labels.append(label)
print(f"✅ 成功加载 {len(images)} 张人脸,跳过 {skipped} 张无效图像")
return images, labels
主函数中调用训练和识别:
train_images, train_labels = load_and_crop_faces_from_folders(FOLDERS)
if len(train_images) == 0:
raise ValueError("❌ 没有成功加载任何人脸图像!请检查 o/t/m 文件夹中的图片是否包含清晰正面人脸。")
print(f"📊 标签分布: {dict(zip(*np.unique(train_labels, return_counts=True)))}")
# 统一尺寸(所有人脸 resize 到相同大小)
TARGET_SIZE = (400, 300)
train_images = [preprocess_image(img, TARGET_SIZE) for img in train_images]
# 训练 LBPH 模型
print("🧠 训练 LBPH 人脸识别模型...")
model = cv2.face.LBPHFaceRecognizer_create()
model.train(train_images, np.array(train_labels))
# ===== 测试阶段(同样先检测人脸)=====
ifnot os.path.exists(TEST_FOLDER):
raise ValueError(f"❌ 测试文件夹 '{TEST_FOLDER}' 不存在!")
test_files = [f for f in os.listdir(TEST_FOLDER) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
ifnot test_files:
raise ValueError(f"❌ 测试文件夹 '{TEST_FOLDER}' 中没有图片!")
print(f"\n🔍 开始测试 {len(test_files)} 张图片...\n")
for test_file in test_files:
test_path = os.path.join(TEST_FOLDER, test_file)
test_img = cv2.imread(test_path)
if test_img isNone:
print(f"⚠️ 跳过无效图像: {test_file}")
continue
# 检测测试图中的人脸
detected_faces, face_rects = [], []
gray_test = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY) if len(test_img.shape) == 3else test_img
faces = face_cascade.detectMultiScale(
gray_test,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60)
)
if len(faces) == 0:
print(f"{test_file}: ❌ 未检测到任何人脸")
continue
print(f"{test_file}: 检测到 {len(faces)} 张人脸")
for i, (x, y, w, h) in enumerate(faces):
face_roi = gray_test[y:y + h, x:x + w]
face_resized = preprocess_image(face_roi, TARGET_SIZE)
predicted_label, confidence = model.predict(face_resized)
if confidence < THRESHOLD and predicted_label in LABEL_TO_NAME:
person_name = LABEL_TO_NAME[predicted_label]
result = f" 👤 人脸 {i + 1}: ✅ {person_name} (置信度: {confidence:.1f})"
else:
result = f" 👤 人脸 {i + 1}: ❌ 未知 (置信度: {confidence:.1f})"
print(result)
print("训练与测试完成!")
结果如下图:
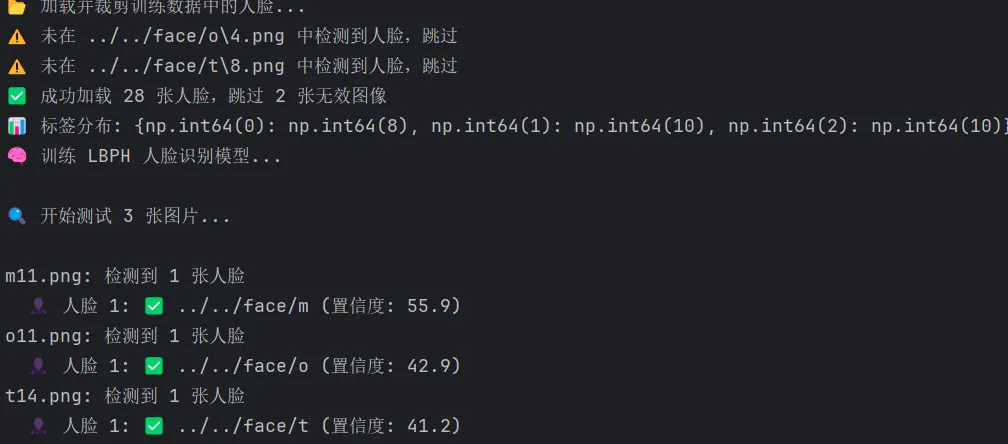 人脸识别结果
人脸识别结果5. 最后
通过实践可以发现,有了人脸检测的加持,识别的准确率提升了很多。 至此,传统算法的人脸识别任务完成。下一期,让我们来搞搞深度学习的人脸识别! 有什么问题,我们评论区见。
参考:
- OpenCV官方文档之Cascade Classifier
- Object Detection in 20 Years: A Survey
#目标检测 #人脸检测 #HAAR
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
