之前聊过 LLM 其实更擅长写代码而不是调用工具,这篇就是实践篇。我做的事情很简单,就是完全按照 blog 写的思路,我不让 llm 来调用 mcp tools,而是通过代码的方式来调用 mcp tools,可以看到,整个 agent 的方案会更加的灵活和高效。
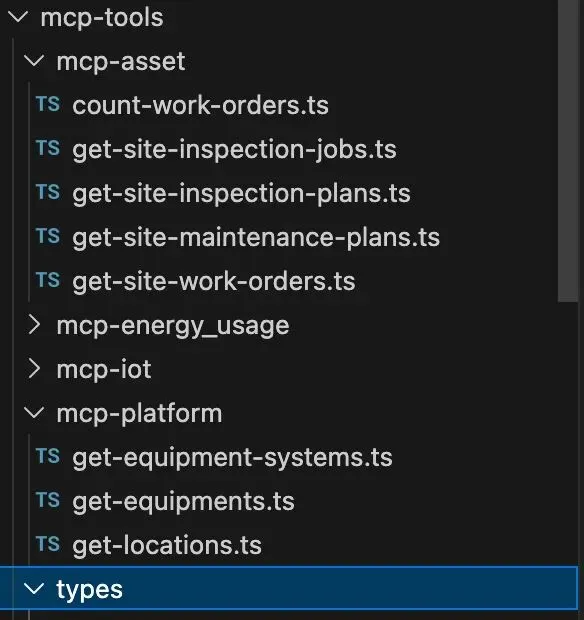
第一步,所有的 mcp tools 我都把它变成了可以调用的 ts 文件(包括代码调用和 schema),我这里有4个 mcp servers,一共十几个 mcp tools。图一。
第二步,所有的 mcp tools 不会注册给 llm,只会在处理用户问题的时候,它需要通过 bash 工具(本地的 bash 工具)去搜索这个 mcp tools 文件夹,然后送给 llm 一次来判断,应该加载什么 mcp 工具。比如对于问题 - “什么系统的工单最多”, llm 会从这个 mcp-tools 目录中找到对应的三个工具 ,[get-equipment-systems,get-equipments,get-site-work-orders]
第三步,让 llm 根据对应的这3个工具的 ts 文件 + 用户的问题,生成对应的代码,这是第2次调用 llm,输出就是生成的、可执行的代码。
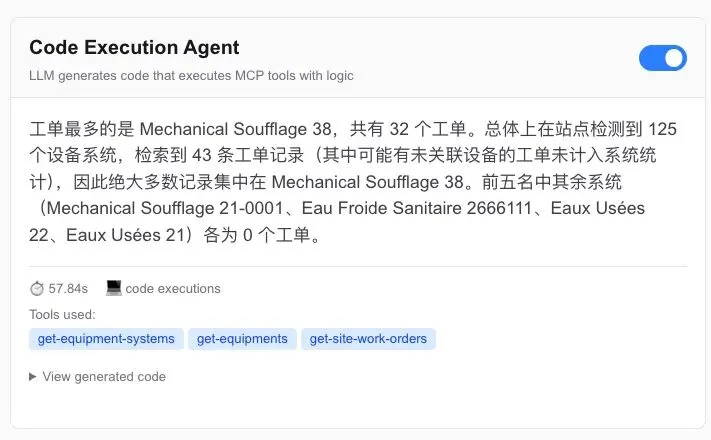
第四步,通过代码的调用,把生成的代码,丢到本地沙盒去运行。运行的结果见图二,代码的方式就是很灵活,你可以做统计,做聚合等数据分析,代码就是一句话的事情。
所以,将来 agent 的实现方向,肯定不会是大量的调用工具,工具的设计一定是高度抽象和能自由组合的,少量的通用工具就可以。然后剩下的就是业务知识(从 memory 来给)+ 代码的生成执行了。而且这个版本的 agent 实现更加的通用,之前我们花了很多时间在设计很多工具,同时为了减少上下文进行信息的传递,需要把每个工具的结果都存起来,用于工具之间的调用,同时还要写好几个本地统计聚合工具来根据返回的工具的 schema 进行分析,实际上代码 agent 要简洁的多。
另外一个好处就是之前 blog 上说的,工具的所有调用和结果处理都在代码中处理了,基本上不需要把工具的定义+工具的调用结果返回给 LLM 了,这节省了大量的时间和成本。
如果有细节问题想要了解实现的,欢迎关注后私信或者留言询问,共同交流~
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
