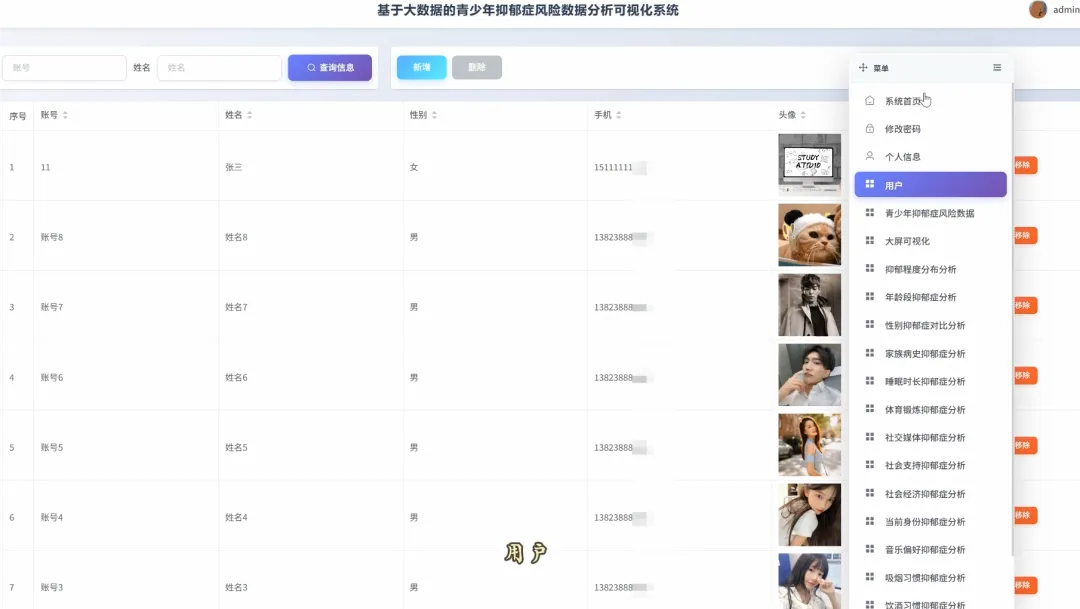
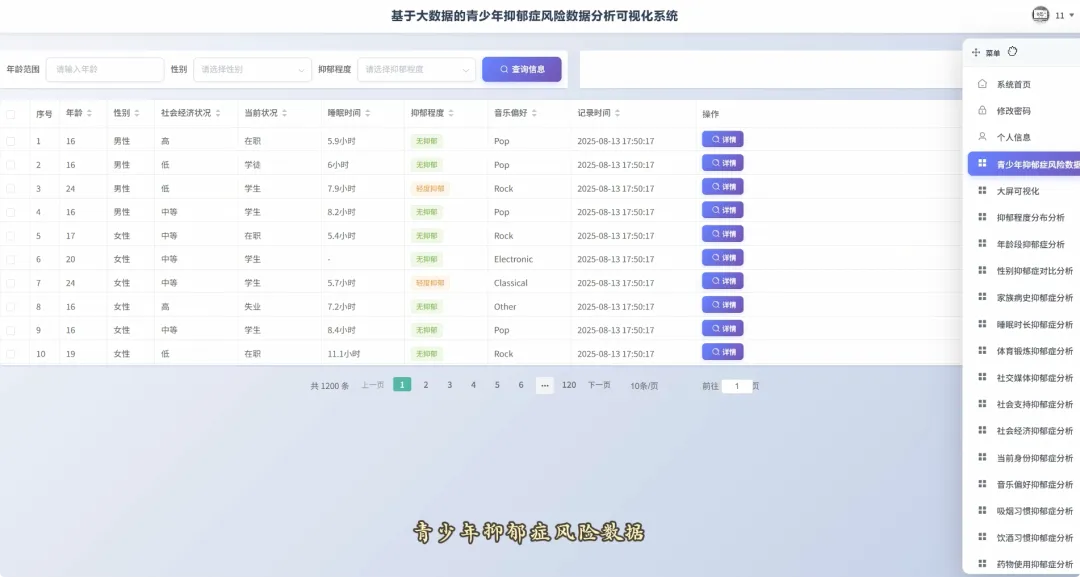
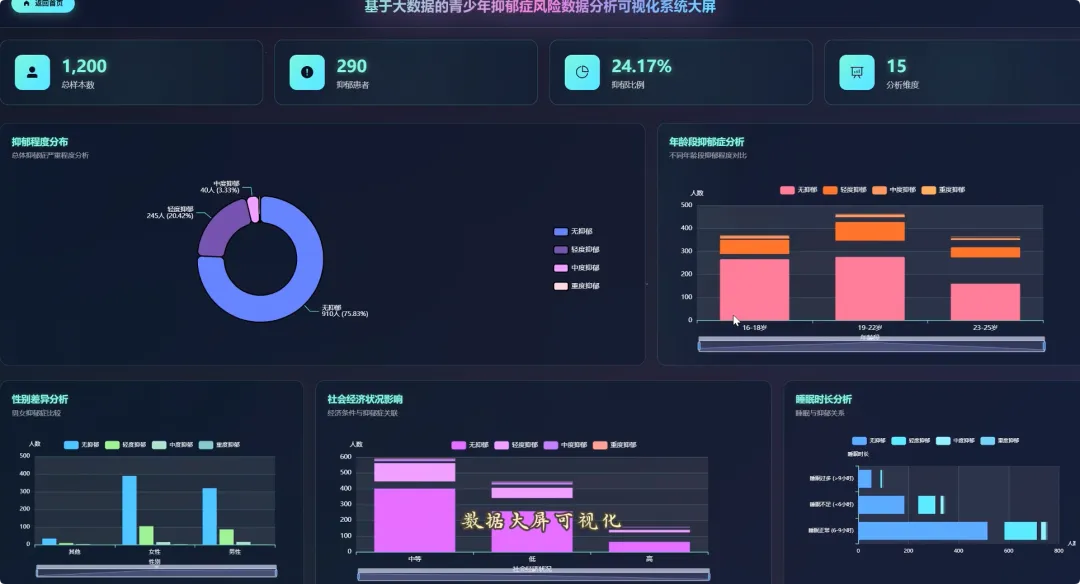
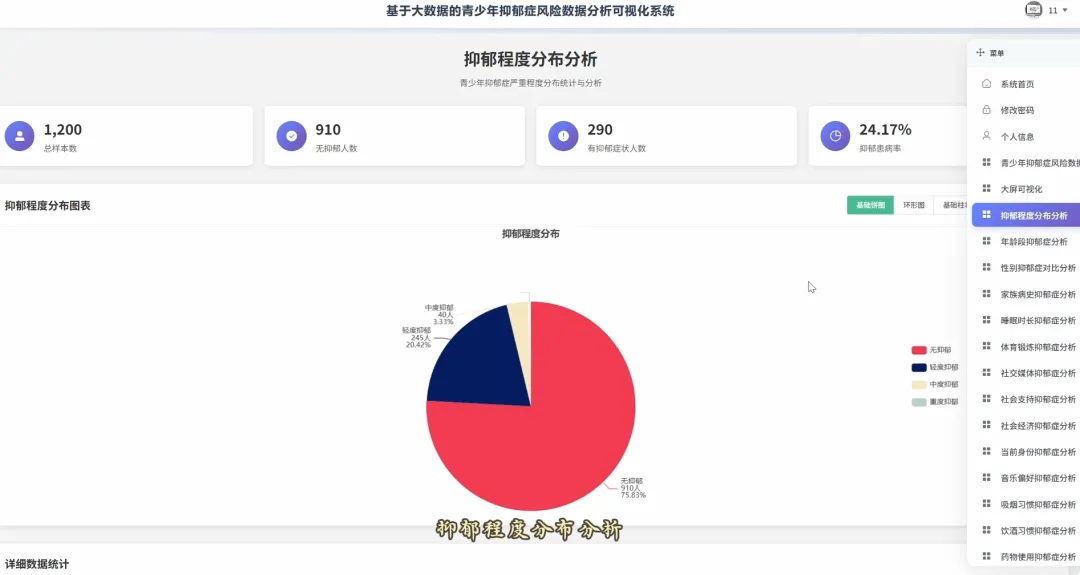
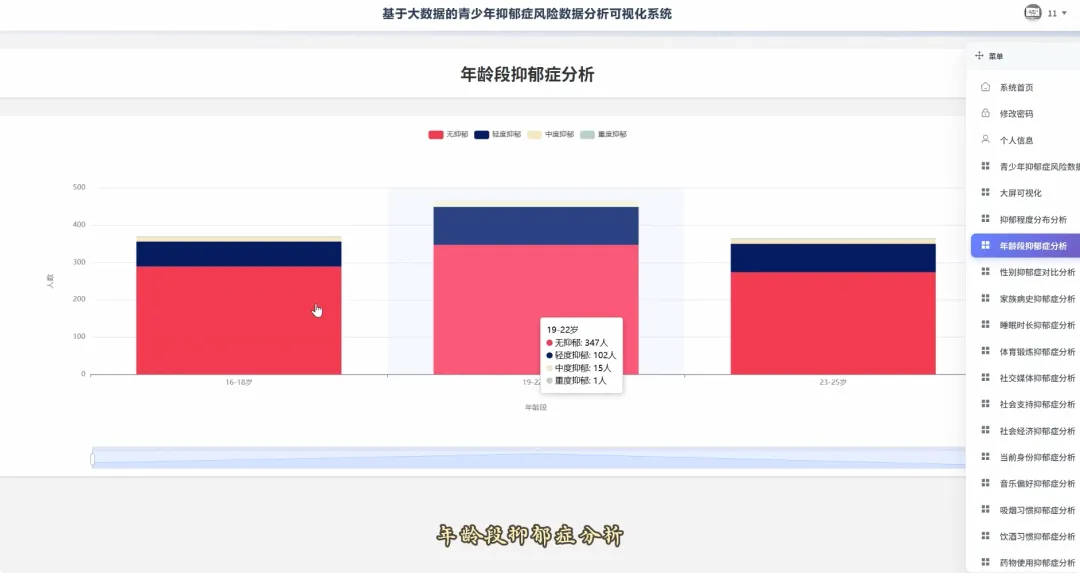
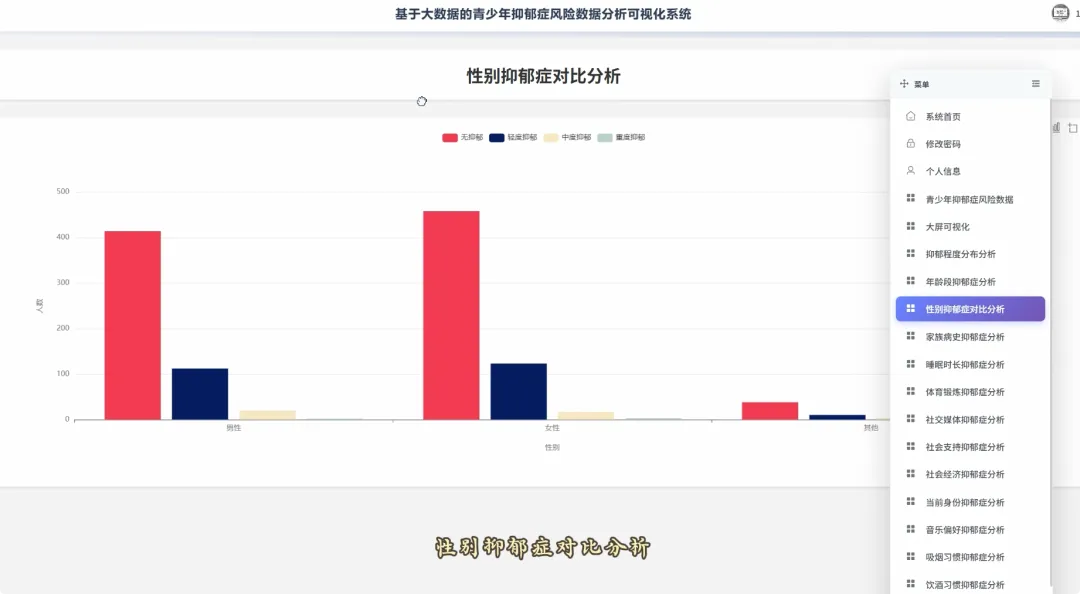
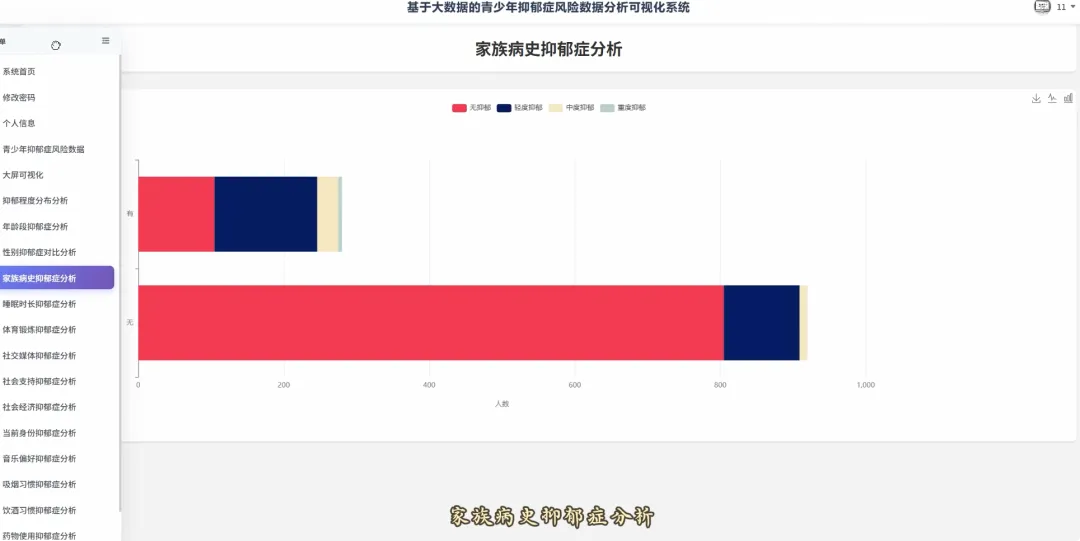
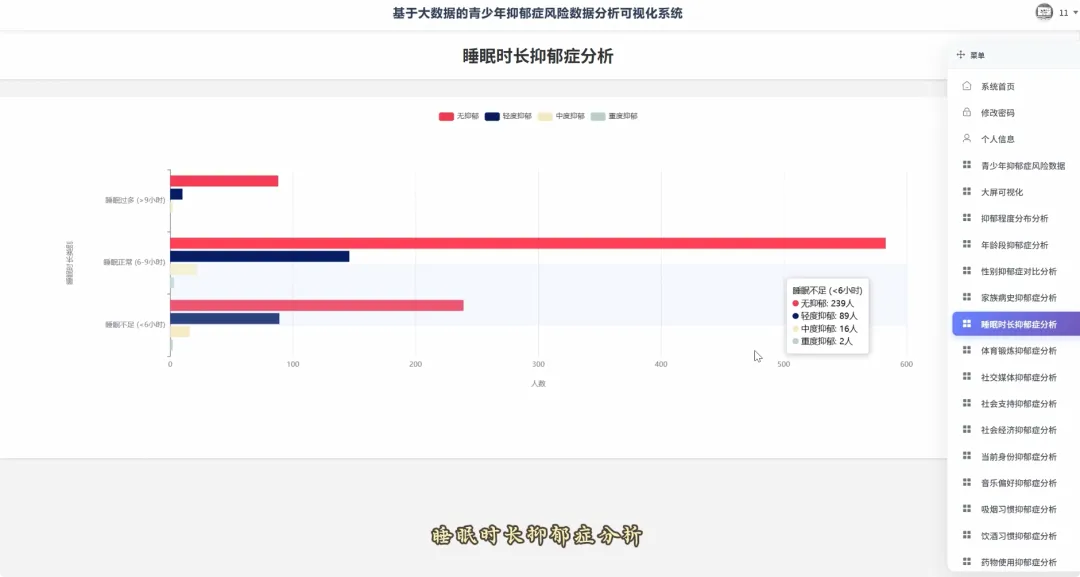
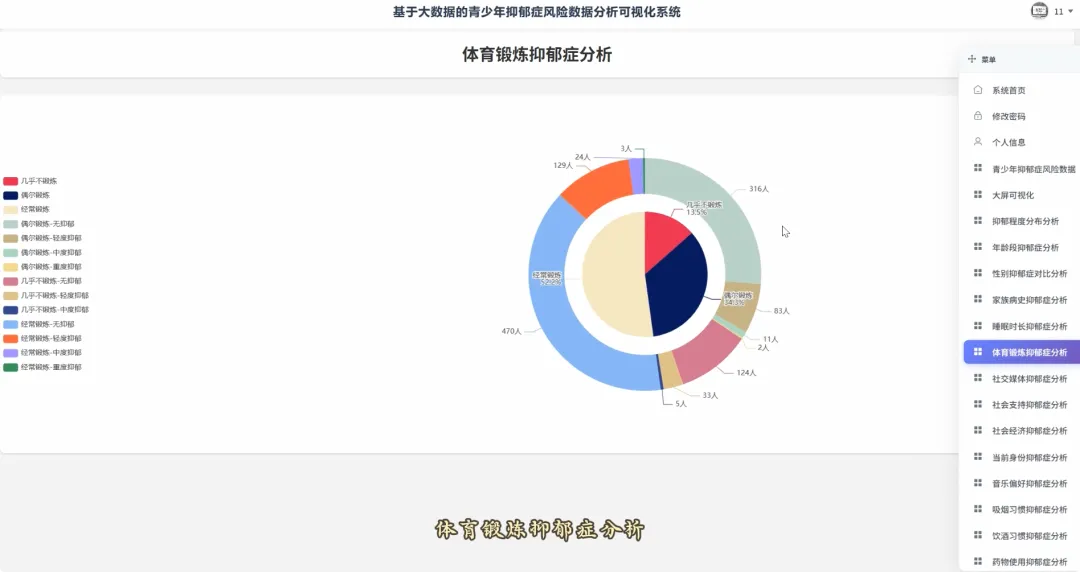
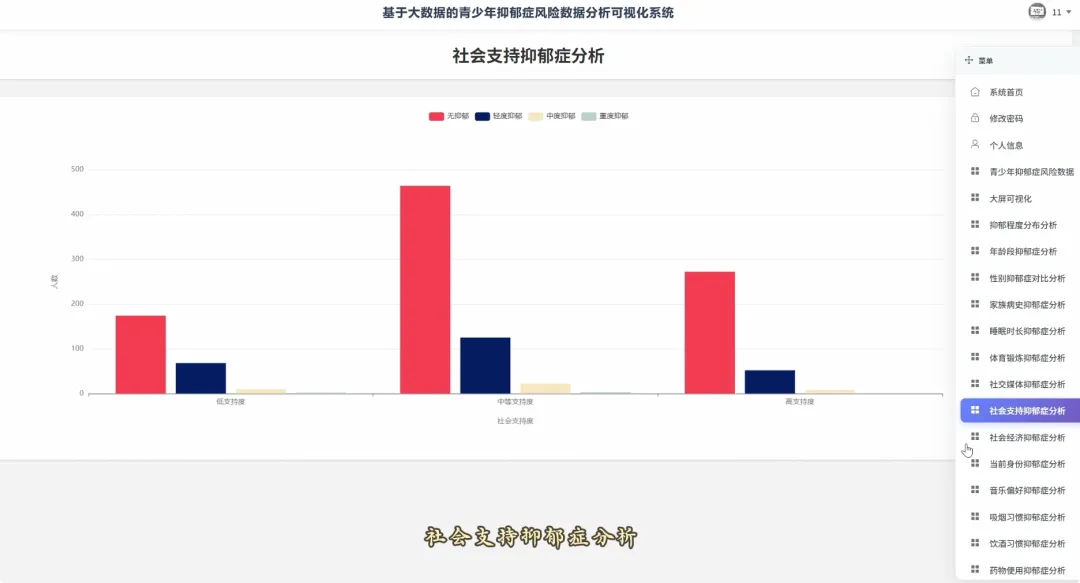
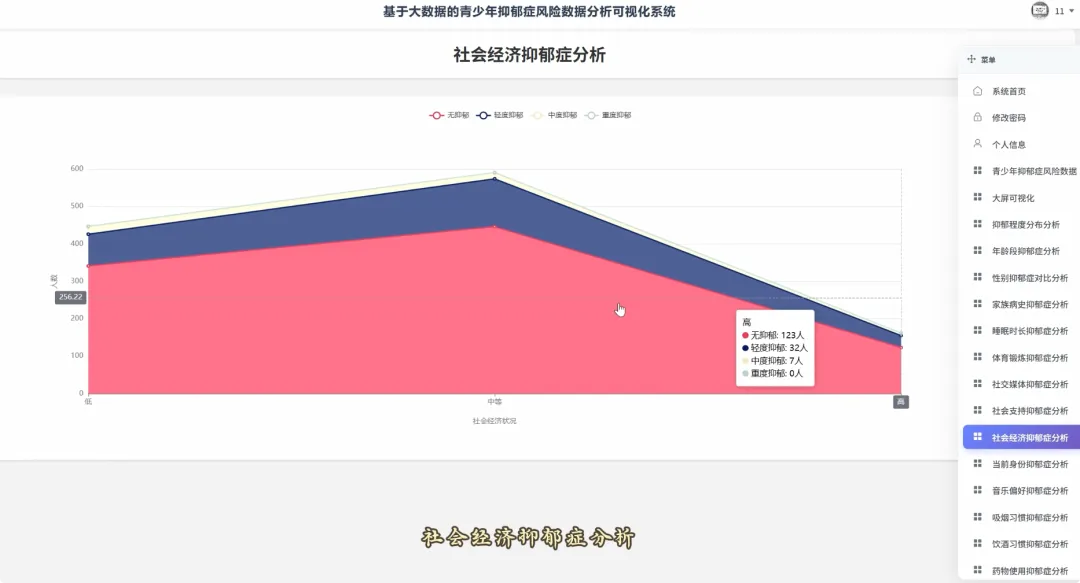
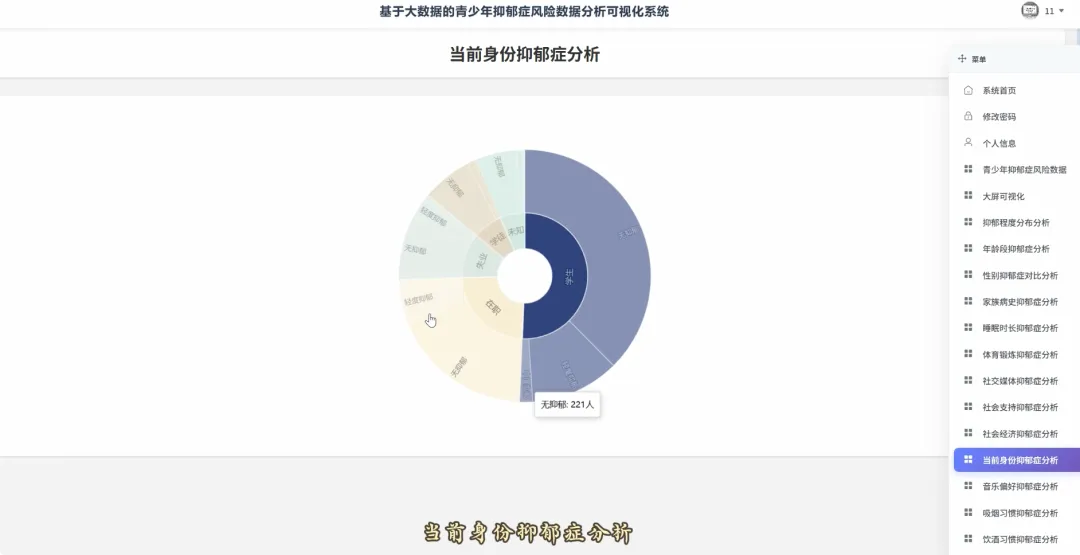
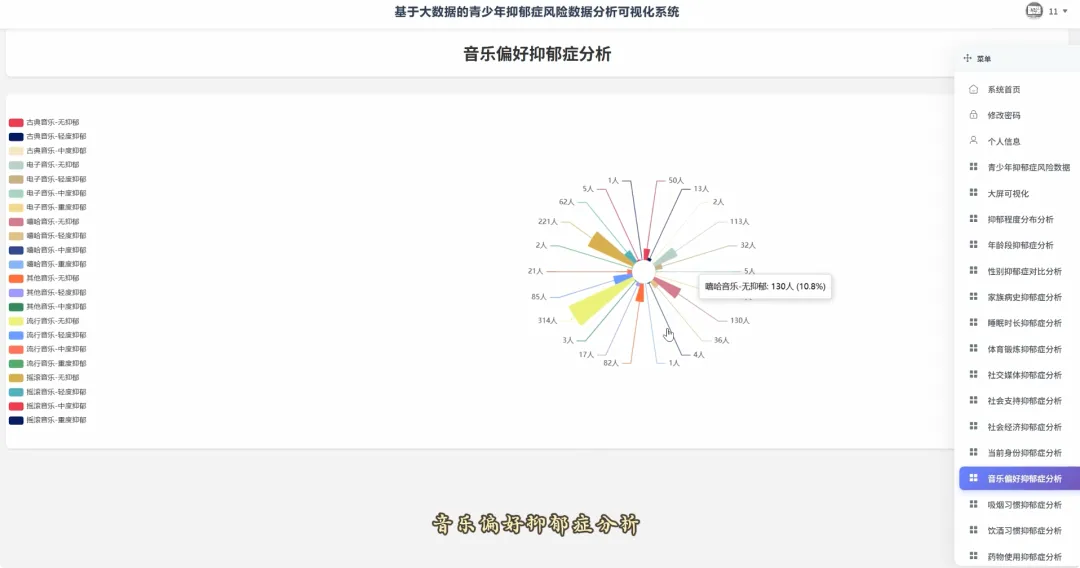
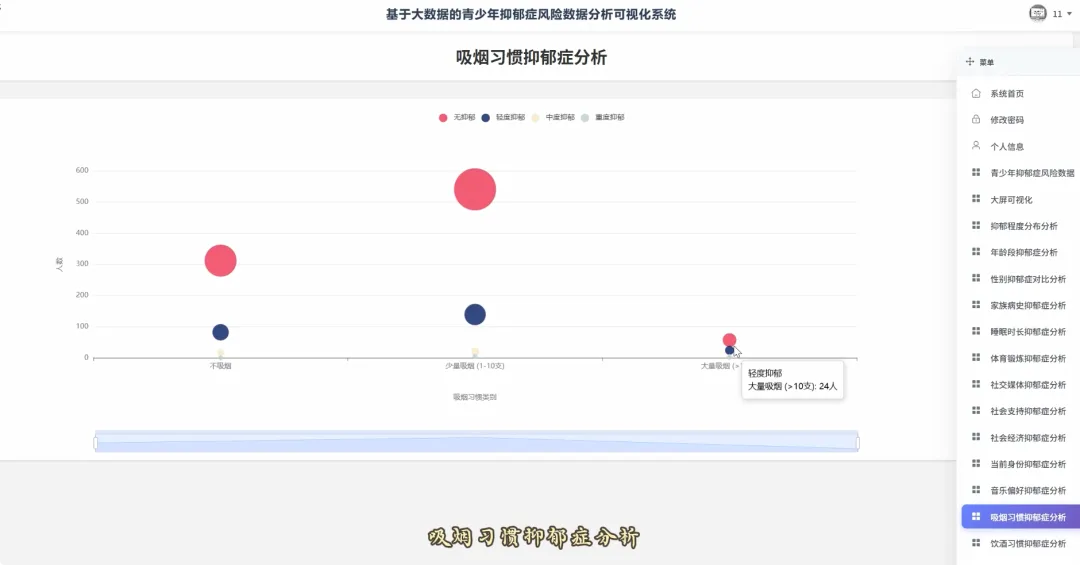
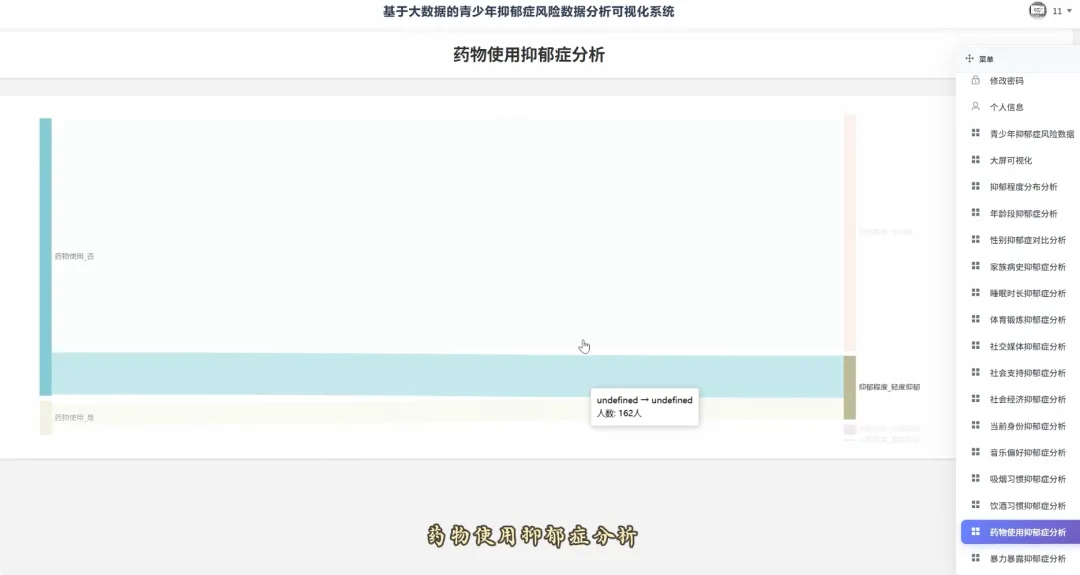
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("YouthDepressionAnalysis").getOrCreate()df = spark.read.csv("hdfs://namenode:8020/user/hadoop/depression_data.csv", header=True, inferSchema=True)def analyze_overall_depression_distribution(): global df result_df = df.groupBy("depression_severity").count().orderBy("count", ascending=False) data_list = [{"name": row['depression_severity'], "value": row['count']} for row in result_df.collect()] return data_listdef analyze_gender_vs_depression(): global df result_df = df.groupBy("gender", "depression_severity").count().orderBy("gender", "count", ascending=False) data_list = [{"gender": row['gender'], "severity": row['depression_severity'], "count": row['count']} for row in result_df.collect()] return data_listdef analyze_sleep_hours_vs_depression(): global df from pyspark.sql.functions import when, col binned_df = df.withColumn("sleep_category", when(col("sleep_hours") < 6, "睡眠不足(<6小时)").when((col("sleep_hours") >= 6) & (col("sleep_hours") <= 8), "正常睡眠(6-8小时)").otherwise("睡眠过多(>8小时)")) result_df = binned_df.groupBy("sleep_category", "depression_severity").count().orderBy("sleep_category", "count", ascending=False) data_list = [{"sleep": row['sleep_category'], "severity": row['depression_severity'], "count": row['count']} for row in result_df.collect()] return data_list