[快览-具身VLA] 通过“底层代码”优化VLA效果:香港大学、华为联合发布基于扩散式大模型构建的Dream-VLA
- 2026-07-06 15:36:12
文章背景
常用简称: Dream-VL、Dream-VLA(之前有另一篇简称为DreamVLA的研究,注意区分)
首发时间: 2025年12月27日(2026年01月04日v2)
主要作者: Jiacheng Ye、Shansan Gong、Jiahui Gao 等
发表机构: 香港大学、华为技术有限公司
文章导读
目前大部分 VLA 模型基于的自回归式 LLM/MLLM Backbone 在复杂视觉规划中能力受限,因此本研究将该 Backbone 替换为扩散式,在主流 Benchmarks上取得了较好的表现;
针对问题: 现有 VLA 模型的 Backbone 主要基于自回归式构建,存在长时程规划与全局推理瓶颈,推理时易误差累积,且下游适配需架构修改;
研究思路: 基于扩散式 LLM(dLLM)构建 dMLLM,再以其为 Backbone 构建 dVLA 模型;使 dLLM 的双向注意力、全局连贯性和并行生成等优势得以在 dVLA 模型中延续;
研究切入: 以 Dream-7B 为 Backbone,搭配视觉编码器 Qwen2ViT,经多阶段训练得到 Dream-VL,使其兼顾 High-Level 任务规划和 Low-Level 动作生成的能力;再通过任务头的适配+具身数据的预训练、LoRA微调,将其改造为 Dream-VLA,使其专注于 Low-Level 动作的生成任务;
方案实现
基于模型: dLLM:Dream-7B + 视觉编码器:Qwen2ViT
主要对比: Pi0、OpenVLA-OFT、GR00T-N1 等;
评测数据:
• 模拟:LIBERO、SimplerEnv、ViPlan • 实机:松灵PiPER+Intel RealSense D455 相机(Sim2Sim+Sim2Real方式)
主要流程:

主要工作
基于 dLLM 的架构设计: 以 Dream-7B 为主干模型,依次逐级构建 Dream-VL 和 Dream-VLA 。Dream-VL 通过给 Dream-7B 配置视觉编码器 Qwen2ViT 对输入的视觉信息进行编码,结合大量开源多模态数据进行多阶段训练,实现 High-Level 通用视觉理解与规划;Dream-VLA 在其基础上分别经过大量具身场景轨迹数据预训练+少量具身场景轨迹数据LoRA微调,使得 Dream-VLA 具备 Low-Level 具身动作生成输出能力;
多阶段训练与灵活适配策略: Dream-VL 基于 Dream-7B 采用三阶段训练范式,每个阶段之间的区别主要体现在训练数据从基础数据到单图、多图及视频数据的逐步拓展、训练参数的逐渐增加以及一些训练参数的逐渐调整;Dream-VLA 通过 LoRA 微调适配下游任务,支持 L1 回归、连续扩散、流匹配等多种损失函数,无需修改模型架构即可适配不同的下游动作生成任务头,同时实现更快的训练收敛速度;
实验实践
主要结果:
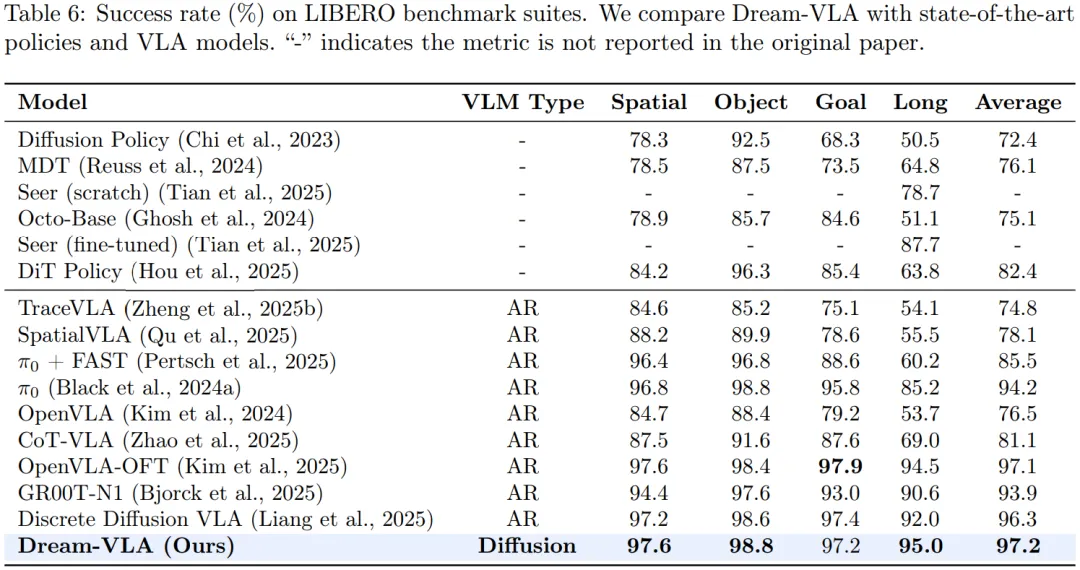
后续方向
• 系统优化训练数据; • 联合涉及 High-Level、Low-Level 的数据进行训练; • 改进离散动作表示,扩大实机数据集并深化泛化性评估;
相关链接
原文: https://arxiv.org/pdf/2512.22615
备注:上述论文解析仅针对本文发布时,arxiv上已公开被解析论文的最新版本内容进行;其中所有涉及原论文的图、数据都引用自原论文,如涉及侵权,请及时联系删除;人工解读,难免有错误遗漏,如有发现及时联系修改;如需要深入研究建议阅读原文;

