在 Linux 的世界里,有一个广为人知的哲学理念 ——“一切皆文件” 。无论是普通的文本文件、二进制文件,还是硬件设备(如硬盘、键盘、显示器),甚至是网络套接字、管道,在 Linux 内核眼中,统统被视为文件。这种统一的抽象处理,极大地简化了系统资源的管理和操作方式。但你有没有想过,当我们在 Linux 系统中执行各种文件操作时,系统是如何精准识别和管理这些不同类型的 “文件” 的呢?答案就是文件描述符(File Descriptor,简称 FD)。文件描述符就像是一把神奇的钥匙,它是进程访问文件或其他 I/O 资源的唯一标识,也是连接用户进程与内核资源的关键桥梁 。
举个简单的例子,当你在终端输入ls -l > file.txt命令时,这里的>就是重定向操作符,它将原本输出到终端屏幕(标准输出)的内容重定向到了file.txt文件中。在这个过程中,Linux 系统会为file.txt文件分配一个文件描述符,通过这个文件描述符,系统就能准确地将ls -l命令的输出内容写入到file.txt文件中 。
再比如,当你使用curl命令访问一个网页时,curl程序会打开一个网络套接字文件,并获得对应的文件描述符,然后通过这个文件描述符与远程服务器进行数据交互,获取网页内容 。
可以说,文件描述符在 Linux 系统的文件 I/O 操作中无处不在,它是理解 Linux 系统底层机制的关键所在。那么,文件描述符究竟是什么?它又是如何工作的呢?接下来,相信本文能为你带来关于 Linux 文件描述符的新认识和收获 。
一、文件描述符到底是什么?
1.1 定义与本质
在 Linux 系统中,文件描述符(File Descriptor)是一个非负整数,它是进程访问文件或其他 I/O 资源(如套接字、管道等)的唯一标识 。简单来说,文件描述符就像是一个 “资源索引”,它指向内核中被打开的文件或资源,是进程与内核之间进行文件操作的桥梁 。
需要注意的是,文件描述符本身并不是文件,而是一个指向文件或资源的标识符。每个进程都维护着一个独立的文件描述符表(File Descriptor Table),这个表记录了该进程当前打开的所有文件描述符及其对应的内核文件对象 。当进程打开一个文件或创建一个新的 I/O 资源时,内核会在该进程的文件描述符表中分配一个空闲的文件描述符,并返回给进程使用 。进程在进行文件读写、关闭等操作时,都是通过文件描述符来指定要操作的文件或资源 。
举个例子,假设你有一个文件柜,里面存放着各种文件。文件描述符就像是文件柜的索引标签,每个标签都对应着一个文件。当你想要查找某个文件时,只需要找到对应的索引标签,就能快速定位到文件所在的位置 。同样,在 Linux 系统中,进程通过文件描述符来快速定位和访问内核中的文件或资源 。
1.2 三个 “天生” 的文件描述符
在 Linux 系统中,每个进程在启动时都会默认打开三个标准的文件描述符,它们分别是:
标准输入(Standard Input):文件描述符为 0,通常简称为stdin。它默认对应着键盘设备,用于从键盘读取输入数据 。例如,当你在终端中输入命令时,命令行程序就是通过stdin来读取你输入的内容 。
标准输出(Standard Output):文件描述符为 1,通常简称为stdout。它默认对应着显示器设备,用于将程序的正常输出信息显示在终端屏幕上 。比如,当你执行ls命令时,ls命令的输出结果就是通过stdout输出到终端屏幕上的 。
标准错误(Standard Error):文件描述符为 2,通常简称为stderr。它也默认对应着显示器设备,用于将程序运行过程中产生的错误信息显示在终端屏幕上 。例如,当你执行一个不存在的命令时,系统会通过stderr输出错误提示信息,告诉你该命令未找到 。
这三个标准文件描述符在 Linux 系统中具有非常重要的作用,它们是进程与外部设备进行交互的基础 。而且,它们的分配是固定的,每个进程的文件描述符表中,0、1、2 这三个位置始终分别对应着stdin、stdout和stderr 。
我们可以通过一个简单的例子来验证这一点。在终端中执行以下命令:
echo "这是标准输出" >&1echo "这是标准错误" >&2
>&1表示将输出重定向到标准输出(文件描述符 1),>&2表示将输出重定向到标准错误(文件描述符 2) 。你会发现,两条echo命令的输出都会显示在终端屏幕上,这就证明了文件描述符 1 和 2 分别对应着标准输出和标准错误 。
理解这三个标准文件描述符是深入学习 Linux 文件 I/O 操作和重定向机制的基础,后续还会详细介绍它们在实际应用中的各种技巧和用法 。
二、内核视角:文件描述符的底层工作原理
2.1 三层数据结构
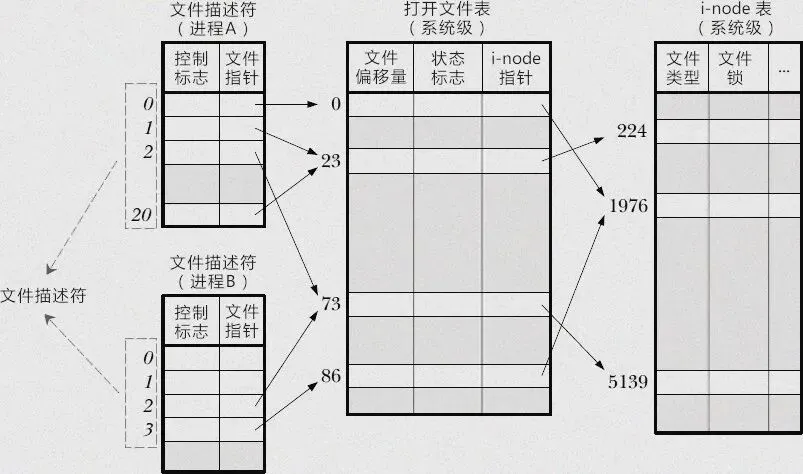
在内核中,文件描述符的管理依赖于三层紧密关联的数据结构,这三层结构分别是进程文件描述符表、系统打开文件表和 vnode/inode 表 。
进程文件描述符表(Process File Descriptor Table):每个进程都拥有一张属于自己的文件描述符表,这张表就像是一个 “索引簿”,记录了该进程当前打开的所有文件描述符 。表中的每一个表项都存储了一个文件描述符,以及该描述符对应的系统打开文件表条目的指针 。简单来说,进程通过文件描述符表,可以快速找到对应的系统打开文件表项,进而访问到文件的相关信息 。例如,当进程打开一个文件时,内核会在进程的文件描述符表中分配一个空闲的文件描述符,并将其与系统打开文件表中的对应表项建立关联 。
系统打开文件表(System Open File Table):这是一个系统级的数据结构,它记录了系统中所有被打开的文件的相关信息 。与进程文件描述符表不同,系统打开文件表是全局共享的,所有进程都可以访问它 。系统打开文件表中的每一个表项,包含了文件的读写位置、文件状态、访问权限等动态信息 。此外,它还维护了一个引用计数(reference count),用于记录有多少个文件描述符指向该表项 。这意味着,多个文件描述符可以指向系统打开文件表中的同一个表项,从而实现多个进程对同一个文件的共享访问 。比如,当多个进程同时打开同一个文件时,它们的文件描述符会指向系统打开文件表中的同一个表项,这样就避免了重复加载文件内容,提高了系统资源的利用率 。
vnode/inode 表(vnode/inode Table):vnode(虚拟节点)和 inode(索引节点)表存储了文件的元数据信息,如文件类型、文件大小、所有者、创建时间、修改时间等 。这些信息是文件的静态属性,不会随着文件的读写操作而频繁变化 。inode 是文件在磁盘上的唯一标识,每个文件都有一个对应的 inode 。而 vnode 则是 inode 在内存中的抽象表示,它提供了一种统一的接口,使得内核可以以相同的方式处理不同类型的文件系统 。vnode/inode 表的存在,使得内核在处理文件时,不需要关心文件的具体存储位置和文件系统类型,只需要通过 vnode/inode 表获取文件的元数据信息即可 。这大大简化了内核的文件管理逻辑,提高了系统的可扩展性和兼容性 。
为了更好地理解这三层数据结构之间的关系,以一个具体的例子来说明 。假设现在有一个进程 P1,它要打开一个名为fileA.txt的文件 。当进程 P1 执行open("fileA.txt", O_RDONLY)系统调用时,内核会按照以下步骤进行处理:
在进程文件描述符表中分配文件描述符:内核会在进程 P1 的文件描述符表中查找一个空闲的表项,假设找到的空闲表项对应的文件描述符为 3 。
在系统打开文件表中创建表项:内核会在系统打开文件表中创建一个新的表项,用于记录fileA.txt文件的相关信息,如读写位置、文件状态、访问权限等 。同时,内核会将该表项的引用计数设置为 1 。
在 vnode/inode 表中查找或创建 inode:内核会根据fileA.txt的文件名,在 vnode/inode 表中查找对应的 inode 。如果该 inode 已经存在(说明文件之前被打开过),内核会直接使用该 inode;如果 inode 不存在,内核会根据文件系统的元数据信息,创建一个新的 inode 。
建立三层结构之间的关联:内核会将进程 P1 的文件描述符 3 与系统打开文件表中的新表项建立关联,即进程文件描述符表中的表项 3 指向系统打开文件表中的新表项 。同时,系统打开文件表中的新表项会指向 vnode/inode 表中对应的 inode 。
通过以上步骤,进程 P1 就成功打开了fileA.txt文件,并建立了进程文件描述符表、系统打开文件表和 vnode/inode 表之间的关联 。此后,进程 P1 就可以通过文件描述符 3 来对fileA.txt文件进行读写操作了 。在这个过程中,三层数据结构各司其职,共同完成了文件的打开和管理工作 。进程文件描述符表提供了进程对文件的访问接口,系统打开文件表记录了文件的动态信息,vnode/inode 表存储了文件的静态元数据 。它们之间的紧密协作,是 Linux 系统高效管理文件的关键所在 。
2.2 文件描述符的两大核心特性
2.2.1 继承性
文件描述符的继承性是指子进程会继承父进程的文件描述符表 。当父进程调用fork()函数创建子进程时,子进程会复制父进程的地址空间,包括文件描述符表 。这意味着,子进程会拥有与父进程相同的文件描述符,并且这些文件描述符指向的是系统打开文件表中的同一个表项 。
文件描述符的继承性在很多场景中都发挥着重要的作用,其中最典型的就是管道和重定向功能 。以管道为例,管道是一种进程间通信(IPC)机制,它允许两个或多个有亲缘关系的进程之间进行数据传输 。在使用管道时,父进程首先会创建一个管道,然后调用fork()函数创建子进程 。由于子进程会继承父进程的文件描述符表,所以子进程也会拥有管道的读端和写端文件描述符 。通过这种方式,父进程和子进程就可以通过管道进行数据通信了 。
再比如,在命令行中经常使用的重定向操作,也是基于文件描述符的继承性实现的 。例如,当我们执行ls -l > file.txt命令时,>符号表示将标准输出重定向到file.txt文件 。在这个过程中,ls命令是父进程,它的标准输出文件描述符(FD=1)被重定向到了file.txt文件 。当ls命令执行完毕后,它会将标准输出的数据写入到file.txt文件中 。而file.txt文件的文件描述符是通过继承父进程的文件描述符表得到的 。
为了更直观地理解文件描述符的继承性,来看一个具体的代码示例 。下面是一段使用管道进行父子进程通信的 C 语言代码:
#include<stdio.h>#include<stdlib.h>#include<unistd.h>#include<string.h>#define BUFFER_SIZE 1024intmain(){ int pipe_fd[2]; pid_t pid; char buffer[BUFFER_SIZE]; // 创建管道 if (pipe(pipe_fd) == -1) { perror("pipe creation failed"); return 1; } // 创建子进程 pid = fork(); if (pid == -1) { perror("fork failed"); return 1; } else if (pid == 0) { // 子进程逻辑 close(pipe_fd[1]); // 关闭写端,子进程只需要读数据 ssize_t bytes_read = read(pipe_fd[0], buffer, BUFFER_SIZE - 1); if (bytes_read == -1) { perror("read failed"); return 1; } buffer[bytes_read] = '\0'; printf("子进程读取到的数据: %s\n", buffer); close(pipe_fd[0]); // 关闭读端 } else { // 父进程逻辑 close(pipe_fd[0]); // 关闭读端,父进程只需要写数据 const char *message = "Hello, child process!"; ssize_t bytes_written = write(pipe_fd[1], message, strlen(message)); if (bytes_written == -1) { perror("write failed"); return 1; } close(pipe_fd[1]); // 关闭写端 wait(NULL); // 等待子进程结束 printf("父进程已完成数据发送\n"); } return 0;}
在这段代码中,父进程首先创建了一个管道,然后调用fork()函数创建子进程 。子进程继承了父进程的文件描述符表,因此也拥有管道的读端和写端文件描述符 。在子进程中,关闭了写端文件描述符,只保留读端文件描述符,用于从管道中读取数据 。而在父进程中,关闭了读端文件描述符,只保留写端文件描述符,用于向管道中写入数据 。通过这种方式,父进程和子进程实现了通过管道进行数据通信 。
2.2.2 引用计数
当多个文件描述符指向系统打开文件表中的同一个表项时,就会涉及到引用计数(reference count)机制 。引用计数是一种用于管理资源引用的技术,它记录了有多少个文件描述符指向同一个打开文件表项 。每次复制文件描述符(例如通过dup()或dup2()函数),引用计数就会加 1;每次关闭文件描述符(通过close()函数),引用计数就会减 1 。只有当引用计数为 0 时,内核才会真正释放该文件的相关资源,包括关闭文件、释放内存等 。
引用计数机制的存在,确保了文件资源的正确管理和释放 。在多进程或多线程环境中,多个文件描述符可能同时指向同一个文件 。如果没有引用计数机制,当一个进程或线程关闭了它的文件描述符时,就可能会导致其他进程或线程无法继续访问该文件,从而引发错误 。而引用计数机制则保证了只有当所有的文件描述符都被关闭后,文件资源才会被释放 。
例如,假设进程 A 打开了一个文件,得到文件描述符 fd1 。然后,进程 A 调用dup(fd1)函数复制了文件描述符,得到 fd2 。此时,fd1 和 fd2 都指向系统打开文件表中的同一个表项,该表项的引用计数为 2 。当进程 A 关闭 fd1 时,系统打开文件表项的引用计数会减 1,变为 1 。这意味着,虽然 fd1 已经被关闭,但由于 fd2 仍然指向该文件,所以文件资源不会被释放 。只有当进程 A 也关闭了 fd2 时,引用计数才会变为 0,内核才会真正释放该文件的相关资源 。
下面是一个简单的代码示例,演示了引用计数的工作原理:
#include<stdio.h>#include<unistd.h>#include<fcntl.h>#include<stdlib.h>intmain(){ int fd1, fd2; // 打开文件 fd1 = open("test.txt", O_RDWR | O_CREAT, 0644); if (fd1 == -1) { perror("open failed"); return 1; } // 复制文件描述符 fd2 = dup(fd1); if (fd2 == -1) { perror("dup failed"); close(fd1); return 1; } // 输出文件描述符 printf("fd1: %d, fd2: %d\n", fd1, fd2); // 关闭fd1 if (close(fd1) == -1) { perror("close fd1 failed"); return 1; } // 此时fd2仍然可以操作文件 const char *message = "Hello, world!"; ssize_t bytes_written = write(fd2, message, strlen(message)); if (bytes_written == -1) { perror("write failed"); close(fd2); return 1; } // 关闭fd2 if (close(fd2) == -1) { perror("close fd2 failed"); return 1; } return 0;}
在这个示例中,首先打开一个文件test.txt,得到文件描述符 fd1 。然后,通过dup(fd1)复制文件描述符,得到 fd2 。此时,fd1 和 fd2 都指向同一个打开文件表项 。接着,关闭 fd1,虽然 fd1 已经关闭,但由于 fd2 仍然存在,所以文件并没有被真正关闭 。最后,通过 fd2 向文件中写入数据,验证了 fd2 仍然可以操作文件 。当关闭 fd2 后,文件的引用计数变为 0,文件资源才被真正释放 。通过这个示例,我们可以清楚地看到引用计数在文件描述符管理中的重要作用 。
三、类型大观
3.1 常见文件描述符类型
3.1.1 普通文件 FD
普通文件文件描述符是最常见的类型,用于操作磁盘上的普通文件,如文本文件(.txt)、二进制文件(.bin)等 。在 C 语言中,我们可以使用open函数来打开一个文件并获取其文件描述符 。
#include<stdio.h>#include<fcntl.h>#include<unistd.h>#include<stdlib.h>intmain(){ // 打开文件,O_RDONLY表示只读模式 int fd = open("test.txt", O_RDONLY); if (fd == -1) { perror("open failed"); return 1; } char buffer[1024]; // 从文件中读取数据 ssize_t bytes_read = read(fd, buffer, sizeof(buffer) - 1); if (bytes_read == -1) { perror("read failed"); close(fd); return 1; } buffer[bytes_read] = '\0'; printf("读取到的内容: %s\n", buffer); // 关闭文件描述符 if (close(fd) == -1) { perror("close failed"); return 1; } return 0;}
在上述代码中,首先使用open函数打开一个名为test.txt的文件,open函数成功执行后返回一个文件描述符fd 。然后,通过read函数利用这个文件描述符从文件中读取数据,并将读取到的数据存储在buffer数组中 。最后,使用close函数关闭文件描述符,释放相关资源 。这是一个典型的使用文件描述符操作普通文件的流程 。
3.1.2 套接字 FD
套接字文件描述符是网络通信的核心,它对应着网络中的 TCP 或 UDP 连接 。在 Linux 系统中,通过socket函数来创建套接字并获取其文件描述符 。网络编程中的连接建立(connect)、数据发送(send或write)、数据接收(recv或read)等操作,都是基于套接字文件描述符进行的 。
以 TCP 连接为例,服务器端的基本代码框架如下:
#include<stdio.h>#include<stdlib.h>#include<string.h>#include<sys/socket.h>#include<arpa/inet.h>#include<unistd.h>#define PORT 8080#define MAX_BUFFER_SIZE 1024intmain(){ int server_fd, new_socket; struct sockaddr_in address; int opt = 1; int addrlen = sizeof(address); char buffer[MAX_BUFFER_SIZE] = {0}; // 创建套接字,AF_INET表示IPv4协议,SOCK_STREAM表示TCP协议 server_fd = socket(AF_INET, SOCK_STREAM, 0); if (server_fd == -1) { perror("socket failed"); return 1; } // 配置套接字选项,SO_REUSEADDR表示允许重用本地地址和端口 if (setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt))) { perror("setsockopt failed"); close(server_fd); return 1; } address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons(PORT); // 将套接字绑定到指定的地址和端口 if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) == -1) { perror("bind failed"); close(server_fd); return 1; } // 开始监听连接,最大连接数为3 if (listen(server_fd, 3) == -1) { perror("listen failed"); close(server_fd); return 1; } // 接受客户端连接,返回新的套接字文件描述符 new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t *)&addrlen); if (new_socket == -1) { perror("accept failed"); close(server_fd); return 1; } // 从客户端接收数据 ssize_t bytes_read = recv(new_socket, buffer, MAX_BUFFER_SIZE - 1, 0); if (bytes_read == -1) { perror("recv failed"); close(new_socket); close(server_fd); return 1; } buffer[bytes_read] = '\0'; printf("接收到客户端的数据: %s\n", buffer); // 关闭套接字文件描述符 close(new_socket); close(server_fd); return 0;}
在这个例子中,首先通过socket函数创建了一个 TCP 套接字,并获得了对应的文件描述符server_fd 。然后,通过bind函数将套接字绑定到指定的 IP 地址和端口 。接着,使用listen函数开始监听连接,等待客户端的接入 。当有客户端连接时,通过accept函数接受连接,并返回一个新的套接字文件描述符new_socket,用于与客户端进行数据交互 。最后,通过recv函数从客户端接收数据,并在处理完数据后关闭套接字文件描述符 。
套接字文件描述符的存在,充分体现了 Linux 系统 “网络连接也是文件” 的设计思想 。这种统一的抽象使得我们可以使用与操作普通文件类似的方式来进行网络通信,大大简化了网络编程的复杂度 。无论是简单的客户端 - 服务器模型,还是复杂的分布式系统,套接字文件描述符都发挥着至关重要的作用 。
3.1.3 管道 FD
管道文件描述符用于进程间通信(IPC,Inter - Process Communication),它分为匿名管道和命名管道(FIFO,First - In - First - Out) 。匿名管道通过pipe函数创建,pipe函数会返回两个文件描述符,一个用于读(fd[0]),一个用于写(fd[1]) 。
下面是一个父子进程通过匿名管道通信的例子:
#include<stdio.h>#include<unistd.h>#include<stdlib.h>#include<string.h>#define BUFFER_SIZE 1024intmain(){ int pipe_fd[2]; pid_t pid; char buffer[BUFFER_SIZE]; // 创建管道 if (pipe(pipe_fd) == -1) { perror("pipe creation failed"); return 1; } // 创建子进程 pid = fork(); if (pid == -1) { perror("fork failed"); return 1; } else if (pid == 0) { // 子进程逻辑 close(pipe_fd[1]); // 关闭写端,子进程只需要读数据 ssize_t bytes_read = read(pipe_fd[0], buffer, BUFFER_SIZE - 1); if (bytes_read == -1) { perror("read failed"); return 1; } buffer[bytes_read] = '\0'; printf("子进程读取到的数据: %s\n", buffer); close(pipe_fd[0]); // 关闭读端 } else { // 父进程逻辑 close(pipe_fd[0]); // 关闭读端,父进程只需要写数据 const char *message = "Hello, child process!"; ssize_t bytes_written = write(pipe_fd[1], message, strlen(message)); if (bytes_written == -1) { perror("write failed"); return 1; } close(pipe_fd[1]); // 关闭写端 wait(NULL); // 等待子进程结束 printf("父进程已完成数据发送\n"); } return 0;}
在这个代码中,首先通过pipe函数创建了一个匿名管道,得到两个文件描述符pipe_fd[0]和pipe_fd[1] 。然后,通过fork函数创建子进程 。在子进程中,关闭管道的写端pipe_fd[1],只保留读端pipe_fd[0],用于从管道中读取父进程发送的数据 。在父进程中,关闭管道的读端pipe_fd[0],只保留写端pipe_fd[1],用于向管道中写入数据 。通过这种方式,实现了父子进程之间的单向数据传输 。需要注意的是,管道是单向的,数据只能从写端流向读端 。
命名管道(FIFO)则可以在不相关的进程之间进行通信 。命名管道在文件系统中以特殊文件的形式存在,通过mkfifo函数创建 。例如:
#include<stdio.h>#include<stdlib.h>#include<fcntl.h>#include<unistd.h>#include<string.h>#define FIFO_NAME "my_fifo"#define BUFFER_SIZE 1024intmain(){ int fd; char buffer[BUFFER_SIZE]; // 创建命名管道 if (mkfifo(FIFO_NAME, 0666) == -1) { perror("mkfifo failed"); return 1; } // 打开命名管道进行读取 fd = open(FIFO_NAME, O_RDONLY); if (fd == -1) { perror("open failed"); return 1; } // 从命名管道中读取数据 ssize_t bytes_read = read(fd, buffer, BUFFER_SIZE - 1); if (bytes_read == -1) { perror("read failed"); close(fd); return 1; } buffer[bytes_read] = '\0'; printf("读取到的数据: %s\n", buffer); // 关闭文件描述符 close(fd); return 0;}
在另一个进程中,可以通过以下方式向命名管道写入数据:
#include<stdio.h>#include<stdlib.h>#include<fcntl.h>#include<unistd.h>#include<string.h>#define FIFO_NAME "my_fifo"#define BUFFER_SIZE 1024intmain(){ int fd; const char *message = "Hello from another process!"; // 打开命名管道进行写入 fd = open(FIFO_NAME, O_WRONLY); if (fd == -1) { perror("open failed"); return 1; } // 向命名管道中写入数据 ssize_t bytes_written = write(fd, message, strlen(message)); if (bytes_written == -1) { perror("write failed"); close(fd); return 1; } // 关闭文件描述符 close(fd); return 0;}
通过命名管道,不同的进程可以通过文件系统中的同一个 FIFO 文件进行数据交互,实现进程间的通信 。
3.1.4 设备文件 FD
设备文件文件描述符用于操作硬件设备,如终端设备(/dev/tty)、空设备(/dev/null)等 。在 Linux 系统中,设备文件以特殊文件的形式存在于/dev目录下 。我们可以使用open函数打开设备文件,并获得对应的文件描述符,进而对设备进行操作 。
例如,将程序的日志输出重定向到/dev/null,可以实现程序的 “静默运行”,即不输出任何日志信息 。代码如下:
#include<stdio.h>#include<stdlib.h>#include<fcntl.h>#include<unistd.h>intmain(){ // 打开/dev/null设备文件,O_WRONLY表示只写模式 int null_fd = open("/dev/null", O_WRONLY); if (null_fd == -1) { perror("open /dev/null failed"); return 1; } // 将标准输出(文件描述符1)重定向到/dev/null if (dup2(null_fd, 1) == -1) { perror("dup2 failed"); close(null_fd); return 1; } // 关闭/dev/null的文件描述符,因为已经重定向,不再需要直接操作 close(null_fd); // 以下代码的输出将被重定向到/dev/null,不会显示在终端 printf("这是一条不会显示的日志信息\n"); return 0;}
在上述代码中,首先使用open函数打开/dev/null设备文件,得到文件描述符null_fd 。然后,通过dup2函数将标准输出文件描述符(fd = 1)重定向到null_fd,这样后续所有发送到标准输出的数据都会被写入到/dev/null设备中,从而实现了程序的静默运行 。这种技巧在一些后台服务程序或者不需要输出详细日志的场景中非常有用,可以避免大量无关信息输出到终端,干扰用户视线 。
3.2 特殊 FD 类型
除了上述常见的文件描述符类型外,Linux 系统还提供了一些特殊的文件描述符类型,用于实现更高级的功能 。例如,事件描述符(epoll_fd)和定时器描述符(timerfd) 。
事件描述符(epoll_fd)是 Linux 内核提供的一种高效的 I/O 多路复用机制,它允许程序同时监控多个文件描述符上的 I/O 事件(如可读、可写、异常等) 。通过epoll_create函数创建一个 epoll 实例,并返回对应的文件描述符(epoll_fd) 。然后,使用epoll_ctl函数将需要监控的文件描述符添加到 epoll 实例中,并指定要监控的事件类型 。最后,通过epoll_wait函数等待事件的发生 。事件描述符在处理大量并发连接的网络服务器中非常常用,可以显著提高服务器的性能和并发处理能力 。
定时器描述符(timerfd)则用于实现定时器功能 。通过timerfd_create函数创建一个定时器描述符,该描述符会在定时器到期时变成可读状态 。程序可以通过read函数从定时器描述符中读取定时器到期的次数,从而实现定时任务的触发 。定时器描述符为 Linux 系统中的定时任务处理提供了一种高效、灵活的方式,尤其适用于需要精确控制时间间隔的场景 。
这些特殊的文件描述符类型虽然不常见,但它们是 Linux 系统强大功能的重要组成部分,为开发者提供了更多的编程手段和灵活性 。它们也是 Linux 事件驱动编程的基础,在后续关于 I/O 多路复用和高性能服务器开发的内容中,我们会深入探讨它们的使用方法和应用场景 。
四、实战指南
4.1 基础操作
在 Linux 系统中,文件描述符的基础操作是进行文件 I/O 的核心,主要涉及open、read、write和close这几个系统调用 。掌握它们的正确使用方法,是熟练运用文件描述符的关键 。
创建文件描述符(open): open函数用于打开一个文件或创建一个新文件,并返回对应的文件描述符 。其函数原型如下:
#include<fcntl.h>#include<sys/types.h>#include<sys/stat.h>intopen(constchar *pathname, int flags, mode_t mode);
其中,pathname是要打开或创建的文件路径名;flags是打开文件的方式标志,常用的标志有O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写)等,还可以通过按位或(|)操作组合其他标志,如O_CREAT(如果文件不存在则创建)、O_APPEND(追加写入)等 。mode参数在创建新文件时用于指定文件的访问权限,例如0644表示文件所有者具有读写权限,组用户和其他用户具有读权限 。
例如,以读写方式打开一个文件,如果文件不存在则创建它:
int fd = open("test.txt", O_RDWR | O_CREAT, 0644);if (fd == -1) { perror("open failed"); return 1;}
通过文件描述符读写数据(read/write): read函数用于从文件描述符对应的文件中读取数据,write函数用于向文件描述符对应的文件中写入数据 。它们的函数原型分别为:
#include<unistd.h>ssize_tread(int fd, void *buf, size_t count);ssize_twrite(int fd, constvoid *buf, size_t count);
read函数中,fd是文件描述符,buf是用于存储读取数据的缓冲区,count是要读取的字节数 。函数返回实际读取的字节数,如果返回-1表示读取出错 。write函数中,fd同样是文件描述符,buf是要写入的数据缓冲区,count是要写入的字节数 。函数返回实际写入的字节数,如果返回-1表示写入出错 。
在使用read和write时,要注意缓冲区的使用 。合理设置缓冲区大小可以提高 I/O 效率,减少系统调用次数 。例如,从文件中读取数据并存储到缓冲区,然后再将缓冲区中的数据写入另一个文件:
char buffer[1024];ssize_t bytes_read = read(fd, buffer, sizeof(buffer));if (bytes_read > 0) { int new_fd = open("new_file.txt", O_WRONLY | O_CREAT, 0644); if (new_fd != -1) { ssize_t bytes_written = write(new_fd, buffer, bytes_read); if (bytes_written != bytes_read) { perror("write to new file failed"); } close(new_fd); } else { perror("open new file failed"); }} else if (bytes_read == -1) { perror("read failed");}
释放文件描述符(close): close函数用于关闭一个文件描述符,释放相关资源 。其函数原型为:
#include<unistd.h>intclose(int fd);
在使用完文件描述符后,一定要及时调用close函数关闭它,遵循 “打开即关闭” 的原则,避免资源泄露 。
if (close(fd) == -1) { perror("close failed");}
下面是一个完整的 C 语言示例代码,展示了文件描述符的基础操作流程:
#include<stdio.h>#include<fcntl.h>#include<unistd.h>#include<stdlib.h>intmain(){ // 打开文件,若不存在则创建 int fd = open("test.txt", O_RDWR | O_CREAT, 0644); if (fd == -1) { perror("open failed"); return 1; } // 写入数据 const char *write_message = "Hello, Linux file descriptor!"; ssize_t bytes_written = write(fd, write_message, strlen(write_message)); if (bytes_written == -1) { perror("write failed"); close(fd); return 1; } // 将文件指针移动到文件开头 if (lseek(fd, 0, SEEK_SET) == -1) { perror("lseek failed"); close(fd); return 1; } // 读取数据 char buffer[1024]; ssize_t bytes_read = read(fd, buffer, sizeof(buffer) - 1); if (bytes_read == -1) { perror("read failed"); close(fd); return 1; } buffer[bytes_read] = '\0'; printf("读取到的数据: %s\n", buffer); // 关闭文件描述符 if (close(fd) == -1) { perror("close failed"); return 1; } return 0;}
在这个示例中,首先使用open函数打开或创建一个文件,获取文件描述符fd 。然后使用write函数向文件中写入数据,接着通过lseek函数将文件指针移动到文件开头,再使用read函数从文件中读取数据并打印 。最后,使用close函数关闭文件描述符,释放资源 。每个关键步骤都进行了错误处理,确保程序的健壮性 。
4.2 查看技巧:如何监控进程的 FD?
4.2.1 利用 /proc 文件系统
在 Linux 系统中,/proc文件系统是一个非常强大的工具,它提供了一种便捷的方式来查看和管理系统信息,包括进程的文件描述符 。/proc文件系统是一个虚拟文件系统,它以文件和目录的形式展示了系统内核和进程的运行状态 。
对于每个正在运行的进程,在/proc目录下都有一个以其进程 ID(PID)命名的子目录 。例如,进程 ID 为1234的进程,其相关信息可以在/proc/1234目录中找到 。在这个目录下,有一个名为fd的子目录,它包含了该进程当前打开的所有文件描述符的符号链接 。这些符号链接的文件名就是文件描述符的编号,而链接指向的目标则是对应的文件或设备 。
例如,要查看当前 Shell 进程的文件描述符,可以通过以下步骤:
首先,获取当前 Shell 进程的 PID 。在终端中执行echo $$命令,$$是一个特殊的 Shell 变量,它表示当前 Shell 进程的 PID 。假设输出的 PID 为5678 。
然后,查看/proc/5678/fd目录下的内容 。执行ls -l /proc/5678/fd命令,会看到类似如下的输出:
lrwx------ 1 user user 64 Jun 8 15:34 0 -> /dev/pts/0lrwx------ 1 user user 64 Jun 8 15:34 1 -> /dev/pts/0lrwx------ 1 user user 64 Jun 8 15:34 2 -> /dev/pts/0lr-x------ 1 user user 64 Jun 8 15:34 3 -> /usr/bin/bash
从输出中可以看出,文件描述符0、1、2都指向/dev/pts/0,这表示它们分别对应着标准输入、标准输出和标准错误,并且都关联到当前的终端设备 。文件描述符3指向/usr/bin/bash,这是当前 Shell 进程的可执行文件 。
通过这种方式,我们可以直观地了解到一个进程打开了哪些文件描述符,以及它们分别指向哪些资源 。这在调试和排查问题时非常有用,比如可以通过查看文件描述符的指向,来确定某个进程是否正确地打开了所需的文件或设备 。
4.2.2 使用 lsof 命令
lsof(list open files)命令是另一个用于查看系统中打开文件信息的强大工具 。它可以列出指定进程打开的所有文件描述符及其对应的文件、设备、套接字等资源信息,帮助我们快速定位进程的资源占用情况 。
lsof命令的基本用法是:lsof [options] [filename] 。其中,options是各种选项参数,用于指定要显示的信息和过滤条件;filename是可选参数,用于指定要查看的文件或目录 。如果不指定filename,lsof将列出系统中所有打开的文件 。
常用的选项包括:
-p pid:指定要查看的进程 ID(PID),只列出该进程打开的文件 。例如,lsof -p 1234将列出进程 ID 为1234的进程打开的所有文件 。
-c comm:指定要查看的进程名称,列出该进程打开的文件 。例如,lsof -c bash将列出所有名为bash的进程打开的文件 。
-i:用于查看与网络相关的文件,如套接字 。可以进一步指定协议、端口等条件 。例如,lsof -i tcp:80将列出所有使用 TCP 协议且监听在 80 端口的套接字 。
下面通过几个具体的例子来演示lsof命令的使用:
查看进程 ID 为1234的进程打开的所有文件:
输出结果类似如下:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEprocess1 1234 user cwd DIR 8,1 4096 2 /process1 1234 user rtd DIR 8,1 4096 2 /process1 1234 user txt REG 8,1 123456 123 /usr/bin/process1process1 1234 user mem REG 8,1 567890 456 /lib/libc.so.6process1 1234 user 3u REG 8,1 1024 789 /home/user/data.txtprocess1 1234 user 4u IPv4 12345 0t0 TCP *:80 (LISTEN)
在这个输出中,每一行表示一个打开的文件或资源 。其中,COMMAND表示进程名称,PID是进程 ID,USER是进程所有者,FD是文件描述符,TYPE是文件类型,DEVICE表示设备,SIZE/OFF是文件大小或偏移量,NODE是索引节点,NAME是文件或资源的名称 。可以看到,进程process1打开了当前工作目录(cwd)、根目录(rtd)、可执行文件(txt)、共享库文件(mem)、普通文件(3u)以及一个监听在 80 端口的 TCP 套接字(4u) 。
查看所有使用 UDP 协议且监听在 53 端口(DNS 服务常用端口)的套接字:
通过lsof命令,我们可以清晰地了解到系统中各个进程对文件描述符的使用情况,无论是普通文件、设备文件还是网络套接字 。这对于系统管理员进行资源管理、故障排查以及安全审计等工作都非常有帮助 。
4.3 重定向实战:用 dup2 实现 “输出转移”
在 Linux 系统中,重定向是一种非常实用的功能,它允许我们改变程序的输入输出方向 。例如,将原本输出到终端屏幕的内容重定向到文件中,或者将文件的内容作为程序的输入 。重定向的底层原理其实就是修改文件描述符的指向,而实现这一功能的核心函数就是dup2 。
dup2函数的原型如下:
#include<unistd.h>intdup2(int oldfd, int newfd);
dup2函数的作用是将newfd文件描述符重定向到oldfd文件描述符所指向的文件或资源 。如果newfd之前已经打开,dup2会先关闭newfd,然后将newfd指向与oldfd相同的文件或资源 。函数执行成功时返回newfd,失败时返回-1 。
下面通过一个具体的代码示例来演示如何使用dup2函数实现标准输出的重定向:
#include<stdio.h>#include<unistd.h>#include<fcntl.h>#include<stdlib.h>intmain(){ // 打开一个文件,用于接收重定向后的输出 int file_fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644); if (file_fd == -1) { perror("open output.txt failed"); return 1; } // 将标准输出(文件描述符1)重定向到file_fd if (dup2(file_fd, 1) == -1) { perror("dup2 failed"); close(file_fd); return 1; } // 关闭file_fd,因为已经重定向,不需要再直接操作它 close(file_fd); // 此时,所有原本输出到标准输出的数据都会被重定向到output.txt文件中 printf("This is a test message.\n"); return 0;}
在这个示例中,首先使用open函数打开一个名为output.txt的文件,并获取其文件描述符file_fd 。然后,通过dup2函数将标准输出文件描述符(fd = 1)重定向到file_fd 。这样,后续所有发送到标准输出的数据都会被写入到output.txt文件中 。最后,关闭file_fd,因为标准输出已经重定向,不再需要直接操作这个文件描述符 。
执行上述代码后,在终端中不会看到printf函数的输出,而是会在当前目录下生成一个output.txt文件,文件内容为This is a test message. 。
为了验证重定向后文件描述符的指向变化,我们可以结合/proc文件系统来查看 。假设当前进程的 PID 为1234,在重定向之前,执行ls -l /proc/1234/fd命令,可以看到文件描述符1指向/dev/pts/0(表示终端设备) 。在重定向之后,再次执行ls -l /proc/1234/fd命令,会发现文件描述符1已经指向了output.txt文件 。这就直观地证明了dup2函数成功地修改了文件描述符的指向,实现了输出重定向的功能 。
通过dup2函数实现的重定向功能,在实际应用中非常广泛 。例如,在编写日志记录程序时,可以将程序的日志输出重定向到文件中,方便后续查看和分析 。在进行数据处理时,也可以将数据的输入输出进行重定向,实现自动化的数据处理流程 。
五、高级进阶:FD 与 I/O 多路复用的 “强强联合”
5.1 为什么需要 I/O 多路复用?
在高并发场景下,服务器需要同时处理大量的客户端连接和 I/O 操作 。例如,一个大型的 Web 服务器可能需要同时处理成千上万的用户请求 。如果采用传统的阻塞 I/O 模型,为每个客户端连接创建一个单独的线程或进程来处理 I/O 操作,那么当客户端数量增多时,系统资源会被大量消耗,性能也会急剧下降 。因为每个线程或进程都需要占用一定的系统资源(如内存、CPU 时间片等),而且线程或进程的上下文切换也会带来额外的开销 。
为了解决这个问题,I/O 多路复用技术应运而生 。I/O 多路复用允许一个进程或线程同时监控多个文件描述符(FD)的状态变化,当某个 FD 上有 I/O 事件发生(如可读、可写、异常等)时,系统会通知进程或线程进行相应的处理 。这样,一个进程或线程就可以处理多个客户端的 I/O 操作,而不需要为每个客户端创建单独的线程或进程,从而大大提高了系统的并发处理能力和资源利用率 。
传统的阻塞 I/O 模型在处理多个 FD 时,存在明显的局限性 。假设我们有一个服务器程序,需要同时处理多个客户端的连接 。在阻塞 I/O 模型下,当服务器调用accept函数等待客户端连接时,如果没有客户端连接到来,accept函数会一直阻塞,导致服务器无法处理其他任务 。同样,当服务器调用read或write函数进行数据读写时,如果数据没有准备好,read或write函数也会一直阻塞,使得服务器无法及时响应其他客户端的请求 。
相比之下,I/O 多路复用机制通过一个接口(如select、poll、epoll等)来监控多个 FD 的状态,当有 FD 就绪时,接口会返回,通知程序进行处理 。这样,程序可以在一个线程或进程中同时处理多个 FD 的 I/O 操作,避免了线程或进程的阻塞和上下文切换开销,提高了系统的性能和并发处理能力 。
5.2 select/poll:早期的多路复用方案
select和poll是早期 Linux 系统中常用的 I/O 多路复用方案 。它们的出现,在一定程度上解决了传统阻塞 I/O 模型在高并发场景下的性能瓶颈问题 。
select函数通过位图(fd_set)来管理需要监控的文件描述符 。它将需要监控的 FD 分为三类:读集合(readfds)、写集合(writefds)和异常集合(exceptfds) 。在调用select函数时,需要将这三个集合传递给内核,内核会遍历这些集合,检查每个 FD 的状态 。如果某个 FD 上有可读、可写或异常事件发生,select函数会返回,并将就绪的 FD 对应的位设置为 1 。应用程序通过检查返回的位图,来判断哪些 FD 就绪,然后进行相应的 I/O 操作 。然而,select存在一个明显的缺陷,即单个进程所能监控的 FD 数量受到FD_SETSIZE的限制,通常这个值为 1024 。这意味着,当需要处理的并发连接数超过 1024 时,select就无法满足需求了 。而且,每次调用select函数时,都需要将整个fd_set从用户空间拷贝到内核空间,返回时又要将修改后的fd_set从内核空间拷贝回用户空间,这种频繁的内存拷贝操作会带来较大的开销 。另外,select返回后,应用程序需要遍历整个fd_set来确定哪些 FD 就绪,时间复杂度为 O (n),当 FD 数量较多时,效率会显著下降 。
poll函数则是对select的改进 。它使用一个pollfd结构体数组来表示需要监控的 FD 及其事件 。每个pollfd结构体包含三个成员:文件描述符(fd)、监控的事件(events)和事件的返回值(revents) 。poll函数没有了 FD 数量的硬限制,理论上可以监控任意数量的 FD 。在调用poll函数时,将pollfd数组传递给内核,内核会遍历数组,检查每个 FD 的状态,并将事件的发生情况记录在revents成员中 。poll函数返回后,应用程序通过检查revents来判断哪些 FD 就绪 。虽然poll解决了select的 FD 数量限制问题,但它本质上和select没有太大差别 。每次调用poll时,仍然需要将整个pollfd数组从用户空间拷贝到内核空间,返回时再拷贝回来,这同样会带来较大的开销 。而且,poll返回后,应用程序还是需要遍历整个pollfd数组来确定就绪的 FD,随着 FD 数量的增加,性能依然会受到影响,时间复杂度也为 O (n) 。
5.3 epoll:高并发场景的 “最优解”
epoll是 Linux 内核为处理大批量文件描述符而设计的高效 I/O 多路复用机制,它诞生于 Linux 2.5.44 内核版本 ,专为解决高并发场景下 I/O 处理的效率问题 。与select和poll相比,epoll在设计上有了质的飞跃,成为了高并发场景下的 “最优解” 。
epoll的工作机制主要涉及三个系统调用:epoll_create、epoll_ctl和epoll_wait 。首先,通过epoll_create函数创建一个epoll实例,并返回一个特殊的文件描述符(epoll_fd),这个epoll_fd用于标识该epoll实例,后续对该实例的操作都需要通过这个文件描述符来进行 。接着,使用epoll_ctl函数向epoll实例中添加、修改或删除需要监听的文件描述符及其事件 。epoll_ctl函数会将这些信息注册到内核的事件表中,内核使用红黑树来管理这些文件描述符,这样可以保证插入、删除和查找的高效性,时间复杂度为 O (log n) 。最后,通过epoll_wait函数等待事件的发生 。当有文件描述符就绪(即有可读、可写或异常事件发生)时,内核会将其加入就绪链表中 。epoll_wait函数返回时,会直接返回就绪的文件描述符列表,应用程序只需处理这些就绪的文件描述符即可,无需遍历所有的文件描述符,时间复杂度为 O (1) 。
epoll具有以下显著优势:
无 FD 数量限制:epoll没有文件描述符数量的上限,它能轻松处理成千上万的并发连接,这使得它非常适合高并发的网络应用场景 。例如,在一个大型的在线游戏服务器中,可能需要同时处理大量玩家的连接和实时交互,epoll能够很好地满足这种需求,而不会像select那样受到 FD 数量的限制 。
无需重复拷贝:epoll通过内核与用户空间共享内存,避免了像select和poll那样每次调用时都需要将文件描述符集合从用户空间拷贝到内核空间,以及从内核空间拷贝回用户空间的操作,大大减少了数据拷贝的开销,提高了系统的性能 。
避免无效轮询:epoll采用事件驱动模式,只有当文件描述符上有实际事件发生时,内核才会通知应用程序,应用程序只需处理有状态变化的文件描述符,避免了对所有文件描述符的无效轮询,从而提高了系统的效率 。在一个拥有大量并发连接的 Web 服务器中,大部分连接可能在大部分时间内都处于空闲状态,如果使用select或poll,每次都需要遍历所有的连接来检查是否有事件发生,而epoll只需要关注那些有事件发生的连接,大大减少了无效操作 。
许多高性能服务器,如 Nginx 和 Redis,都基于epoll来处理海量连接 。以 Nginx 为例,它作为一款高性能的 Web 服务器和反向代理服务器,能够处理大量的并发请求 。Nginx 利用epoll的高效 I/O 多路复用机制,在一个进程中同时监控大量的网络连接,当有客户端请求到来时,能够迅速响应并处理,从而实现了高并发和高性能 。在实际应用中,Nginx 可以轻松应对数以万计的并发连接,为用户提供快速、稳定的服务 。Redis 作为一款高性能的内存数据库,也依赖epoll来处理大量的客户端连接和数据读写操作 。通过epoll,Redis 能够高效地处理大量的并发请求,保证数据的快速读写和一致性,满足了各种对性能要求极高的应用场景 。
六、FD 常见问题与解决方案
6.1 “Too many open files”:FD 耗尽的原因与解决
在 Linux 系统中,当进程试图打开的文件描述符(FD)数量超过了系统或进程自身的限制时,就会遭遇 “Too many open files” 错误 。这一错误犹如系统发出的红色警报,预示着进程的资源使用已达极限,必须及时处理,否则可能导致程序崩溃或服务中断 。
该错误的核心原因是进程打开的 FD 数量超过了系统或进程级别的限制 。系统为了防止单个进程无节制地占用资源,会对每个进程可打开的 FD 数量设置上限 。在 Linux 系统中,有两个主要的限制指标:进程级限制和系统级限制 。进程级限制可以通过ulimit -n命令查看,它表示当前进程可打开的最大 FD 数量,默认值通常为 1024 。而系统级限制则可以通过cat /proc/sys/fs/file-max命令查看,它表示整个系统可打开的最大 FD 数量 。
当进程在运行过程中不断打开新的文件、套接字或其他 I/O 资源,却没有及时关闭不再使用的 FD 时,FD 数量就会逐渐增加,最终可能达到并超过系统或进程级的限制,从而触发 “Too many open files” 错误 。例如,在一个高并发的网络服务器中,如果每个客户端连接都需要打开一个套接字文件描述符,并且没有正确处理连接关闭的情况,当并发连接数超过了系统或进程可承受的 FD 数量时,就会出现这个错误 。
为了解决 “Too many open files” 问题,我们可以采取以下措施:
这种方法简单快捷,但仅对当前终端会话生效,一旦重新登录或重启系统,限制值将恢复为默认值 。
* soft nofile 65535* hard nofile 65535
其中,soft表示软限制,是用户可动态调整的上限;hard表示硬限制,是管理员设置的绝对上限,用户无法超过这个值 。修改完成后,保存文件并重新登录系统,新的限制配置即可生效 。
这将把系统全局的最大文件描述符数设置为 1000000 。修改完成后,执行sudo sysctl -p命令使配置生效 。
在进行上述修改时,需要谨慎操作,确保设置的值合理且系统资源能够支持 。如果设置过高,可能会导致系统资源耗尽,影响其他进程的正常运行 。
6.2 FD 泄露排查:如何找到 “忘记关闭” 的 FD?
文件描述符(FD)泄露是指在程序运行过程中,打开的文件描述符没有被正确关闭,导致系统资源被持续占用 。对于长期运行的进程,如后台服务程序,FD 泄露问题尤为严重 。随着时间的推移,未关闭的 FD 数量会不断累积,最终耗尽系统的 FD 资源,引发 “Too many open files” 错误,导致程序崩溃或服务异常 。
为了排查 FD 泄露问题,我们可以采用以下方法:
watch -n 1 "lsof -p 1234 | wc -l"
上述命令中,watch -n 1表示每 1 秒执行一次后面的命令;lsof -p 1234用于列出进程 ID 为 1234 的进程打开的所有文件描述符;wc -l则用于统计输出的行数,即 FD 数量 。通过观察 FD 数量是否持续增长,我们可以初步判断是否存在 FD 泄露问题 。
withopen('test.txt', 'r') as f: data = f.read()# 这里文件会在with块结束时自动关闭,无需手动调用close方法
在 C++ 中,可以利用智能指针和 RAII 机制来管理文件描述符,如下所示:
#include<iostream>#include<fstream>#include<memory>class FileGuard {public: FileGuard(const std::string& filename) : file_(std::make_unique<std::ifstream>(filename)) { if (!file_->is_open()) { throw std::runtime_error("Failed to open file"); } } ~FileGuard() = default; std::ifstream& get(){ return *file_; }private: std::unique_ptr<std::ifstream> file_;};intmain(){ try { FileGuard file("test.txt"); std::string line; while (std::getline(file.get(), line)) { std::cout << line << std::endl; } } catch (const std::exception& e) { std::cerr << "Error: " << e.what() << std::endl; } return 0;}
在这个 C++ 示例中,FileGuard类利用智能指针std::unique_ptr来管理文件流std::ifstream 。在FileGuard对象的构造函数中打开文件,在析构函数中自动关闭文件 。这样,即使在main函数中发生异常,文件也能被正确关闭,有效避免了 FD 泄露 。通过类似的机制,我们可以在各种编程语言中更好地管理文件描述符,减少 FD 泄露的风险 。